Hadoop-DataNode分析
HDFS主要流程
客户端创建到namenode的文件与目录操作
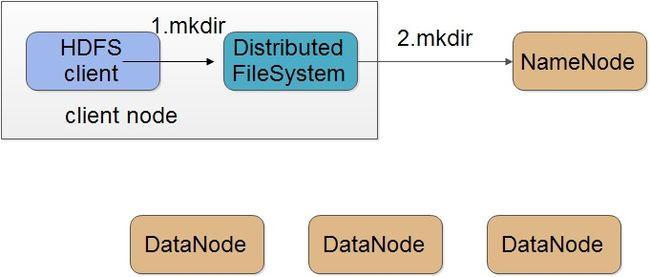
客户端会调用FileSystem实现也就是DistributedFileSystem的mkdir()函数,之后DistributedFileSystem会通过IPC调用namenode的mkdir()
这个操作会持久化到日志中FSImage#saveFSImage(),之后返回
创建目录只是客户端和namenode交互,不会跟datanode交互
删除文件操作
操作类似mkdir(),但是删除操作只是删除namenode中的引用关系,并不会真正删除datanode中的数据,namenode和datanode只是维持简单的主从关系,namenode不会向datanode发起任何IPC操作,datanode的数据删除操作是通过心跳包DatanodeCommand向namenode报告后,然后才删除的
读取文件操作

1)客户端通过DistributedFileSystem打开文件,然后创建输入流FSDataInputStream返回给客户端
对HDFS来说具体的输入流是DFSInputStream,在DFSInputStream的构造函数中,输出流实例通过
2)ClientProtocol#getBlockLocation()以确定文件开始部分数据的保存位置,namenode保存着该副本块中的数据节点地址,通过网络拓扑工具类计算出离客户端最近的节点然后返回
3)之后客户端调用FSDataInputStream#read()读取文件数据,当达到块的末尾时,DFSInputStream会关闭和datanode的连接,然后namenode继续找到文件的后续部 分,依旧是寻找离客户端最近的节点再返回
4)客户端接续读取剩余部分然后通过FSDataInputSrream#close()关闭输入流
5)客户端读取的时候如果发生datanode故障或者网络等问题,会尝试读取下一个数据块的位置(namenode中记录了每个块对应的datanode全部副本,通过链表保存),同时客户端也会记录有问题的datanode
6)读数据的应答包中还包含了校验部分,如果校验有错误,客户端会通知给namenode,之后尝试从其他datanode中读取数据
7)由客户端联系namenode,能够将读取文件引起的数据传输,分散到集群的各个datanode上,这样读取大文件的时候,HDFS集群就可以支持大量的并发客户端,namenode只提供处理数据块定位请求,不提供具体数据
写文件操作
1)客户端调用create()创建文件,此时DistributedFileSystem创建DFSOutputStream,由它向namenode创建一个新的文件,namenode创建文件时需要做各种检查操作,完成后返回DFSOutputStream给客户端
2)写文件时首先向namenode申请数据块也就是调用addBlock(),执行成功后 返回一个LocatedBlock对象,这个对象中包含了新数据块标示和版本号等信息,通过这些信息DFSOutputStream就可以和datanode通讯
3)客户端写入的数据被分成一个个的文件包,放入DFSOutputStream对象内部,最后打包发送给datanode,然后根据流的形式继续发送给后续的datanode节点,其他datanode收到数据后会返回一个应答包,最后全部完成后返回给客户端
4)DFSOputStream写完一个数据块后,所有的datanode会通过DatanodeProtocol远程接口的blockReceived汇报给namenode,向namenode提交数据,为了减轻namenode压力汇报的数据也会放入队列等累积到一定量后再提交。如果客户端的队列中海油数据,DFSOputputStream需要再次调用addBlock()向文件添加新的数据块
5)客户端写完数据后就调用close(),之后DFSOputStream调用ClientProtocol#complete通知namenode关闭文件,这样就完成了一次正常写入文件操作
6)在写入过程中可能会出现一些datanode故障,默认只要有1个datanode写成功就会返程,后续会有定时器扫描到副本数小于3就开启复制
7)写入datanode故障后,写入队列的数据会重新添加到DFSOutputStream队列中,然后重新找一个datanode,新的datanode数据块会赋予新的版本号,之后如果有问题的datanode重启启动后会因为数据块版本号不匹配而删除。
datanode和namenode交互
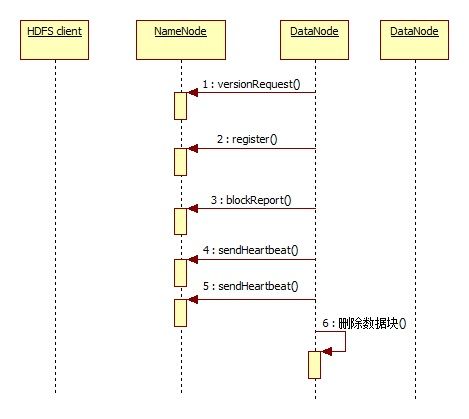
1)datanode启动后会向namenode发送远程调用versionReuqest(),进行版本检查,保证HDFS版本一致
2)之后调用register向namenode注册 ,主要工作也是检查,确认该datanode是不是集群中的成员
3)注册成功后,datanode会将它管理的所有数据块信息,通过blockReport()上报到namenode,帮助namenode建立HDFS文件数据块到datanode节点的映射关系,这一步完成后数据节点才正式提供服务
一般来说只有namenode中的映射完成95%之后才离开安全模式,之间都是只读模式
4)datanode每隔一段时间发送心跳到namenode,如果namenode有一些需要datanode配合的动作,则返回DatanodeCommand数组,它包含一系列指令比如删除数据。datanode收到后就会真正删除数据
命名空间镜像检查点的产生

