Java源码解析——volatile
1 定义及作用
1.1英文释义

1.2百度百科

1.3维基百科

译:
当被用于修饰变量时,Java volatile关键字可以保证:
(1)在所有版本的Java中,对volatile关键字修饰的变量的读写存在全局排序。这意味着每个访问volatile修饰字段的线程都 会去读取字段的当前值,而不是继续使用(可能存在地)字段的缓存值。(但是,并不能保证 读写volatile修饰字段与 读写常规字段 之间的相对顺序,这意味着它通常不是有用的线程结构。)
(2)在Java 5或更高版本中,对volatile关键字修饰字段的读和写建立了happens-before原则,非常像获取和释放互斥锁一 样。这个原则仅仅提供保证:一个特定语句的写内存操作对另一个特定语句是可见的。
volatile属性是线性化的。读取易volatile修饰的字段就像获取锁:将导致工作内存(参考后面Java内存模型小节)中缓存的变量副本无效,从内存中重新读取该字段的当前值。对volatile修饰字段的写就像释放锁:修改后的值将被写回内存。
1.4官方释义
![]()
译:Java编程语言中一个被用于修饰变量的关键词,被volatile修饰的变量具有被同时运行的线程异步修改的特性。
综上所述,volatile是Java(此处只针对java)编程语言中预定义的关键字,它被用作修饰java成员变量(属性),在java多线程环境中,能保证代码(代码最终会被编译器编译为机器操作指令)执行的有序性和操作结果在内存中的可见性。
2 背景知识补充
为更好地理解java volatile关键字的含义以及深层原理,本节将补充介绍以下知识:为更好地理解java volatile关键字的含义以及深层原理,本节将补充介绍以下知识:
(1)从操作系统层面,介绍线程的实现方式以及实现细节;
(2)从Java层面,介绍java线程创建和启动细节;
(3)计算机内存模型和Java内存模型;
读完(1)小节,对于操作系统如何实现线程会有一个大致地了解。第(2)小节,将通过跟踪源码的方式,向你展示java线程的创建以及启动过程,并结合第(1)的内容,得到一个重要结论:java线程和操作系统的内核线程是一一映射的关系,即“用户级线程与内核控制线程的连接”小节中的一对一模型。第(3)小节将首先详细介绍计算机内存模型,包括如下内容:CPU结构,CPU缓存,CPU缓存一致性协议MESI,为提升CPU性能而引入的StoreBuffer和InvalidQueue数据结构,引入StoreBuffer和InvalidQueue对CPU缓存一致性带来的问题以及通过内存屏障方式带来的解决方案。
2.1操作系统---线程实现方式及线程实现
2.1.1线程实现方式
线程已在许多系统中实现,但各系统的实现方式并不完全相同。在有的系统中,特别是一些数据库管理系统如Infomix,所实现的是用户级线程(UserLevel Threads);而另一些系统(如Macintosh和OS/2 操作系统)所实现的是内核支持(KernelSupported Threads); 还有一些系统如Solaris操作系统,则同时实现了这两种类型的线程。
2.1.11内核支持线程
对于通常的进程,无论是系统进程还是用户进程,进程的创建、撤消,以及要求由系统设备完成的I/O 操作,都是利用系统调用而进入内核,再由内核中的相应处理程序予以完成的。进程的切换同样是在内核的支持下实现的。因此我们说,不论什么进程,它们都是在操作系统内核的支持下运行的,是与内核紧密相关的。这里所谓的内核支持线程KST(Kernel Supported Threads),也都同样是在内核的支持下运行的,即无论是用户进程中的线程,还是系统进程中的线程,他们的创建、撤消和切换
等也是依靠内核,在内核空间实现的。此外,在内核空间还为每一个内核支持线程设置了一个线程控制块,内核是根据该控制块而感知某线程的存在,并对其加以控制。
这种线程实现方式主要有如下四个优点:
(1) 在多处理器系统中,内核能够同时调度同一进程中多个线程并行执行;
(2) 如果进程中的一个线程被阻塞了,内核可以调度该进程中的其它线程占有处理器运行,也可以运行其它进程中的线程;
(3) 内核支持线程具有很小的数据结构和堆栈,线程的切换比较快,切换开销小;
(4) 内核本身也可以采用多线程技术,可以提高系统的执行速度和效率。
内核支持线程的主要缺点是:对于用户的线程切换而言,其模式切换的开销较大,在同一个进程中,从一个线程切换到另一个线程时,需要从用户态转到内核态进行,这是因为用户进程的线程在用户态运行,而线程调度和管理是在内核实现的,系统开销较大。
2.1.12用户级线程
