Python scrapy实践应用,爬取电影网站的影片资源并存入数据库
知识点
- scrapy 分页爬取。
- scrapy提取页面元素之xpath表达式语法
- scrapy 配合pymysql保存爬取到的数据到mysql数据库
- scrapy.Request(……)向回调方法传递额外数据
- 数据库存储前先查重
本文为前文:Python scrapy使用入门,爬取拉勾网上万条职位信息 基础之上的拓展实战,没有看过前文的可以先去看看。对于之前说过的步骤不再赘述。本篇只做举一反三的一次实践,代码抄下来运行成功并没有意义,我们要善于掌握核心技术,为己所用,正好,我选择了一个电影下载站,很适合我练习,于是,在上一篇的代码基础上进行修改。
second.py文件修改后如下:
# -*- coding: utf-8 -*-
import scrapy
from First.items import FirstItem
class SecondSpider(scrapy.Spider):
name = 'second'
allowed_domains = []
start_urls = ['http://www.66ys.tv/']
def parse(self, response):
for item in response.xpath('//div[@class="menutv"]/ul/li/a'):
movClass = item.xpath('text()').extract()
movUrl = item.xpath("@href").extract_first()
oneItem = FirstItem()
oneItem["movClass"] =movClass
oneItem["movUrl"] = movUrl
for i in range(150):
mvUrl2 = movUrl+str('index_%s.html'%i)
try:
yield scrapy.Request(url=mvUrl2,
callback=lambda response, mvclass=movClass: self.parse_url(response, mvclass))
except:
pass
# yield scrapy.Request(url=movUrl,callback=lambda response,mvclass=movClass: self.parse_url(response,mvclass))
def parse_url(self, response,mvclass):
for sel2 in response.xpath('//div[@class="listBox"]/ul/li'):
imgurl = sel2.xpath("div/a/img/@src").extract() # 电影海报链接
mvname = sel2.xpath('div/h3/a/text()').extract()#电影名字
mvurl = sel2.xpath("div/h3/a/@href").extract_first()#电影链接
yield scrapy.Request(url=mvurl, callback=lambda response,mvsclass =mvclass,img = imgurl,name = mvname: self.parse_mor(response, mvclass,img,name))
def parse_mor(self, response, mvsclass,img,name):
for select in response.xpath('//div[@class="contentinfo"]'):
mvdownloadUrl = select.xpath("div/table/tbody/.//tr/td/a/@href").extract() # 下载地址,可能是多个
mvdtilte = select.xpath("div/table/tbody/.//tr/td/a/text()").extract()#下载标签的文本
mvdesc = select.xpath("div[@id='text']/.//p/text()")#/p[2]/text()
desc = ""
for p in mvdesc:
desc = desc + p.extract().strip()
desc= str(desc).replace('\\u3000',' ')
Item = FirstItem()
Item['movClass'] = mvsclass
Item['downLoadName'] = name
if str(mvdtilte).strip()=='':
mvdtilte = "点击下载"
Item['downdtitle'] = str(mvdtilte)
Item['downimgurl'] = img
Item['downLoadUrl'] = mvdownloadUrl
Item['mvdesc'] = desc
yield Item
item.py文件修改后如下:
# -*- coding: utf-8 -*-
import scrapy
class FirstItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
movClass = scrapy.Field()#电影分类
movUrl = scrapy.Field()#电影分类的URL
mvName = scrapy.Field()
mvUrl = scrapy.Field()
downLoadUrl = scrapy.Field()#下载地址
downLoadName = scrapy.Field()#下载电影的名称
downimgurl = scrapy.Field()#电影海报图片
mvdesc = scrapy.Field()#电影的详情介绍
downdtitle = scrapy.Field()#下载的电影的标题
settings.py中添加数据库配置信息:
# -*- coding: utf-8 -*-
# Scrapy settings for First project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'First'
SPIDER_MODULES = ['First.spiders']
NEWSPIDER_MODULE = 'First.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'First (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'First.middlewares.FirstSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'First.middlewares.FirstDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'First.pipelines.FirstPipeline': 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
FEED_EXPORTERS_BASE = {
'json': 'First.recode.recodes',
'jsonlines' : 'scrapy.contrib.exporter.JsonLinesItemExporter'
}
MY_USER_AGENT = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0"
]
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddleware.useragent.UserAgentMiddleware': None,
'First.middlewares.MyUserAgentMiddleware': 400,
}
ITEM_PIPELINES = {
'First.pipelines.FirstPipeline': 1,
}
#Mysql数据库的配置信息
MYSQL_HOST = '127.0.0.1'
MYSQL_DBNAME = 'movie' #数据库名字,请修改
MYSQL_USER = 'root' #数据库账号,请修改
MYSQL_PASSWD = 'root' #数据库密码,请修改
MYSQL_PORT = 3306 #数据库端口,在dbhelper中使用
这里,我为了实验方便,本地装了个phpstudy,里面自带了mysql,然后用navcat新建一个数据库,建一个表,添加对应字段,由于对写sql命令不太熟,所以尤其喜欢navcat这个工具,真是太友好了。
接下来配置piplines.py,在这个里面配置数据库相关的操作,我们的数据都是在这个模块里存入mysql的:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
from twisted.enterprise import adbapi
import pymysql
from First import settings
from scrapy import log
class FirstPipeline(object):
def __init__(self):
# 连接数据库
self.connect = pymysql.connect(
host=settings.MYSQL_HOST,
db=settings.MYSQL_DBNAME,
user=settings.MYSQL_USER,
passwd=settings.MYSQL_PASSWD,
charset='utf8',
use_unicode=True)
# 通过cursor执行增删查改
self.cursor = self.connect.cursor()
def process_item(self, item, spider):
try:
# 插入数据
# 查重处理
self.cursor.execute(
"""select * from mybt where downLoadName = %s""",
item['downLoadName'])
# 是否有重复数据
repetition = self.cursor.fetchone()
# 重复
if repetition is not None:
#结果返回,已存在,则不插入
pass
else:
self.cursor.execute(
"""insert into mybt(movClass, downLoadName, downLoadUrl, mvdesc,downimgurl,downdtitle )
value (%s, %s, %s, %s, %s, %s)""",
(item['movClass'],
item['downLoadName'],
item['downLoadUrl'],
item['mvdesc'],
item['downimgurl'],
item['downdtitle']
))
# 提交sql语句
self.connect.commit()
except Exception as error:
# 出现错误时打印错误日志
log(error)
return item
因为我们不希望每次采集,都累加进数据库,那样会有很多重复数据,所以在插入之前先判断是否存在该记录,如果没有再插入。可能这个方法不太理想,暂时先这么干吧,需要改进的地方很多。
好啦,就这么简单,修改的地方不多,总共代码依旧很简洁。但是却可以爬取一整个电影网站的资源了。试了一下,运行近15分钟,爬了14000多条,下载地址也存进了数据库。
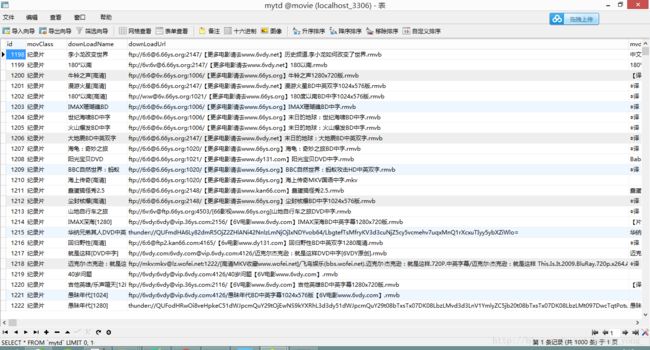
然后,你可以拿这个数据库去搭建自己的影视下载app,or 下载站了。
目前存在的问题
1.详情页的数据,电影和电视剧是不一样的,电影较为统一,但是电视剧因为下载集数很多,所以格式有别,目前是粗暴的都存入了一个长字符串里,我慢慢再优化吧。
2.部分电影明明匹配格式正确但是就是没爬下来数据
3.部分非常规页面的下载链接和名称没能正确匹配,像排行榜啊啥的
完整源码在github。