Tomcat源码分析---NIO请求处理过程
NIO的启动过程这里就不再介绍了,具体请看《Tomcat源码分析---启动过程》一文。
这里要补充几点,
1.在启动的时候,执行到NioEndpoint#init()方法的最后一行,很不起眼的一句:
selectorPool.open();
也就是调用 NioSelectorPool #open(),它会启动NioBlockingSelector的一个内部类线程BlockPoller,不过很奇怪的事,大多数情况下这个线程并有什么作用。
2.创建Poller线程是和CPU数目有关的:
pollers = new Poller [getPollerThreadCount()];
getPollerThreadCount()就是:
Runtime .getRuntime().availableProcessors();
3.BIO连接器在配置的时候需要指定关联的线程池,但是NIO不管指没指定都会启动一个线程池,它和BIO一样,有一个WorkerStack,
只是这个类永远不会用到。
先来看看一个简略的NIO请求流程:
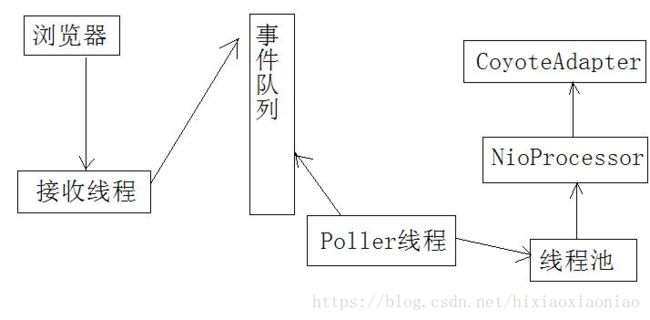
这里一共出现了三个线程,一个接收线程,一个Poller线程,还有工作线程(运行在线程池上)
BIO只有两个线程,一个接收线程,一个工作线程
先来看看Acceptor线程是如何处理的,它的流程很简单
下面是时序图:
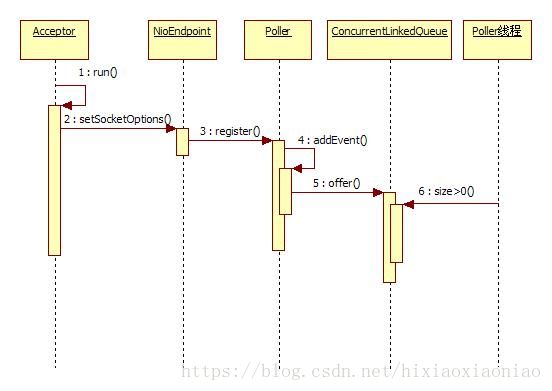
Acceptor接收到请求之后,调用NioEndpoint#setSocketOptions(),此时会将socket设置为非阻塞的,然后创建一个NioChannel,这个类是将SocketChannel和ByteBuffer封装了,可以看做是socket的工具类吧,之后调用Poller#register(),在这个方法里会获取一个KeyAttachment,接着从并发队列中获取一个PollerEvent,再将NioChannel,KeyAttachment作为参数传给PollerEvent。
最后将这个PollerEvent加入到并发队列中。这些操作执行完后Acceptor会坚持是否发生异常,如果有异常就关闭socket,没有就会继续接收请求。所以Acceptor的工作就完成了。
Poller是如何拿到请求的呢?它会从并发队列中不停的取事件,默认情况下并发队列是没有事件的,所以Poller也就没任务执行,上面那个时序图实际上是有两个线程,Acceptor和Poller是两个线程,但是他们都是和并发队列打交道的,一个放一个取,呵呵,这又是典型的生产者消费者模式了。
下面看一下Poller线程处理的时序图:
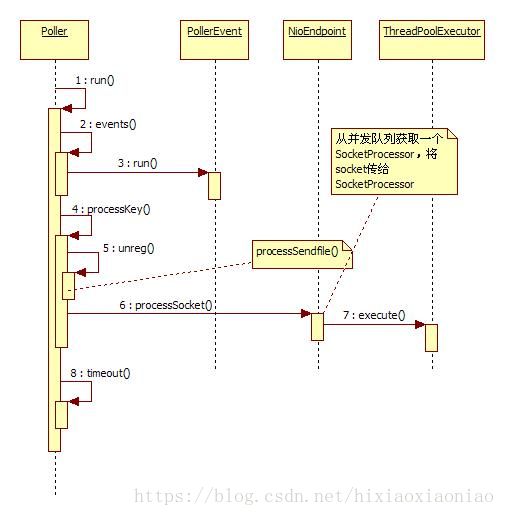
Poller线程的run()会调用自己的events(),检查队列中是否有事件,如果找到了事件,就调用PollerEvent#run(),这里很有意思,PollerEvent是一个线程类,但是却不启动它,直接调用它的run()方法。PollerEvent获取和自己关联的NioChannel,通过NioChannel取得SocketChannel,然后获得关联的Selector,将这个Seleclt注册,并注明是可读,同时将key附带上,这个key就是KeyAttachment,它里面包含了对NioChannel的引用。注册完之后就下面的代码就是读取是否有可用的Selector,注意现在是读不到的,只有等第二次循环的时候才会读到值。当遍历Selector发现有SelectorKey可用了,就调用processKey()。
processKey()方法里判断KeyAttachment是否有关联的文件,如果有调用 processSendfile(),发送文件。之后检查到SelectorKey是可读就,先讲SelectorKey给解注册,这样的好处是下次就不会重复读到这个SelectorKey了。之后再调用NioEndpoint#processSocket()
processSocket()的内容很简单,从队列里取一个SocketProcessor,然后将NioChannel交给它,最后使用JDK的线程池运行这个SocketProcessor。
