程序的加载链接和库-内存
Linux的进程内存布局如下图,栈往下生长,堆往上生长

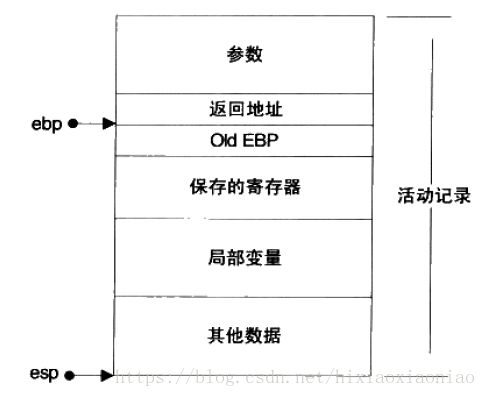
一个典型的栈结构如下
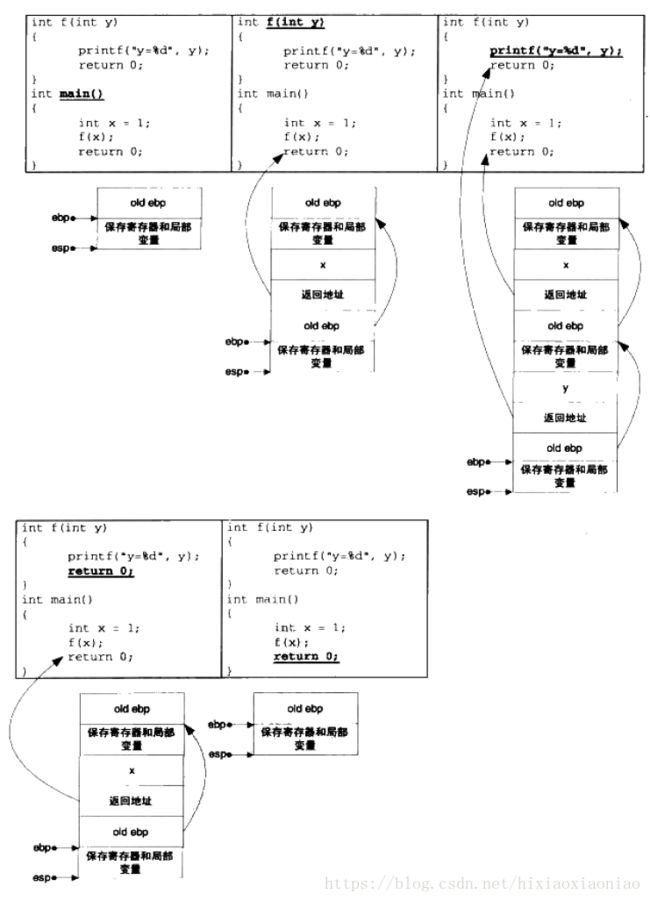
假设一段函数如下
int foo() {
return 123;
}反编译后的结果图如下:

整个执行逻辑如下
1.先保存rbp寄存器,因为rbp,rsp是指向同样位置的,所以push rbp,再将rbp赋给rsp
2.开辟一块新空间,也就是 sub rsp 0xC0H,因为栈是往下生长的所以要减
3.保存寄存器,rbx,rsi,rdi,这一步是可选的
4.加入一些调试信息
5.将返回值赋给rax,这步才是函数中真正的逻辑
6.将保存的寄存器还原,也就是pop rdi,pop rsi等
7.恢复rbp,rsp
8.ret返回函数的值
多个函数调用的关系栈图
对于函数返回一个很大的值,比如几百字节,超过了寄存器容量,参考下面这个例子
typedef struct big_thing {
char buf[128];
}big_thing;
big_thing return_test() {
big_thing b;
b.buf[0] = 0;
return b;
}
int main() {
big_thing n = return_test();
}main函数的反汇编如下:

大致思路是
1.main函数在栈上额外开辟了一篇空间,将这块空间的一部分作为传递返回值的临时对象比如temp
2.将temp对象的地址作为隐藏参数传递给return_test函数
3.return_test函数将数据拷贝给temp对象,并将temp对象的地址用rax传递出来
4.return_test返回之后,main函数将rax指向的temp对象内容拷贝给n
对应的伪代码如下:
void return_test(void* temp) {
big_thing b;
b.buf[0] = 0;
memcpy(temp, &b);
rax = temp;
}
int main() {
big_thing temp;
big_thing n;
return_test(&temp);
memcpy(&n,rax,sizeof(big_thing));
}传递流程如下:

Linux的堆内存申请需要系统调用,从性能上来说频繁的调用系统函数获取内存不好
实际的做法是有个应用程序级别的管理程序,每次需要内存就找个代理程序
这个代理程序会一次性向操作系统批量申请一批内存,然后管理释放内存,等不够了再找系统申请
int brk(void* end_data_segment)
//glic中还有一个sbrk,是对brk的包装,可以传入负数
mmap函数最早是最为映射到某个文件的,当它不映射到某个文件时,这个空间快就是匿名的,就可以用来作为堆使用
void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
//前面两个参数用于申请空间的起始地址和长度
//prot和flag用于设置申请的空间权限(可读,可写,可执行)以及映射类型(文件映射,匿名空间)
//最后两个用于文件映射时指定文件描述符和文件偏移量void *malloc(size_t nbytes) {
void* ret = mmap(0, nbytes, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, 0, 0);
if(ret == MAP_FAILED) {
return 0;
}
return ret;
}堆分配算法
1.空闲链接方式
2.位图,用bit标识一块内存是否被分配,但会出现很多碎片问题
3.对象池
对象池可以使用空闲链表也可以使用对象池
对于glic来说,申请小雨64字节的空闲是使用对象池的方式,而大于12字节是最佳适配算法,大于128K的申请会使用mmap机制


参考
每个程序员都应该了解的内存知识
《程序员的自我修养-链接,加载和库》