Python数据分析库之pandas,你该这么学!No.1
写这个系列背后的故事
咦,面试系列的把基础部分都写完啦,哈哈答,接下来要弄啥嘞~
pandas吧
外国人开发的
翻译成汉语叫 熊猫

厉害厉害,很接地气
一个基于numpy的库
干啥的?
做数据分析用的
而数据分析是python体系下一个非常庞大的分支
厉害到,好多人一看就会(博主就不是)

博主将用不知道多少篇博客把她给你捣鼓明白(说白了,就是没写大纲!)
当然也可能让你失去对她的兴趣
毕竟,博主叫梦想橡皮擦啊
擦掉你编程的梦想也是我努力的一部分

下载按照这个库
这个库,安装easy
你只要这样,这样,然后在这样,中间出现问题,百度一下,这样,这样,就好了… …
嘿嘿

我其实用的是python3.6版本
然后通过下面的命令安装的
pip install pandas
国内,一般安装比较慢,你添加一个清华大学的源就好了
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple/
下载&安装速度就嗷嗷的了
pandas版本为
pandas 0.23.3
你的版本比我应该高,
毕竟我是老程序员了
pandas官网 http://pandas.pydata.org/
没有翻译完的伪中文网 https://www.pypandas.cn/index.html
安装之后
一番简单的操作之后,如果过程中你没有出现任何BUG
恭喜你,安装成功
下面打开你的任意开发工具
一般我用“被免费版”的pycharm

创建一个文件,然后输入下面的代码,直接run
import pandas
没有报错,完美,一个库学会了
当然,一般写成
import pandas as pd
你就和国际程序员接轨了
pandas主要干啥
如果你英文好,直接打开官方文档
瞅就可以了
如果英语不好,没关系
你这么理解,pandas就像用代码操作excel一样,一样一样的
在pandas中,你要学习一个新的数据结构
Series
百度翻译,恩,先记住发音吧 say 额 瑞 z 多么棒的标注,中英结合。
这是一种什么样的数据结构呢?
在解释这个问题前,我们先创建一个,然后在代码中看看
不就清晰明了了么
编写下面的代码
import pandas as pd
my_series = pd.Series(['我','是','梦想','橡皮擦'])
print(my_series)
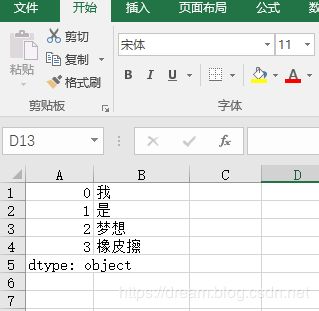
运行结果
0 我
1 是
2 梦想
3 橡皮擦
dtype: object
好像也有看出来了啥?
别着急,弄到excel里面瞅瞅,直接复制就好
看到没,我们通过列表创建了一个series
在excel中,你需要先确定你知道什么是行,什么是列

横着的叫行,竖着的叫列
你通过列表创建series之后,每行的前面出现一个从0开始的序号
这个新出现的序列,记住,叫索引,
既然叫做索引了,那么我们就可以给索引设置值
如果你有编程经验,那么你知道,索引值对应的英文叫做index
every 编程语言索引基本都是设置index
那我们在重写一下
import pandas as pd
my_series = pd.Series(['我','是','梦想','橡皮擦'],index=['a','b','c','d'])
print(my_series)
看一下结果 索引变了吧
a 我
b 是
c 梦想
d 橡皮擦
dtype: object
继续往里面挖,注意index和前面列表的长度一定要一致
什么意思?
pd.Series(['我','是','梦想','橡皮擦'],index=['a','b','c','d','e']) 报错
pd.Series(['我','是','梦想','橡皮擦'],index=['a','b','c']) 报错
声明一个series的函数中,还可以携带一个name参数
请查看
import pandas as pd
my_series = pd.Series(['我','是','梦想','橡皮擦'],index=['a','b','c','d'],name='梦想序列')
print(my_series)
结果瞅瞅
a 我
b 是
c 梦想
d 橡皮擦
Name: 梦想序列, dtype: object
接下来,可以把前面的列表参数也写完整了
import pandas as pd
my_series = pd.Series(data = ['我','是','梦想','橡皮擦'],index=['a','b','c','d'],name='梦想序列')
print(my_series)
总结一下
创建一个series是非常容易的,只需要采用
pd.Series(data=列表,index=列表,name=名称就可以)
其他创建方式
用字典也是可以的
my_series1 = pd.Series({'a':'非本科程序员','b':'公号'})
print(my_series1)
Series里面存储不同类型也是可以的
my_series2 = pd.Series([1,1.2,True,'MyName'])
print(my_series2)
这个Series你把他当成只有一列的excel就好了
咦?有人问了,刚才打印的结果不是2列么
没关系,那个是索引,只是获取值的一个序号罢了
不信,我们获取一下
my_series2 = pd.Series([1,1.2,True,'MyName'])
print(my_series2[0])
打印出来了吧
在试试
import pandas as pd
my_series = pd.Series(data = ['我','是','梦想','橡皮擦'],index=['a','b','c','d'],name='梦想序列')
my_series1 = pd.Series({'a':'非本科程序员','b':'公号'})
my_series2 = pd.Series([1,1.2,True,'MyName'])
print(my_series1['a']) # 通过索引 a 访问到了“非本科程序员”
print(my_series[0]) # 通过索引 0 访问到了“我“,通过my_series['a']依旧可以
这样子,你是不是感觉series跟python中的列表有点相似了呢?
好像还有点字典的感觉
这就对了,下篇见吧
我们会对series继续研究的~
最后,欢迎关注一个唠叨的编程工程师的公号,非本科程序员
你懒得搜,就打开这个链接吧
https://dwz.cn/r4lCXEuL
或者掏出你的手机,拍这个