1)secondarynamenode会通过NamenodeProtocol#getEditLogSize()获取编辑文件大小,如果文件比较小则直接由namenode完成就行了
2)如果文件较大则调用rollEditLog()启动检查点过程,这时namenode会创建一个新的edits.new文件,后续对fsimage的改动都会记录到这个新的日志中
3)之后secondary通过HTTP方式下载fsimage和edits,将两个文件合并保存为fsimage.ckpt
4)namenode通过HTTP方式下载这个合并后的fsimage.ckpt文件
5)namenode将新的fsimage.ckpt覆盖原有的fsimage,同时将edits.new改为edit,这时编辑日志中的内容就是从合并后的fsimage.ckpt基础上增加的了
各节点之间的主要接口

1)客户端和namenode之间的接口 ClientProtocol,是HDFS客户访问文件系统的入口,客户端通过这个接口访问namenode,操作文件或目录打开文件,之后再跟datanode交互
2)客户端和datanode之间的接口,客户端和datanode之间的交互主要通过流接口进行读/写,如果发生错误需要配合namenode完成
3)DatanodeProtocol是datanode和namenode之间的接口,在HDFS集群中,datanode节点通过这个接口不断的向namenode报告一些信息,同步信息到namenode,同时该接口的函数会返回一些信息通过这些信息,datanode会移动,删除,或者恢复磁盘上的数据块
4)InterDatanodeProtocol 这是datanode节点之间的接口,通过这个接口跟其他datanode通讯,恢复数据保证数据一致性
5)NamenodeProtocol 这是secondary跟namenode通讯的接口,secondary会定期获取namenode上的edits文件的变化然后做合并
6)其他比如跟安全相关的RefreshAuthorizationPolicyProtocol和RefreshUsrMappingProtocol
HDFS主要角色类图

datanode目录
| blocksBeingWritten | 该目录保存当前正在写的数据块,和位于tmp目录下保存的正在 写的数据块相比,这个目录写的是由客户端发起的 |
| current | 数据节点管理的最重要目录,保存已经写入HDFS文件系统的数据块, 也就是写操作已经结束的已提交的数据块,该目录还包含一些系统工作时 需要的文件 |
| detach | 用于配合数据节点升级,供数据块分离操作保存临时工作文件 |
| tmp | 该目录页保存着当前正在写的数据块,这里的写是由数据块复制引发的, 另一个数据节点正在发送数据到数据块中 |
| storage | 0.13版本以前的hadoop使用这个名称做目录保存数据块,这样做的目的 是防止旧的hadoop版本在新的集群上启动破坏系统 |
| in_use.lock | 表示目录已经被使用,实现了一种锁机制,如果停止数据节点该文件就会 消失 |
datanode的current目录
这里有数据块和meta后缀的校验信息文件,用来保存数据块的校验信息
当目录块中的数目超过64个,就会新生成一个目录
namenode目录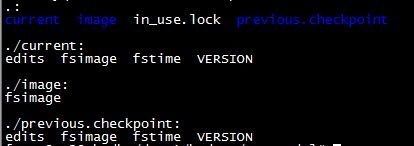
| fsimage | 元数据镜像文件 |
| edits | 日志文件,和元数据镜像文件一起,提供了一个完整 的HDFS目录树及元信息 |
| fstime | 保存了最近一次检查点的时间,检查点一般由第二名字节点 产生,是一次fsimage和对应edits合并的结果 |
| VERSION | 和数据节点类似,该文件保存了名字节点存储的一些属性 |
| in_use.lock | 和数据节点的这个文件功能一样,保存名字节点独占使用该目录 |
| current目录 | 保存了最新的镜像内容 |
| fsimage目录 | 跟current目录一样,是老版本是用的,是为了兼容考虑的 |
| previous.checkpoint目录 | 保存名字及节点的上一次检查点 |
其中fsimage目录和edits目录是可以分开的