Python爬虫入门教程 50-100 Python3爬虫爬取VIP视频-Python爬虫6操作
爬虫背景
原计划继续写一下关于手机APP的爬虫,结果发现夜神模拟器总是卡死,比较懒,不想找原因了,哈哈,所以接着写后面的博客了,从50篇开始要写几篇python爬虫的骚操作,也就是用Python3通过爬虫实现一些小工具。
Python3 VIP视频下载器
这种软件或者网站满天都是了,就是在线观看收费网站的VIP视频,你只要会玩搜索引擎或者是一个程序员基本都知道,虽说一直在被封杀,但是能赚钱的地方就一定有人钻漏洞。今天要实现的就是通过别人的API在Python中下载ts视频到本地,自己去百度一下TS视频是什么吧。

找相关的接口
我随便搜索了一下,那是非常多的,版权问题,就不放相关的地址了,当然在代码中还是会出现一下的。
我找到这个接口应该是目前相对比较稳定的,并且还在更新的
我看了一下,他中间主要通过三个API整体实现的页面逻辑
首先你先去优酷啊,腾讯啊,爱奇艺啊找个VIP视频的地址,这个随意啦
我找了一个《叶问外传》
http://v.youku.com/v_show/id_XNDA0MDg2NzU0OA==.html?spm=a2h03.8164468.2069780.5

编写代码几个步骤
在浏览器测试播放地址,得到线路播放数据
http://y.mt2t.com/lines?url=https://v.qq.com/x/cover/5a3aweewodeclku/b0024j13g3b.html

在页面的源码中,请注意,打开开发者工具直接按快捷键F12即可,右键已经被锁定。
在源码中,发现真实的调用地址
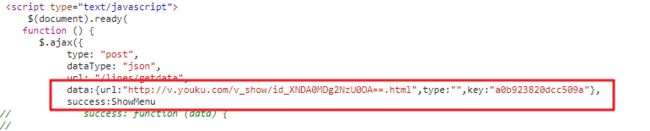
所以,你需要先匹配出来key来,非常简单,使用正则表达式即可
import requests
import re
class VIP(object):
def __init__(self):
self.api = "http://y.mt2t.com/lines?url="
self.url = "http://v.youku.com/v_show/id_XNDA0MDg2NzU0OA==.html?spm=a2h03.8164468.2069780.5"
def run(self):
res = requests.get(self.api+self.url)
html = res.text
key = re.search(r'key:"(.*?)"',html).group(1)
print(key)
if __name__ == '__main__':
vip = VIP()
vip.run()
得到key之后,就可以进行获取播放地址了,经过分析也可以知道接口为
Request URL: http://y.mt2t.com/lines/getdata
Request Method: POST
那么只需要编写一下即可
import requests
import re
import json
class VIP(object):
def __init__(self):
self.api = "http://y.mt2t.com/lines?url="
self.post_url = "http://y.mt2t.com/lines/getdata"
self.url = "http://v.youku.com/v_show/id_XNDA0MDg2NzU0OA==.html?spm=a2h03.8164468.2069780.5"
def run(self):
res = requests.get(self.api+self.url)
html = res.text
key = re.search(r'key:"(.*?)"',html).group(1)
return key
def get_playlist(self):
key = self.run()
data = {
"url":self.url,
"key":key
}
html = requests.post(self.post_url,data=data).text
dic = json.loads(html)
print(dic)
if __name__ == '__main__':
vip = VIP()
vip.get_playlist()
上面的代码可以得到如下的数据集

这个数据集需要解析一下,用来获取播放地址,请注意还有一个接口我们需要打通
Request URL: http://y2.mt2t.com:91/ifr/api
Request Method: POST
参数如下
url: +bvqT10xBsjrQlCXafOom96K2rGhgnQ1CJuc5clt8KDHnjH75Q6BhQ4Vnv7gUk+SpJYws4A93QjxcuTflk7RojJt0PiXpBkTAdXtRa6+LAY=
type: m3u8
from: mt2t.com
device:
up: 0
这个API的所有参数都是从刚才获得的数据集分解出来的
提取上面结果集中的URL
http://y2.mt2t.com:91/ifr?url=%2bbvqT10xBsjrQlCXafOom96K2rGhgnQ1CJuc5clt8KDHnjH75Q6BhQ4Vnv7gUk%2bSpJYws4A93QjxcuTflk7RojJt0PiXpBkTAdXtRa6%2bLAY%3d&type=m3u8
对这个URL进行分解,这个地方你需要了解一般情况下URL进行哪些符号的特殊编码
大小写都有可能
| 符号 | 特殊编码 |
|---|---|
| + | %2d |
| / | %2f |
| % | %25 |
| = | %3d |
| ? | %3F |
| # | %23 |
| & | %26 |
所以编写的代码如下
def url_spilt(self):
url = "http://y2.mt2t.com:91/ifr?url=%2bbvqT10xBsjrQlCXafOom96K2rGhgnQ1CJuc5clt8KDHnjH75Q6BhQ4Vnv7gUk%2bSpJYws4A93QjxcuTflk7RojJt0PiXpBkTAdXtRa6%2bLAY%3d&type=m3u8"
url = url.split("?url=")[1].split("&")[0].replace("%2b","+").replace("%3d","=").replace("%2f","/")
print(url)
接下来获取type 这个比较容易
只需要判断以下type=是否在字符串中然后截取即可。
url截取的代码如下
def url_spilt(self,url):
#url = "http://y2.mt2t.com:91/ifr?url=%2bbvqT10xBsjrQlCXafOom96K2rGhgnQ1CJuc5clt8KDHnjH75Q6BhQ4Vnv7gUk%2bSpJYws4A93QjxcuTflk7RojJt0PiXpBkTAdXtRa6%2bLAY%3d&type=m3u8"
url_param = url.split("?url=")[1].split("&")[0].replace("%2b","+").replace("%3d","=").replace("%2f","/")
if "type=" in url:
type = url.split("type=")[1]
else:
type = ""
return url_param,type
完善get_playlist函数,最终的代码如下
def get_playlist(self):
key = self.run()
data = {
"url":self.url,
"key":key
}
html = requests.post(self.post_url,data=data).text
dic = json.loads(html)
for item in dic:
url_param, type = self.url_spilt(item["Url"])
res = requests.post(self.get_videourl,data={
"url":url_param,
"type":type,
"from": "mt2t.com",
"device":"",
"up":"0"
})
play = json.loads(res.text)
print(play)
运行之后得到下面的提示,其中最重要的m3u8已经成果获取到,完成任务

