(自总结详细资料)如何在CentOS7下安装hadoop2.8分布式集群
不管在什么地方,什么时候,学习是快速提升自己的能力的一种体现!!!!!!!!!!!
前些时候学习了大数据方面的知识,于是就开始搭建Hadoop集群,在网上搜罗了很多关于安装Hadoop的文章,有的写得有点模糊(可能是因为浏览者看到文章之后想留起来方便以后自己查看同时又不怎么注意细节就直接复制到自己的博客上的吧),有的写得也是很详细的,真心感谢用心去写文章的人。送人玫瑰,手有余香。
今天又重新搭一遍,也是边搭边写博客,给自己做个记录方便以后有个提示 。同时希望能给看到这篇文章的伙伴带来一些些帮助,OK,多余的话我也不多说了。
准备环境:
3台服务器(CentOS7 64位 点击如何下载安装CentOS7) ,
每台服务器都已安装好JDK(如何卸载centos7自带JDK安装自己的JDK1.8),
建议把虚拟机的主机名也改改 如何修改虚拟机主机名,这样可以更直观一点,也能顾名思义
远程连接虚拟机工具 xshell5 下载安装使用xshell5
master 192.168.31.128
slave1 192.168.31.129
slave2 192.168.31.130
准备资料 hadoop-2.8.0.tar.gz
hadoop下载地址 http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
打开下载链接之后 点击红框链接下载安装包

以上环境和资料准备好之后就要开始了
使用xshell连接上虚拟机,如下图:
输入命令 vim /etc/hosts 编辑hosts文件 在最后加上
192.168.31.128 master
192.168.31.129 slave1
192.168.31.130 slave2
如下图:

注:每一台服务器(master、slave1、slave2)都需要修改这个配置
弄好上面操作之后,
先配置每台服务器之间可以免密码登录也就是SSH免密码登录,因为CentOS默认是没有开启免密码登录的所以需要我们自己手动操作
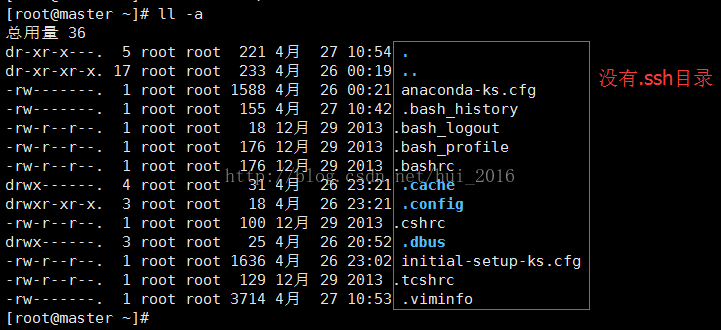
没有配置过ssh一般是不会有 .ssh 目录的 ,可以先通过命令 ll -a(以点开头的目录或文件都是隐藏的,所以需要加上 -a 才能看到) 查看是否存在 .ssh 目录
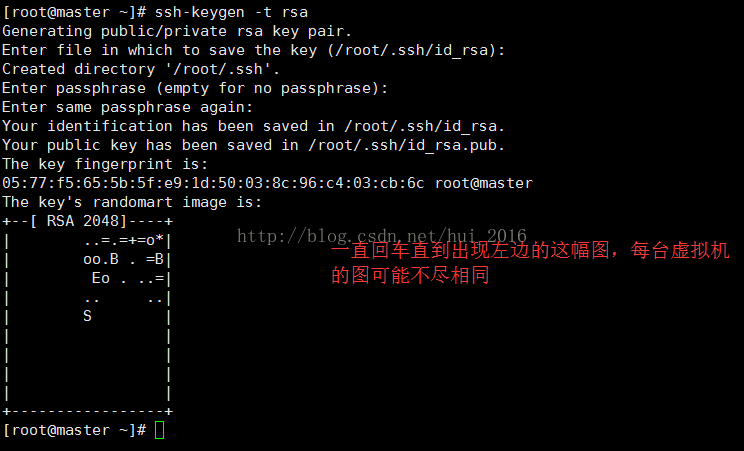
输入命令 ssh-keygen -t rsa 生成key(公钥、私钥), 然后一直回车
注:每一台服务器(master、slave1、slave2)都需要生成这个key,还是给个图吧
slave1 :

slave2:

