Android消息机制Looper与VSync的传播
#1 主要内容
本文主要简单记录在native层Looper消息机制的相关内容,主要着手于下面几个问题:
(1)消息机制的原理;
(2)VSync是如何借助消息机制进行传播的;
2 Android消息机制
2.1 应用进程的创建
说起Android的消息机制,先大致的理一下Android应用的运行机制,Android上层是基于消息机制的,首先考虑一个问题,描述如下:Android应用作为运行在Linux平台上的用户进程,是如何保持一致处于运行状态的?也就是如何做到主线程不结束,进程一直存在的?
要想搞清楚这个问题,首先得搞清楚Android应用进程是如何创建的,比如我们点击桌面上的icon,应用进程启动了,然后界面出现了,只要不退出,界面一直存在,这整个的过程是怎么样的呢?下面分几个步骤来说明这个问题:
(1)桌面Launcher应用也是一个Android应用,点击图标启动进程;
(2)ActivityManagerService接收到Activity的启动请求,发现需要启动的Activity所在的进程当前尚未运行,首先需要启动进程;
(3)进程启动后,Activity随之被启动,进入主线程的消息循环,保持“不死状态”;
本文主要讨论消息机制,为保持主题清晰,只对上述问题简单描述:
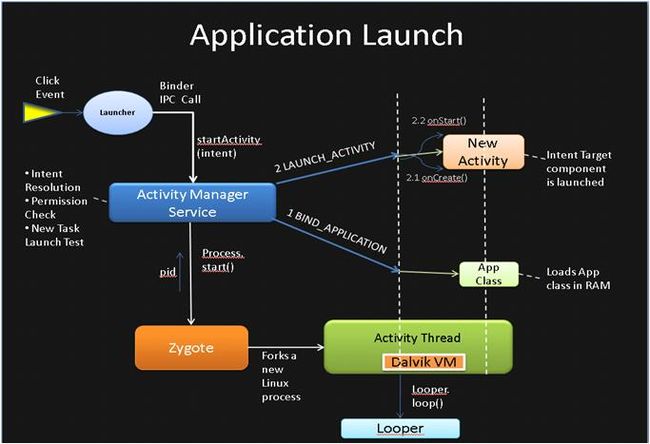
(网上某位大神画的图,因为是之前下载的,现在找不到作者了,引用一下,说明问题,切莫见怪)
上面的图画的很清楚:
(1)桌面Launcher应用收到点击事件,通过Binder IPC通信调用AMS中的startActivity;
(2)AMS首先调用Process.start()方法,从Zygote进程Fork出一个进程,并将ActivityThread.main函数作为主线程的入口,开始执行;
(3)应用进程启动后,会在ActivityThread.main函数中调用attach函数,该函数会远程调用AMS.attachApplication函数,向AMS注册当前的进程,然后AMS会远程调用应用的ActivityThread.bindApplication函数,创建一些关键的数据结构,后面AMS接收到Idle消息后,经由Binder向应用进程发送LAUNCH_ACTIVITY远程调用,从而开始启动Activity。
上面的最下面的部分,就是应用一直保持运行状态的原因,应用进程主线程里面创建了一个Looper循环,一直在等待消息,没有消息的时候线程会被阻塞住,从而保证主线程一直处于活跃状态。

这个图是Android应用启动后,整个的进程结构,里面包含了上面的图中没有包含的有关Android系统进程的相关内容,有兴趣的可以再研究一下。
2.2 Android消息机制
网上有很多资料,对于Android消息机制已经讲的很清楚,这里就不详细的介绍了,推荐老罗的 http://blog.csdn.net/luoshengyang/article/details/6817933 ,这里简单介绍一下Handler、Looper以及MessageQueue之间的关系,看一下图:

分两种情况来说明整个过程:
情形(1):应用线程中的MessageQueue中没有消息,线程处于阻塞状态;
情形(2):应用线程中MessageQueue中有消息,线程处于运行状态;
2.2.1 线程阻塞
线程阻塞的时候,会停止在MessageQueue.next函数中的nativePollOnce里面,超时时间设置成了-1,假设当前线程代号线程A,这时候只能由别的线程(比如线程B)向线程A的MessageQueue中enqueueMessage,看一下这个函数:
boolean enqueueMessage(Message msg, longwhen) {
Message p = mMessages;
boolean needWake;
if (p == null || when == 0 || when < p.when) {
// New head, wake up the event queue if blocked.
msg.next = p;
mMessages = msg;
needWake = mBlocked;
} else {
needWake = mBlocked && p.target == null && msg.isAsynchronous();
Message prev;
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
if (needWake && p.isAsynchronous()) {
needWake = false;
}
}
msg.next = p; // invariant: p == prev.next
prev.next = msg;
}
if (needWake) {
nativeWake(mPtr); //唤醒处于阻塞状态的mPtr所对应的线程
}
}
return true;
}如果当前线程处于阻塞状态,会调用到nativeWake函数,该函数会向native层的MessageQueue、Looper对应的pipe管道中写入一个W字符,epoll机制在监听pipe管道读事件的时候收到数据会从上述阻塞的nativePollOnce函数里面返回,返回到java层以后发现MessageQueue里面有未处理的消息,就可以接着处理了。
2.2.2 线程正在运行
一开始以为,如果线程处于运行状态,应该一直处理MessageQueue中的消息,直到全部都处理完,没有消息以后进入阻塞状态,整个的流程应该不会和native层有任何的关系,但是实际上代码不是这样实现的,线程在处理每一个消息的时候,都会执行native函数nativePollOnce,如果当前MessageQueue里面有消息,会将epoll的超时时间设置为0,epoll会立马返回,这时候就可以从nativePollOnce里面返回处理下一个消息,但是像上面的MessageQueue里面没有消息后nativePollOnce在执行的时候,超时时间标记被设置成了-1,在进入epoll之前会用一个很大的时间值来替代-1,从而让epoll机制无法返回,达到阻塞线程的目的。
说明:这个部分,老罗的博客上将的很清楚,实在不想也没有必要去细写了。
3 应用请求VSync同步信号
应用在请求重绘的时候会请求同步信号,而且是重绘一次,请求一次,不重绘的时候是不请求的,也就是正常情况下,若应用的界面不请求重绘,应用是接收不到VSync信号的。应用要想请求同步信号,可以借助Choreographer对象来实现,Choreographer的英文含义是“编舞”,是用来控制节奏的,名字起得确实挺生动的。
看一下Choreographer的定义,该类包含一个FrameDisplayEventReceiver对象,看一下代码:
//Choreographer.java
private final class FrameDisplayEventReceiver extends DisplayEventReceiver implements Runnable {
private boolean mHavePendingVsync;
private long mTimestampNanos;
private int mFrame;
public FrameDisplayEventReceiver(Looper looper) {
super(looper);
}
@Override
publicvoid onVsync(long timestampNanos, int builtInDisplayId, int frame) {
.............
