北京二手房房价数据集分析
本次分析的数据集来源为链家2017年房源信息。
在数据分析的过程中,我们也可以先去理解数据,再提出问题,在探索数据的过程当中,我们往往会发现很多有趣的事情~
1.提出问题
北京二手房的房价跟哪些因素有关呢?
2.读取数据,理解数据
导入数据分析相关工具包
%matplotlib 为魔法函数,之后的数据可视化过程中,有了它我们就不需要每次都使用plt.show()来显示图表了。

用pandas中的read_csv()方法读取格式为CSV的数据集,并用Head()方法默认查看前5行。
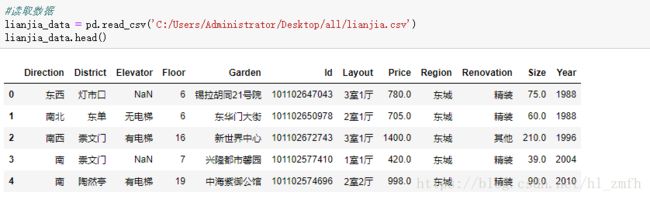
数据类型分析:
1.数值型:Floor,Price,Size,Year
2.字符串类型:Direction,District,Layout,Region,Renovation,Elevato
查看数据类型以及是否存在缺失值
![]()

Elevator 有缺失值
我们可以根据楼层高度判断是否有电梯,然后进行缺失值的填补。

查看数据是否有异常值
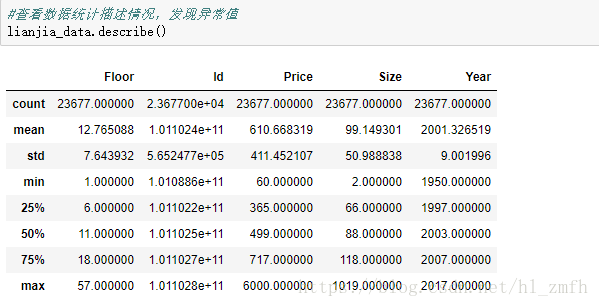
从这里我们发现,房屋楼层最高层竟然有57层,价格中最大值有6000万,而房屋大小中最小的只有2平,这是不符合住房常理的,这就是我们当前发现的异常值,要找到它们并且移除它们。
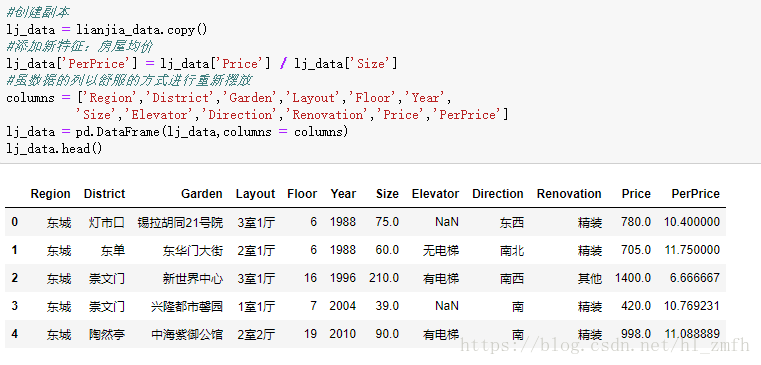
3.数据处理
创建副本,添加房屋均价新特征,并以分析方便的方式重新摆放各列
4.特征分析
分析各区与房价之间的关系:
我们首先按区分类(groupby()方法),各区的住房数量(count()方法),然后再计算按区分类各区的房屋每平均价(mean()方法)。