再次通过 ll -a 查看是否有存在 .ssh 目录
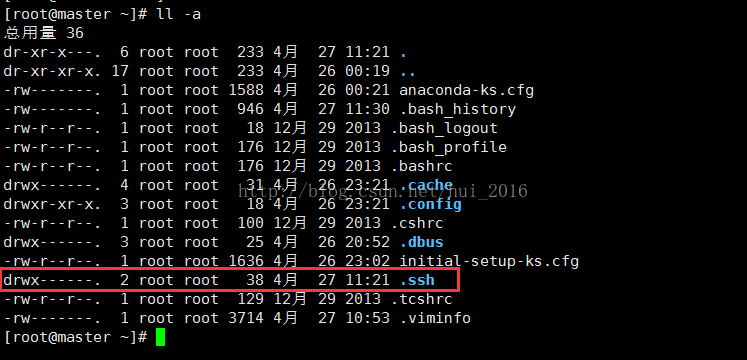
这时候就都存在了,回到master机,通过命令cd .ssh 进入 .ssh 目录会发现有两个文件
id_rsa (私钥)
id_rsa.pub (公钥)

通过命令 cat id_rsa.pub >> authorized_keys 将 id_rsa.pub(公钥)里的内容合并(也可以说复制)到authorized_keys 文件中,authorized_keys 文件本身是不存在的,但是通过上面这条命令就可以自动的创建出来并且把 id_rsa.pub里的内容复制到authorized_keys中去,不相信的话,大家可以自己对比下id_rsa.pub里的内容跟 authorized_keys的是否一致
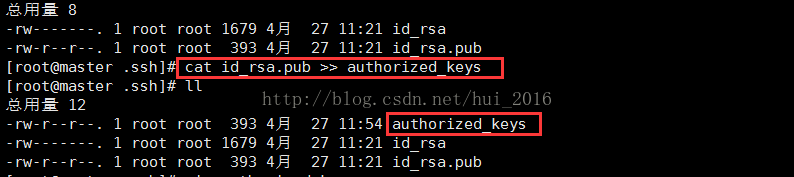
在master机上通过命令 ssh root@slave1 cat ~/.ssh/id_rsa.pub >> authorized_keys 意思是将slave1 虚拟机中 ~/.ssh/目录下的 id_rsa.pub(公钥)文件的内容复制到master 中的 authorized_keys文件中
因为现在还没配置好 ssh 免密码跨服务登录,所以在操作这条命令时候会提示你 :
Are you sure you want to continue connecting (yes/no)? 意思是:你确定要继续连接?
这时候 就直接可以输入 yes , 按回车之后又会提示你输入虚拟机的root密码;输完密码之后按回车
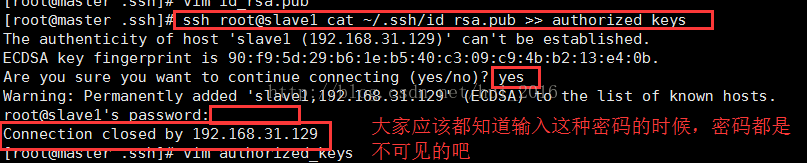
到这步时我出现了 : Connection closed by 192.168.31.129 意思就是:连接被192.168.31.129关闭了 这样的错误,
错误原因:因为我新装的虚拟机,之前没有关闭防火墙,所以造成了连接失败了。
解决方案:关闭防火墙及禁用其开机自启 ,三台服务器都要关闭及禁用
systemctl stop firewalld.service #关闭firewall防火墙
systemctl disable firewalld.service #禁止firewall开机启动
firewall-cmd --state #查看防火墙状态 ,如果显示 not running 就是关闭了,如果显示 running就是在运行中

PS:CentOS 7.0以上版本默认使用的是firewall作为防火墙,网上有一大堆说要重新配置和设置什么iptables之类的,我个人觉得完全不用配置iptables,费那么多事干嘛,就直接使用的默认的就可以了
关闭防火墙之后重新使用 ssh root@slave1 cat ~/.ssh/id_rsa.pub >> authorized_keys 命令,这时候只会提示输入密码就可以了,不会再提示你是否需要继续连接了,如图:
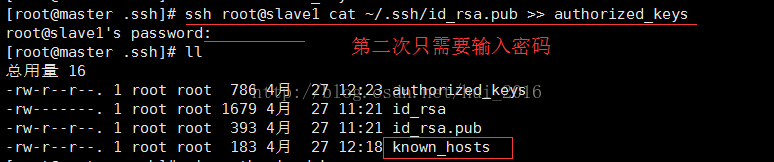
这时候会多出一个叫 known_hosts文件(很重要) 可以先看看里面是什么内容

但是现在先不管他,等下会说到,先完成其他的先
现在同样要把slave2的公钥给弄到master的authorized_keys中去
ssh root@slave2 cat ~/.ssh/id_rsa.pub >> authorized_keys 还是按照上面的操作进行

