Python爬虫入门教程 22-100 CSDN学院课程数据抓取
1. CSDN学院课程数据写在前面
今天又要抓取一个网站了,选择恐惧症使得我不知道该拿谁下手,找来找去,算了,还是抓取CSDN学院吧,CSDN学院的网站为 https://edu.csdn.net/courses 我看了一下这个网址,课程数量也不是很多,大概有 6000+ 门课程,数据量不大,用单线程其实就能很快的爬取完毕,不过为了秒爬,我还是选用了一个异步数据操作。
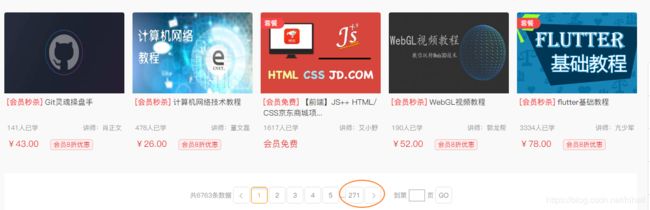
2. CSDN学院课程数据分析页码
还是需要好好的分析一下页码规律
https://edu.csdn.net/courses/p2
https://edu.csdn.net/courses/p3
https://edu.csdn.net/courses/p4
... ...
https://edu.csdn.net/courses/p271
页码还是非常有规律的,直接编写代码就可以快速的爬取下来。出于人文关怀,我还是把协程数限制在3,要不顺发271个请求还是有点攻击的性质了。这样不好,不符合我们的精神。
import asyncio
import aiohttp
from lxml import etree
sema = asyncio.Semaphore(3)
async def get_html(url):
headers = {
"user-agent": "自己找个UA即可"
}
'''
本文来自 梦想橡皮擦 的博客
地址为: https://blog.csdn.net/hihell
可以任意转载,但是希望给我留个版权。
'''
print("正在操作{}".format(url))
async with aiohttp.ClientSession() as s:
try:
async with s.get(url, headers=headers, timeout=3) as res:
if res.status==200:
html = await res.text()
html = etree.HTML(html)
get_content(html) # 解析网页
print("数据{}插入完毕".format(url))
except Exception as e:
print(e)
print(html)
time.sleep(1)
print("休息一下")
await get_html(url)
async def x_get_html(url):
with(await sema):
await get_html(url)
if __name__ == '__main__':
url_format = "https://edu.csdn.net/courses/p{}"
urls = [url_format.format(index) for index in range(1, 272)]
loop = asyncio.get_event_loop()
tasks = [x_get_html(url) for url in urls]
request = loop.run_until_complete(asyncio.wait(tasks))
3. CSDN学院课程数据解析网页函数
网页下载到了之后,需要进行二次处理,然后才可以把他放入到mongodb中,我们只需要使用lxml库即可
def get_content(html):
course_item = html.xpath("//div[@class='course_item']")
data = []
for item in course_item:
link = item.xpath("./a/@href")[0] # 获取课程详情的链接,方便我们后面抓取
tags = item.xpath(".//div[@class='titleInfor']/span[@class='tags']/text()") # 获取标签
title = item.xpath(".//div[@class='titleInfor']/span[@class='title']/text()")[0] # 获取标题
num = item.xpath(".//p[@class='subinfo']/span/text()")[0] # 学习人数
subinfo = item.xpath(".//p[@class='subinfo']/text()")[1].strip() # 作者
price = item.xpath(".//p[contains(@class,'priceinfo')]/i/text()")[0].strip() # 作者
data.append({
"title":title,
"link":link,
"tags":tags,
"num":num,
"subinfo":subinfo,
"price":price
})
collection.insert_many(data)
4. 数据存储
数据保存到mongodb中,完成。