mTimestampNanos = timestampNanos;
mFrame = frame;
Messagemsg = Message.obtain(mHandler, this);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
}
@Override
publicvoid run() {
mHavePendingVsync = false;
doFrame(mTimestampNanos, mFrame);
}
}FrameDisplayEventReceiver这个类比较简单,主要的工作都在基类DisplayEventReceiver里面完成了,DisplayEventReceiver类里面有两个比较重要的函数,一个是构造器,还有一个就是scheduleVsync函数:
//DisplayEventReceiver.java
public abstract class DisplayEventReceiver {
private final CloseGuard mCloseGuard = CloseGuard.get();
private long mReceiverPtr;
// We keep a reference message queue object here so that it is not
// GC'd while the native peer of the receiver is using them.
private MessageQueue mMessageQueue;
/**
* Creates a display event receiver.
* @param looper The looper to use when invoking callbacks.
*/
public DisplayEventReceiver(Looper looper) {
if (looper == null) {
thrownew IllegalArgumentException("looper must not be null");
}
mMessageQueue = looper.getQueue();
mReceiverPtr = nativeInit(this, mMessageQueue);
mCloseGuard.open("dispose");
}
/**
* Schedules a single vertical sync pulse to be delivered when the next
* display frame begins.
*/
public void scheduleVsync() {
if (mReceiverPtr == 0) {
Log.w(TAG, "Attempted to schedule a vertical sync pulse but the display event "
+ "receiver has already been disposed.");
} else {
nativeScheduleVsync(mReceiverPtr);
}
}
}该类是一个abstract类,构造器里面调用了nativeInit函数,当应用需要同步信号的时候,最终会调用到scheduleVsync函数,里面调用到了nativeScheduleVsync函数,这两个函数步骤比较多,下面分别来分析。
3.1 nativeInit
函数定义在android_view_DisplayEventReceiver.cpp里面:
static jlong nativeInit(JNIEnv* env, jclass clazz, jobject receiverObj, jobject messageQueueObj) {
sp messageQueue = android_os_MessageQueue_getMessageQueue(env, messageQueueObj);
if (messageQueue == NULL) {
jniThrowRuntimeException(env, "MessageQueue is not initialized.");
return 0;
}
sp receiver = new NativeDisplayEventReceiver(env, receiverObj, messageQueue);
status_t status = receiver->initialize();
if (status) {
String8 message;
message.appendFormat("Failed to initialize display event receiver. status=%d", status);
jniThrowRuntimeException(env, message.string());
return 0;
}
receiver->incStrong(gDisplayEventReceiverClassInfo.clazz); // retain a reference for the object
returnreinterpret_cast(receiver.get());
} (1)获取与当前应用主线程相关联的native层的MessageQueue对象;
(2)创建一个NativeDisplayEventReceiver对象;
(3)调用NativeDisplayEventReceiver.initialize函数;
下面逐个分析上面的2、3两个步骤。
3.1.1 NativeDisplayEventReceiver
该类定义在android_view_DisplayEventReceiver.cpp文件中,看一下定义:
class NativeDisplayEventReceiver : public LooperCallback {
public:
NativeDisplayEventReceiver(JNIEnv* env, jobject receiverObj, const sp& messageQueue);
status_t initialize();
void dispose();
status_t scheduleVsync();
protected:
virtual ~NativeDisplayEventReceiver();
private:
jobject mReceiverObjGlobal;
sp mMessageQueue;
DisplayEventReceiver mReceiver;
bool mWaitingForVsync;
virtual int handleEvent(int receiveFd, int events, void* data);
bool processPendingEvents(nsecs_t* outTimestamp, int32_t* id, uint32_t* outCount);
void dispatchVsync(nsecs_t timestamp, int32_t id, uint32_t count);
void dispatchHotplug(nsecs_t timestamp, int32_t id, bool connected);
}; 该类包含一个DisplayEventReceiver成员变量,在创建NativeDisplayEventReceiver对象时会创建DisplayEventReceiver对象,看一下DisplayEventReceiver对象的构造函数:
//DisplayEventReceiver.cpp
DisplayEventReceiver::DisplayEventReceiver() {
sp<ISurfaceComposer> sf(ComposerService::getComposerService());
if (sf != NULL) {
mEventConnection = sf->createDisplayEventConnection();
if (mEventConnection != NULL) {
mDataChannel = mEventConnection->getDataChannel();
}
}
}上面几行代码是应用进程与SurfaceFlinger进程通信的连接建立的关键函数。逐个函数进行分析,先看ComposerService::getComposerService():
// Get a connection to the Composer Service. This will block until
// a connection is established.