这时候可以打开authorized_keys文件看看里面是不是都有三台虚拟机的公钥了 命令 vim authorized_keys
接下来需要把master机器中 ~/.ssh/ 目录下的authorized_keys文件和known_hosts文件拷贝到slave1和slave2中的 ~/.ssh/目录下 跨服务拷贝命令 scp 文件名1 文件名2 文件名3 ... 主机名或IP:拷贝到目的地的目录路径
如:
scp authorized_keys known_hosts slave1:~/.ssh/
scp authorized_keys known_hosts slave2:~/.ssh/

从图片中大家可以注意到跨服务拷贝也还是需要需要填写密码的,因为ssh免密码登录还没配置好,等下配置好了以后就不用在输入密码了,省很多事
拷过去之后可以先看看slave1和slave2有没有这两个文件,看过都有之后 就可以通过master免密码登录slave1和slave2了,测试是否完成免登陆命令 ssh 主机名或IP 如 ssh slave1 或 ssh 192.168.31.129
如下图:

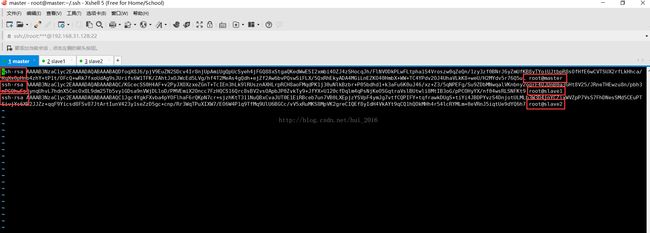
大家可以从这幅图中看到master机器连接slave1时不用密码就直接可以连接上了,可是当slave1连接master时就出现了询问,有时还会出现要输密码,这是怎么回事呢,原因是因为上面提到的 known_hosts 文件中没有master的加密算法在里面,可以回去看看是不是,因此复制到slave1和slave2中也还是没有

所以就会这样询问你是否要连接,可能大家就会想到那是不是以后每次slave1或slave2连接master时都需要询问呢,然而不是的,只有第一次时才会询问,之后就会把master的加密算法永久保存到slave1与slave2中的known_hosts文件里,从上上一张图片中的 Warning: Permanently added 'master,192.168.31.128' (ECDSA) to the list of known hosts. 这句话也可以看出来
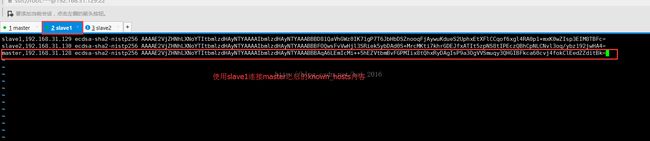
如果大家想尽可能的不要询问怎么办,可以先把master的authorized_keys和known_hosts文件拷到slave1中,然后再使用slave1连接master,询问一次之后就会把master的加密算法保存到known_hosts中,然后可以把master的这条算法复制到master的known_hosts中,然后再由master统一拷贝其他的slave中去,这样其他的slave连接master时就不会再询问了(如果在这里有不懂的伙伴可以留言给我我看到会第一时间回复大家)
此时 ssh 就已经配置好了。
第一段总结:
1、有可能有些伙伴会觉得我搭建Hadoop集群干嘛要解决ssh免密码登录的问题呢,其实是因为搭建集群环境是需要每台服务器都要互通的,如果没有解决免密码登录的问题就会在集群之间相互通信时相互要密码,等候管理员输入密码的这个时间就算是几秒钟的时间在这个大数据时代大家也可以想象下,代价可想而知吧。再说在集群启动时也是要通过master(namenode)带动其他的子节点启动的,所以ssh免密码是必须的
2、关于ssh免密码登录的原理,我也只是略懂一二,就不在这里瞎BB了,以免误导大家,下面有一张在网上看到的ssh原理图可以参考参考

