使用Tensorflow训练LSTM+Attention中文标题党分类
这里用Tensorflow中LSTM+Attention模型训练一个中文标题党的分类模型,并最后用Java调用训练好的模型。
数据预处理
首先根据语料和实验数据训练词向量word2vec模型,这个有很多教程,这么不再叙述。之后根据训练好的词向量生成我们需要的词典文件。保存的词典map为每行一个词和词的编号。
import gensim
import numpy as np
def load_words_embedding(model, embedding_dim, word_map_path):
"""
获取word2vec词向量中的词表
:param model: 训练好的word2vec模型
:param embedding_dim: word2vec模型的维度
:param word_map_path: word2vec中的词保存为词典编号
:return:
vocab_dict 词典编号
vectors_array 词向量转成数组,索引为0的位置填充了一个随机初始化向量,表示未知词
"""
# load word2vec
w2v_model = gensim.models.KeyedVectors.load_word2vec_format(w2v_path, binary=True)
vocab = model.wv.vocab
word_keys = list(vocab.keys())
vocab_dict = {"UNKNOW": 0} # 0表示未知词
fw = open(word_map_path, "w", encoding="utf8")
for i in range(len(word_keys)):
vocab_dict[word_keys[i]] = i+1
fw.write(word_keys[i] + " " + str(i+1) + "\n")
fw.close()
vector_list = list()
vector_list.append(np.random.rand(embedding_dim))
for word in word_keys:
try:
vector_list.append(model[word])
except:
vector_list.append(np.random.rand(embedding_dim).astype(np.float32))
vectors_array = np.array(vector_list)
print("dict_size:", len(vocab_dict))
print("embedding_sizes:", len(vectors_array))
return vocab_dict, vectors_array
处理实验数据集,我们的数据是中文已经分好词的标题党数据,每行一个标签(1为标题党,0为正常标题)和一条数据,中间制表符隔开("\t"),实例如下图所示:

我们需要根据上面的词典文件,把分词序列转成词典编号序列,并记录每个样本的长度。
def read_data(data_path, vocab_dict, sequence_length):
"""
读取并处理实验数据集
:param data_path: 数据集路径
:param vocab_dict: 前面产生的词典
:param sequence_length: 输入模型最大长度控制,多则阶段,少则填充
:return:
datas_index: 由词序列转成的编号序列
datas_length:每条数据的长度
labels:每条数据的标签
"""
fo = open(data_path, "r", encoding='utf8')
all_data = fo.readlines()
fo.close()
random.shuffle(all_data) # 打乱顺序
datas_index = []
datas_length = []
labels = []
for line in all_data:
line = line.strip().split("\t")
label = int(line[0])
title = line[1]
data_index = []
for word in title.split(" "):
try:
data_index.append(vocab_dict[word])
except:
data_index.append(0)
length = len(title.split(" "))
if length > sequence_length:
length = sequence_length
datas_index.append(data_index)
datas_length.append(length)
labels.append(label)
return datas_index, datas_length, labels
对于长度不一致的情况,需要进行数据填充。还对标签进行one-hot编码。
def pad_sequences(data_index, maxlen):
"""
数据填充
:param data_index: 输入数据的词索引
:param maxlen: 最大长度
:return: 填充后的数据
"""
data_pad_index = []
for sentence in data_index:
if len(sentence) >= maxlen:
padded_seq = sentence[0: maxlen]
else:
padded_seq = sentence + [0] * (maxlen - len(sentence))
data_pad_index.append(padded_seq)
data_pad = np.array(data_pad_index)
return data_pad
def make_one_hot(label, n_label):
"""
label表转成one-hot向量
:param label: 输入标签值
:param n_label: 标签及分类的总数
:return: one-hot标签向量
"""
values = np.array(label)
label_vec = np.eye(n_label)[values]
return label_vec
产生训练模型需要的数据。
def load_dataset(data_path, vocab_dict, max_length, n_label):
"""
:param data_path: 输入数据路径
:param vocab_dict: 词典
:param max_length: 最大长度
:param n_label: 标签及分类的总数
:return:
"""
datas_index, datas_length, labels = read_data(data_path, vocab_dict, max_length)
datas_index = pad_sequences(datas_index, max_length)
labels_vec = make_one_hot(labels, n_label)
return datas_index, datas_length, labels_vec
模型的构建
我们创建一个类来构建模型,包括输入参数,输入数据占位符,LSTM模型,Attention模型。
def attention(inputs, attention_size, time_major=False):
if isinstance(inputs, tuple):
inputs = tf.concat(inputs, 2)
if time_major: # (T,B,D) => (B,T,D)
inputs = tf.transpose(inputs, [1, 0, 2])
hidden_size = inputs.shape[2].value
# Trainable parameters
w_omega = tf.Variable(tf.random_normal([hidden_size, attention_size], stddev=0.1))
b_omega = tf.Variable(tf.random_normal([attention_size], stddev=0.1))
u_omega = tf.Variable(tf.random_normal([attention_size], stddev=0.1))
v = tf.tanh(tf.tensordot(inputs, w_omega, axes=1) + b_omega)
vu = tf.tensordot(v, u_omega, axes=1, name='vu') # (B,T) shape
alphas = tf.nn.softmax(vu, name='alphas') # (B,T) shape
# the result has (B,D) shape
output = tf.reduce_sum(inputs * tf.expand_dims(alphas, -1), 1)
return output, alphas
首先构建计算图
class LSTMModel():
def __init__(self, embedding_dim, word_embedding, sequence_length, hidden_size,attention_size,
drop_keep_prob, n_class, learning_rate, l2_reg_lambda):
self.embedding_dim = embedding_dim
self.word_embedding = word_embedding
self.sequence_length = sequence_length
self.hidden_size = hidden_size
self.attention_size = attention_size
self.drop_keep_prob = drop_keep_prob
self.n_class = n_class
self.learning_rate = learning_rate
self.l2_reg_lambda = l2_reg_lambda
self.create_graph()
self.loss_optimizer()
self.predict_result()
def create_graph(self):
# Input placeholders
with tf.name_scope('Input_Layer'):
self.X = tf.placeholder(tf.int32, [None, self.sequence_length], name='input_x')
self.y = tf.placeholder(tf.float32, [None, self.n_class], name='input_y')
self.seq_length = tf.placeholder(tf.int32, [None], name='length')
# self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')
# Embedding layer
with tf.name_scope('Embedding_layer'):
embeddings_var = tf.Variable(self.word_embedding, trainable=True, dtype=tf.float32)
batch_embedded = tf.nn.embedding_lookup(embeddings_var, self.X)
print("batch_embedded:", batch_embedded)
# Dynamic BiRNN layer
with tf.name_scope('BiRNN_layer'):
forward_cell = tf.contrib.rnn.BasicLSTMCell(self.hidden_size, forget_bias=1.0, state_is_tuple=True)
forward_cell = tf.contrib.rnn.DropoutWrapper(forward_cell, output_keep_prob=self.drop_keep_prob)
backward_cell = tf.contrib.rnn.BasicLSTMCell(self.hidden_size, forget_bias=1.0, state_is_tuple=True)
backward_cell = tf.contrib.rnn.DropoutWrapper(backward_cell, output_keep_prob=self.drop_keep_prob)
outputs, last_states = tf.nn.bidirectional_dynamic_rnn(cell_fw=forward_cell,
cell_bw=backward_cell,
inputs=batch_embedded,
sequence_length=self.seq_length,
dtype=tf.float32,
time_major=False)
outputs = tf.concat(outputs, 2)
outputs = tf.transpose(outputs, [1, 0, 2])
print("lstm outputs:", outputs)
# Attention layer
with tf.name_scope('Attention_layer'):
outputs, _ = attention(outputs, self.attention_size, time_major=True)
print("attention outputs:", outputs)
# Fully connected layer
with tf.name_scope('Output_layer'):
W = tf.Variable(tf.random_normal([self.hidden_size * 2, self.n_class]), dtype=tf.float32)
b = tf.Variable(tf.random_normal([self.n_class]), dtype=tf.float32)
# self.y_outputs = tf.matmul(drop_outputs, W) + b
self.y_outputs = tf.add(tf.matmul(outputs, W), b, name="output")
self.l2_loss = tf.nn.l2_loss(W) + tf.nn.l2_loss(b)
print("y_outputs:", self.y_outputs)
计算损失函数,以及添加正则化:
def loss_optimizer(self):
# loss function
with tf.name_scope('Loss'):
self.loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=self.y_outputs, labels=self.y))
self.loss = self.loss + self.l2_loss * self.l2_reg_lambda
self.optimizer = tf.train.AdamOptimizer(learning_rate=self.learning_rate).minimize(self.loss)
预测结果:
def predict_result(self):
# Accuracy
with tf.name_scope('Accuracy'):
score = tf.nn.softmax(self.y_outputs, name="score")
self.predictions = tf.argmax(self.y_outputs, 1, name="predictions")
self.y_index = tf.argmax(self.y, 1)
correct_pred = tf.equal(tf.argmax(self.y_outputs, 1), tf.argmax(self.y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
模型的训练
产生batch数据的方法,每次只训练一个batch的数据。
def batch_generator(all_data , batch_size, shuffle=True):
"""
:param all_data : all_data整个数据集
:param batch_size: batch_size表示每个batch的大小
:param shuffle: 每次是否打乱顺序
:return: 一个batch的数据
"""
all_data = [np.array(d) for d in all_data]
data_size = all_data[0].shape[0]
print("data_size: ", data_size)
if shuffle:
p = np.random.permutation(data_size)
all_data = [d[p] for d in all_data]
batch_count = 0
while True:
if batch_count * batch_size + batch_size > data_size:
batch_count = 0
if shuffle:
p = np.random.permutation(data_size)
all_data = [d[p] for d in all_data]
start = batch_count * batch_size
end = start + batch_size
batch_count += 1
yield [d[start: end] for d in all_data]
训练模型前需要预训练一个word2vec词向量模型,结果保存为二进制文件word2vec_model.bin。然后设置参数,加载训练数据,新建模型,按batch训练模型,最后保存模型。
# -*- coding: utf-8 -*-
from __future__ import print_function
import os
import tensorflow as tf
# set parameters
embedding_dim = 100
sequence_length = 40
hidden_size = 64
attention_size = 64
batch_size = 128
n_class = 2
n_epochs = 500
learning_rate = 0.001
drop_keep_prob = 0.5
l2_reg_lambda = 0.01
early_stopping_step = 15
model_name = "lstm_attention.ckpt"
checkpoint_name = "lstm_attention.checkpoint"
model_pd_name = "lstm_attention.pb"
w2v_path = "word2vec_model.bin"
word_map_path = "wordIndexMap.txt"
train_data_path = "clickbait_train.txt"
# 读取预训练的词向量
vocab_dict, words_embedding = load_words_embedding(model, embedding_dim, word_map_path)
# 加载训练数据
X_train, X_train_length, y_train= load_dataset(train_data_path , vocab_dict, max_length, n_label)
# create model
model = LSTMModel(
embedding_dim=embedding_dim,
word_embedding=word_embedding,
sequence_length=sequence_length,
hidden_size=hidden_size,
attention_size=attention_size,
drop_keep_prob=drop_keep_prob,
n_class=n_class,
learning_rate=learning_rate,
l2_reg_lambda=l2_reg_lambda
)
# set minimize gpu use
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
# config = tf.ConfigProto()
# config.gpu_options.per_process_gpu_memory_fraction = 0.5
saver = tf.train.Saver()
# create session
with tf.Session(config=config) as sess:
sess.run(tf.global_variables_initializer())
# Batch generators
train_batch_generator = batch_generator([X_train, X_train_length, y_train], batch_size)
test_batch_generator = batch_generator([X_test, X_test_length, y_test], batch_size)
print("Start learning...")
best_loss = 100.0
temp_loss = 100.0
stopping_step = 0
for epoch in range(n_epochs):
loss_train = 0
loss_test = 0
accuracy_train = 0
accuracy_test = 0
print("epoch ", epoch)
num_batches = X_train.shape[0] // batch_size
for i in range(0, num_batches):
x_batch, y_batch, x_length = next(train_batch_generator)
loss_train_batch, train_acc, _ = sess.run([model.loss, model.accuracy, model.optimizer],
feed_dict={model.X: x_batch,
model.y: y_batch,
model.seq_length: x_length})
accuracy_train += train_acc
loss_train += loss_train_batch
loss_train /= num_batches
accuracy_train /= num_batches
# test model
num_batches = X_test.shape[0] // batch_size
for i in range(0, num_batches):
x_batch, y_batch, x_length = next(test_batch_generator)
loss_test_batch, test_acc = sess.run([model.loss, model.accuracy],
feed_dict={model.X: x_batch,
model.y: y_batch,
model.seq_length: x_length})
accuracy_test += test_acc
loss_test += loss_test_batch
accuracy_test /= num_batches
loss_test /= num_batches
print("train_loss: {:.4f}, test_loss: {:.4f}, train_acc: {:.4f}, test_acc: {:.4f}".format(
loss_train, loss_test, accuracy_train, accuracy_test))
if loss_test <= best_loss:
stopping_step = 0
best_loss = loss_test
else:
stopping_step += 1
temp_loss = loss_test
if stopping_step >= early_stopping_step:
print("training finished!")
break
# 模型保存为"ckpt"格式
saver.save(sess, model_name, latest_filename=checkpoint_name)
graph = tf.graph_util.convert_variables_to_constants(sess, sess.graph_def, ["Accuracy/score"]) # 填入输出tensor
# 模型保存为"pb"格式
tf.train.write_graph(graph, '.', model_pd_name, as_text=False)
Python预测结果
真实无标签数据,根据训练好的模型预测结果,数据是分好词的标题。数据格式如下图所示,每行一条数据。

具体预测代码,输入无标签的预测数据,并按照训练数据同样的预处理方法处理数据,然后加载训练好的模型,预测结果。
import tensorflow as tf
import numpy as np
import pandas as pd
def read_unlabel_data(data_path, vocab_dict, sequence_length):
"""
读取并处理真实无标签数据
:param data_path: 数据集路径
:param vocab_dict: 前面产生的词典
:param sequence_length: 输入模型最大长度控制,多则阶段,少则填充
:return:
datas_index: 由词序列转成的编号序列
datas_length:每条数据的长度
"""
fo = open(data_path, "r", encoding='utf8')
all_data = fo.readlines()
fo.close()
datas_index = []
datas_length = []
for line in all_data:
title = line.strip()
data_index = []
for word in title.split(" "):
try:
data_index.append(vocab_dict[word])
except:
data_index.append(0)
length = len(title.split(" "))
if length > sequence_length:
length = sequence_length
datas_index.append(data_index)
datas_length.append(length)
datas_index = pad_sequences(datas_index, max_length)
return datas_index, datas_length
# 读取预测数据
datas_index, datas_length = read_unlabel_data("unlabel_data.txt", vocab_dict, sequence_length)
with tf.Session() as sess:
tf.global_variables_initializer().run()
output_graph_def = tf.GraphDef()
with open('lstm_attention.pb', "rb") as f:
output_graph_def.ParseFromString(f.read())
_ = tf.import_graph_def(output_graph_def, name="")
sess.run(tf.global_variables_initializer())
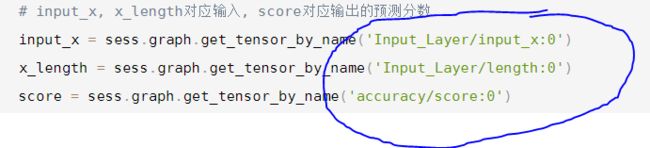
# input_x, x_length对应输入, score对应输出的预测分数
input_x = sess.graph.get_tensor_by_name('Input_Layer/input_x:0')
x_length = sess.graph.get_tensor_by_name('Input_Layer/length:0')
score = sess.graph.get_tensor_by_name('accuracy/score:0')
score_output = sess.run(score, feed_dict={input_x: datas_index, x_length: datas_length})
count = 0
pred_label = [0] * len(score_output)
for i in range(len(score_output)):
scores = [round(s, 6) for s in score_output[i]]
if scores[1] >= 0.5:
pred_label [i] = 1
print(pred_label)
上面的预测需要注意,模型创建时对应的输入输出,在预测时需要一一对应,特别是有name_scope时注意预测的写法。


输入中有作用域名(Input_Layer, Accuracy), 变量名(input_x, length, score),在预测时需要按下面的写法,才能获得tensor的值。
Java预测结果
用Java调用上面训练好的模型,首先需要下载一些包,如果是maven项目在pom.xml中添加两个依赖。
<dependency>
<groupId>org.tensorflowgroupId>
<artifactId>tensorflowartifactId>
<version>1.5.0version>
dependency>
<dependency>
<groupId>org.tensorflowgroupId>
<artifactId>libtensorflow_jniartifactId>
<version>1.5.0version>
dependency>
然后就可以写java预测代码了。
见下一篇博客:Java调用Tensorflow训练模型预测结