//注释很重要 这是一个static方法获取单例模式下的BpSurfaceComposer(new BpBinder(handle))对象
/*static*/ sp<ISurfaceComposer> ComposerService::getComposerService() {
ComposerService& instance = ComposerService::getInstance();
Mutex::Autolock _l(instance.mLock);
if (instance.mComposerService == NULL) {
//------------------重要---------------------------
ComposerService::getInstance().connectLocked();
assert(instance.mComposerService != NULL);
ALOGD("ComposerService reconnected");
}
return instance.mComposerService;
}该函数是一个static函数,ComposerService是一个单例模式,想到单例就应该想到是进程内唯一,首先创建对象ComposerService,然后调用该对象的connectLocked()函数:
void ComposerService::connectLocked() {
const String16 name("SurfaceFlinger");
/*
(1) sp mComposerService;
这里getService将mComposerService实例化成一个BpSurfaceComposer对象,定义在ISurfaceComposer.cpp中
其中这里的BpSurfaceComposer已经获得了SurfaceFlinger的service的在binder驱动中的handle值
mComposerService是一个 BpSurfaceComposer(new BpBinder(handle))对象
(2) 这里的getService作用很明显,是从ServiceManager进程中查找"SurfaceFlinger"的Binder对应的handle值,
返回的out型参数mComposerService对应的就是"SurfaceFlinger" binder 服务端的客户端Binder对象,通过这个
mComposerService就可以和"SurfaceFlinger"进行通信
*/
while (getService(name, &mComposerService) != NO_ERROR) {
usleep(250000);
}
assert(mComposerService != NULL);
// Create the death listener.
classDeathObserver : public IBinder::DeathRecipient {
ComposerService& mComposerService;
virtualvoidbinderDied(const wp& who) {
ALOGW("ComposerService remote (surfaceflinger) died [%p]",
who.unsafe_get());
mComposerService.composerServiceDied();
}
public:
DeathObserver(ComposerService& mgr) : mComposerService(mgr) { }
};
mDeathObserver = new DeathObserver(*const_cast(this));
IInterface::asBinder(mComposerService)->linkToDeath(mDeathObserver);
} 上面调用了getService函数,该函数是一个模板函数,因此定义在头文件IServiceManager.h里面:
template
status_t getService(const String16& name, sp* outService)
{
const sp sm = defaultServiceManager();
if (sm != NULL) {
*outService = interface_cast(sm->getService(name));
if ((*outService) != NULL) return NO_ERROR;
}
return NAME_NOT_FOUND;
} 1 defaultServiceManager返回的进程范围内唯一的BpServiceManager,相当于是 sm = new BpServiceManager(new BpBinder(0));
2 sm->getService(name): 会调用BpServiceManager中的getService函数,经过binder驱动程序和service_manager守护进程进行通信,得到service名称为name的service的handle值,返回的是一个BpBinder(handle)
3 interface_cast(new BpBinder(handle))会创建一个BpINTERFACE对象,
sm返回的是一个BpServiceManager对象,该对象是一个Binder的客户端,也就是Service_Manager服务守护进程的Bp客户端,相当于是BpServiceManager(new BpBinder(0)),根据前面的服务名称”SurfaceFlinger”,最终outService返回的是一个BpSurfaceComposer对象,再看一下SurfaceFlinger的声明:
class SurfaceFlinger : public BnSurfaceComposer,
private IBinder::DeathRecipient,
private HWComposer::EventHandler{.....}根据上面的分析可知,ComposerService::getComposerService()返回的是一个与SurfaceFlinger进程建立Binder进程通信的客户端,服务端就SurfaceFlinger对象本身,接下来看DisplayEventReceiver构造函数中的:
mEventConnection = sf->createDisplayEventConnection(); //BpSurfaceComposer->createDisplayEventConnection()该函数定义在ISurfaceComposer.cpp文件中:
virtual sp<IDisplayEventConnection> createDisplayEventConnection()
{
Parcel data, reply;
sp<IDisplayEventConnection> result;
int err = data.writeInterfaceToken(ISurfaceComposer::getInterfaceDescriptor());
if (err != NO_ERROR) {
return result;
}
err = remote()->transact(BnSurfaceComposer::CREATE_DISPLAY_EVENT_CONNECTION, data, &reply);
if (err != NO_ERROR) {
ALOGE("ISurfaceComposer::createDisplayEventConnection: error performing "
"transaction: %s (%d)", strerror(-err), -err);
return result;
}
result = interface_cast<IDisplayEventConnection>(reply.readStrongBinder());
return result;
}该函数经由BnSurfaceComposer.onTransact函数辗转调用到SurfaceFlinger.createDisplayEventConnection函数:
sp<IDisplayEventConnection> SurfaceFlinger::createDisplayEventConnection() {
return mEventThread->createEventConnection();
}出现了熟悉的面孔mEventThread,该对象是一个EventThread对象,该对象在SurfaceFlinger.init函数里面创建,但是创建运行以后,貌似还没有进行任何的动作,这里调用createEventConnection函数:
sp EventThread::createEventConnection() const {
return new Connection(const_cast(this));
} 有创建了一个EventThread::Connection对象,前面分析到,Connection的构造函数会创建一个BitTube对象,BitTube对象中包含一对互联的socket,一端发送另一端就能收到。并将BitTube对象存储在EventThread::Connection.mChannel里面。返回到上面DisplayEventReceiver构造函数中的mEventConnection是一个BpDisplayEventConnection对象,看一下EventThread::Connection的定义可以知道Connection是一个BnDisplayEventConnection对象,又是一对Binder客户端和服务器,接下来再看mEventConnection->getDataChannel()函数,该函数调用链:
(1)BpDisplayEventConnection.getDataChannel() //DisplayEventConnection.cpp
(2)BnDisplayEventConnection.onTransact //DisplayEventConnection.cpp
(3)EventThread::Connection.getDataChannel() //EventThread.cpp
先看BnDisplayEventConnection.onTransact函数,该函数先调用Connection.getDataChannel()函数返回前面创建的BitTube对象:
status_t BnDisplayEventConnection::onTransact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
switch(code) {
case GET_DATA_CHANNEL: {
CHECK_INTERFACE(IDisplayEventConnection, data, reply);
sp<BitTube> channel(getDataChannel());
