Hadoop完全分布式集群搭建过程(HA高可用)
使用Centos7来进行完全分布式的集群搭建,一般我们用伪分布式的集群就可以了,不需要配置完全分布式的集群
和我们搭建伪分布式集群一样,我们首先要现在好安装包,以及我们需要配置配置JDK,SSH免秘钥登陆,以及Zookeeper分布式的搭建等,下面就开始我们的搭建过程
一、配置Linux虚拟机
1.配置主机名以及主机映射
我们配置集群环境的时候,设置固定的主机名和主机映射能够方便的让我我们使用
修改主机名
修改主机名的时候,Centos6和Centos7完全不一样。下面是Centos7为例来修改我们的主机名
vim /etc/hostname
删除原来的主机名,修改为我们自己的要配置的,在这里我修改的主机名为zj01,zj02,zj03,一般我们都是设置的master,slave1,slave2。按照个人喜好修改主机名
注意:修改主机名后我们需要重启虚拟机才会生效,使用reboot命令重启虚拟机
reboot
补充:Centos6修改主机名
vim /etc/sysconfig/network
将里面原来信息修改为如下信息:
NETWORKING=yes
HOSTNAME=zj01
修改完成后重启虚拟机
配置主机映射
修改配置文件hosts
vim /etc/hosts
根据自己的ip信息,添加如下信息:
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.8.130 zj01
192.168.8.131 zj02
192.168.8.132 zj03
再修改我们的主机映射的时候,我们可以通过ifconfig来查看我们自己的ip信息,进行配置
ifconfig

主机映射配置完毕
2.关闭防火墙
Centos7系统默认防火墙不是iptables,而是firewall,那就得使用以下方式关闭防火墙了。
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
此时Centos7的防火墙就关闭了。
补充:Centos6关闭防火墙
service iptables status #查看防火墙状态
service iptables stop #关闭防火墙,但是重启后会恢复原来状态
chkconfig iptables --list #查看系统中防火墙的自动
chkconfig iptables off #关闭防火墙自启动
chkconfig iptables --list #再次查看防火墙自启动的情况,所有启动状态都变成额off
常时间没有用过Centos6了,应该是–list,如果不是直接关闭就行了,不用纠结这个命令
二、SSH免秘钥的配置
执行以下命令来生成相应得秘钥
ssh-keygen -t rsa
一路回车,生成私有秘钥
cd /root/.ssh
ls

一般在第一次执行的时候,只有id_rsa、id_rsa.pub这两个文件,但是id_rsa.pub文件存的基石私有秘钥,要想让其他节点来连接本台机器我们需要生成公钥,执行ssh-copy-id可以将秘钥转成公钥,在三台节点上执行以下命令:
ssh-copy-id zj01
ssh-copy-id zj02
ssh-copy-id zj03
执行过次语句后,每台节点上都会生成以下两个文件authorized_keys,known_hosts,查看两个文件的内容,执行此语句的时候需要我们先输入yes统一连接,再输入要连接节点的密码就可以了。
cat authorized_keys

此文件里面存储的是三台节点的秘钥。
查看known_hosts文件
cat known_hosts

此文件主要记录的是我们使用ssh连接过的主机名。
相对而言authorized_keys文件是最重要的,有了这个文件我们再使用ssh连接的时候直接就连接了,不用我们再输入密码。

自此SSH免秘钥设置完毕。我们可以继续下面组件的安装配置。
三、JDK的安装部署
创建一个目录,用来存放所有的安装目录。在这里我创建的是目录是/apps/,我们可以将所有的安装包上传到这个文件中,解压后再将安装包删除。
注意:jdk三台都需要配置
1.卸载系统自带的jdk
rpm -qa | grep java
使用rpm进行卸载
rpm -e java-xxx
rpm -e --nodeps java-xxx #强制卸载
2.下载jdk安装包并上传到虚拟机中
在官网上进行下载jdk的安装包
官网路径:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html

我这里面使用的XShell连接的虚拟机,在XShell连接的时候,执行以下语句就可以实验windows和虚拟机之间的文件传输
yum install lrzsz -y
执行完成后就可以将文拖到虚拟机终端里面进行文件的上传。
注意:这只是其中的一种解决方案,我们还可以下载winscp来实现文件的上传下载。
3.安装jdk
解压并重新命令
tar -zxvf jdk-8u162-linux-x64.tar.gz ./
mv jdk-1.8.0_162 jdk
rm -rf jdk-8u162-linux-x64.tar.gz
修改环境变量(三个节点都配置)
vim /etc/profile
配置如下:
#JDK 1.8
export JAVA_HOME=/apps/jdk
export PATH=$PATH:$JAVA_HOME/bin
刷新环境变量
source /etc/profile
验证jdk是否安装成功
java -version
输出如下:

我们可以通过以下命令将jdk文件上传到其余的节点中
scp -r /apps/jdk zj02:/apps/
scp -r /apps/jdk zj03:/apps/
这样我们就可以在02,03节点上/apps/目录下查看我们上传的jdk文件,需要我们配置环境变量就可以了。
四、Zookeeper的安装部署
要配置完全分布式的Hadoop集群,Zookeeper的主要作用就是协调集群的运行,在Hadoop生态圈中zookeeper的作用是至关重要的。
下载zookeeper的安装包
首先我们要先下载zookeeper的安装包,在管网上下载安装包就可以了
管网路径:https://archive.apache.org/dist/zookeeper/
这里面有好多版本,我们可以选择自己版本进行下载。
将下载后的安装包,上传到zj01的/apps目录下。
安装zookeeper
解压zookeeper的安装包并重名为zookeeper
tar -zxvf zookeeper-3.4.12.tar.gz
mv zookeeper-3.4.12 zookeeper
rm -rf zookeeper-3.4.12.tar.gz
修改环境变量(三个节点都配置)
vim /etc/profile
在文件末尾添加一下信息
#zookeeper
export ZOOKEEPER_HOME=/apps/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
配置到文件后我们要刷新一下环境变量,让我们的配置信息生效
source /etc/profile
配置zookeeper
进入zookeeper的conf目录下,将zoo_example.cfg复制出来一个为zoo.cfg
cp zoo_example.cfg zoo.cfg
修改zoo.cfg文件
vim zoo.cfg
配置信息如下

server.0=zj01:2888:3888
server.1=zj02:2888:3888
server.2=zj03:2888:3888
其中0、1、2分别代表的是zj01、zj02、zj03的标识符。
创建标识符
进入dataDir设置的目录/apps/zookeeper/tmp,在此目录下创建一个myid文件,用来存放我们设置的标识符
cd /apps/zookeeper/tmp
echo 1 > myid
查看标识符

分发文件到其余的两个节点
scp -r /apps/zookeeper slave2:/apps/zookeeper
scp -r /apps/zookeeper slave3:/apps/zookeeper
记得修改zj02,zj03的标识符为1和2


