ZooKeeper安装说明手册-个人整理
一、Zookeeper 概述
ZooKeeper是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一个复杂的过程。ZooKeeper通过其简单的架构和API解决了这个问题。ZooKeeper允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
ZooKeeper框架最初是在“Yahoo!"上构建的,用于以简单而稳健的方式访问他们的应用程序。 后来,Apache ZooKeeper成为Hadoop,HBase和其他分布式框架使用的有组织服务的标准。 例如,Apache HBase使用ZooKeeper跟踪分布式数据的状态。
在进一步深入之前,我们了解关于分布式应用的一两件事情是很重要的。因此,让我们开始分布式应用的概述的快速讨论。
1、什么是Apache ZooKeeper
Apache ZooKeeper是由集群(节点组)使用的一种服务,用于在自身之间协调,并通过稳健的同步技术维护共享数据。ZooKeeper本身是一个分布式应用程序,为写入分布式应用程序提供服务。
ZooKeeper提供的常见服务如下 :
1)命名服务
按名称标识集群中的节点。它类似于DNS,但仅对于节点。
2)配置管理
加入节点的最近的和最新的系统配置信息。
3)集群管理
实时地在集群和节点状态中加入/离开节点。
4)选举算法
选举一个节点作为协调目的的leader。
5)锁定和同步服务
在修改数据的同时锁定数据。此机制可帮助你在连接其他分布式应用程序(如Apache HBase)时进行自动故障恢复。
6)高度可靠的数据注册表
即使在一个或几个节点关闭时也可以获得数据。
2、ZooKeeper的好处
分布式应用程序提供了很多好处,但它们也抛出了一些复杂和难以解决的挑战。ZooKeeper框架提供了一个完整的机制来克服所有的挑战。竞争条件和死锁使用故障安全同步方法进行处理。另一个主要缺点是数据的不一致性,ZooKeeper使用原子性解析。
以下是使用ZooKeeper的好处:
1)简单的分布式协调过程
2)同步
服务器进程之间的相互排斥和协作。此过程有助于Apache HBase进行配置管理。
3)有序的消息
4)序列化
根据特定规则对数据进行编码。确保应用程序运行一致。这种方法可以在MapReduce中用来协调队列以执行运行的线程。
5)可靠性
6)原子性
数据转移完全成功或完全失败,但没有事务是部分的。
二、zookeeper安装部署
1、JDK安装
1.1 系统卸载自带JDK
查询系统是否安装自带软件:
查询:rpm -qa|grep jdk
若有则删除已安装软件:
删除:rpm -qa |grep jdk | xargs rpm -e --nodeps
查询是否删除干净:
查询:rpm -qa |grep jdk
1.2 安装新版本JDK
下载路径:http://www.oracle.com/technetwork/java/javase/downloads/index.html
执行如下命令安装jdk
# rpm -ivh jdk-8u151-linux-x64.rpm
jdk安装成功后,默认存放在/usr/java文件目录中

配置环境变量
使用 vim 或 vi 编辑器打开文件/etc/profile
# vim /etc/profile
# vi /etc/profile
在文件尾部添加如下内容,保存退出
exportJAVA_HOME=/usr/java/jdk1.8.0_151
export PATH=$JAVA_HOME/bin:$PATH
exportCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tool.jar
此时,我们刚刚配置的环境变量并没有起效,输入如下命令,使用环境变量立即生效
# source /etc/profile
输入如下命令验证环境变量是否生效
# echo $JAVA_HOME
![]()
2、安装zookeeper
2.1 机器规划
本安装是在三台机器上进行操作,具体机器信息如下:
| 机器名称 |
机器IP |
操作系统 |
| server1 |
192.168.51.127 |
Centos7 |
| server2 |
192.168.51.128 |
Centos7 |
| server3 |
192.168.51.129 |
Centos7 |
2.2 下载
进入要下载的版本的目录,选择.tar.gz文件下载