channel->writeToParcel(reply);
return NO_ERROR;
}
}
return BBinder::onTransact(code, data, reply, flags);
}上面的channel是一个指向BitTube对象的指针,值得注意的是后面调用了BitTube.writeToParcel函数:
status_t BitTube::writeToParcel(Parcel* reply) const
{ if (mReceiveFd < 0)return -EINVAL;
status_t result = reply->writeDupFileDescriptor(mReceiveFd);
close(mReceiveFd);
mReceiveFd = -1;
return result;
}这里将前面创建BitTube对象时建立的互联的socket的mReceiveFd接收端的描述符传递给了对应的Binder客户端,也就是步骤(1)中的BpDisplayEventConnection中,同时关闭了Binder服务端的接收端描述符,也就是对应的Bn服务端只负责往Connection的socket中写入数据,客户端负责接收数据,在继续看BpDisplayEventConnection.getDataChannel函数之前,先理一下思路:
(1)应用程序创建了一个Choreographer对象;
(2)Choreographer对象创建了一个FrameDisplayEventReceiver对象,该类继承了DisplayEventReceiver类;
(3)创建DisplayEventReceiver对象的过程中,调用nativeInit函数,创建了native层对象NativeDisplayEventReceiver;
(4)NativeDisplayEventReceiver对象的成员变量mReceiver是一个DisplayEventReceiver对象;
(5)在创建DisplayEventReceiver对象的过程中,通过Service_Manager进程建立了与SurfaceFlinger进程之间的连接,
(6)通过SurfaceFlinger的mEventThread在SurfaceFlinger进程中创建了EventThread::Connection对象,该对象创建了一个BitTube对象,该对象包含一对互联的socket,并返回了Binder客户端BpDisplayEventConnection对象;
(7)经由返回的BpDisplayEventConnection对象,获取步骤6中创建的SurfaceFlinger服务端对象EventThread::Connection中BitTube对象的接收端socket描述符;
接下来看一下对应的BpDisplayEventConnection.getDataChannel函数:
virtual sp<BitTube> getDataChannel() const {
Parcel data, reply;
data.writeInterfaceToken(IDisplayEventConnection::getInterfaceDescriptor());
remote()->transact(GET_DATA_CHANNEL, data, &reply);
returnnew BitTube(reply);
}该函数调用了BpDisplayEventConnection客户端的transact函数,最终根据返回的Parcel数据创建了一个客户端的BitTube对象,看一下BitTube的对应的构造函数:
BitTube::BitTube(const Parcel& data) : mSendFd(-1), mReceiveFd(-1){
mReceiveFd = dup(data.readFileDescriptor());
}该构造函数从Parcel中读取前面在SurfaceFlinger进程中写入的socket接收端的描述符。
到这里native层的NativeDisplayEventReceiver对象已经创建结束,这时候客户端进程已经有了一个和SurfaceFlinger服务端相连的socket接收端描述符。
3.1.2 NativeDisplayEventReceiver.initialize
直接看代码:
status_t NativeDisplayEventReceiver::initialize() {
status_t result = mReceiver.initCheck();
if (result) {
ALOGW("Failed to initialize display event receiver, status=%d", result);
return result;
}
int rc = mMessageQueue->getLooper()->addFd(mReceiver.getFd(), 0, Looper::EVENT_INPUT, this, NULL);
if (rc < 0) {
return UNKNOWN_ERROR;
}
return OK;
}这里的主要代码是mMessageQueue->getLooper()->addFd()这一行,其中的参数mReceiver.getFd()返回的是在创建NativeDisplayEventReceiver时从SurfaceFlinger服务端接收回来的socket接收端描述符,前面分析到
mMessageQueue是与当前应用线程关联的java层的MessageQueue对应的native层的MessageQueue对象,下面看一下Looper.addFd这个函数,上面调用时传进来的this指针对应的是一个NativeDisplayEventReceiver对象,该类继承了LooperCallback:
int Looper::addFd(int fd, int ident, int events, Looper_callbackFunc callback, void* data) {
return addFd(fd, ident, events, callback ? new SimpleLooperCallback(callback) : NULL, data);
}
int Looper::addFd(int fd, int ident, int events, const sp& callback, void* data) {
int epollEvents = 0;
if (events & EVENT_INPUT) epollEvents |= EPOLLIN;
if (events & EVENT_OUTPUT) epollEvents |= EPOLLOUT;
{ // acquire lock
AutoMutex _l(mLock);
Request request;
request.fd = fd;
request.ident = ident;
request.callback = callback;
request.data = data;
struct epoll_event eventItem;
memset(& eventItem, 0, sizeof(epoll_event)); // zero out unused members of data field union
eventItem.events = epollEvents;
eventItem.data.fd = fd;
ssize_t requestIndex = mRequests.indexOfKey(fd);
if (requestIndex < 0) {
int epollResult = epoll_ctl(mEpollFd, EPOLL_CTL_ADD, fd, & eventItem);
if (epollResult < 0) {
}
mRequests.add(fd, request);
} else {
int epollResult = epoll_ctl(mEpollFd, EPOLL_CTL_MOD, fd, & eventItem);
if (epollResult < 0) {
return -1;
}
mRequests.replaceValueAt(requestIndex, request);
}
} // release lock
return 1;
} 首先将上面传进来的NativeDisplayEventReceiver对象封装成一个SimpleLooperCallback对象,调用下面的addFd函数的时候主要步骤如下:
(1)创建一个struct epoll_event结构体对象,将对应的内存全部用清0,并作对应的初始化;
(2)查询通过addFd方法已经添加到epoll中监听的文件描述符;
(3)查询不到的话,则调用epoll_ctl方法设置EPOLL_CTL_ADD属性将对应的文件描述符添加到epoll监听的描述符中;
(4)根据前面addFd传入的参数EVENT_INPUT,说明当前应用线程的native层的Looper对象中的epoll机制已经开始监听来自于SurfaceFlinger服务端socket端的写入事件。
分析到这里,大概可以猜测,SurfaceFlinger端的垂直同步信号分发到客户端进程应该适合当前的这个socket又密切的关系。
3.2 nativeScheduleVsync
该函数经由下面的调用路径调用到:
(1)Choreographer.scheduleVsyncLocked
(2)NativeDisplayEventReceiver.scheduleVsync —-> DisplayEventReceiver.scheduleVsync
看一下nativeScheduleVsync函数,该函数定义在android_view_DisplayEventReceiver.cpp文件中:
static void nativeScheduleVsync(JNIEnv* env, jclass clazz, jlong receiverPtr) {
sp receiver = reinterpret_cast(receiverPtr);
status_t status = receiver->scheduleVsync();
if (status) {
String8 message;
message.appendFormat("Failed to schedule next vertical sync pulse. status=%d", status);
jniThrowRuntimeException(env, message.string());
}
} 首先根据java层传进来的native层NativeDisplayEventReceiver对象的指针,该native对象就是前面在调用nativeInit函数时创建的对象,看函数的名称,应该是java层想要请求同步信号,这里面就有一个问题:同步信号是周期性的,那么应用请求同步信号是只请求一次呢?还是多次?