到此为止,NIO的Poller线程就处理完了,后面就是工作线程要干的事了,现在用一个图总结一下Acceptor和Poller:
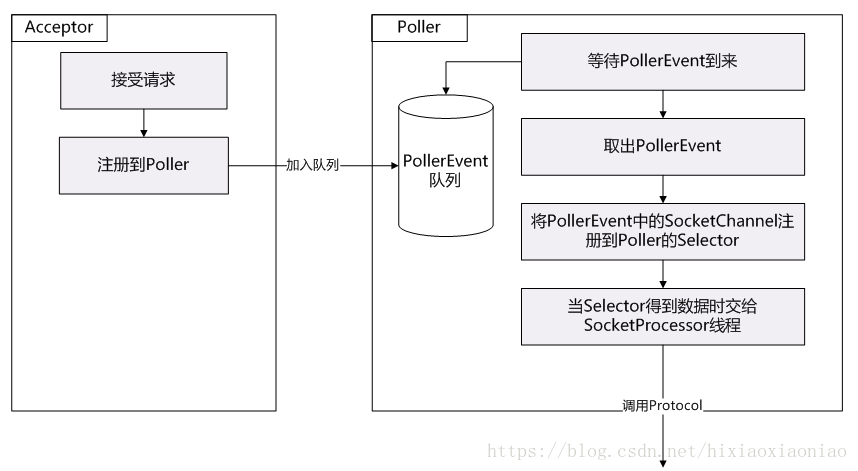
这里最后说明一下,Poller线程获取是不停的获取PollerEvent事件,它是从队列中获取的,那当没有任务来的时候是否会阻塞呢?不会,它会一直运行,Poller是从ConcurrentLinkedQueue中获取任务的,这种队列获取是不会阻塞的,如果没有值就返回null,所以当没有任务的时候会出现CPU空转的。
Accpetor和Poller都介绍完了,下面看看工作线程,也就是NIO处理任务的核心,
NIO请求处理核心过程时序图:
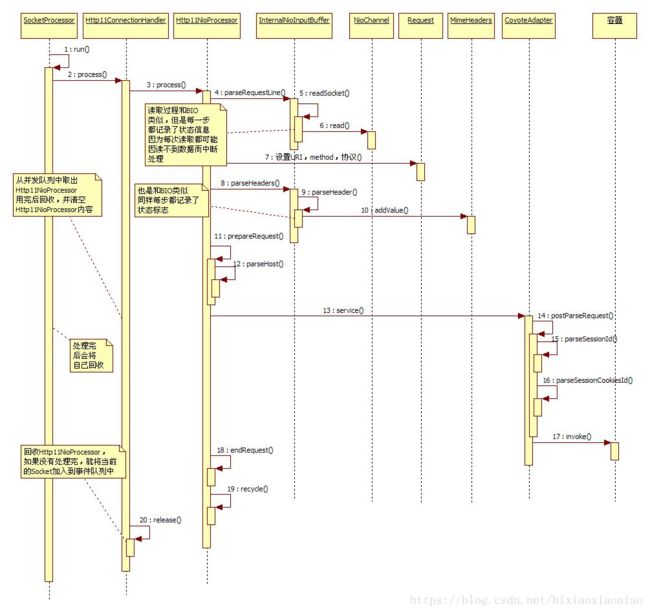
这个就比前面几个要复杂多了,其实NIO和BIO很多类都是一一对应的。
比如:
Http11Protocol ----Http11NioProtocol
Http11Processor----Http11NioProcessor
Http11Protocol $Http11ConnectionHandler ---- Http11NioProtocol$Http11ConnectionHandler
InternalInputBuffer---InternalNioInputBuffer
上面4个对应关系,左边是BIO相关的类,右边是NIO相关的类,他们的功能基本上是差不多的
下面分析核心处理的过程,SocketProcessor就是工作线程了,它是由线程池调用的,这里就省略了线程池了,这个SocketProcessor是可以回收的,它是由并发队列管理的,当处理完后会将自己回收。SocketProcessor会调用Http11NioProtocol$Http11ConnectionHandler#process(),这个内部类首先从并发队列中拿出一个Http11NioProcessor,当然这个Http11NioProcessor也是可以回收的,这个过程和BIO几乎一样,只是有一点不同,它是先从并发map中拿一个Http11NioProcessor,此时如果拿不到就新创建一个。如果是BIO模式下,当Http11Processor处理完后,就被回收了,但NIO不是,因为NIO的线程可能会因为读不到数据而返回,它不会像BIO一样一直等下去。如果Http11NioProcessor已经处理了一些数据了,此时又突然返回,那么它是怎么记住自己和哪个Socket关联的呢?在Http11ConnectionHandler是用并发map关联的,socket作为key,Http11NioProcessor作为值相互关联。
好了,让我们看看最核心的Http11NioProcessor是怎么处理请求的吧,这个过程我们可以参照BIO,因为它的流程和BIO几乎一样,但是请记住,NIO之所以不同BIO在于它每次读取数据都可能会因为读不到而返回,不像BIO那样,读不到会一直等待。
Http11NioProcessor 解析请求行,请求头是调用 InternalNioInputBuffer#parseRequestLine()和parseHeaders()
读取请求行parseRequestLine()时,使用了NioChannel#read(),也就是用SocketChannel#read()去真正的去socket的。这个读取分解请求行的过程可以参照BIO,当解析完后会将请求method,URI,URI的请求参数,HTTP协议号赋给Request(非规范类)。
读取请求头是调用InternalNioInputBuffer#parseHeaders(),这是一个循环解析的过程,它会多次调用自己的parseHeader(),解析每一个请求头,然后将请求头增加到 MimeHeaders上。
