Mysql 面试问题
| 问题 | 答案 |
|---|---|
| ACID | Atomic 原子性:事务中的所有操作,要么全部完成,要么全部不完成,执行错误会回滚 Consistent 一致性:一个事务操作前与操作后的状态一致,事务完成后,符合逻辑运算 Isolated 隔离性:多个事务并发执行,各个事务独立执行一样,其他事务对本次事务的影响 Durable 持久性:事务处理的结果能够被永久保存下来 |
| B树(B-树)、B+树 平衡的多路查找树 参考: https://blog.csdn.net/hla199106/article/details/46770701 |
m阶B树:关键字分部在整颗树中,且出现且只出现在一个结点中 孩子节点数:根节点孩子数[2,m],非根非叶节点孩子数[ceil(m / 2),m] 关键字数:非叶节点关键字数=该节点孩子数-1;叶节点数(即查找失败节点数)= 关键字数+1
m阶B+树:叶子节点包含了整个关键字信息,B树的变形 孩子节点数:与B数一样 关键字数:非叶子结点的孩子书与关键字个数相同 所有叶子结点增加一个链指针
为什么B+数适合做索引 (1)很适合磁盘存储,能够充分利用局部性原理,磁盘预读; (2)很低的树高度,能够存储大量数据; (3)索引本身占用的内存很小; (4)能够很好的支持单点查询,范围查询,有序性查询; |
| 聚簇索引与非聚簇索引 InnoDB并不支持哈希索引 |
聚簇索引:就是指主索引文件和数据文件为同一份文件,Innodb存储引擎主键索引。每个表只能有一个聚簇索引。
非聚簇索引:就是指B+Tree的叶子节点上的data,并不是数据本身,而是数据存放的地址。主索引和辅助索引没啥区别,主要用在MyISAM存储引擎中。 |
| 建索引的几大原则 参考: https://www.cnblogs.com/jiligalaer/p/5609373.html |
1.最左前缀匹配原则 mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配, 比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2 =和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
3 尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例
4 索引列不能参与计算,保持列“干净” 比如from_unixtime(create_time) = ’2014-05-29’ 换成 create_time = unix_timestamp(’2014-05-29’)
5 尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可 |
| 索引失效 参考: https://yq.aliyun.com/articles/568736 |
没有查询条件,或者查询条件没有建立索引 查询条件使用函数在索引列上 like "%_" 百分号在前 != 、 not in 、not exist 、 is not null (注 is null 可以用索引 参考:https://www.jianshu.com/p/3cae3e364946) 范围条件后列上索引失效 对小表查询,查询的数量是大表的大部分 |
| count https://blog.csdn.net/wendychiang1991/article/details/70909958/ |
count()语法: (1)count(*)---包括所有列,返回表中的记录数,相当于统计表的行数,在统计结果的时候,不会忽略列值为NULL的记录。 (2)count(1)---包括所有列,1表示一个固定值,也可以用count(2)、count(3)代替,在统计结果的时候,不会忽略列值为NULL的记录。 (3)count(列名)---只包括列名指定列,返回指定列的记录数,在统计结果的时候,会忽略列值为NULL的记录(不包括空字符串和0),即列值为NULL的记录不统计在内。 (4)count(distinct 列名)---只包括列名指定列,返回指定列的不同值的记录数,在统计结果的时候,在统计结果的时候,会忽略列值为NULL的记录(不包括空字符串和0),即列值为NULL的记录不统计在内。 |
| Mysql 事务隔离级别 参考: InnoDB,快照读,在RR和RC下有何差异?