调用到NativeDisplayEventReceiver::scheduleVsync函数:
status_t NativeDisplayEventReceiver::scheduleVsync() {
if (!mWaitingForVsync) {
ALOGV("receiver %p ~ Scheduling vsync.", this);
// Drain all pending events.
nsecs_t vsyncTimestamp;
int32_t vsyncDisplayId;
uint32_t vsyncCount;
processPendingEvents(&vsyncTimestamp, &vsyncDisplayId, &vsyncCount);
status_t status = mReceiver.requestNextVsync();
if (status) {
ALOGW("Failed to request next vsync, status=%d", status);
return status;
}
mWaitingForVsync = true;
}
return OK;
}先跳过这里的processPendingEvents函数,后面再分析,先分析DisplayEventReceiver.requestNextVsync函数:
status_t DisplayEventReceiver::requestNextVsync() {
if (mEventConnection != NULL) {
mEventConnection->requestNextVsync();
return NO_ERROR;
}
return NO_INIT;
}这里的mEventConnection也是前面创建native层对象NativeDisplayEventReceiver时创建的,实际对象是一个BpDisplayEventConnection对象,也就是一个Binder客户端,对应的Binder服务端BnDisplayEventConnection是一个EventThread::Connection对象,对应的BpDisplayEventConnection.requestNextVsync函数和BnDisplayEventConnection.onTransact(REQUEST_NEXT_VSYNC)函数没有进行特别的处理,下面就调用到EventThread::Connection.requestNextVsync函数,从BnDisplayEventConnection.onTransact(REQUEST_NEXT_VSYNC)开始已经从用户进程将需要垂直同步信号的请求发送到了SurfaceFlinger进程,下面的函数调用开始进入SF进程:
void EventThread::Connection::requestNextVsync() {
mEventThread->requestNextVsync(this);
}辗转调用到EventThread.requestNextVsync函数,注意里面传了参数this,也就是当前的EventThread::Connection对象,需要明确的是,这里的mEventThread对象是创建EventThread::Connection对象的时候保存的,对应的是SurfaceFlinger对象的里面的mEventThread成员,该对象是一个在SurfaceFlinger.init里面创建并启动的线程对象,可见设计的时候就专门用这个SurfaceFlinger.mEventThread线程来接收来自应用进程的同步信号请求,每来一个应用进程同步信号请求,就通过SurfaceFlinger.mEventThread创建一个EventThread::Connection对象,并通过EventThread.registerDisplayEventConnection函数将创建的EventThread::Connection对象保存到EventThread.mDisplayEventConnections里面,上面有调用到了EventThread.requestNextVsync函数:
void EventThread::requestNextVsync(const sp<EventThread::Connection>& connection) {
Mutex::Autolock _l(mLock);
if (connection->count < 0) {
connection->count = 0;
mCondition.broadcast();
}
}传进来的是一个前面创建的EventThread::Connection对象,里面判断到了EventThread::Connection.count成员变量,看一下EventThread::Connection构造函数中初始变量的值:
EventThread::Connection::Connection(const sp<EventThread>& eventThread)
: count(-1), mEventThread(eventThread), mChannel(new BitTube()){
}可以看到初始值是-1,这个值就是前面那个问题的关键,EventThread::Connection.count标示了这次应用进程的垂直同步信号的请求是一次性的,还是多次重复的,看一下注释里面对于这个变量的说明:
// count >= 1 : continuous event. count is the vsync rate
// count == 0 : one-shot event that has not fired
// count ==-1 : one-shot event that fired this round / disabled
int32_t count;很清楚的说明了,count = 0说明当前的垂直同步信号请求是一个一次性的请求,并且还没有被处理。上面EventThread::requestNextVsync里面将count设置成0,同时调用了mCondition.broadcast()唤醒所有正在等待mCondition的线程,这个会触发EventThread.waitForEvent函数从:
mCondition.wait(mLock);中醒来,醒来之后经过一轮do…while循环就会返回,返回以后调用序列如下:
(1)EventThread::Connection.postEvent(event)
(2)DisplayEventReceiver::sendEvents(mChannel, &event, 1),mChannel参数就是前面创建DisplayEventReceiver是创建的BitTube对象
(3)BitTube::sendObjects(dataChannel, events, count),static函数,通过dataChannel指向BitTube对象
最终调用到BitTube::sendObjects函数:
ssize_t BitTube::sendObjects(const sp& tube, void const* events, size_t count, size_t objSize){
const char* vaddr = reinterpret_cast<const char*>(events);
ssize_t size = tube->write(vaddr, count*objSize);
return size < 0 ? size : size / static_cast(objSize);
} 继续调用到BitTube::write函数:
ssize_t BitTube::write(void const* vaddr, size_t size){
ssize_t err, len;
do {
len = ::send(mSendFd, vaddr, size, MSG_DONTWAIT | MSG_NOSIGNAL);
// cannot return less than size, since we're using SOCK_SEQPACKET
err = len < 0 ? errno : 0;
} while (err == EINTR);
return err == 0 ? len : -err;