接下来就要开始搭建Hadoop了
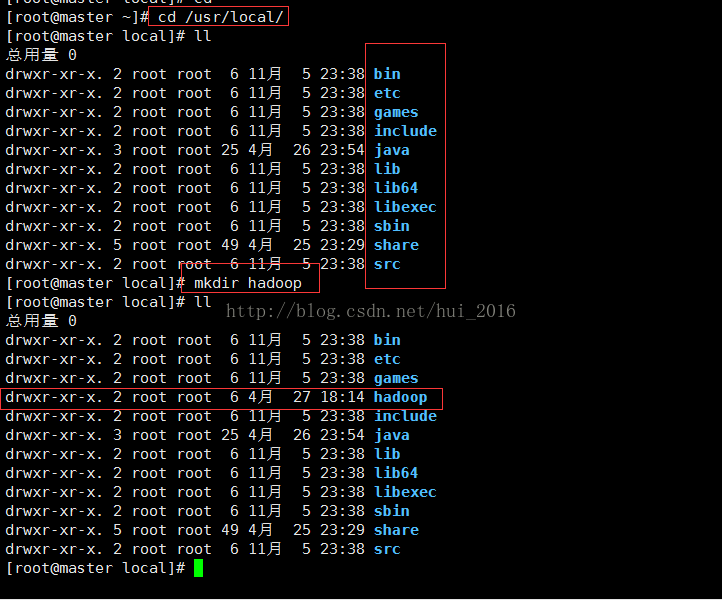
通过命令 mkdir hadoop 创建一个 hadoop 目录 ,我个人喜欢在 /usr/local/ 目录下创建,如下图:
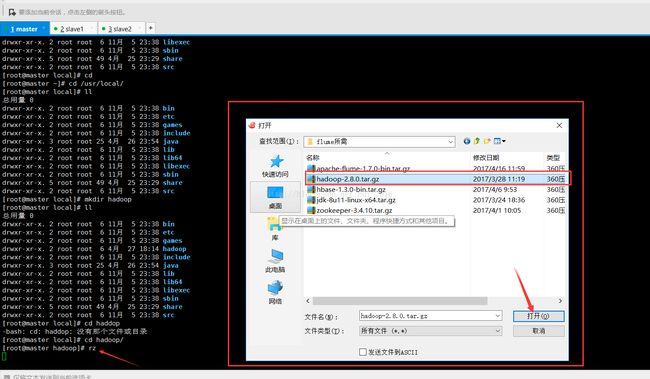
进入hadoop目录通过 rz 命令导入hadoop的安装包,rz 命令是在安装插件之后才会有效的,如果没有安装过 ,可以通过 yum -y install lrzsz 命令安装这个插件,安装完之后就可以使用了,这个插件的好处在于你在什么目录下导入的安装包,安装包就会在什么目录下,不会跑到根目录下
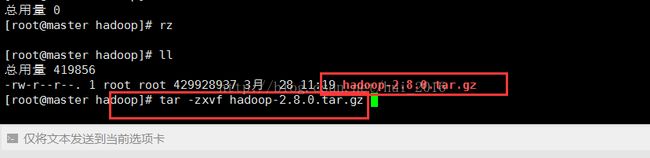
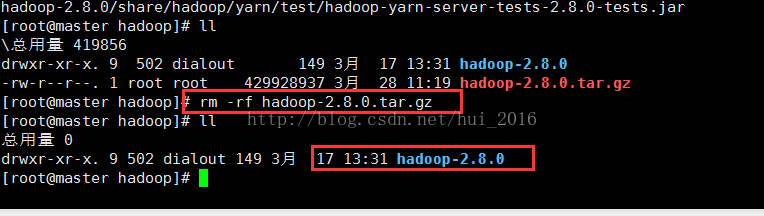
导入安装包之后,通过解压命令 tar -zxvf hadoop-2.8.0.tar.gz 解压hadoop安装包