数据可视化


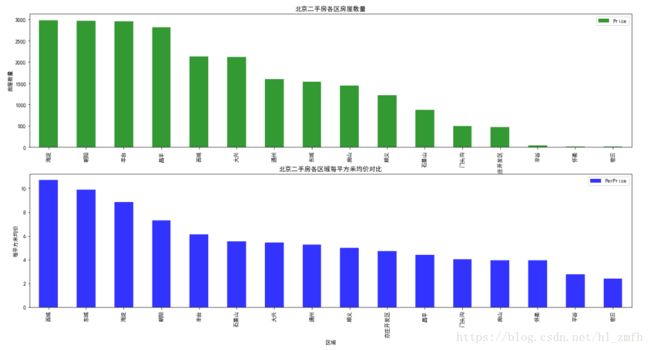
观察数据:
1.海淀区、朝阳区、丰台区、昌平区的房源较多,平谷、怀柔、密云房源较少,说明接近市中心的区房源较多,离市中心较远的区房源较少,也符合常理;
2.西城区、东城区、海淀、朝阳的房价较高,评估、怀柔、密云房价较低,这与房屋越接近市中心,房价越高。
分析房屋大小与房价之间的关系:
我们通过密度图和散点图来分析房屋(Size)特征
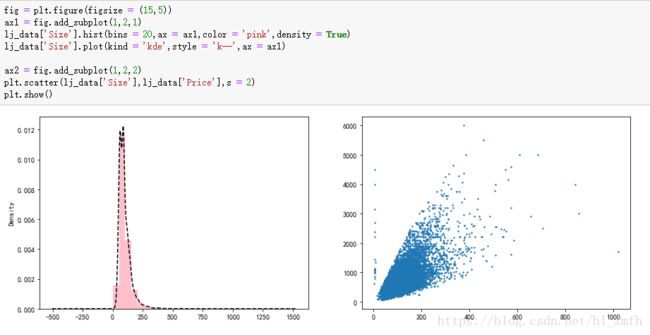
发现问题:
问题1:长尾分布,有很多面积超出正常范围的数据;
问题2:大部分数据符合实际情况,价格随着面积的增大而增大,有异常数据,面积小,价格高。
找出异常点:
我们查找房屋面积小于10或者大于1000的数据
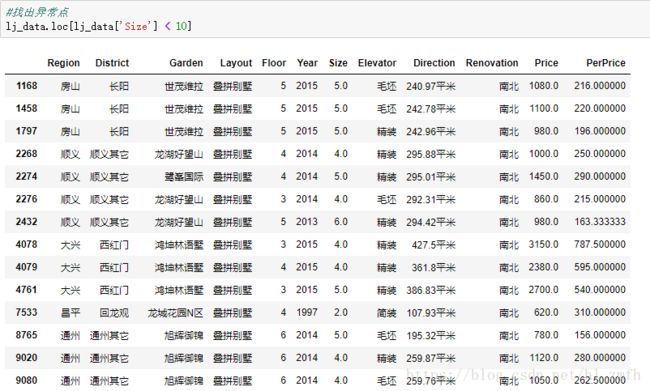

别墅跟商用房都不是我们要考虑的,所要移除这部分数据。
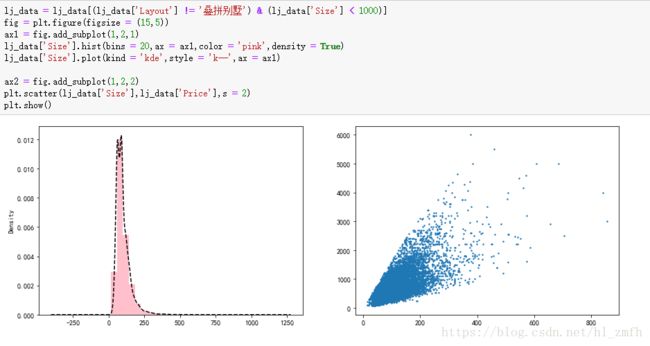
将异常点移除之后,我们观察到,房屋的价格随着房屋面积的增长而增长,呈正相关。
分析房屋布局的数量
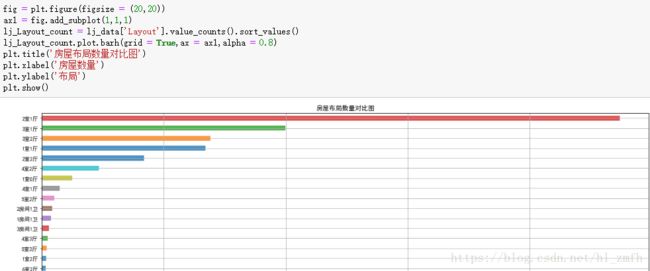
这里我们观察发现,房屋布局为2室1厅的房屋数量最多。
分析房屋价格与装修类型的关系:

数据可视化
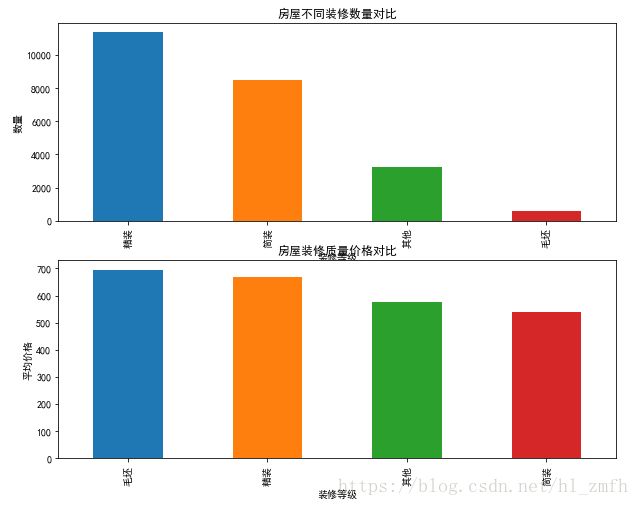
观察数据:
1.精装修和简装修房屋数量最多;
2.毛坯房的均价却最高。
分析有无电梯与房价之间的关系:
查看数据是否有错位的现象
数据可视化

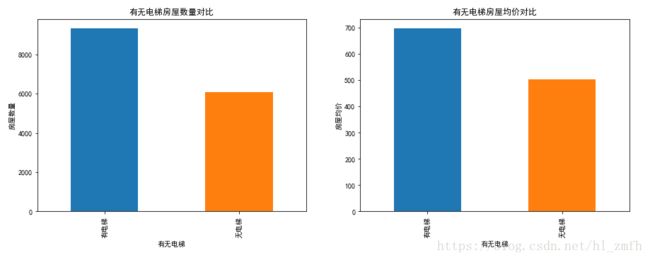
观察数据:
1.有电梯的房屋数量较多;
2.有电梯的房屋均价较高。
分析房屋总体因素随时间的变化

这是一个多维图,点的位置分布表示随着时间的增长房屋价格的变化;
点的数量表示随着时间的增长房屋数量的变化;
点的颜色深浅表示房屋的装修等级;
点的大小表示是否有电梯。

观察结果:
(1)整个二手房价格趋势随着时间增长,尤其在2000年之后大幅增长;
(2)1980年之前电梯房非常少,毛坯房较多;
(3)1980-2000年之间,简装房屋较多,出现电梯房;
(4)2000年之后电梯房较多,精装房屋较多
分析房屋价格与楼层之间的关系:

数据可视化
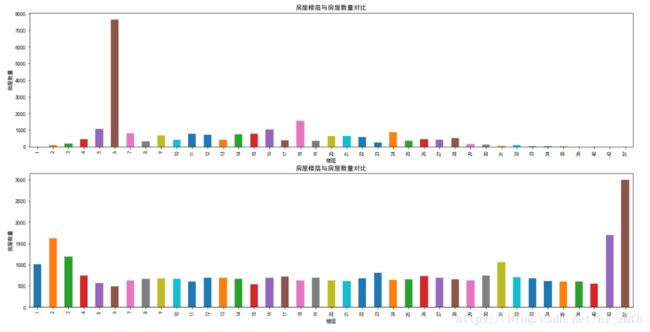
观察数据:
可以看到,6层二手房数量最多,但是单独的楼层特征没有什么意义,因为每个小区住房的总楼层数都不一样,我们需要知道楼层的相对意义。
另外,楼层与文化也有很重要联系,比如中国文化七上八下,七层可能受欢迎,房价也贵,而一般也不会有4层或18层。当然,正常情况下中间楼层是比较受欢迎的,价格也高,底层和顶层受欢迎度较低,价格也相对较低。
所以楼层是一个非常复杂的特征,对房价影响也比较大。