在kubernetes集群上使用ks搭建kubeflow
安装ks:
$ wget https://github.com/ksonnet/ksonnet/releases/download/v0.9.2/ks_0.9.2_linux_amd64.tar.gz
$ tar xvf ks_0.11.0_linux_amd64.tar.gz
$ sudo cp ks_0.11.0_linux_amd64/ks /usr/local/bin/
$ ks version
ksonnet version: 0.11.0
初始化ks应用程序目录:
$ ks init my_kubeflow
安装kubeflow套件到ks应用程序
$ cd my_kubeflow
$ export GITHUB_TOKEN=99510f2ccf40e496d1e97dbec9f31cb16770b884
#$ ks registry add kubeflow github.com/kubeflow/kubeflow/tree/master/kubeflow
$ks registry add kubeflow github.com/katacoda/kubeflow-ksonnet/tree/master/kubeflow
$ ks pkg install kubeflow/argo
$ ks pkg install kubeflow/core
$ ks pkg install kubeflow/seldon
$ ks pkg install kubeflow/tf-serving
另外一种安装方式,指定版本:
$ cd my_kubeflow
$ ks registry add kubeflow github.com/kubeflow/kubeflow/tree/master/kubeflow
$ VERSION=v0.1.2
$ ks pkg install kubeflow/core@${VERSION}
$ ks pkg install kubeflow/tf-serving@${VERSION}
$ ks pkg install kubeflow/tf-job@${VERSION}
另外一种安装方式,指定0.4.1版本:
ks init my-kubeflow
cd my-kubeflow
VERSION=v0.4.1
ks registry add kubeflow github.com/kubeflow/kubeflow/tree/${VERSION}/kubeflow
ks pkg install kubeflow/jupyter@${VERSION}
ks pkg install kubeflow/tf-serving@${VERSION}
ks pkg install kubeflow/tf-training@${VERSION}
ks apply ${KF_ENV} -c jupyter
然后建立 Kubeflow 核心组件,该组件包含 JupyterHub 和 TensorFlow job controller:
kubectl create namespace kubeflow
kubectl create clusterrolebinding tf-admin --clusterrole=cluster-admin --serviceaccount=default:tf-job-operator
ks env add kubeflow
ks env set kubeflow --namespace kubeflow
ks env list
ks generate kubeflow-core kubeflow-core --name=kubeflow-core --namespace=kubeflow
ks apply kubeflow -c kubeflow-core
PODNAME=`kubectl get pods --namespace=kubeflow --selector="app=tf-hub" --output=template --template="{{with index .items 0}}{{.metadata.name}}{{end}}"`
此时转入后台执行,但是可以发现很多pod状态不对:

可以通过:
kubectl -n kubeflow describe pod pod_name查看pod的状态:

可以发现出错在image的获取上,根本原因还是GFW的问题。
手动下载ambassador镜像:
Docker pull quay.io/datawire/ambassador:0.30.1
docker tag svendowideit/ambassador quay.io/datawire/ambassador:0.30.1
下载tf-operator镜像:
docker pull quelle/tf_operator:v0.2.0
通过kubectl -n kubeflow edit pod tf-job-dashboard-87bb756b7-tj6v6查看yaml文件里面用到的tf-operator镜像的信息
然后通过:
docker tag quelle/tf_operator:v0.2.0 gcr.io/kubeflow-images-public/tf_operator:v0.2.0
匹配对应的版本
下载jupyterhub-k8s镜像:
docker pull lcax200000/jupyterhub-k8s:v20180531-3bb991b1
docker tag lcax200000/jupyterhub-k8s: :v20180531-3bb991b1gcr.io/kubeflow/jupyterhub-k8s:v20180531-3bb991b1
同样使用docker tag命令改变镜像的版本信息,匹配yaml文件里面指定的版本信息
下载centraldashboard镜像:
Docker pull lowyard/centraldashboard:v0.2.1
Docker tag lowyard/centraldashboard:v0.2.1 gcr.io/kubeflow-images-public/centraldashboard:v0.2.1
最终的状态:

在启动过程中有时会遇到ambassador服务一致处于crash状态,这个跟网络有关,通过
kubectl logs --namespace=kubeflow ambassador-68954d75f4-l5zzs -c ambassador命令查看log输出可以得到以下信息,主要是该服务无法访问kubernaut.io 的443端口,与当前网络有关,解决方法:
1) 执行 iptables -P FORWARD ACCEPT,并可通过ping kubernaut.io 和telnet kubernaut.io 443检查网络
2)wget https://kubernaut.io/scout
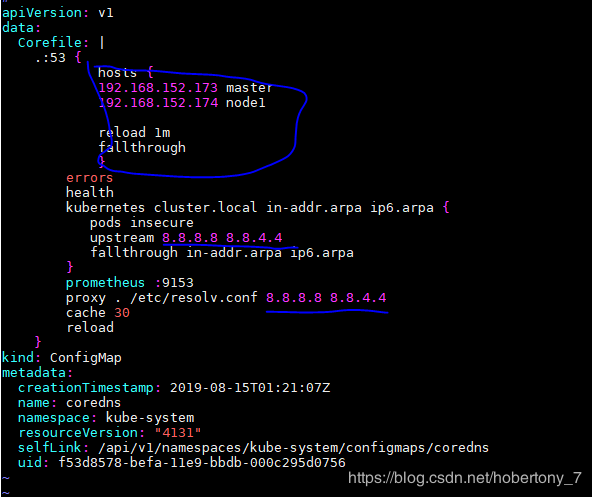
3)在coredns的yaml文件中加入对ip 和 hostname的静态解析
kubectl edit configmap coredns -n kube-system
修改完成后重启coredns pod
4)如果都没问题可以尝试使用如下命令重启ambassador pod:
kubectl get pod ambassador -n kubeflow -o yaml | kubectl replace --force -f -

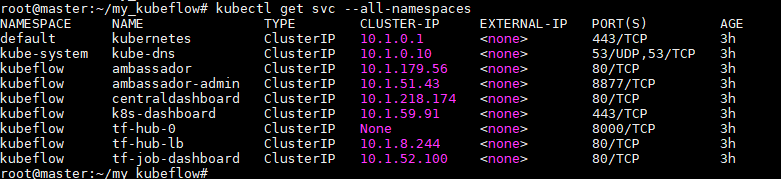
这时候可以使用cluster ui访问不同的服务,这里使用nodeport,把相应的端口映射到主机master上的特定端口:
$ kubectl -n kubeflow edit svc tf-hub-lb
...
![]()
![]()

通过nodeport把端口暴露给master端口,通过127.0.0.1:port访问
Tf-hub-lb服务:
访问mster_ip:30883即可访问tf-hub-lb服务

tf-job-dashboard服务访问:
访问mster_ip:31853即可访问tf-job-dashboard服务

Centraldashboard服务访问:
访问mster_ip:30177即可访问Centraldashboard服务
刪除kubeflow
kubectl delete namespace kubeflow -n kubeflow
至此,搭建工作完成
测试:
docker pull registry.aliyuncs.com/kubeflow-images-public/tensorflow-notebook-cpu
下载notebook镜像
kubectl port-forward svc/ambassador -n ${NAMESPACE} 8080:80
测试一:
利用TFjob测试tensorflow模型的训练:
创建tfjob的yaml文件,并通过改yaml生成对应的pod,该镜像主要做一个很简单的tensorflow程序:向量乘法,并输出结果:
#kubectl apply -f ~/example.yaml && kubectl get tfjob && kubectl get pods

手动下载gcr.io/tf-on-k8s-dogfood/tf_sample:dc944ff镜像:
#docker pull benni82/tf_sample:dc944ff
Docker tag benni82/tf_sample:dc944ff gcr.io/tf-on-k8s-dogfood/tf_sample:dc944ff
Example.yaml:

通过下属命令查看上述实例的计算结果:
kubectl get pods --no-headers -o go-template --template '{{range .items}}{{.metadata.name}}{{"\n"}}{{end}}' | grep master | xargs kubectl logs -f
kubectl get pod coredns-78fcdf6894-wn78c -n kube-system -o yaml | kubectl replace --force -f -
测试二:
使用tensorflow-notebook-cpu编写代码执行,其实就是利用tensorflow-1.8.0-notebook-cpu:v0.2.1
Docker pull registry.aliyuncs.com/kubeflow-images-public/tensorflow-notebook-cpu
Docker tag registry.aliyuncs.com/kubeflow-images-public/tensorflow-notebook-cpu gcr.io/kubeflow-images-public/tensorflow-1.8.0-notebook-cpu:v0.2.1
启动jupyter notebook,notebook的运行需要kubernetes pv的支持,所以需要自己在集群中创建pv, 测试过程中我们使用nfs系统创建pv:

使用kubectl apply –f pv.yaml命令创建 名字为notebook-pv的pv存储,存储使用nfs系统, 存储目录在192.168.152.173主机下的/nfs-data/kubeflow-pv2/目录下:

点击提交按钮,在此过程中会下载notebook镜像,如果没有提前下载该过程会比较慢,下载完成后就会出现熟悉的jupyter界面了:

现在我们就可以像在“单机版”里那样编写代码了。
每个Jupyter Notebook都运行在一个独立的Docker容器中,用户之间不会互相干扰,还可以通过New按钮创建一个Terminal
登陆到容器内部操作。
测试三:
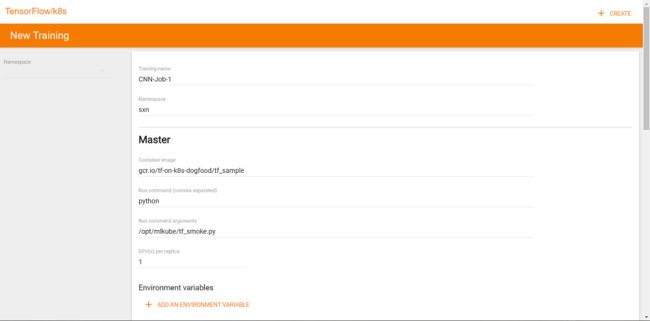
Kubeflow提供了一个分布式训练的发起页面,在该页面填写训练名称、镜像地址、入口程序、所需资源和节点数等参数即可发起训练:
发起训练之后还可以通过Web页面查看运行状态,在这个页面中可以看到kubeflow通过镜像创建了一系列的容器,每个容器即为训练集群的一个节点