解压完之后,我会删掉安装包,因为占内存 命令 rm -rf hadoop-2.8.0.tar.gz
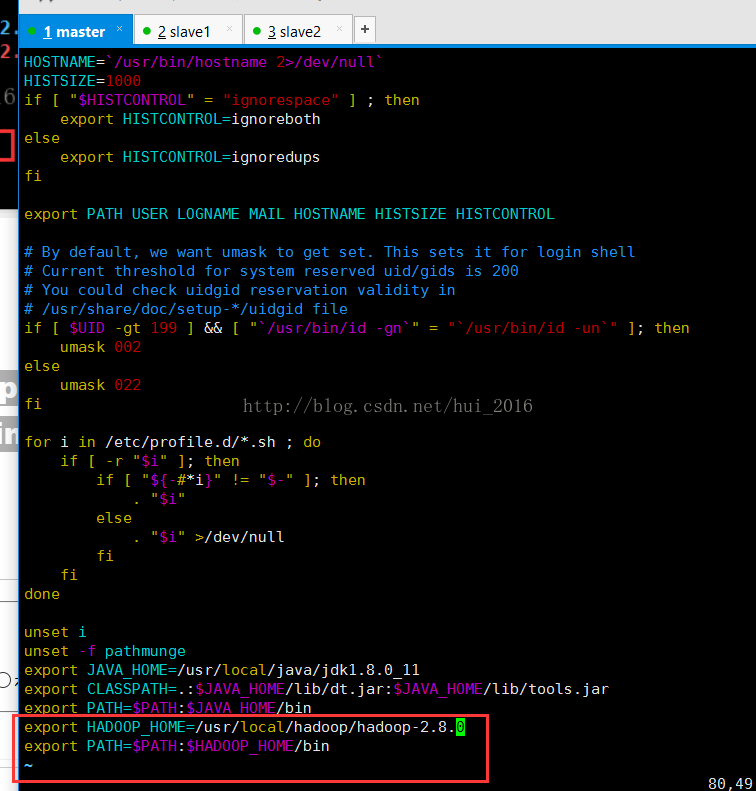
接下来配置环境变量 vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.8.0
export PATH=$PATH:$HADOOP_HOME/bin
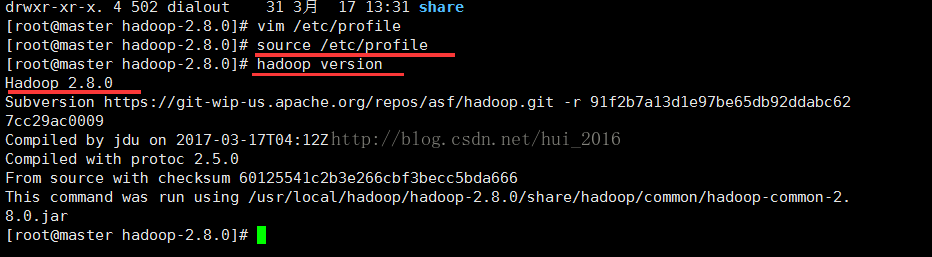
保存并退出 使用 source /etc/proflie 命令使配置生效 输入 命令 hadoop version查看信息
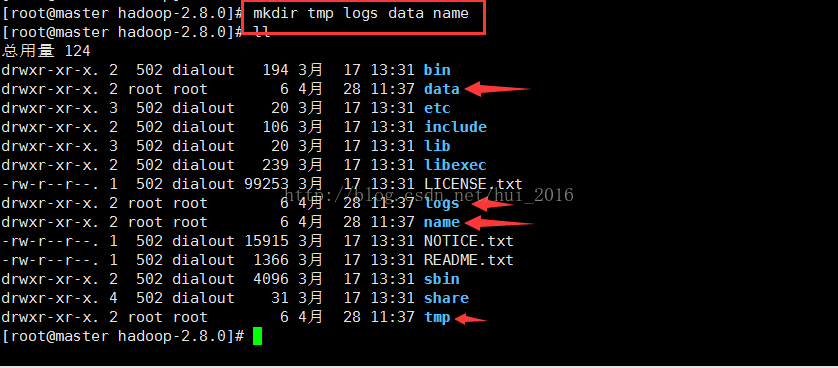
在 hadoop-2.8.0目录下创建 以下目录 tmp、logs、data、name (至于为什么要创建这些目录请在看完等下的配置文件写法之后参考hadoop文档 hadoop中文文档 网上也有很多关于配置的详解 )
