AlexNet和VGG的总结
Alexnet 和 VGG 解读
Alexnet
结构
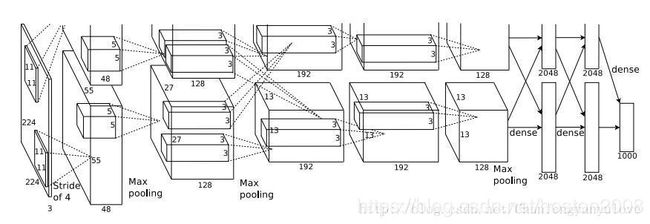
Alexnet 的网络结构,共含五层卷基层和三层全连接层。Alex-Net的上下两支是为方便同时使用两个GPU并行训练,不过在第三层卷积和全连接层处上下两支信息可交互。由于两支网络完全一致,在此仅对其中一只进行分析。AlexNet将CNN用到了更深更宽的网络中,其效果分类的精度更高相比于以前的LeNet,其中有一些trick是必须要知道的.
1.首次将卷积神经网络应用于计算机视觉领域的海量图像数据集ImageNet, 揭示了卷积神经网络拥有强大的学习能力和表示能力.另一方面,海量数据同事也使卷积神经网络免于过拟合。可以说两者相辅相成,缺一不可。
2.利用GPU实现网络训练。在上一轮神经网络中,由于计算资源的受限。研究者无法借助更加高效的计算手段如GPU,这也较大程度的阻碍了当时神经网络的研究进程。在Alex-Net中,研究者借助GPU从而将原本需数周甚至数月的网络训练过程大大缩短至五到六天。在揭示卷积神经网络强大能力的同时,无疑也大大缩短了深度网络和大型网络模型开发研究的周期与时间成本。缩短了迭代周期,数量繁多,立意新颖的网络模型和应用才能像雨后春笋一般层出不穷。
3 ReLU激活函数,局部响应规范化操作、为防止过拟合而采取的数据增广和随机失活等,这些训练技巧不仅保证了模型性能,更重要的时为后续深度卷积神经网络的构建提供了范本。实际上,此后的卷积神经网络大体上都遵循这一思路。AlexNet使用ReLU代替了Sigmoid,其能更快的训练,同时解决sigmoid在训练较深的网络中出现的梯度消失,或者说梯度弥散的问题.
ReLUs具有符合本文要求的一个性质:它不需要对输入进行归一化来防止饱和。只要一些训练样本产生一个正输入给一个ReLU,那么在那个神经元中学习就会开始。但是,我们还是发现如下的局部标准化方案有助于增加泛化性能。aix,y表示使用核i作用于(x,y)然后再采用ReLU非线性函数计算得到的活跃度,那么响应标准化活跃bix,y由以下公式计算出
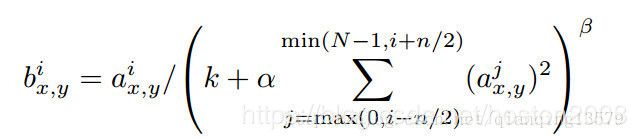 这里,对同一个空间位置的n个邻接核特征图(kernel maps)求和,N是该层的核的总数目。核特征图的顺序显然是任意的,并且在训练之前就已决定了的。这种响应归一化实现了侧抑制的一种形式,侧抑制受启发于一种在真实神经中发现的形式,对利用不同核计算得到的神经输出之间的大的活跃度生成竞争。常数k,n,α,β是超参数,它们的值使用一个验证集来确定。本文使用k=2,n=5,α=10−4,β=0.75。本文在某些特定的层中,采用ReLUs非线性函数后应用了该归一化
这里,对同一个空间位置的n个邻接核特征图(kernel maps)求和,N是该层的核的总数目。核特征图的顺序显然是任意的,并且在训练之前就已决定了的。这种响应归一化实现了侧抑制的一种形式,侧抑制受启发于一种在真实神经中发现的形式,对利用不同核计算得到的神经输出之间的大的活跃度生成竞争。常数k,n,α,β是超参数,它们的值使用一个验证集来确定。本文使用k=2,n=5,α=10−4,β=0.75。本文在某些特定的层中,采用ReLUs非线性函数后应用了该归一化
这个方案与Jarrett等[11]的局部对比度归一化方案有些相似,但本文更加准确的称呼为“亮度归一化”(brightness normalization),因为本文没有减去平均活跃度。响应归一化将top-1和top-5的错误率分别降低了1.4%和1.2%。本文也在CIFAR-10数据集上验证了这个方案的有效性:一个四层的CNN网络在未归一化的情况下错误率是13%,在归一化的情况下是11%。
重叠池化层
CNNs中的池化层归纳了同一个核特征图中的相邻神经元组的输出。通常,由邻接池化单元归纳的邻域并不重叠(例如,[17,11,4] )。更确切地说,一个池化层可以被看作是包含了每间隔S个像素的池化单元的栅格组成,每一个都归纳了以池化单元为中心大小为Z x Z的邻域。如果令S=Z,将会得到CNNs通常采用的局部池化。