4种事务的隔离级别,InnoDB如何巧妙实现? |
(1)Serializable:可避免脏读、不可重复读、虚读情况的发生。 (2)Repeatable read:可避免脏读、不可重复读、幻读情况的发生。(可重复读,是 mysql默认的事务隔离级别) (3)Read committed:可避免脏读情况发生。(读取已提交的数据) (4)Read uncommitted:最低级别,以上情况均无法保证。(读取到了未提交的数据)
可重复读:事务中前后两次读,读已修改 幻读:事务中前后两次读,读插入
|
| Mysql 锁 参考: https://blog.csdn.net/zhaozonglu/article/details/82429186 |
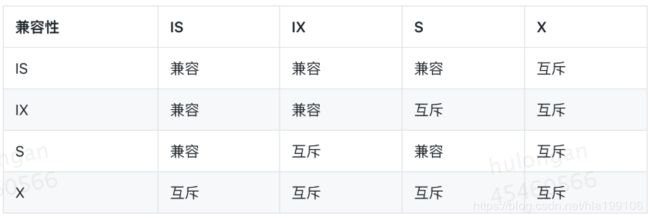
共享锁(S锁、读锁)/排他锁(X锁、写锁)、意向共享锁、意向排他锁
意向锁的意义在哪里? 意向锁之间不会互斥 1.IX,IS是表级锁,不会和行级的X,S锁发生冲突。只会和表级的X,S发生冲突 InnoDB的行锁是基于索引实现的,如果不通过索引访问数据,InnoDB会使用表锁。 意向锁仅仅表明意向,它其实是比较弱的锁,意向锁之间并不相互互斥,而是可以并行
设置共享锁:SELECT … LOCK IN SHARE MODE;
对于普通select 语句,innodb不会加任何锁 ,快照读 MVCC只在RR和RC两个隔离级别下工作 自增锁:是一种特殊的表级别锁 记录锁,它封锁索引记录 select * from t where id=1 for update; 它会在id=1的索引记录上加锁,以阻止其他事务插入,更新,删除id=1的这一行 间隙锁,它封锁索引记录中的间隔,select * from t where id between 8 and 15 for update;防止其他事务在间隔中插入数据,以导致“不可重复读”。读提交(Read Committed, RC),间隙锁则会自动失。 临键锁,是记录锁与间隙锁的组合,它的封锁范围,既包含索引记录,又包含索引区间。临键锁的主要目的,也是为了避免幻读(Phantom Read) 插入意向锁:是间隙锁(Gap Locks)的一种(所以,也是实施在索引上的);多个事务,在同一个索引,同一个范围区间插入记录时,如果插入的位置不冲突,不会阻塞彼此 |
| 各种SQL到底加了什么锁?
参考: 别废话,各种SQL到底加了什么锁
|
普通select: 在 RU,RC,RR 隔离级别下 使用快照读 ,不加锁,并发非常高;串行化 升级为S锁
加锁select:唯一索引 上使用记录锁;其他的查询条件和索引条件 并使用间隙锁与临键锁,避免索引范围区间插入记录;
update与delete:唯一索引上 使用记录锁;符合查询条件的索引记录之前 排他临键锁;update的是聚集索引记录,普通索引记录也会被隐式加锁;
insert:排它锁封锁被插入的索引记录,而不会封锁记录之前的范围;会在插入区间加插入意向锁不会阻止相同区间的不同KEY插入; |
| MyISAM 与 InnoDB 参考: InnoDB,5项最佳实践,知其所以然?
|
关于count(*) : MyISAM会直接存储总行数,InnoDB则不会,需要按行扫描;只有查询全表的总行数,MyISAM才会直接返回结果,当加了where条件后,两种存储引擎的处理方式类似 关于全文索引:MyISAM支持全文索引,InnoDB5.6之前不支持全文索引,5.6支持 关于事务:MyISAM不支持事务,InnoDB支持事务;小技巧:MyISAM可以通过lock table表锁,来实现类似于事务的东西(不推荐) 关于外键:MyISAM不支持外键,InnoDB支持外键 关于行锁与表锁:MyISAM只支持表锁,InnoDB可以支持行锁;InnoDB的行锁是实现在索引上的,而不是锁在物理行记录上。潜台词是,如果访问没有命中索引,也无法使用行锁,将要退化为表锁 关于索引:都是B+树实现的索引,InnoDB是聚集索引,MyISAM是非聚集索引 |
| InnoDB 为何并发如此高 参考: InnoDB并发如此高,原因竟然在这?
|
(1)常见并发控制保证数据一致性的方法有锁,数据多版本; (2)普通锁串行,读写锁读读并行,数据多版本读写并行; (3)redo日志保证已提交事务的ACID特性,设计思路是,通过顺序写替代随机写,提高并发; 数据库事务提交后,将修改行为先写到redo日志里(此时变成了顺序写) (4)undo日志用来回滚未提交的事务,它存储在回滚段里; 数据库事务未提交时,会将事务修改数据的镜像(即修改前的旧版本)存放到undo日志里 (5)InnoDB是基于MVCC的存储引擎,它利用了存储在回滚段里的undo日志,即数据的旧版本,提高并发; (6)InnoDB之所以并发高,快照读不加锁(回滚段里的数据,其实是历史数据的快照); (7)InnoDB所有普通select都是快照读; |
| InnoDB页 | 将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,InnoDB中页的大小一般为 16 KB |
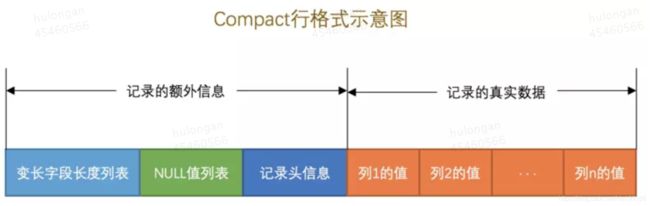
| InnoDB行格式 | COMPACT行格式:
Redundant行格式 Dynamic和Compressed行格式 |
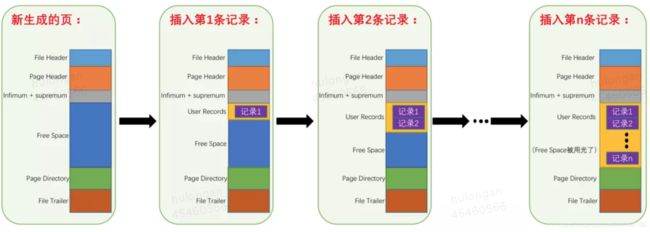
| InnoDB页结构 |
|
| explan 执行计划 https://blog.csdn.net/jiadajing267/article/details/81269067 |
 |
| SQL注入漏洞产生的原因?如何防止? | 程序开发过程中不注意规范书写sql语句和对特殊字符进行过滤,导致客户端可以通过全局变量POST和GET提交一些sql语句正常执行 防止SQL注入的方式: 开启配置文件中的magic_quotes_gpc 和 magic_quotes_runtime设置 执行sql语句时使用addslashes进行sql语句转换 Sql语句书写尽量不要省略双引号和单引号。 过滤掉sql语句中的一些关键词:update、insert、delete、select、 * 。 提高数据库表和字段的命名技巧,对一些重要的字段根据程序的特点命名,取不易被猜到的。 控制错误信息,不要在浏览器上输出错误信息,将错误信息写到日志文件中。 |
| char和varchar的区别 | char是一种固定长度的类型,varchar则是一种可变长度的类型 char(M)类型的数据列里,每个值都占用M个字节,如果某个长度小于M,MySQL就会在它的右边用空格字符补足 在varchar(M)类型的数据列里,每个值只占用刚好够用的字节再加上一个用来记录其长度的字节(即总长度为L+1字节)
varchar得适用场景: 1.字符串列得最大长度比平均长度大很多 2.字符串很少被更新,容易产生存储碎片 3.使用多字节字符集存储字符串
char得场景: 存储具有近似得长度(md5值,身份证,手机号),长度比较短小得字符串(因为varchar需要额外空间记录字符串长度),更适合经常更新得字符串,更新时不会出现页分裂得情况,避免出现存储碎片,获得更好的io性能 |
| 存储时期 | Datatime:以 YYYY-MM-DD HH:MM:SS 格式存储时期时间,精确到秒,占用8个字节得存储空间,datatime类型与时区无关
Timestamp:以时间戳格式存储,占用4个字节,范围小1970-1-1到2038-1-19,显示依赖于所指定得时区,默认在第一个列行的数据修改时可以自动得修改timestamp列得值
Date:(生日)占用得字节数比使用字符串.datatime.int储存要少,使用date只需要3个字节,存储日期月份,还可以利用日期时间函数进行日期间得计算
Time:存储时间部分得数据 注意:不要使用字符串类型来存储日期时间数据(通常比字符串占用得储存空间小,在进行查找过滤可以利用日期得函数) 使用int存储日期时间不如使用timestamp类型 |
| left join 、right join 、inner join | A left join B on A.id=B.id 返回A所有数据B符合条件的数据不足补null A right join B on A.id=B.id 返回B所有数据A符合条件数据不足补null A inner join B on A.id=B.id 返回符合条件的数据 Mysql不支持FULL JOIN 用 UNION ALL 代替 (取A、B 所有数据) |