命令:mkdir tmp logs data name 这条命令意思是一次性创建多个目录 如果想创建父子(层级)目录 请使用命令
mkdir -p parent/child
进入 etc/hadoop目录下配置hadoop相关文件(注意:这个etc不是根目录的etc,是hadoop里面的etc)
所有要配置的都在这里
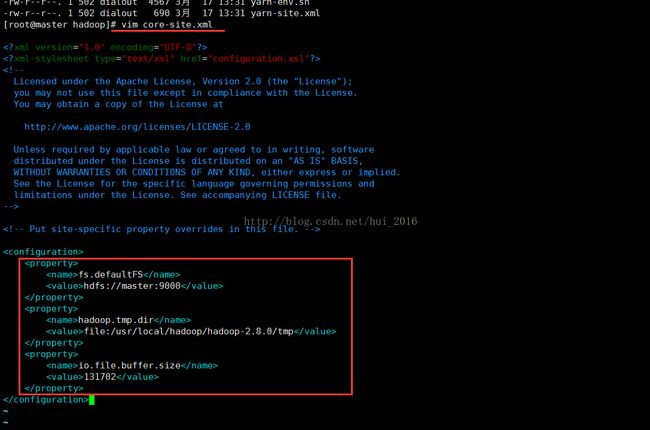
先配置core-site.xml文件 vim core-site.xml
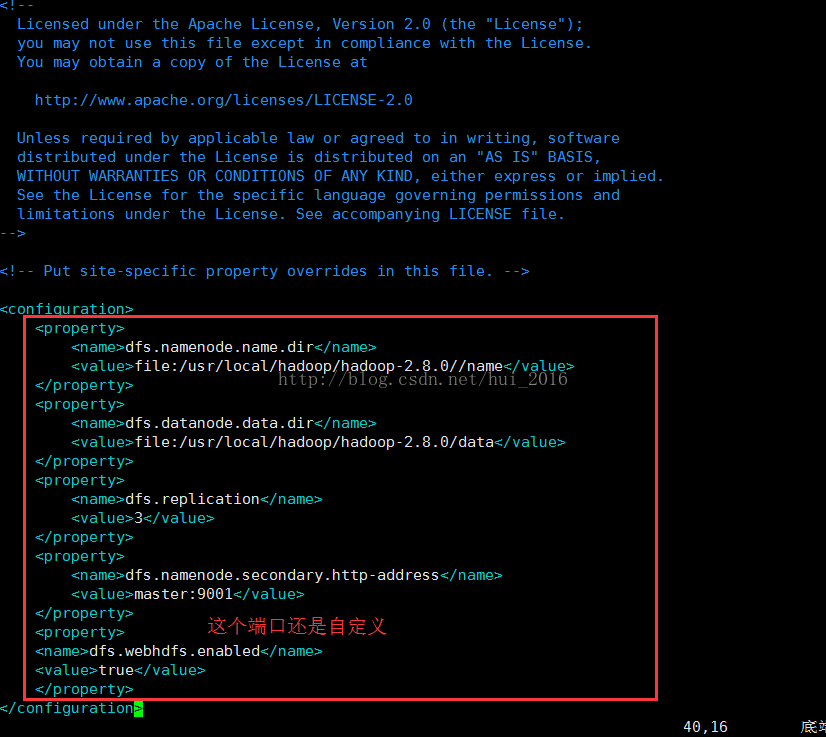
保存并退出 编辑hdfs-site.xml 文件 命令 vim hdfs-site.xml
保存并退出 编辑 mapred-site.xml 文件 这个文件本身是不存在的需要拷贝一份
cp mapred-site.xml.template mapred-site.xml (意思是:拷贝一份相同的文件并命名为xxx)