现在我们可以来描述本文CNN的整体结构。正如图2所示,这个网络包含八个有权值的层:前五层是卷积层,剩下的三层是全连接层。最后一个全连接层的输出传递给一个1000路的softmax层,这个softmax产生一个对1000类标签的分布。本文的网络最大化多项Logistic回归结果,也就是最大化训练集预测正确的标签的对数概率。
第二、四、五层卷积层的核只和同一个GPU上的前层的核特征图相连(见图2)。第三层卷积层和第二层所有的核特征图相连接。全连接层中的神经元和前一层中的所有神经元相连接。响应归一化层跟着第一和第二层卷积层。最大池化层,3.4节中有所描述,既跟着响应归一化层也跟着第五层卷积层。ReLU非线性变换应用于每一个卷积和全连接层的输出。
第一层卷积层使用96个大小为11x11x3的卷积核对224x224x3的输入图像以4个像素为步长(这是核特征图中相邻神经元感受域中心之间的距离)进行滤波。第二层卷积层将第一层卷积层的输出(经过响应归一化和池化)作为输入,并使用256个大小为5x5x48的核对它进行滤波。第三层、第四层和第五层的卷积层在没有任何池化或者归一化层介于其中的情况下相互连接。第三层卷积层有384个大小为3x3x256的核与第二层卷积层的输出(已归一化和池化)相连。第四层卷积层有384个大小为3x3x192的核,第五层卷积层有256个大小为 的核。每个全连接层有4096个神经元。
4 降低过拟合( Reducing Overfitting)
结合多种不同模型的预测结果是一种可以降低测试误差的非常成功的方法[1,3],但是这对于已经要花很多天来训练的大规模神经网络来说显得太耗费时间了。但是,有一种非常有效的模型结合的方法,训练时间只需要原先的两倍。最新研究的技术,叫做“dropout”,它将每一个隐藏神经元的输出以50%的概率设为0。这些以这种方式被“踢出”的神经元不会参加前向传递,也不会加入反向传播。因此每次有输入时,神经网络采样一个不同的结构,但是所有这些结构都共享权值。这个技术降低了神经元之间复杂的联合适应性,因为一个神经元不是依赖于另一个特定的神经元的存在的。因此迫使要学到在连接其他神经元的多个不同随机子集的时候更鲁棒性的特征。在测试时,本文使用所有的神经元,但对其输出都乘以了0.5,对采用多指数dropout网络生成的预测分布的几何平均数来说这是一个合理的近似。
本文在图2中的前两个全连接层使用dropout。如果不采用dropout,本文的网络将会出现大量的过拟合。Dropout大致地使达到收敛的迭代次数增加了一倍。
VGG
VGG的特点:
1.小卷积核。作者将卷积核全部替换为3x3(极少用了1x1);
2.小池化核。相比AlexNet的3x3的池化核,VGG全部为2x2的池化核;
层数更深特征图更宽。基于前两点外,由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,计算量的增加放缓;
全连接转卷积。网络测试阶段将训练阶段的三个全连接替换为三个卷积,测试重用训练时的参数,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入。
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
比如,3个步长为1的3x3卷积核连续作用在一个大小为7的感受野,其参数总量为 3*(9C^2),这里 C 指的是输入和输出的通道数。而且3x3卷积核有利于更好地保持图像性质。VGG网络的架构如下表所示:
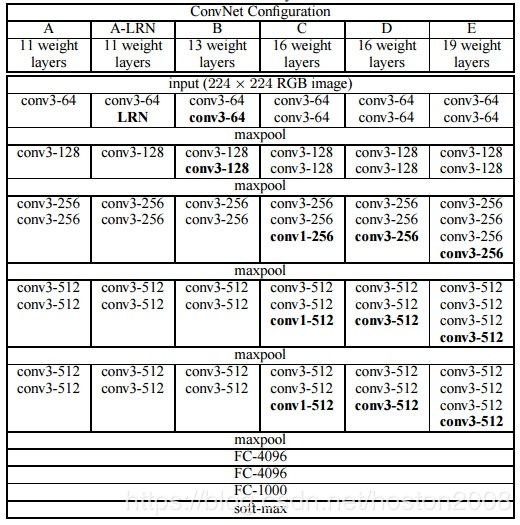 VGG卷积层之后是3个全连接层。网络的通道数从较小的64开始,然后每经过一个下采样或者池化层成倍地增加,当然特征图大小成倍地减小。最终其在ImageNet上的Top-5准确度为92.3%
VGG卷积层之后是3个全连接层。网络的通道数从较小的64开始,然后每经过一个下采样或者池化层成倍地增加,当然特征图大小成倍地减小。最终其在ImageNet上的Top-5准确度为92.3%