启动zookeeper
zkServer.sh stat
查看每台zookeeper的状态,会出现一个leader,两个flower。此时zookeeper的集群搭建完毕
五、Hadoop的安装部署
下载安装包
我们可以在官网上进行下载安装包
官网:https://archive.apache.org/dist/hadoop/common/
进入官网选择自己想要下载的安装包进行下载,切记下载64位的tar.gz安装包
将下载好的安装包上传到zj01的/apps/目录下。
安装hadoop
解压并重命名为hadoop
tar -zxvf hadoop-2.7.5.tar.gz
mv hadoop-2.7.5 hadoop
rm -rf hadoop-2.7.5.tar.gz
修改环境变量(三个节点都配置)
vim /etc/profile
在文件末尾添加一下信息
#hadoop
export HADOOP_HOME=/apps/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
配置到文件后我们要刷新一下环境变量,让我们的配置信息生效
source /etc/profile
修改配置文件
进入hadoop配置文件所在目录
cd /apps/hadoop/etc/hadoop
我们在此目录下需要修改5个配置文件
修改hadoop-env.sh
需要我们指定jdk的版本信息
export JAVA_HOME=/apps/jdk
修改core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://bigdatavalue>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/apps/hadoop/tmpvalue>
<description>Abase for other temporary directories.description>
property>
<property>
<name>hadoop.proxyuser.hduser.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.hduser.groupsname>
<value>*value>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>zj01:2181,zj02:2181,zj03:2181value>
property>
configuration>
修改hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservicesname>
<value>bigdatavalue>
property>
<property>
<name>dfs.ha.namenodes.bigdataname>
<value>nn1, nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.bigdata.nn1name>
<value>zj01:9000value>
property>
<property>
<name>dfs.namenode.rpc-address.bigdata.nn2name>
<value>zj02:9000value>
property>
<property>
<name>dfs.namenode.http-address.bigdata.nn1name>
<value>zj01:50070value>
property>
<property>
<name>dfs.namenode.http-address.bigdata.nn2name>
<value>zj02:50070value>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/home/hadoop/hadoop/journaldatavalue>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://zj01:8485;zj02:8485;zj03:8485/bigdatavalue>
property>
<property>
<name>dfs.namenode.edits.journal-plugin.qjournal name>
<value>org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManagervalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.namenode.name.dir.restorename>
<value>truevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.bigdataname>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>
sshfence
shell(/bin/true)
value>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/root/.ssh/id_rsavalue>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///apps/hadoop/dfsdata/namevalue>
property>
<property>
<name>dfs.blocksizename>
<value>67108864value>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///apps/hadoop/dfsdata/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
configuration>
修改mapred-site.xml
复制mapred-site.xml.template为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
具体配置信息如下:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.connect.retry-interval.msname>
<value>2000value>
property>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>zj01value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>zj02value>
property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.ha.idname>
<value>rm1value>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>zj01:2181,zj02:2181,zj03:2181value>
property>
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-msname>
<value>5000value>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>bigdatavalue>
property>
<property>
<name>yarn.resourcemanager.address.rm1name>
<value>zj01:8132value>
property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1name>
<value>zj01:8130value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1name>
<value>zj01:8088value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1name>
<value>zj01:8131value>
property>
<property>
<name>yarn.resourcemanager.admin.address.rm1name>
<value>zj01:8033value>
property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1name>
<value>zj01:23142value>
property>
<property>
<name>yarn.resourcemanager.address.rm2name>
<value>zj02:8132value>
property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2name>
<value>zj02:8130value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2name>
<value>zj02:8088value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2name>
<value>zj02:8131value>
property>
<property>
<name>yarn.resourcemanager.admin.address.rm2name>
<value>zj02:8033value>
property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2name>
<value>zj02:23142value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.nodemanager.local-dirsname>
<value>/apps/hadoop/dfsdata/yarn/localvalue>
property>
<property>
<name>yarn.nodemanager.log-dirsname>
<value>/apps/hadoop/dfsdata/logsvalue>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>1024value>
<discription>每个节点可用内存,单位 MBdiscription>
property>
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>258value>
<discription>单个任务可申请最少内存,默认 1024MBdiscription>
property>
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>512value>
<discription>单个任务可申请最大内存,默认 8192MBdiscription>
property>
<property>
<name>yarn.nodemanager.webapp.addressname>
<value>0.0.0.0:8042value>
property>
configuration>
修改slaves文件
zj01
zj02
zj03
分发hadoop文件到其他节点
scp -r /apps/hadoop slave2:/apps/
scp -r /apps/hadoop slave3:/apps/
初始化hadoop
在执行格式化的时候开启一个进程:
hadoop-daemon.sh start journalnode
格式化之后将name文件拷贝到zj02中,按理说应该是自动生成的,我的没有自动生成,是自己拷贝进去的
hadoop namennode -format
启动hadoop集群
#先启动zookeeper,再启动hadoop集群
start-all.sh
启动情况如下:

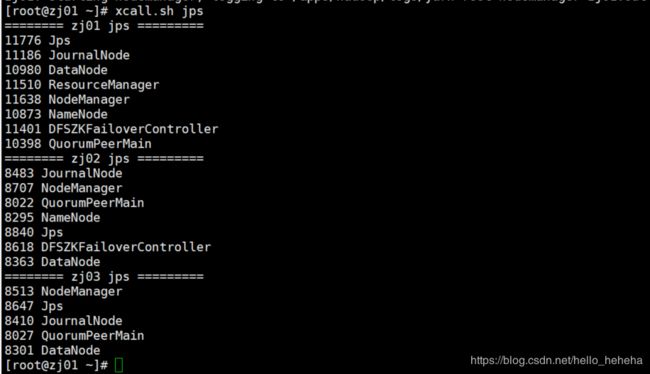
查看虚拟机的各个进程:
访问zj01:50070端口和zj02:50070端口
http://zj01:50070
http://zj02:50070


访问zj01:8088端口
http://zj01:8088

hadoop集安装成功,如果安装有什么问题,可以随时提哟,希望能帮助您。
如果你在安装碰见了什么样问题,或者我的文档写的有不合理之处,欢迎指出谢谢。