| union和union all | UNION 操作符合并两个或多个 SELECT 语句的结果。
UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
Union All:对两个结果集进行并集操作,包括重复行,不进行排序; |
| group by、order by、having | order by 一般是用来,依照查询结果的某一列(或多列)属性,进行排序 DESC降 ASC升 null 看成无穷大 group by 按照查询结果集中的某一列(或多列),进行分组,值相等的为一组
细化集函数(count,sum,avg,max,min)的作用对象: 未对查询结果分组,集函数将作用于整个查询结果。 对查询结果分组后,集函数将分别作用于每个组。
在sql命令格式使用的先后顺序上,group by 先于 order by,rder by的字段必须是group by 里面已经存在的字段 having 作用于组,从中选择满足条件的组 |
| InnoDB调试死锁的方法 MySQL5.6 参考 超赞,InnoDB调试死锁的方法! |
区间锁是否关闭 innodb_locks_unsafe_for_binlog 设置为ON,表示关闭区间锁 查询 show global variables like "innodb_locks%" 事务自动提交是否关闭 show global variables like "autocommit" ON 表示autocommit开启 事务的隔离级别 show global variables like "tx_isolation" set session transaction isolation level X
查看锁的情况:show engine innodb status
共享排他锁死锁(并发量插入相同记录) : A插入3 B插入 3 C插入3 此时A回滚,B C死锁 (InnoDB有死锁检测机制,B和C中的一个事务会插入成功,另一个事务会自动放弃) 并发间隙锁的死锁: |
| 主键与唯一索引约束 参考: MySQL不为人知的主键与唯一索引约束 |
即是 插入或更新 主键或唯一索引 对于主键与唯一索引约束:
|
| sql 慢查询 | 1.开启慢查询 查询慢查询配置: show variables like '%slow%' slow_query_log (OFF 关闭慢查询) log_slow_queries(OFF 慢查询log日志关闭) slow_query_log_file (慢查询log日志路径)
2.设置慢查询时间 long_query_time 默认10s
3. 显示慢查询次数 show status like 'slow_queries' |
| 分库分表 | 解决问题:高并发、数据量大 带来收益:并发支撑提升;磁盘使用降低;SQL 执行性能
分库分表中间件: Sharding-jdbc(client 层方案-zebra) :不用部署,运维成本低,不需要代理层的二次转发请求,性能很高;客户端耦合,遇到组件升级得统一去处理 Mycat(proxy 层方案):对项目是透明的;缺点在于需要部署
分库分表方案:停机迁移方案;双写迁移方案 计划还需要几台数据库服务器,每台服务器上几个库,每个库多少个表;选好路由规则 如hash;选好数据库中间件;选择双写大方案就行迁移;发布上线后做好后续数据检查。 |
| 主从复制 | 主库binlog线程:主库将变更写入 binlog 日志 从库IO线程:将主库的 binlog 日志拷贝到自己本地,写入一个 relay 中继日志 SQL 线程:从中继日志读取 binlog,然后执行 binlog 日志中的内容,将更改在数据库中重放 主从延时问题解决: 半同步复制(解决主库数据丢失问题):强制将数据同步到从库,从库会有ack机制 并行复制(解决主从同步延时问题):从库开启多个线程,并行读取 relay log 中不同库的日志,然后并行重放不同库的日志
主从复制会遇到的问题:高并发下,插入之后立即查 解决方案:分库降低并发量;打开并行复制降低延时;业务方重写代码;读主库; |