用户级线程ULT(User Level Threads)仅存在于用户空间中。对于这种线程的创建、撤消、线程之间的同步与通信等功能,都无须利用系统调用来实现。对于用户级线程的切换,通常发生在一个应用进程的诸多线程之间,这时,也同样无须内核的支持。由于切换的规则远比进程调度和切换的规则简单,因而使线程的切换速度特别快。可见,这种线程是与内核无关的。我们可以为一个应用程序建立多个用户级线程。在一个系统中的用户级线程的数目可以达到数百个至数千个。由于这些线程的任务控制块都是设置在用户空间,而线程所执行的操作也无须内核的帮助,因而内核完全不知道用户级线程的存在。
值得说明的是,对于设置了用户级线程的系统,其调度仍是以进程为单位进行的。在采用轮转调度算法时,各个进程轮流执行一个时间片,这对诸进程而言似乎是公平的。但假如在进程A中包含了一个用户级线程,而在另一个进程B中含有100 个用户级线程,这样,进程A中线程的运行时间将是进程B中各线程运行时间的100倍;相应地,其速度要
快上100 倍。
假如系统中设置的是内核支持线程,则调度便是以线程为单位进行的。在采用轮转法调度时,是各个线程轮流执行一个时间片。同样假定进程A 中只有一个内核支持线程,而在进程B中有100 个内核支持线程。此时进程B可以获得的CPU时间是进程A的100倍,且进程B可使100 个系统调用并发工作。
使用用户级线程方式有许多优点,主要表现在如下三个方面:
(1) 线程切换不需要转换到内核空间,对一个进程而言,其所有线程的管理数据结构均在该进程的用户空间中,管理线程切换的线程库也在用户地址空间运行。因此,进程不必切换到内核方式来做线程管理,从而节省了模式切换的开销,也节省了内核的宝贵资源。
(2) 调度算法可以是进程专用的。在不干扰操作系统调度的情况下,不同的进程可以根据自身需要,选择不同的调度算法对自己的线程进行管理和调度,而与操作系统的低级调度算法是无关的。
(3) 用户级线程的实现与操作系统平台无关,因为对于线程管理的代码是在用户程序内的,属于用户程序的一部分,所有的应用程序都可以对之进行共享。因此,用户级线程甚至可以在不支持线程机制的操作系统平台上实现。
用户级线程实现方式的主要缺点在于如下两个方面:
(1) 系统调用的阻塞问题。在基于进程机制的操作系统中,大多数系统调用将阻塞进程,因此,当线程执行一个系统调用时,不仅该线程被阻塞,而且进程内的所有线程都会被阻塞。而在内核支持线程方式中,则进程中的其它线程仍然可以运行。
(2) 在单纯的用户级线程实现方式中,多线程应用不能利用多处理机进行多重处理的优点。内核每次分配给一个进程的仅有一个CPU,因此进程中仅有一个线程能执行,在该线程放弃CPU之前,其它线程只能等待。
2.1.13组合方式
有些操作系统把用户级线程和内核支持线程两种方式进行组合,提供了组合方式ULT/KST 线程。在组合方式线程系统中,内核支持多KST线程的建立、调度和管理,同时,也允许用户应用程序建立、调度和管理用户级线程。一些内核支持线程对应多个用户级线程,程序员可按应用需要和机器配置对内核支持线程数目进行调整,以达到较好的效果。组合方式线程中,同一个进程内的多个线程可以同时在多处理器上并行执行,而且在阻塞一个线程时,并不需要将整个进程阻塞。所以,组合方式多线程机制能够结合KST和ULT两者的优点,并克服了其各自的不足。
2.1.2线程实现
不论是进程还是线程,都必须直接或间接地取得内核的支持。由于内核支持线程可以直接利用系统调用为它服务,故线程的控制相当简单;而用户级线程必须借助于某种形式的中间系统的帮助方能取得内核的服务,故在对线程的控制上要稍复杂些。
2.1.21内核支持线程的实现
在仅设置了内核支持线程的OS中,一种可能的线程控制方法是,系统在创建一个新进程时,便为它分配一个任务数据区PTDA(Per Task Data Area),其中包括若干个线程控制块TCB空间,如图2-15所示。在每一个TCB中可保存线程标识符、优先级、线程运行的CPU状态等信息。虽然这些信息与用户级线程TCB中的信息相同,但现在却是被保存在内核空间中。

每当进程要创建一个线程时,便为新线程分配一个TCB,将有关信息填入该TCB中,并为之分配必要的资源,如为线程分配数百至数千个字节的栈空间和局部存储区,于是新创建的线程便有条件立即执行。当PTDA
中的所有TCB 空间已用完,而进程又要创建新的线程时,只要其所创建的线程数目未超过系统的允许值(通常为数十至数百个),系统可再为之分配新的TCB空间;在撤消一个线程时,也应回收该线程的所有资源和TCB。可见,内核支持线程的创建、撤消均与进程的相类似。在有的系统中为了减少创建和撤消一个线程时的开销,在撤消一个线程时,并不立即回收该线程的资源和TCB,当以后再要创建一个新线程时,便可直接利用已被撤消但仍保持有资源和TCB的线程作为新线程。
