CentOS6.5下搭建高可用完全分布式
一、什么是高可用性
“高可用性”(High Availability)通常来描述一个系统经过专门的设计,从而减少停工时间,而保持其服务的高度可用性。
高可用集群是指以减少服务中断时间为目的的服务器集群技术。它通过保护用户的业务程序对外不间断提供的服务,把因软件/硬件/人为造成的故障对业务的影响降低到最小程度。
为此我们在完全分布式系统的基础上加入了ZooKeeper、JournalNode集群,为了提高数据的安全性以及缓解NameNode的工作压力;其次,为了防止NameNode出现意外情况,我们还加入了能替代NameNode工作的另一进程:standbyNameNode;高可用的完全分布式系统有效的解决了NameNode的单点故障问题。
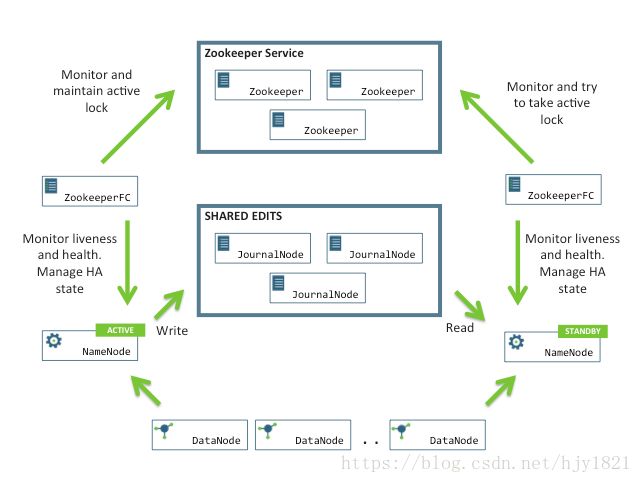
二、配置步骤
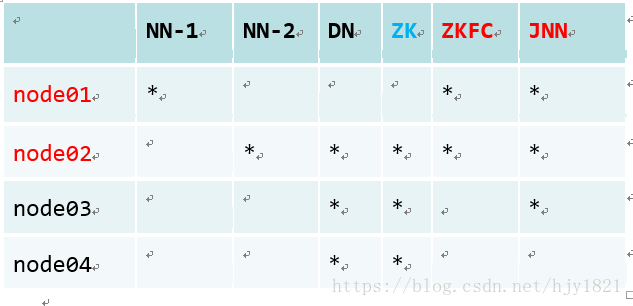
1.集群规划;
2.配置免密登录
node01->node01 node01->node02 node01->node03 node01->node04
node02->node01
将生成的公钥发送到要通信的节点:
1)ssh-keygen -t rsa -P ‘’ -f ~/.ssh/id_rsa -->每个节点都执行
2)在node01节点执行,将node01的公钥加入到其他节点的白名单中
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node01
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node02
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node03
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node04
3.所有节点配置JDK(jdk、防火墙、host文件的更改与配置可见我完全分布式搭建的过程)
4.修改hdfs-site.xml配置文件
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
node01:8020
dfs.namenode.rpc-address.mycluster.nn2
node02:8020
dfs.namenode.http-address.mycluster.nn1
node01:50070
dfs.namenode.http-address.mycluster.nn2
node02:50070
dfs.namenode.shared.edits.dir
qjournal://node01:8485;node02:8485;node03:8485/mycluster
dfs.journalnode.edits.dir
/var/sxt/hadoop/ha/jn
dfs.client.failover.proxy.provider.mycluster org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.automatic-failover.enabled
true
5.修改core-site.xml配置文件
fs.defaultFS
hdfs://mycluster
ha.zookeeper.quorum
node02:2181,node03:2181,node04:2181
hadoop.tmp.dir
/var/abc/hadoop/cluster
- 修改slaves配置文件
修改为node02 node03 node04,此为DataNode节点的确定
修改好后不先把Hadoop包发送到各个节点,要首先配置好zooKeeper
7.搭建zookeeper集群:
(1)解压
(2)修改conf目录下的zoo_sample.cfg的名称,改为zoo.cfg
① mv zoo_sample.cfg zoo.cfg
(3)修改zoo.cfg
① dataDir=/var/zfg/zookeeper
② server.1=node02:2888:3888
③ server.2=node03:2888:3888
④ server.3=node04:2888:3888
(4)在dataDir目录下创建一个myid文件,在这个文件中写上当前节点ID号
(5)将配置好的zookeeper安装包拷贝到node03 node04
(6)拷贝完毕后,在各自节点上创建myid号,ID号要依次递增
8.依次在node02、node03、node04节点上启动zookeeper,启动zookeeper必须优先启动,以便选举出activeNamenode;zookeeper中有一个势力范围的概念,可以有效的解决集群中脑裂的问题。
bin/zkServer.sh start
9.将配置好的HDFS安装包拷贝到node02 node03 node04
scp -r hadoop-2.6.5 root@node02:/opt/software/hadoop/
10.
(1) 格式化NameNode(创建目录以及文件)
① 在node01、node02、node03分别执行如下命令
1) hadoop-daemon.sh start journalnode
journalNode也要先启动,目的是为了将存放元数据的edits文件和fsimage文件初始化准备好。
② 随机选择一台NameNode执行:
1) hdfs namenode -format
2) hadoop-daemon.sh start namenode
③ 另外一台NameNode节点执行:
1) hdfs namenode -bootstrapStandby
(2) 启动zkfc,此进程用于连接zookeeper与NameNode之间,用于监控与改变Namenode的工作状态
hdfs zkfc -formatZK
(3) 关闭所有节点上的进程 stop-dfs.sh
(4) 启动HDFS start-dfs.sh
为使客户端的数据更加安全,防止数据倾斜,我们最好使用集群外操作使用客户端
11.客户端的配置

为什么?

/******************************************************************************************/
分界线 2018-10-17 更新 在高可用的基础上搭建YARN集群
集群规划:
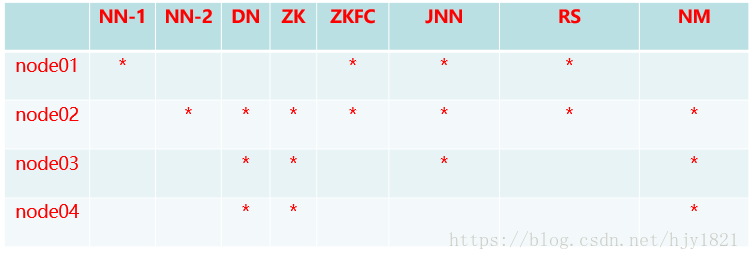
1)首先修改Hadoop下的mapred-site.xml
mapreduce.framework.name
yarn
2)修改Hadoop下的yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
cluster1
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
node01
yarn.resourcemanager.hostname.rm2
node02
yarn.resourcemanager.zk-address
node02:2181,node03:2181,node04:2181
3)将更新后的Hadoop包分别发往各个节点,包括客户端节点
scp -r hadoop-2.6.5 root@node02:/opt/software/hadoop/
4)发送完成后使用正常启动高可用的HDFS集群,然后使用 start-yarn.sh 启动yarn集群;然后在另外一个节点手动启动备用的ResourceManager,命令为:
yarn-daemon.sh start resourcemanager
完成搭建后,可通过“节点名:8088”查看Web监控页面来查看搭建的状态。