现在有很重要的一点要说明,记得反复强调了一点,NIO读取数据会因为读不到而返回,不会一直等待,那么读取请求行解析,请求头解析的时候其中每一次读取都有可能会因为读不到数据而返回,那么NIO连接器是怎么解决这个问题呢? 因为Http11ConnectionHandler实际上是将socket和一个Http11NioProcessor关联了,也就是说一个请求对应一个Http11NioProcessor,新来一个请求就会对应一个不同的Http11NioProcessor,所以我们只要记录下每次解析到哪里了,就算这次会返回,下次再处理的时候就不会重头再来了,会接着上次的记录点继续往下走。
在处理请求行的时候,InternalNioInputBuffer会记录当前执行到哪步了,比如解析完method,解析完URL,解析完URL后面的空格都会记录的。然后读取请求头也会记录位置,读取到请求头一行的name,读取到value,是否后续还有请求头,都有记录,所以不怕被中断。由于每个Http11NioProcessor都包含了Request,Reponse(非规范类),Internal输入输出Buffer,整个这一切都像是绑定的一套,所以就想RPG游戏一样,记录当前位置下次继续执行。
请求行和请求头处理完后,就是预解析请求头了,这里会预先处理一些可以先出去的请求头,比如connection,user-agent,transfer-encoding等请求头,另外外解析主机,着一些处理完后会调用CoyoteAdapter#service(),service()首先调用postParseRequest(),这里主要是设置一下当前请求关联的上下文和包装,然后解析sessionID,首先是调用parseSessionId(),它是先从请求的URL中获取,如果解析成功就将sessionID关联到当前请求的Request(非规范)上,不管有没有获取到还会调用parseSessionCookiesId(),这是从cookie中获取sessionID,如果获取到了就将之前从URL中获取的ID给覆盖。
最后调用invoke()将请求传给容器,这会委托Connector调用第一个valve:
connector.getContainer().getPipeline().getFirst().invoke(request, response);
此时就会开始调用容器部分。
现在补充说明一个安全性的问题,假如有恶意用户故意写了一个程序连接NIO,请求行只写了一半,GET /test/index.html HT
就这样,HT后面就没有了,然后把数据发给服务器,然后关闭自己的程序,此时NIO的处理过程是读取请求行,因为读取不完整,所以推出了,它会要求再次读取,所以设置
openSocket = true;
recycle = false;
也就是不回收,同时将当前的连接设置为长连接,此时Http11ConnectionHandler会将Http11NioProcessor回收,然后将当前的socket作为一个事件加入到事件队列中。那如果这个用户以后用户不执行自己的程序了,这样这个socket就会一直保存在Http11ConnectionHandler的map中不会删除,是这样吗?不是,注意看第三个图,Poller执行的时序图,在Poller#run()的最后会执行一个timeout(),超时检查,它会检查所有超时的任务,会将这个任务删除掉,所以就解决了出错或者恶意的攻击问题了。
读取数据结束了,下面来看看处理数据,也就是写数据的过程,这里会列出几个时序图,分别是设置响应头,将响应头写入缓存,将响应头和响应体合并,最终写数据,以及servlet主动flush()的过程,这里省略了发送超大数据的过程,这个过程NIO处理的很简单,所以在最终写数据里一起概括了,BIO的发送超大数据和NIO的就不同。
首先看一下设置响应头的时序图:

当DefalutSerlet需要设置响应头了,会将这个响应头放通过规范实现的Response,加入到MimeHeaders中。过程很简单
再来看看响应头是如何写入缓存的, 时序图如下:
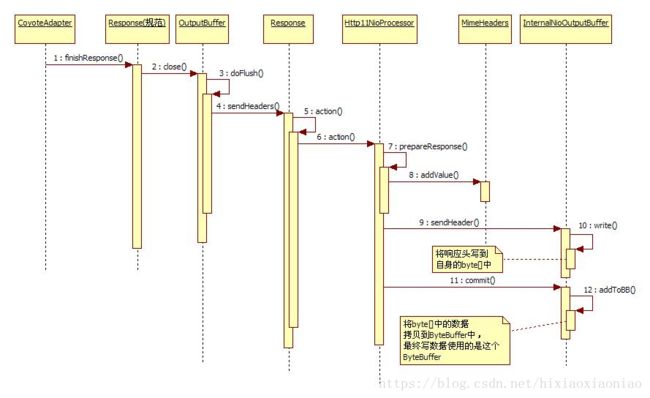