内核支持线程的调度和切换与进程的调度和切换十分相似,也分抢占式方式和非抢占方式两种。在线程的调度算法上,同样可采用时间片轮转法、优先权算法等。当线程调度选中一个线程后,便将处理机分配给它。当然,线程在调度和切换上所花费的开销,要比进程的小得多。
2.1.22用户级线程的实现
用户级线程是在用户空间实现的。所有的用户级线程都具有相同的结构,它们都运行在一个中间系统的上面。当前有两种方式实现的中间系统,即运行时系统和内核控制线程。
1) 运行时系统(Runtime System)
所谓“运行时系统”,实质上是用于管理和控制线程的函数(过程)的集合,其中包括用于创建和撤消线程的函数、线程同步和通信的函数以及实现线程调度的函数等。正因为有这些函数,才能使用户级线程与内核无关。运行时系统中的所有函数都驻留在用户空间,并作为用户级线程与内核之间的接口。
在传统的OS中,进程在切换时必须先由用户态转为核心态,再由核心来执行切换任务;而用户级线程在切换时则不需转入核心态,而是由运行时系统中的线程切换过程来执行切换任务。该过程将线程的CPU状态保存在该线程的堆栈中,然后按照一定的算法选择一个处于就绪状态的新线程运行,将新线程堆栈中的CPU状态装入到CPU相应的寄存器中,一旦将栈指针和程序计数器切换后,便开始了新线程的运行。由于用户级线程的切换无需进入内核,且切换操作简单,因而使用户级线程的切换速度非常快。
不论在传统的OS 中,还是在多线程OS 中,系统资源都是由内核管理的。在传统的OS中,进程是利用OS 提供的系统调用来请求系统资源的,系统调用通过软中断(如trap)机制进入OS内核,由内核来完成相应资源的分配。用户级线程是不能利用系统调用的。当线程需要系统资源时,是将该要求传送给运行时系统,由后者通过相应的系统调用来获得系统资源的。
2) 内核控制线程
这种线程又称为轻型进程LWP(Light Weight Process)。每一个进程都可拥有多个LWP,同用户级线程一样,每个LWP都有自己的数据结构(如TCB),其中包括线程标识符、优先级、状态,另外还有栈和局部存储区等。它们也可以共享进程所拥有的资源。LWP 可通过系统调用来获得内核提供的服务,这样,当一个用户级线程运行时,只要将它连接到一个LWP上,此时它便具有了内核支持线程的所有属性。这种线程实现方式就是组合方式。
在一个系统中的用户级线程数量可能很大,为了节省系统开销,不可能设置太多的LWP,而把这些LWP 做成一个缓冲池,称为“线程池”。用户进程中的任一用户线程都可以连接到LWP池中的任何一个LWP上。为使每一用户级线程都能利用LWP与内核通信,可以使多个用户级线程多路复用一个LWP,但只有当前连接到LWP上的线程才能与内核通信,其余进程或者阻塞,或者等待LWP。而每一个LWP都要连接到一个内核级线程上,这样,通过LWP可把用户级线程与内核线程连接起来,用户级线程可通过LWP来访问内核,但内核所看到的总是多个LWP 而看不到用户级线程。亦即,由LWP 实现了在内核与用户级线程之间的隔离,从而使用户级线程与内核无关。图2-16 示出了利用轻型进程作为中间系统时用户级线程的实现方法。
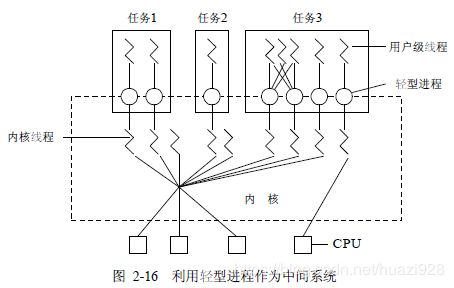
当用户级线程不需要与内核通信时,并不需要LWP;而当要通信时,便需借助于LWP,而且每个要通信的用户级线程都需要一个LWP。例如,在一个任务中,如果同时有5 个用户级线程发出了对文件的读、写请求,这就需要有5 个LWP 来予以帮助,即由LWP 将对文件的读、写请求发送给相应的内核级线程,再由后者执行具体的读、写操作。如果一个任务中只有4 个LWP,则只能有4 个用户级线程的读、写请求被传送给内核线程,余下的一个用户级线程必须等待。
在内核级线程执行操作时,如果发生阻塞,则与之相连接的多个LWP也将随之阻塞,进而使连接到LWP上的用户级线程也被阻塞。如果进程中只包含了一个LWP,此时进程也应阻塞。这种情况与前述的传统OS一样,在进程执行系统调用时,该进程实际上是阻塞的。但如果在一个进程中含有多个LWP,则当一个LWP阻塞时,进程中的另一个LWP可继续执行;即使进程中的所有LWP全部阻塞,进程中的线程也仍然能继续执行,只是不能再去访问内核。
2.1.23用户级线程与内核控制线程的连接
实际上,在不同的操作系统中,实现用户级线程与内核控制线程的连接有三种不同的模型:一对一模型、多对一模型和多对多模型。
1) 一对一模型
该模型是为每一个用户线程都设置一个内核控制线程与之连接,当一个线程阻塞时,允许调度另一个线程运行。在多处理机系统中,则有多个线程并行执行。该模型并行能力较强,但每创建一个用户线程相应地就需要创建一个内核线程,开销较大,因此需要限制整个系统的线程数。Windows 2000、Windows NT、OS/2 等系统上都实现了该模型。