下载链接:http://archive.apache.org/dist/zookeeper/
当前最新版本为:zookeeper-3.4.12.tar.gz
2.3 安装
使用tar解压要安装的目录即可,以3.4.12版本为例。这里解压到/usr/zookeeper,实际安装根据自己的想安装的目录修改(注意如果修改,那后边的命令和配置文件中的路径都要相应修改)。
# tar -zxvf zookeeper-3.4.12.tar.gz -C /usr/zookeeper
解压ZooKeeper软件压缩包后,可以看到zk包含以下的文件和目录:
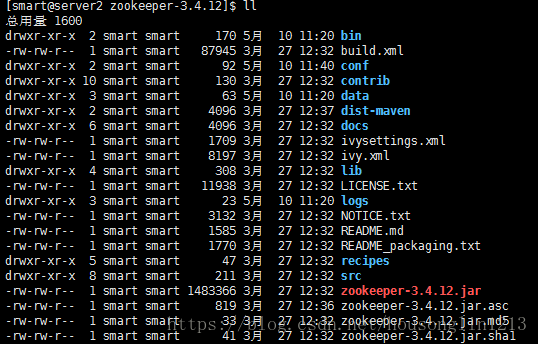
上图为ZooKeeper软件的文件和目录
1) bin目录
ZooKeeper的可执行脚本目录,包括zk服务进程,zk客户端,等脚本。其中,.sh是Linux环境下的脚本,.cmd是Windows环境下的脚本。
2)conf目录
配置文件目录。zoo_sample.cfg为样例配置文件,需要修改为自己的名称,一般为zoo.cfg。log4j.properties为日志配置文件。
3)lib
zk依赖的包。
4)contrib目录
一些用于操作zk的工具包。
5)recipes目录
zk某些用法的代码示例
3、单机模式配置
ZooKeeper的安装包括单机模式安装,以及集群模式安装。
单机模式较简单,是指只部署一个zk进程,客户端直接与该zk进程进行通信。 在开发测试环境下,通过来说没有较多的物理资源,因此我们常使用单机模式。当然在单台物理机上也可以部署集群模式,但这会增加单台物理机的资源消耗。故在开发环境中,我们一般使用单机模式。 但是要注意,生产环境下不可用单机模式,这是由于无论从系统可靠性还是读写性能,单机模式都不能满足生产的需求。
3.1 运行配置
上面提到,conf目录下提供了配置的样例zoo_sample.cfg,要将zk运行起来,需要将其名称修改为zoo.cfg。
打开zoo.cfg,可以看到默认的一些配置。
1) tickTime
时长单位为毫秒,为zk使用的基本时间度量单位。例如,1 * tickTime是客户端与zk服务端的心跳时间,2 * tickTime是客户端会话的超时时间。
tickTime的默认值为2000毫秒,更低的tickTime值可以更快地发现超时问题,但也会导致更高的网络流量(心跳消息)和更高的CPU使用率(会话的跟踪处理)。
2)clientPort
zk服务进程监听的TCP端口,默认情况下,服务端会监听2181端口。
3) dataDir
无默认配置,必须配置,用于配置存储快照文件的目录。如果没有配置dataLogDir,那么事务日志也会存储在此目录。
在主目录下创建data和logs两个目录用于存储数据和日志:
# cd /usr/zookeeper/zookeeper-3.4.12
# mkdir data
# mkdir logs
在conf目录下,复制zoo_sample.cfg到zoo.cfg文件。
# cd /usr/zookeeper/zookeeper-3.4.12/conf
# cp zoo_sample.cfg zoo.cfg
以192.168.51.127机器为例,具体配置如下:
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/usr/zookeeper/zookeeper-3.4.12/data
clientPort=2181
dataLogDir=/usr/zookeeper/zookeeper-3.4.12/logs
3.2 启动
在Windows环境下,直接双击zkServer.cmd即可。在Linux环境下,进入bin目录,执行命令
$ ./zkServer.sh start
进入bin目录,启动、停止、重启分和查看当前节点状态(包括集群中是何角色)别执行:
./zkServer.sh start
./zkServer.sh stop
./zkServer.sh restart
./zkServer.sh status
这个命令使得zk服务进程在后台进行。如果想在前台中运行以便查看服务器进程的输出日志,可以通过以下命令运行:
$ ./zkServer.sh start-foreground
执行此命令,可以看到大量详细信息的输出,以便允许查看服务器发生了什么。
使用文本编辑器打开zkServer.cmd或者zkServer.sh文件,可以看到其会调用zkEnv.cmd或者zkEnv.sh脚本。zkEnv脚本的作用是设置zk运行的一些环境变量,例如配置文件的位置和名称等。