当容器处理完后会返回给CoyoteAdapter,它会调用finishResponse(),处理最终数据,它调用规范Response类的close(),这个类里面保存了一个内部缓存,相当于是容器用的,Tomcat连接器有容器内部缓存和真正写数据时用的缓存两种,此时的OutputBuffer就是容器内部使用的缓存,它首先调用自己的doFlush(),然后会调用到Response(非规范类)的sendHeaders(),这是会有一个回调的触发机制,Reponse会触发Http11NioProcessor的action,根据不同的类型,触发相应的方法。此时Http11NioProcessor会触发自己的
prepareResponse()方法,它将一些响应头增加到MimeHeaders中,然后InternalNioOutputBuffer#sendHeader(),这是会将响应头的内容写入到InternalNioOutputBuffer自己内部的一个byte[]数组中。
写完了之后就返回,像BIO就跟NIO之前的过程几乎一样,但是NIO多了一个commit(),它会将InternalNioOutputBuffer内部byte[]的内容再拷贝到ByteBuffer中,因为NIO最后写数据是要用到ByteBuffer的。
下面是响应头和响应体的合并过程:
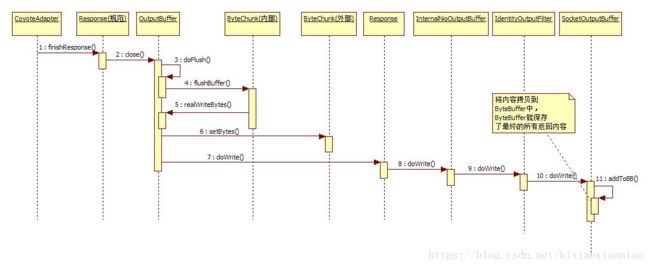
这里的前三部和响应头写入缓存是一样的,第四部变成了调用 ByteChunk#flushBuffer(),注意这个ByteChunk是内部使用的,在OutputBuffer中有两个ByteChunk一个是对内的,相当于用于容器,一个是对外的,真正写数据的时候需要用到这个对外的ByteChunk。内部ByteChunk再调用OutputBuffer,此时OutputBuffer会将内部buffer的内容拷贝到外部buffer中。然后调用Response#doWrite()。Reponse就继续调用InternalNioOutputBuffer#doWrite(),在InternalNioOutputBuffer内部默认会关联一些过滤器,此时会再传到IdentityOutputFilter,再由它传给SocketOutputBuffer,这个类是InternalNioOutputBuffer内部类,它的结构和BIO非常类似,调用这个类的时候会将数据写入到ByteBuffer,它是将响应头和响应体的内容一起写入,最后InternalNioOutputBuffer就会用到这个ByteBuffer真正写数据。
下面是最终写数据的时序图:
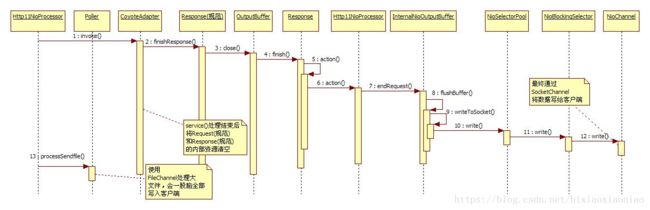
前面几步都很简单,所以从第三部开始,规范Response 调用OutputBuffer#close(),它会调用和它关联的Reponse#finish(),由这个Response执行一个回调事件,这会触发Http11NioProcessor,由它调用InternalNioOutputBuffer#endRequest(),看到这里,BIO和NIO的过程都是类似的,不同的是在于InternalNioOutputBuffer,BIO的的内部缓冲区会直接写到网络,而NIO会再委托其他类继写。
它会将写任务交给NioSelectorPool,然后由它再给NioBlockingSelector,NioBlockingSelector会调用NioChannel,使用SocketChannel真正的像网络写数据。
如果是向网络写文件,比如DOC,JPG,这个文件很大的话,就Http11NioProcessor在循环结束的时候会调用Poller线程的processSendfile(),它会使用FileChannel,一股脑的将这个文件的所有内容都写入网络。
NioSelectorPool只是简单的调用了NioBlockingSelector,真正写数据的主要类是NioBlockingSelector,如果这个写操作不成功,比如写入了0字节,就是什么都没写然后返回了,这样会将这个selectKey当做写事件注册到队列中,但是不清楚是什么地方又再次使用了这个写事件。NioBlockingSelector有一个内部类BlockPoller,这是一个线程类,但是也不清楚它到底在什么地方运行的。
最后来看看servlet主动flush()的过程,下面是时序图:

当servlet调用了flush()后,OutputBuffer会先将响应头和响应体都写入到缓存,这个过程可以参见前面时序图分析的介绍。