2) 多对一模型
该模型是将多个用户线程映射到一个内核控制线程,为了管理方便,这些用户线程一般属于一个进程,运行在该进程的用户空间,对这些线程的调度和管理也是在该进程的用户空间中完成。当用户线程需要访问内核时,才将其映射到一个内核控制线程上,但每次只允许一个线程进行映射。该模型的主要优点是线程管理的开销小,效率高,但当一个线程在访问内核时发生阻塞,则整个进程都会被阻塞,而且在多处理机系统中,一个进程的多个线程无法实现并行。
3) 多对多模型
该模型结合上述两种模型的优点,将多个用户线程映射到多个内核控制线程,内核控制线程的数目可以根据应用进程和系统的不同而变化,可以比用户线程少,也可以与之相同。
2.2Java线程创建和启动细节
本小节内容将通过源码追踪的方式,了解java线程的创建以及启动过程。使用源码版本为openjdk-jdk8-b120,可从Github获取所用源码(https://github.com/unofficial-openjdk/openjdk/tags?after=jdk9-b09)。
接下来以一段java线程代码开始我们的分析:

先分析上图中第12行标红的代码,该行代码是在调用Thread类的构造函数,打开相应的构造器一探究竟,如下图所示:
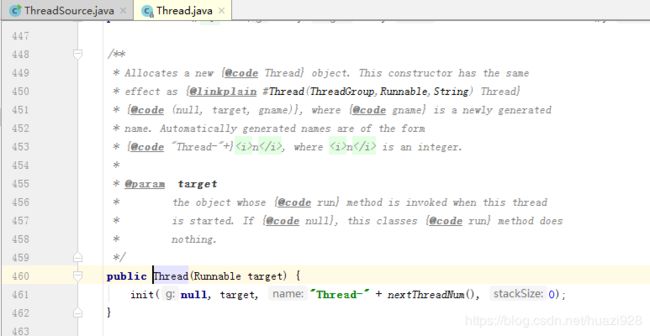
翻译:449-453行,分配一个新的Thread对象。此构造器和下图中的构造函数具有相同效果,其中“gname”是一个新生成的名称。自动生成的名称以“Thread-n”的形式存在,n是一个整数。456-458行:当这个线程开始时,target对象的run方法将被调用。如果run方法体为空,那这个类方法什么也不做。
可以看到461行调用了Thread内部的init()方法,具体代码如下图:

翻译:用当前访问控制上下文对线程进行初始化。
查看341行代码详情,如下:
/**
* Initializes a Thread. // 初始化一个线程
*
* @param g the Thread group //参数g:线程组
* @param target the object whose run() method gets called //参数target:该对象的run()方法会被调用
* @param name the name of the new Thread //参数name:新线程的名称
* @param stackSize the desired stack size for the new thread, or
* zero to indicate that this parameter is to be ignored. //参数stackSize:新线程期望的栈大小,或者为0表明这个参数被忽略
* @param acc the AccessControlContext to inherit, or //参数acc:要继承的访问控制上下文,如果不对该参数传值,就使用AccessController.getContext()对相应属性赋值
* AccessController.getContext() if null
*/
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc) {
//对线程名字进行校验,不允许为空
if (name == null) {
throw new NullPointerException("name cannot be null");
}
//对线程名进行赋值
this.name = name.toCharArray();
//为保证后面g.checkAccess()中g不为空,需要在此进行参数校验,如果g==null,则需要对其赋值
Thread parent = currentThread();
SecurityManager security = System.getSecurityManager();
if (g == null) {
/* Determine if it's an applet or not */
//如果security已经存在,那么调用security.getThreadGroup()对参数g赋值
if (security != null) {
g = security.getThreadGroup();
}
//如通过security.getThreadGroup()进行赋值而参数g仍旧为空,那就使用父线程的线程组进行赋值
if (g == null) {
g = parent.getThreadGroup();
}
}