3.3 连接
如果是连接同一台主机上的zk进程,那么直接运行bin/目录下的zkCli.cmd(Windows环境下)或者zkCli.sh(Linux环境下),即可连接上zk。
直接执行zkCli.cmd或者zkCli.sh命令默认以主机号 127.0.0.1,端口号 2181 来连接zk,如果要连接不同机器上的zk,可以使用 -server 参数,例如:
$ bin/zkCli.sh -server192.168.0.1:2181
4、集群模式配置
单机模式的zk进程虽然便于开发与测试,但并不适合在生产环境使用。在生产环境下,我们需要使用集群模式来对zk进行部署。
注意:
在集群模式下,建议至少部署3个zk进程,或者部署奇数个zk进程。如果只部署2个zk进程,当其中一个zk进程挂掉后,剩下的一个进程并不能构成一个quorum的大多数。因此,部署2个进程甚至比单机模式更不可靠,因为2个进程其中一个不可用的可能性比一个进程不可用的可能性还大。
4. 1 运行配置
将192.168.51.128/192.168.51.129参考单机模式进行配置。或者直接将192.168.51.127机器上的zookeeper打包复制到其余两台机器上。
在集群模式下,所有的zk进程可以使用相同的配置文件(是指各个zk进程部署在不同的机器上面),例如如下配置:
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/usr/zookeeper/zookeeper-3.4.12/data
clientPort=2181
dataLogDir=/usr/zookeeper/zookeeper-3.4.12/logs
server.1=192.168.51.127:2888:3888
server.2=192.168.51.128:2888:3888
server.3=192.168.51.129:2888:3888
Ø initLimit
ZooKeeper集群模式下包含多个zk进程,其中一个进程为leader,余下的进程为follower。 当follower最初与leader建立连接时,它们之间会传输相当多的数据,尤其是follower的数据落后leader很多。initLimit配置follower与leader之间建立连接后进行同步的最长时间。
Ø syncLimit
配置follower和leader之间发送消息,请求和应答的最大时间长度。
Ø tickTime
tickTime则是上述两个超时配置的基本单位,例如对于initLimit,其配置值为5,说明其超时时间为 2000ms * 5 = 10秒。
Ø server.id=host:port1:port2
其中id为一个数字,表示zk进程的id,这个id也是dataDir目录下myid文件的内容。 host是该zk进程所在的IP地址,port1表示follower和leader交换消息所使用的端口,port2表示选举leader所使用的端口。
Ø dataDir
其配置的含义跟单机模式下的含义类似,不同的是集群模式下还有一个myid文件。myid文件的内容只有一行,且内容只能为1 - 255之间的数字,这个数字亦即上面介绍server.id中的id,表示zk进程的id。
注意
如果仅为了测试部署集群模式而在同一台机器上部署zk进程,server.id=host:port1:port2配置中的port参数必须不同。但是,为了减少机器宕机的风险,强烈建议在部署集群模式时,将zk进程部署不同的物理机器上面。
4.2 启动
在三台机器dataDir目录( /home/myname/zookeeper 目录)下,分别生成一个myid文件,其内容分别为1,2,3。myid文件的内容只有一行,且内容只能为1 - 255之间的数字,这个数字亦即上面介绍server.id中的id,表示zk进程的id。
然后分别在这三台机器上启动zk进程,这样我们便将zk集群启动了起来。
待三台机器上的zk全部启动完成后,可在bin目录执行:
./zkServer.sh status
以查看zk集群的状态。
具体效果如下所示:



4.3 连接
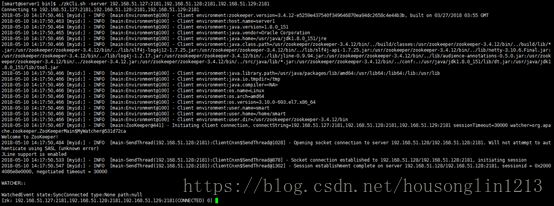
可以使用以下命令来连接一个zk集群:
$ zkCli.sh -server 192.168.51.127:2181,192.168.51.128:2181, 192.168.51.129:2181
成功连接后,可以看到如下输出: