NLP TASK9 Attention原理
任务
基本的Attention原理。
HAN的原理(Hierarchical Attention Networks)。
利用Attention模型进行文本分类。
学习笔记
Attention原理
Attention是一种用于提升基于RNN(LSTM或GRU)的Encoder + Decoder模型的效果的的机制(Mechanism),一般称为Attention Mechanism。Attention Mechanism目前非常流行,广泛应用于机器翻译、语音识别、图像标注(Image Caption)等很多领域。Attention Mechanism可以帮助模型对输入的X每个部分赋予不同的权重,抽取出更加关键及重要的信息,使模型做出更加准确的判断,同时不会对模型的计算和存储带来更大的开销,这也是Attention Mechanism应用如此广泛的原因。Attention模块图解:
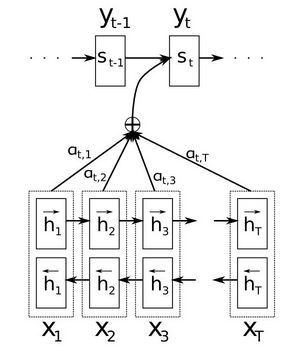
传统的Seq2Seq模型,想要解决的主要问题是,如何把机器翻译中,变长的输入X映射到一个变长输出Y的问题,但是该方法存在一个问题就是对输入序列X缺乏区分度。Attenction就可以用来解决该问题,通过计算 a t a_t at就将输入序列赋予不同重要性。
HAN的原理(Hierarchical Attention Networks)
Zichao Yang等人在论文《Hierarchical Attention Networks for Document Classification》提出了Hierarchical Attention用于文档分类。Hierarchical Attention构建了两个层次的Attention Mechanism,第一个层次是对句子中每个词的attention,即word attention;第二个层次是针对文档中每个句子的attention,即sentence attention。网络结构如图所示:
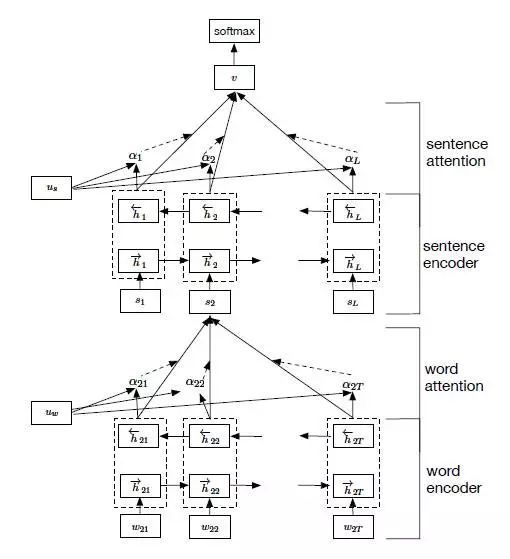
整个网络结构由四个部分组成:一个由双向RNN(GRU)构成的word sequence encoder,然后是一个关于词的word-level的attention layer;基于word attention layar之上,是一个由双向RNN构成的sentence encoder,最后的输出层是一个sentence-level的attention layer。
Attenction文本分类范例
#Attention模块代码
#! -*- coding: utf-8 -*-
from keras import backend as K
from keras.engine.topology import Layer
class Position_Embedding(Layer):
def __init__(self, size=None, mode='sum', **kwargs):
self.size = size # 必须为偶数
self.mode = mode
super(Position_Embedding, self).__init__(**kwargs)
def call(self, x):
if (self.size == None) or (self.mode == 'sum'):
self.size = int(x.shape[-1])
batch_size, seq_len = K.shape(x)[0], K.shape(x)[1]
position_j = 1. / K.pow(10000., 2 * K.arange(self.size / 2, dtype='float32') / self.size)
position_j = K.expand_dims(position_j, 0)
position_i = K.cumsum(K.ones_like(x[:, :, 0]), 1) - 1 # K.arange不支持变长,只好用这种方法生成
position_i = K.expand_dims(position_i, 2)
position_ij = K.dot(position_i, position_j)
position_ij = K.concatenate([K.cos(position_ij), K.sin(position_ij)], 2)
if self.mode == 'sum':
return position_ij + x
elif self.mode == 'concat':
return K.concatenate([position_ij, x], 2)
def compute_output_shape(self, input_shape):
if self.mode == 'sum':
return input_shape
elif self.mode == 'concat':
return (input_shape[0], input_shape[1], input_shape[2] + self.size)
class Attention(Layer):
def __init__(self, nb_head, size_per_head, **kwargs):
self.nb_head = nb_head
self.size_per_head = size_per_head
self.output_dim = nb_head * size_per_head
super(Attention, self).__init__(**kwargs)
def build(self, input_shape):
self.WQ = self.add_weight(name='WQ',
shape=(input_shape[0][-1], self.output_dim),
initializer='glorot_uniform',
trainable=True)
self.WK = self.add_weight(name='WK',
shape=(input_shape[1][-1], self.output_dim),
initializer='glorot_uniform',
trainable=True)
self.WV = self.add_weight(name='WV',
shape=(input_shape[2][-1], self.output_dim),
initializer='glorot_uniform',
trainable=True)
super(Attention, self).build(input_shape)
def Mask(self, inputs, seq_len, mode='mul'):
if seq_len == None:
return inputs
else:
mask = K.one_hot(seq_len[:, 0], K.shape(inputs)[1])
mask = 1 - K.cumsum(mask, 1)
for _ in range(len(inputs.shape) - 2):
mask = K.expand_dims(mask, 2)
if mode == 'mul':
return inputs * mask
if mode == 'add':
return inputs - (1 - mask) * 1e12
def call(self, x):
# 如果只传入Q_seq,K_seq,V_seq,那么就不做Mask
# 如果同时传入Q_seq,K_seq,V_seq,Q_len,V_len,那么对多余部分做Mask
if len(x) == 3:
Q_seq, K_seq, V_seq = x
Q_len, V_len = None, None
elif len(x) == 5:
Q_seq, K_seq, V_seq, Q_len, V_len = x