//判断ThreadGroup(g)是否为rootGroup,是的话,则需要校验其修改线程组的权限
g.checkAccess();
//检查是否有所需要的权限(SUBCLASS_IMPLEMENTATION_PERMISSION)
if (security != null) {
if (isCCLOverridden(getClass())) {
security.checkPermission(SUBCLASS_IMPLEMENTATION_PERMISSION);
}
}
//增加线程组中未开始线程的数量
g.addUnstarted();
//为线程对象的各个属性赋值
this.group = g;
this.daemon = parent.isDaemon();
this.priority = parent.getPriority();
if (security == null || isCCLOverridden(parent.getClass()))
this.contextClassLoader = parent.getContextClassLoader();
else
this.contextClassLoader = parent.contextClassLoader;
this.inheritedAccessControlContext =
acc != null ? acc : AccessController.getContext();
this.target = target;
setPriority(priority);
if (parent.inheritableThreadLocals != null)
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
/* Stash the specified stack size in case the VM cares */
this.stackSize = stackSize;
/* Set thread ID */
tid = nextThreadID();
}构造函数(new Thread(new Runnable...))的调用链路到此就结束了,过程中并没有出现操作系统线程接口相关的调用,那Java线程到底是如何与操作系统内核线程对应起来的呢?答案就在下图中第19行代码,接下来让我们跟踪th.start()调用链路。
start()方法的源码以及解释如下所示:
/**
* Causes this thread to begin execution; the Java Virtual Machine
* calls the run method of this thread. //导致这个线程开始执行; java虚拟机调用本线程的run方法
*
* The result is that two threads are running concurrently: the
* current thread (which returns from the call to the
* start method) and the other thread (which executes its
* run method). //结果是两个线程同时运行:当前线程(在调用start方法后返回),另一个线程(执行它的run方法)
*
* It is never legal to start a thread more than once. //对一个线程执行超过1次的start操作都是不允许的
* In particular, a thread may not be restarted once it has completed
* execution. //尤其是,一旦线程执行完成它就不可能重新启动
*
* @exception IllegalThreadStateException if the thread was already
* started. //如果线程已经启动,调用此方法会抛出 IllegalThreadStateException
* @see #run()
* @see #stop()
*/
public synchronized void start() {
/**
* This method is not invoked for the main method thread or "system"
* group threads created/set up by the VM. Any new functionality added
* to this method in the future may have to also be added to the VM.