}这里调用到了::send函数,::是作用域描述符,如果前面没有类名之类的,代表的就是全局的作用域,也就是调用全局函数send,这里很容易就能想到这是一个socket的写入函数,也就是将event事件数据写入到BitTube中互联的socket中,这样在另一端马上就能收到写入的数据,前面分析到这个BitTube的socket的两端连接着SurfaceFlinger进程和应用进程,也就是说通过调用BitTube::write函数,将最初由SurfaceFlinger捕获到的垂直信号事件经由BitTube中互联的socket从SurfaceFlinger进程发送到了应用进程中BitTube的socket接收端。
下面就要分析应用进程是如何接收并使用这个垂直同步信号事件的。
3.3 应用进程接收VSync
3.3.1 解析VSync事件
VSync同步信号事件已经发送到用户进程中的socket接收端,在上面(3.1.2)NativeDisplayEventReceiver.initialize中分析到应用进程端的socket接收描述符已经被添加到Choreographer所在线程的native层的Looper机制中,在epoll中监听EPOLLIN事件,当socket收到数据后,epoll会马上返回,下面分步骤看一下Looper.pollInner函数:
(1)epoll_wait
struct epoll_event eventItems[EPOLL_MAX_EVENTS];
int eventCount = epoll_wait(mEpollFd, eventItems, EPOLL_MAX_EVENTS, timeoutMillis);在监听到描述符对应的事件后,epoll_wait会马上返回,并将产生的具体事件类型写入到参数eventItems里面,最终返回的eventCount是监听到的事件的个数
(2)事件分析
for (int i = 0; i < eventCount; i++) {
int fd = eventItems[i].data.fd;
uint32_t epollEvents = eventItems[i].events;
if (fd == mWakeReadPipeFd) { //判断是不是pipe读管道的事件 这里如果是EventThread,这里就是一个socket的描述符,而不是mWakeReadPipeFd
if (epollEvents & EPOLLIN) {
awoken(); // 清空读管道中的数据
} else {
ALOGW("Ignoring unexpected epoll events 0x%x on wake read pipe.", epollEvents);
}
} else {
//EventThread接收到同步信号走的这里
ssize_t requestIndex = mRequests.indexOfKey(fd);
if (requestIndex >= 0) {
int events = 0;
if (epollEvents & EPOLLIN) events |= EVENT_INPUT;
if (epollEvents & EPOLLOUT) events |= EVENT_OUTPUT;
if (epollEvents & EPOLLERR) events |= EVENT_ERROR;
if (epollEvents & EPOLLHUP) events |= EVENT_HANGUP;
pushResponse(events, mRequests.valueAt(requestIndex));
} else {
ALOGW("Ignoring unexpected epoll events 0x%x on fd %d that is "
"no longer registered.", epollEvents, fd);
}
}
}Looper目前了解到的主要监听的文件描述符种类有两种:
1)消息事件,epoll_wait监听pipe管道的接收端描述符mWakeReadPipeFd
2)与VSync信号,epoll_wait监听socket接收端描述符,并在addFd的过程中将相关的信息封装在一个Request结构中,并以fd为key存储到了mRequests中,具体可以回过头看3.1.2关于addFd的分析;
因此,上面走的是else的分支,辨别出当前的事件类型后,调用pushResponse:
void Looper::pushResponse(int events, const Request& request) {
Response response;
response.events = events;
response.request = request; //复制不是引用,调用拷贝构造函数
mResponses.push(response);
}该函数将Request和events封装在一个Response对象里面,存储到了mResponses里面,也就是mResponses里面放的是“某某fd上接收到了类别为events的时间”记录,继续向下看Looper.pollInner函数
(3)事件分发处理
// Invoke all response callbacks.
for (size_t i = 0; i < mResponses.size(); i++) {
Response& response = mResponses.editItemAt(i);
if (response.request.ident == POLL_CALLBACK) {
int fd = response.request.fd;
int events = response.events;
void* data = response.request.data;
int callbackResult = response.request.callback->handleEvent(fd, events, data);
if (callbackResult == 0) {
removeFd(fd);
}
// Clear the callback reference in the response structure promptly because we
// will not clear the response vector itself until the next poll.
response.request.callback.clear();
result = POLL_CALLBACK;
}
}这里的response.request是从pushResponse里面复制过来的,里面的request对应的Request对象是在addFd的时候创建的,ident成员就是POLL_CALLBACK,所以继续走到response.request.callback->handleEvent这个函数,回忆一下3.1.2里面的addFd函数,这里的callback实际上是一个SimpleLooperCallback(定义在Looper.cpp中)对象,看一下里面的handleEvent函数:
int SimpleLooperCallback::handleEvent(int fd, int events, void* data) {
return mCallback(fd, events, data);
}这里的mCallback就是当时在addFd的时候传进来的callBack参数,实际上对应的就是NativeDisplayEventReceiver对象本身,因此最终就将垂直同步信号事件分发到了NativeDisplayEventReceiver.handleEvent函数中。
3.3.2 分发VSync事件
调用到NativeDisplayEventReceiver.handleEvent函数,该函数定义在android_view_DisplayEventReceiver.cpp中,直接列出该函数:
int NativeDisplayEventReceiver::handleEvent(int receiveFd, int events, void* data) {
if (events & (Looper::EVENT_ERROR | Looper::EVENT_HANGUP)) {
ALOGE("Display event receiver pipe was closed or an error occurred. "
"events=0x%x", events);
return 0; // remove the callback
}
if (!(events & Looper::EVENT_INPUT)) {
ALOGW("Received spurious callback for unhandled poll event. "
"events=0x%x", events);
return 1; // keep the callback
}
// Drain all pending events, keep the last vsync.
nsecs_t vsyncTimestamp;
int32_t vsyncDisplayId;
uint32_t vsyncCount;
if (processPendingEvents(&vsyncTimestamp, &vsyncDisplayId, &vsyncCount)) {
ALOGV("receiver %p ~ Vsync pulse: timestamp=%" PRId64 ", id=%d, count=%d",
this, vsyncTimestamp, vsyncDisplayId, vsyncCount);
mWaitingForVsync = false;
dispatchVsync(vsyncTimestamp, vsyncDisplayId, vsyncCount);
}
return 1; // keep the callback
}首先判断事件是不是正确的Looper::EVENT_INPUT事件,然后调用到NativeDisplayEventReceiver.processPendingEvents函数:
bool NativeDisplayEventReceiver::processPendingEvents(nsecs_t* outTimestamp, int32_t* outId, uint32_t* outCount) {
bool gotVsync = false;
DisplayEventReceiver::Event buf[EVENT_BUFFER_SIZE];
ssize_t n;
while ((n = mReceiver.getEvents(buf, EVENT_BUFFER_SIZE)) > 0) {
for (ssize_t i = 0; i < n; i++) {
const DisplayEventReceiver::Event& ev = buf[i];
switch (ev.header.type) {
case DisplayEventReceiver::DISPLAY_EVENT_VSYNC:
// Later vsync events will just overwrite the info from earlier
// ones. That's fine, we only care about the most recent.
gotVsync = true;
*outTimestamp = ev.header.timestamp;
*outId = ev.header.id;
*outCount = ev.vsync.count;
break;
case DisplayEventReceiver::DISPLAY_EVENT_HOTPLUG:
dispatchHotplug(ev.header.timestamp, ev.header.id, ev.hotplug.connected);
break;
default:
ALOGW("receiver %p ~ ignoring unknown event type %#x", this, ev.header.type);
break;
}
}
}
if (n < 0) {
ALOGW("Failed to get events from display event receiver, status=%d", status_t(n));
}
return gotVsync;
}这里的mReceiver也就是前面创建NativeDisplayEventReceiver对象是创建的成员变量对象DisplayEventReceiver,下面调用到DisplayEventReceiver.getEvents函数,应该是要从出现同步信号事件的socket中读取数据,上面Looper机制中epoll中监听到socket以后,返回到NativeDisplayEventReceiver.handleEvent里面,但是socket里面的数据还没有读取,下面的调用流程为:
(1)mReceiver.getEvents(buf, EVENT_BUFFER_SIZE) —-> DisplayEventReceiver::getEvents(DisplayEventReceiver::Event* events, size_t count)
(2)BitTube::recvObjects(dataChannel, events, count) —-> BitTube::recvObjects(const sp& tube, void* events, size_t count, size_t objSize)
看一下这个recvObjects函数:
ssize_t BitTube::recvObjects(const sp& tube, void* events, size_t count, size_t objSize)
{
char* vaddr = reinterpret_cast<char*>(events);
ssize_t size = tube->read(vaddr, count*objSize);
return size < 0 ? size : size / static_cast(objSize);
} 这里在NativeDisplayEventReceiver中创建了一个缓冲区,并在recvObjects中将socket中的Event数据读到这个缓冲区中,这个Event.header.type一般都是DISPLAY_EVENT_VSYNC,因此在上面的processPendingEvents函数中会将Event数据保存在outCount所指向的内存中,并返回true。 接下来返回到NativeDisplayEventReceiver.handleEvent后会调用到dispatchVsync函数:
void NativeDisplayEventReceiver::dispatchVsync(nsecs_t timestamp, int32_t id, uint32_t count) {
JNIEnv* env = AndroidRuntime::getJNIEnv();
env->CallVoidMethod(mReceiverObjGlobal, gDisplayEventReceiverClassInfo.dispatchVsync, timestamp, id, count);
mMessageQueue->raiseAndClearException(env, "dispatchVsync");
}这里的处理很直接,直接调用mReceiverObjGlobal对象在gDisplayEventReceiverClassInfo.dispatchVsync中指定的函数,将后面的timestamp(时间戳) id(设备ID) count(经过的同步信号的数量,一般没有设置采样频率应该都是1),下面分别看一下mReceiverObjGlobal以及gDisplayEventReceiverClassInfo.dispatchVsync代表的是什么?