关键部分是它会触发一个回调事件,首先通知Response,然后触发Http11NioProcessor,它再调用InternalNioOutputBuffer,然后进行写,写入过程就是和前面写数据过程一样的,所以这个flush()最主要的还是触发了一个事件。
这里要补充几点,
1.在启动的时候,执行到NioEndpoint#init()方法的最后一行,很不起眼的一句:
selectorPool.open();
也就是调用 NioSelectorPool #open(),它会启动NioBlockingSelector的一个内部类线程BlockPoller,不过很奇怪的事,大多数情况下这个线程并有什么作用。
2.创建Poller线程是和CPU数目有关的:
pollers = new Poller [getPollerThreadCount()];
getPollerThreadCount()就是:
Runtime .getRuntime().availableProcessors();
3.BIO连接器在配置的时候需要指定关联的线程池,但是NIO不管指没指定都会启动一个线程池,它和BIO一样,有一个WorkerStack,
只是这个类永远不会用到。
先来看看一个简略的NIO请求流程:
这里一共出现了三个线程,一个接收线程,一个Poller线程,还有工作线程(运行在线程池上)
BIO只有两个线程,一个接收线程,一个工作线程
先来看看Acceptor线程是如何处理的,它的流程很简单
下面是时序图:
Acceptor接收到请求之后,调用NioEndpoint#setSocketOptions(),此时会将socket设置为非阻塞的,然后创建一个NioChannel,这个类是将SocketChannel和ByteBuffer封装了,可以看做是socket的工具类吧,之后调用Poller#register(),在这个方法里会获取一个KeyAttachment,接着从并发队列中获取一个PollerEvent,再将NioChannel,KeyAttachment作为参数传给PollerEvent。
最后将这个PollerEvent加入到并发队列中。这些操作执行完后Acceptor会坚持是否发生异常,如果有异常就关闭socket,没有就会继续接收请求。所以Acceptor的工作就完成了。
Poller是如何拿到请求的呢?它会从并发队列中不停的取事件,默认情况下并发队列是没有事件的,所以Poller也就没任务执行,上面那个时序图实际上是有两个线程,Acceptor和Poller是两个线程,但是他们都是和并发队列打交道的,一个放一个取,呵呵,这又是典型的生产者消费者模式了。
下面看一下Poller线程处理的时序图:
Poller线程的run()会调用自己的events(),检查队列中是否有事件,如果找到了事件,就调用PollerEvent#run(),这里很有意思,PollerEvent是一个线程类,但是却不启动它,直接调用它的run()方法。PollerEvent获取和自己关联的NioChannel,通过NioChannel取得SocketChannel,然后获得关联的Selector,将这个Seleclt注册,并注明是可读,同时将key附带上,这个key就是KeyAttachment,它里面包含了对NioChannel的引用。注册完之后就下面的代码就是读取是否有可用的Selector,注意现在是读不到的,只有等第二次循环的时候才会读到值。当遍历Selector发现有SelectorKey可用了,就调用processKey()。
processKey()方法里判断KeyAttachment是否有关联的文件,如果有调用 processSendfile(),发送文件。之后检查到SelectorKey是可读就,先讲SelectorKey给解注册,这样的好处是下次就不会重复读到这个SelectorKey了。之后再调用NioEndpoint#processSocket()
processSocket()的内容很简单,从队列里取一个SocketProcessor,然后将NioChannel交给它,最后使用JDK的线程池运行这个SocketProcessor。
到此为止,NIO的Poller线程就处理完了,后面就是工作线程要干的事了,现在用一个图总结一下Acceptor和Poller:
这里最后说明一下,Poller线程获取是不停的获取PollerEvent事件,它是从队列中获取的,那当没有任务来的时候是否会阻塞呢?不会,它会一直运行,Poller是从ConcurrentLinkedQueue中获取任务的,这种队列获取是不会阻塞的,如果没有值就返回null,所以当没有任务的时候会出现CPU空转的。
Accpetor和Poller都介绍完了,下面看看工作线程,也就是NIO处理任务的核心,
NIO请求处理核心过程时序图:
这个就比前面几个要复杂多了,其实NIO和BIO很多类都是一一对应的。
比如:
Http11Protocol ----Http11NioProtocol
Http11Processor----Http11NioProcessor
Http11Protocol $Http11ConnectionHandler ---- Http11NioProtocol$Http11ConnectionHandler
InternalInputBuffer---InternalNioInputBuffer
上面4个对应关系,左边是BIO相关的类,右边是NIO相关的类,他们的功能基本上是差不多的
下面分析核心处理的过程,SocketProcessor就是工作线程了,它是由线程池调用的,这里就省略了线程池了,这个SocketProcessor是可以回收的,它是由并发队列管理的,当处理完后会将自己回收。SocketProcessor会调用Http11NioProtocol$Http11ConnectionHandler#process(),这个内部类首先从并发队列中拿出一个Http11NioProcessor,当然这个Http11NioProcessor也是可以回收的,这个过程和BIO几乎一样,只是有一点不同,它是先从并发map中拿一个Http11NioProcessor,此时如果拿不到就新创建一个。如果是BIO模式下,当Http11Processor处理完后,就被回收了,但NIO不是,因为NIO的线程可能会因为读不到数据而返回,它不会像BIO一样一直等下去。如果Http11NioProcessor已经处理了一些数据了,此时又突然返回,那么它是怎么记住自己和哪个Socket关联的呢?在Http11ConnectionHandler是用并发map关联的,socket作为key,Http11NioProcessor作为值相互关联。
好了,让我们看看最核心的Http11NioProcessor是怎么处理请求的吧,这个过程我们可以参照BIO,因为它的流程和BIO几乎一样,但是请记住,NIO之所以不同BIO在于它每次读取数据都可能会因为读不到而返回,不像BIO那样,读不到会一直等待。
Http11NioProcessor 解析请求行,请求头是调用 InternalNioInputBuffer#parseRequestLine()和parseHeaders()
读取请求行parseRequestLine()时,使用了NioChannel#read(),也就是用SocketChannel#read()去真正的去socket的。这个读取分解请求行的过程可以参照BIO,当解析完后会将请求method,URI,URI的请求参数,HTTP协议号赋给Request(非规范类)。
读取请求头是调用InternalNioInputBuffer#parseHeaders(),这是一个循环解析的过程,它会多次调用自己的parseHeader(),解析每一个请求头,然后将请求头增加到 MimeHeaders上。
现在有很重要的一点要说明,记得反复强调了一点,NIO读取数据会因为读不到而返回,不会一直等待,那么读取请求行解析,请求头解析的时候其中每一次读取都有可能会因为读不到数据而返回,那么NIO连接器是怎么解决这个问题呢? 因为Http11ConnectionHandler实际上是将socket和一个Http11NioProcessor关联了,也就是说一个请求对应一个Http11NioProcessor,新来一个请求就会对应一个不同的Http11NioProcessor,所以我们只要记录下每次解析到哪里了,就算这次会返回,下次再处理的时候就不会重头再来了,会接着上次的记录点继续往下走。
在处理请求行的时候,InternalNioInputBuffer会记录当前执行到哪步了,比如解析完method,解析完URL,解析完URL后面的空格都会记录的。然后读取请求头也会记录位置,读取到请求头一行的name,读取到value,是否后续还有请求头,都有记录,所以不怕被中断。由于每个Http11NioProcessor都包含了Request,Reponse(非规范类),Internal输入输出Buffer,整个这一切都像是绑定的一套,所以就想RPG游戏一样,记录当前位置下次继续执行。
请求行和请求头处理完后,就是预解析请求头了,这里会预先处理一些可以先出去的请求头,比如connection,user-agent,transfer-encoding等请求头,另外外解析主机,着一些处理完后会调用CoyoteAdapter#service(),service()首先调用postParseRequest(),这里主要是设置一下当前请求关联的上下文和包装,然后解析sessionID,首先是调用parseSessionId(),它是先从请求的URL中获取,如果解析成功就将sessionID关联到当前请求的Request(非规范)上,不管有没有获取到还会调用parseSessionCookiesId(),这是从cookie中获取sessionID,如果获取到了就将之前从URL中获取的ID给覆盖。
最后调用invoke()将请求传给容器,这会委托Connector调用第一个valve:
connector.getContainer().getPipeline().getFirst().invoke(request, response);
此时就会开始调用容器部分。
现在补充说明一个安全性的问题,假如有恶意用户故意写了一个程序连接NIO,请求行只写了一半,GET /test/index.html HT
就这样,HT后面就没有了,然后把数据发给服务器,然后关闭自己的程序,此时NIO的处理过程是读取请求行,因为读取不完整,所以推出了,它会要求再次读取,所以设置
openSocket = true;
recycle = false;
也就是不回收,同时将当前的连接设置为长连接,此时Http11ConnectionHandler会将Http11NioProcessor回收,然后将当前的socket作为一个事件加入到事件队列中。那如果这个用户以后用户不执行自己的程序了,这样这个socket就会一直保存在Http11ConnectionHandler的map中不会删除,是这样吗?不是,注意看第三个图,Poller执行的时序图,在Poller#run()的最后会执行一个timeout(),超时检查,它会检查所有超时的任务,会将这个任务删除掉,所以就解决了出错或者恶意的攻击问题了。
读取数据结束了,下面来看看处理数据,也就是写数据的过程,这里会列出几个时序图,分别是设置响应头,将响应头写入缓存,将响应头和响应体合并,最终写数据,以及servlet主动flush()的过程,这里省略了发送超大数据的过程,这个过程NIO处理的很简单,所以在最终写数据里一起概括了,BIO的发送超大数据和NIO的就不同。
首先看一下设置响应头的时序图:
当DefalutSerlet需要设置响应头了,会将这个响应头放通过规范实现的Response,加入到MimeHeaders中。过程很简单
再来看看响应头是如何写入缓存的, 时序图如下:
当容器处理完后会返回给CoyoteAdapter,它会调用finishResponse(),处理最终数据,它调用规范Response类的close(),这个类里面保存了一个内部缓存,相当于是容器用的,Tomcat连接器有容器内部缓存和真正写数据时用的缓存两种,此时的OutputBuffer就是容器内部使用的缓存,它首先调用自己的doFlush(),然后会调用到Response(非规范类)的sendHeaders(),这是会有一个回调的触发机制,Reponse会触发Http11NioProcessor的action,根据不同的类型,触发相应的方法。此时Http11NioProcessor会触发自己的
prepareResponse()方法,它将一些响应头增加到MimeHeaders中,然后InternalNioOutputBuffer#sendHeader(),这是会将响应头的内容写入到InternalNioOutputBuffer自己内部的一个byte[]数组中。
写完了之后就返回,像BIO就跟NIO之前的过程几乎一样,但是NIO多了一个commit(),它会将InternalNioOutputBuffer内部byte[]的内容再拷贝到ByteBuffer中,因为NIO最后写数据是要用到ByteBuffer的。
下面是响应头和响应体的合并过程:
这里的前三部和响应头写入缓存是一样的,第四部变成了调用 ByteChunk#flushBuffer(),注意这个ByteChunk是内部使用的,在OutputBuffer中有两个ByteChunk一个是对内的,相当于用于容器,一个是对外的,真正写数据的时候需要用到这个对外的ByteChunk。内部ByteChunk再调用OutputBuffer,此时OutputBuffer会将内部buffer的内容拷贝到外部buffer中。然后调用Response#doWrite()。Reponse就继续调用InternalNioOutputBuffer#doWrite(),在InternalNioOutputBuffer内部默认会关联一些过滤器,此时会再传到IdentityOutputFilter,再由它传给SocketOutputBuffer,这个类是InternalNioOutputBuffer内部类,它的结构和BIO非常类似,调用这个类的时候会将数据写入到ByteBuffer,它是将响应头和响应体的内容一起写入,最后InternalNioOutputBuffer就会用到这个ByteBuffer真正写数据。
下面是最终写数据的时序图:
前面几步都很简单,所以从第三部开始,规范Response 调用OutputBuffer#close(),它会调用和它关联的Reponse#finish(),由这个Response执行一个回调事件,这会触发Http11NioProcessor,由它调用InternalNioOutputBuffer#endRequest(),看到这里,BIO和NIO的过程都是类似的,不同的是在于InternalNioOutputBuffer,BIO的的内部缓冲区会直接写到网络,而NIO会再委托其他类继写。
它会将写任务交给NioSelectorPool,然后由它再给NioBlockingSelector,NioBlockingSelector会调用NioChannel,使用SocketChannel真正的像网络写数据。
如果是向网络写文件,比如DOC,JPG,这个文件很大的话,就Http11NioProcessor在循环结束的时候会调用Poller线程的processSendfile(),它会使用FileChannel,一股脑的将这个文件的所有内容都写入网络。
NioSelectorPool只是简单的调用了NioBlockingSelector,真正写数据的主要类是NioBlockingSelector,如果这个写操作不成功,比如写入了0字节,就是什么都没写然后返回了,这样会将这个selectKey当做写事件注册到队列中,但是不清楚是什么地方又再次使用了这个写事件。NioBlockingSelector有一个内部类BlockPoller,这是一个线程类,但是也不清楚它到底在什么地方运行的。
最后来看看servlet主动flush()的过程,下面是时序图:
当servlet调用了flush()后,OutputBuffer会先将响应头和响应体都写入到缓存,这个过程可以参见前面时序图分析的介绍。
关键部分是它会触发一个回调事件,首先通知Response,然后触发Http11NioProcessor,它再调用InternalNioOutputBuffer,然后进行写,写入过程就是和前面写数据过程一样的,所以这个flush()最主要的还是触发了一个事件。
除了这个事件之外,Http11NioProcessor还有很多事件,甚至还有一个ACK应答事件,它是返回一个100的响应头,没有响应数据,表示服务器可以接受上传大数据(好像是这个意思,从代码来看,确实是真正写了一个响应头回去了)