* //VM创建/设置的主方法线程或“系统”组线程,不调用此方法。将来添加到此方法中的任何新功能可能也必须添加到VM。
* A zero status value corresponds to state "NEW". //状态值为0的话相当于线程状态为”NEW“
*/
if (threadStatus != 0)
throw new IllegalThreadStateException();
/* Notify the group that this thread is about to be started
* so that it can be added to the group's list of threads
* and the group's unstarted count can be decremented. */
//注意启动线程时,该线程所属线程组的threads列表应相应地增加,为启动线程列表的size也要递减
group.add(this);
boolean started = false;
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
/* do nothing. If start0 threw a Throwable then
it will be passed up the call stack */ //不做任何事情。如果start0方法抛出异常,该异常会被向上传递到调用栈
}
}
}
继续跟踪start0()方法,如下图所示,发现此处是采用JNI调用。关于java代码如何调用在系统本地采用其他语言实现的功能接口,可参考JNI传送门,此处不再赘述。
![]()
接下来我们找到start0()方法的native实现,找到对应的Thread.c文件,在openjdk源码中的如下位置:
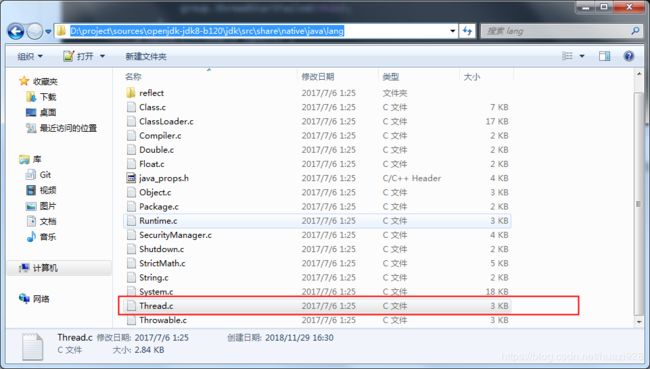
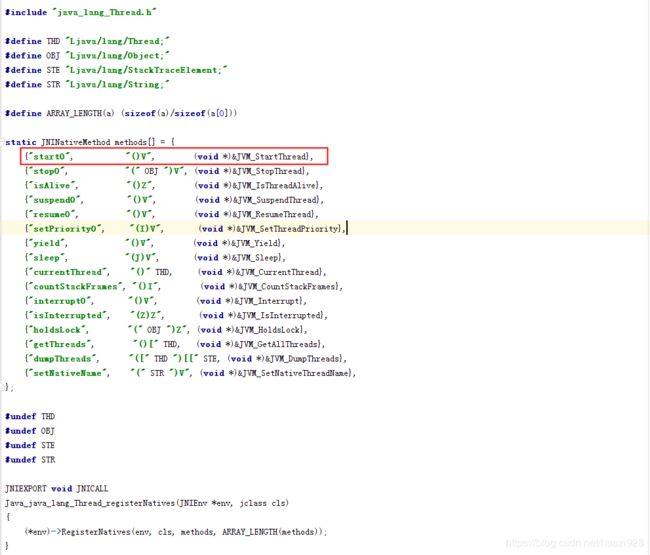
由于后续的调用链路相当长且繁琐,所以笔者通过Xmind树结构的形式给出该方法后续的调用链路,对每一个文件所涉及的方法及源码都有相应说明,详情如下图:

通过对源码的追踪和分析,可以得出以下3个结论:第一,java线程在其构造器被调用时,并不会真正创建与系统内核线程与之映射,在执行start()方法的过程中,C++层面线程以及系统平台层面的线程才会被真正创建;第二,java线程与系统内核线程之间是一一对应的关系,具体证据请仔细阅读上图;第三,结合2.1节中“用户级线程与内核控制线程的连接”板块,我们知道Java用户级线程与内核控制线程的连接模型为一对一模型。
2.3计算机内存模型和Java内存模型
2.3.1计算机内存模型
https://www.cnblogs.com/adinosaur/p/6243605.html
https://blog.csdn.net/gupao123456/article/details/81221641
http://www.importnew.com/10589.html
https://blog.csdn.net/yhb1047818384/article/details/79604976
https://www.cnblogs.com/gtarcoder/p/5295281.html
http://g.oswego.edu/dl/jmm/cookbook.html
https://blog.csdn.net/gupao123456/article/details/81221641(java内存模型以及计算机内存模型)
2.3.2Java内存模型
http://www.importnew.com/10589.html(深入java内存模型)
http://www.importnew.com/29860.html(内存屏障和volatile语义)
5 参考资料
《计算机操作系统》