(1)mReceiverObjGlobal
NativeDisplayEventReceiver::NativeDisplayEventReceiver(JNIEnv* env, jobject receiverObj, const sp& messageQueue) :
mReceiverObjGlobal(env->NewGlobalRef(receiverObj)), mMessageQueue(messageQueue), mWaitingForVsync(false) {
ALOGV("receiver %p ~ Initializing input event receiver.", this);
} 可以看到mReceiverObjGlobal是创建NativeDisplayEventReceiver对象时传进来的第二个参数,该对象是在nativeInit函数中创建:
sp receiver = new NativeDisplayEventReceiver(env, receiverObj, messageQueue);
进一步的,receiverObj是调用nativeInit函数时传进来的第一个参数(第一个参数env是系统用于连接虚拟机时自动加上的),nativeInit函数又是在Choreographer中创建FrameDisplayEventReceiver对象时,在基类DisplayEventReceiver构造器中调用的,因此这里的mReceiverObjGlobal对应的就是Choreographer中的FrameDisplayEventReceiver成员mDisplayEventReceiver。
(2)gDisplayEventReceiverClassInfo.dispatchVsync
在JNI中有很多这样的类似的结构体对象,这些对象都是全局结构体对象,这里的gDisplayEventReceiverClassInfo就是这样的一个对象,里面描述了一些在整个文件内可能会调用到的java层的相关类以及成员函数的相关信息,看一下gDisplayEventReceiverClassInfo:
static struct {
jclass clazz;
jmethodID dispatchVsync;
jmethodID dispatchHotplug;
} gDisplayEventReceiverClassInfo;看一下里面的变量名称就能知道大致的含义,clazz成员代表的是某个java层的类的class信息,dispatchVsync和dispatchHotplug代表的是java层类的方法的方法信息,看一下该文件中注册JNI函数的方法:
int register_android_view_DisplayEventReceiver(JNIEnv* env) {
int res = RegisterMethodsOrDie(env, "android/view/DisplayEventReceiver", gMethods, NELEM(gMethods));
jclass clazz = FindClassOrDie(env, "android/view/DisplayEventReceiver");
gDisplayEventReceiverClassInfo.clazz = MakeGlobalRefOrDie(env, clazz);
gDisplayEventReceiverClassInfo.dispatchVsync = GetMethodIDOrDie(env, gDisplayEventReceiverClassInfo.clazz, "dispatchVsync", "(JII)V");
gDisplayEventReceiverClassInfo.dispatchHotplug = GetMethodIDOrDie(env, gDisplayEventReceiverClassInfo.clazz, "dispatchHotplug", "(JIZ)V");
return res;
}RegisterMethodsOrDie调用注册了java层调用native方法时链接到的函数的入口,下面clazz对应的就是java层的“android/view/DisplayEventReceiver.java”类,gDisplayEventReceiverClassInfo.dispatchVsync里面保存的就是clazz类信息中与dispatchVsync方法相关的信息,同样dispatchHotplug也是。
分析到这里,就知道应用进程native接收到同步信号事件后,会调用Choreographer中的FrameDisplayEventReceiver成员mDisplayEventReceiver的dispatchVsync方法。
3.3.3 应用接收Vsync
看一下FrameDisplayEventReceiver.dispatchVsync方法,也就是DisplayEventReceiver.dispatchVsync方法(Choreographer.java):
// Called from native code.
@SuppressWarnings("unused")
private void dispatchVsync(long timestampNanos, int builtInDisplayId, int frame) {
onVsync(timestampNanos, builtInDisplayId, frame);
}
注释表明这个方法是从native代码调用的,该函数然后会调用FrameDisplayEventReceiver.onVsync方法:
@Override
public void onVsync(long timestampNanos, int builtInDisplayId, int frame) {
// Ignore vsync from secondary display.
// This can be problematic because the call to scheduleVsync() is a one-shot.
// We need to ensure that we will still receive the vsync from the primary
// display which is the one we really care about. Ideally we should schedule
// vsync for a particular display.
// At this time Surface Flinger won't send us vsyncs for secondary displays
// but that could change in the future so let's log a message to help us remember
// that we need to fix this.
//注释:忽略来自非主显示器的Vsync信号,但是我们前面调用的scheduleVsync函数只能请求到一次Vsync信号,因此需要重新调用scheduleVsync函数
//请求来自主显示设备的Vsync信号
if (builtInDisplayId != SurfaceControl.BUILT_IN_DISPLAY_ID_MAIN) {
Log.d(TAG, "Received vsync from secondary display, but we don't support "
+ "this case yet. Choreographer needs a way to explicitly request "
+ "vsync for a specific display to ensure it doesn't lose track "
+ "of its scheduled vsync.");
scheduleVsync();
return;
}
// Post the vsync event to the Handler.
// The idea is to prevent incoming vsync events from completely starving
// the message queue. If there are no messages in the queue with timestamps
// earlier than the frame time, then the vsync event will be processed immediately.
// Otherwise, messages that predate the vsync event will be handled first.
long now = System.nanoTime();
if (timestampNanos > now) {
Log.w(TAG, "Frame time is " + ((timestampNanos - now) * 0.000001f)
+ " ms in the future! Check that graphics HAL is generating vsync "
+ "timestamps using the correct timebase.");
timestampNanos = now;
}
if (mHavePendingVsync) {
Log.w(TAG, "Already have a pending vsync event. There should only be "
+ "one at a time.");
} else {
mHavePendingVsync = true;
}
mTimestampNanos = timestampNanos; //同步信号时间戳
mFrame = frame; //同步信号的个数,理解就是从调用scheduleVsync到onVsync接收到信号之间经历的同步信号的个数,一般都是1
Message msg = Message.obtain(mHandler, this);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
}貌似这里的处理只是往Choreographer对象中的mHandler对应的线程Looper中发送一个消息,消息的内容有两个特点:
(1)将this,也就是当前的FrameDisplayEventReceiver对象作为参数,后面会回调到FrameDisplayEventReceiver.run方法;
(2)为Message设置FLAG_ASYNCHRONOUS属性;
发送这个FLAG_ASYNCHRONOUS消息后,后面会回调到FrameDisplayEventReceiver.run方法,至于为什么,后面再写文章结合View.invalidate方法的过程分析,看一下FrameDisplayEventReceiver.run方法:
@Override
public void run() {
mHavePendingVsync = false;
doFrame(mTimestampNanos, mFrame);
}调用Choreographer.doFrame方法,如果是重绘事件doFrame方法会最终调用到ViewRootImpl.performTraversals方法进入实际的绘制流程。经过上面的分析可以知道,调用一次Choreographer.scheduleVsyncLocked只会请求一次同步信号,也就是回调一次FrameDisplayEventReceiver.onVsync方法,在思考一个问题,一个应用进程需要多次请求Vsync同步信号会不会使用同样的一串对象?多个线程又是怎么样的?
答:一般绘制操作只能在主线程里面进行,因此一般来说只会在主线程里面去请求同步信号,可以认为不会存在同一个应用的多个线程请求SF的Vsync信号,Choreographer是一个线程内的单例模式,存储在了 ThreadLocal sThreadInstance对象里面,所以主线程多次请求使用的是同一个Choreographer对象,所以后面的一串对象应该都是可以复用的。