# 对Q、K、V做线性变换
Q_seq = K.dot(Q_seq, self.WQ)
Q_seq = K.reshape(Q_seq, (-1, K.shape(Q_seq)[1], self.nb_head, self.size_per_head))
Q_seq = K.permute_dimensions(Q_seq, (0, 2, 1, 3))
K_seq = K.dot(K_seq, self.WK)
K_seq = K.reshape(K_seq, (-1, K.shape(K_seq)[1], self.nb_head, self.size_per_head))
K_seq = K.permute_dimensions(K_seq, (0, 2, 1, 3))
V_seq = K.dot(V_seq, self.WV)
V_seq = K.reshape(V_seq, (-1, K.shape(V_seq)[1], self.nb_head, self.size_per_head))
V_seq = K.permute_dimensions(V_seq, (0, 2, 1, 3))
# 计算内积,然后mask,然后softmax
A = K.batch_dot(Q_seq, K_seq, axes=[3, 3]) / self.size_per_head ** 0.5
A = K.permute_dimensions(A, (0, 3, 2, 1))
A = self.Mask(A, V_len, 'add')
A = K.permute_dimensions(A, (0, 3, 2, 1))
A = K.softmax(A)
# 输出并mask
O_seq = K.batch_dot(A, V_seq, axes=[3, 2])
O_seq = K.permute_dimensions(O_seq, (0, 2, 1, 3))
O_seq = K.reshape(O_seq, (-1, K.shape(O_seq)[1], self.output_dim))
O_seq = self.Mask(O_seq, Q_len, 'mul')
return O_seq
def compute_output_shape(self, input_shape):
return (input_shape[0][0], input_shape[0][1], self.output_dim)
#带有Attention的文本分类网络
from __future__ import print_function
from keras.datasets import imdb
from keras.preprocessing import sequence
# from attention import Position_Embedding, Attention
max_features = 20000
maxlen = 80
batch_size = 32
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(path="/home/admin-ygb/Desktop/learning/DataWhale_learning_nlp/data/imdb.npz",num_words=max_features)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
print('Pad sequences (samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
from keras.models import Model
from keras.layers import *
S_inputs = Input(shape=(None,), dtype='int32')
embeddings = Embedding(max_features, 128)(S_inputs)
embeddings = Position_Embedding()(embeddings) # 增加Position_Embedding能轻微提高准确率
O_seq = Attention(8, 16)([embeddings, embeddings, embeddings])
O_seq = GlobalAveragePooling1D()(O_seq)
O_seq = Dropout(0.5)(O_seq)
outputs = Dense(1, activation='sigmoid')(O_seq)
model = Model(inputs=S_inputs, outputs=outputs)
print(model.summary())
# try using different optimizers and different optimizer configs
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
print('Train...')
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=5,
validation_data=(x_test, y_test))
score, acc = model.evaluate(x_test, y_test, batch_size=batch_size)
print('Test score:', score)
print('Test accuracy:', acc)
#输出结果
Train...
Train on 25000 samples, validate on 25000 samples
Epoch 1/5
25000/25000 [==============================] - 163s 7ms/step - loss: 0.4904 - acc: 0.7382 - val_loss: 0.4334 - val_acc: 0.7972
Epoch 2/5
25000/25000 [==============================] - 138s 6ms/step - loss: 0.2798 - acc: 0.8832 - val_loss: 0.3503 - val_acc: 0.8431
Epoch 3/5
25000/25000 [==============================] - 151s 6ms/step - loss: 0.1814 - acc: 0.9302 - val_loss: 0.4032 - val_acc: 0.8327
Epoch 4/5
25000/25000 [==============================] - 143s 6ms/step - loss: 0.1004 - acc: 0.9644 - val_loss: 0.6076 - val_acc: 0.8122
Epoch 5/5
25000/25000 [==============================] - 142s 6ms/step - loss: 0.0435 - acc: 0.9854 - val_loss: 0.8017 - val_acc: 0.8092
25000/25000 [==============================] - 43s 2ms/step
Test score: 0.801709298927784
Test accuracy: 0.8092
参考资料
https://zhuanlan.zhihu.com/p/31547842
《Hierarchical Attention Networks for Document Classification》
https://github.com/foamliu/Self-Attention-Keras