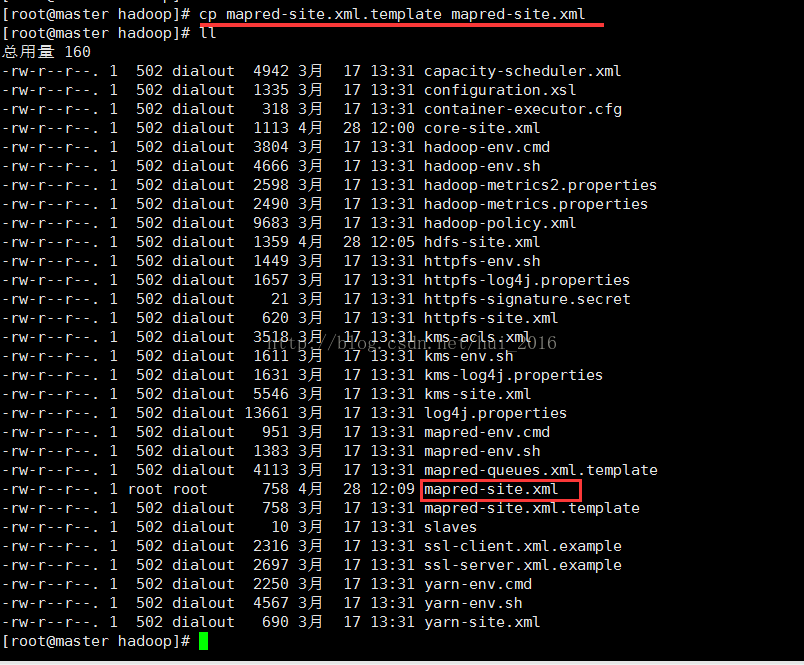
编辑 mapred-site.xml文件
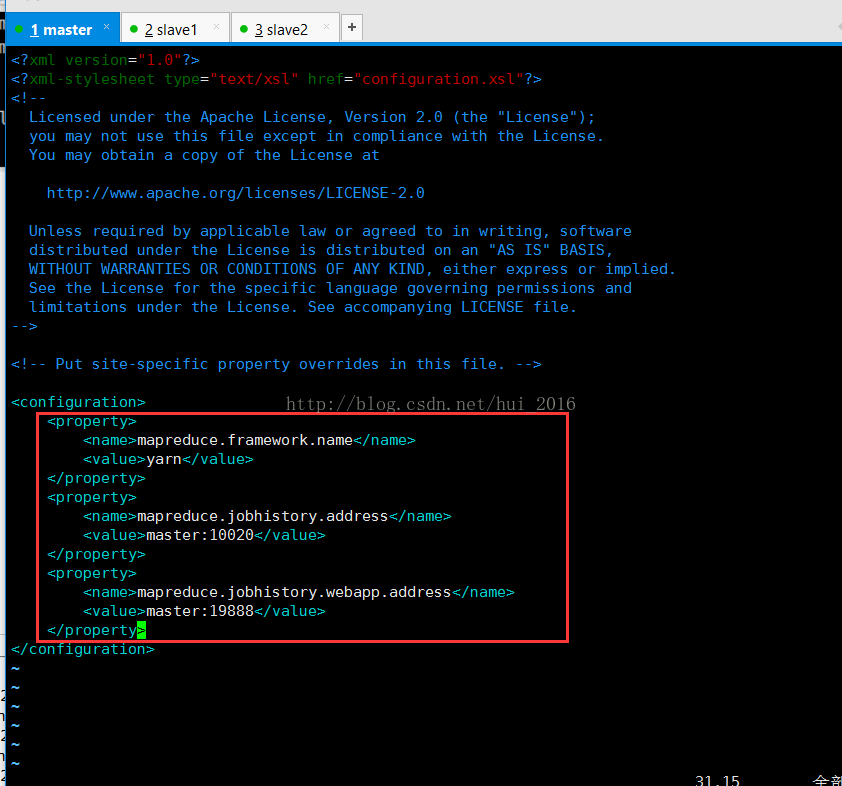
保存并退出 编辑 yarn-site.xml 文件 命令: vim yarn-site.xml
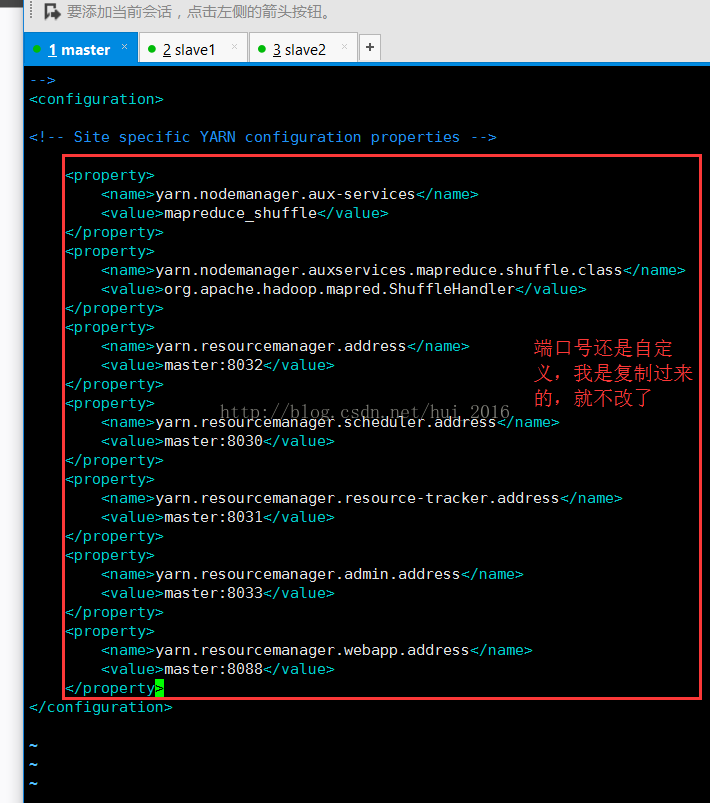
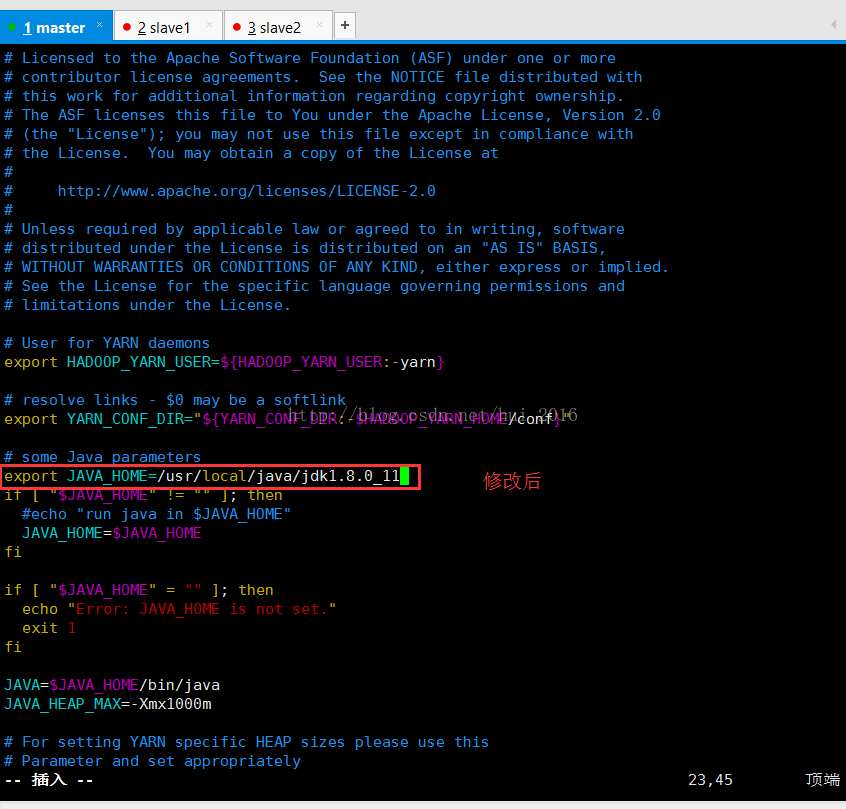
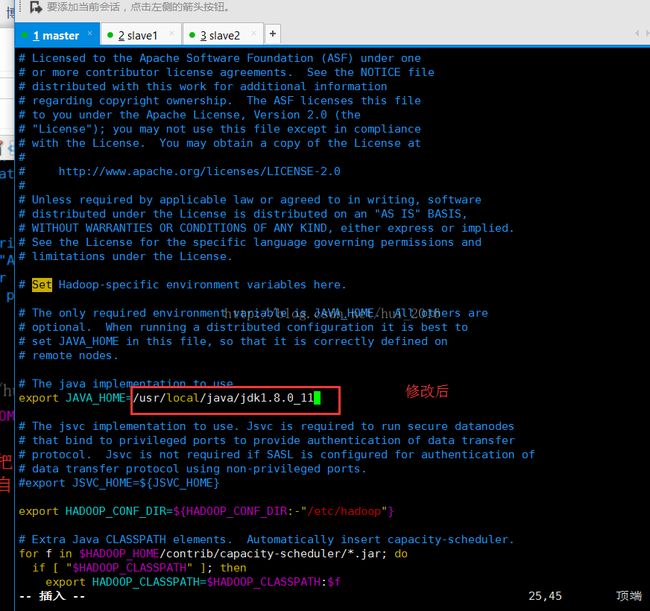
保存并退出 编辑 yarn-env.sh 和 hadoop-env.sh 文件 命令 vim yarn-env.sh vim hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_11
yarn-env.sh 文件修改如下两图:

hadoop-env.sh文件修改如下两图

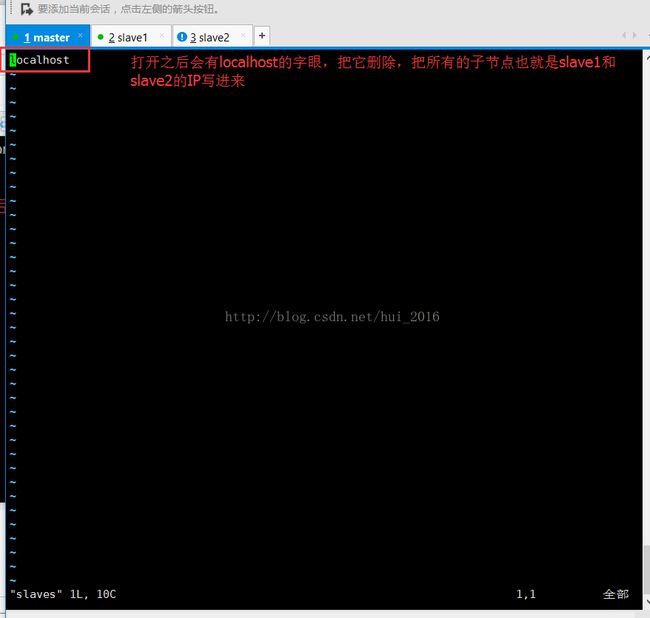
接下来配置 slaves 文件 把所有的子节点的IP或者主机名写进去 命令 vim slaves

现在所有的配置都已经完成了,接下来把hadoop2.8.0拷贝到slave1和slave2里,还是一样像master机中的 /usr/local/目录下创建一个hadoop目录存放hadoop-2.8.0,我就不重复创建命令了,直接开始拷贝 回到hadoop目录下 cd /usr/local/hadoop/
拷贝命令 :
scp -r hadoop-2.8.0 slave1:/usr/local/hadoop/
scp -r hadoop-2.8.0 slave2:/usr/local/hadoop/

请耐心等待拷贝........拷完slave1之后在拷贝到slave2
拷完之后确认salve1和slave2有hadoop-2.8.0之后不用再修改和配置salve1和slave2中的配置文件,之前已经在master配置好了,
当然如果你每台机的JDK路径都放得不太一样的话,那就要修改yarn-env.sh 文件的JAVA_HOME的路径了。
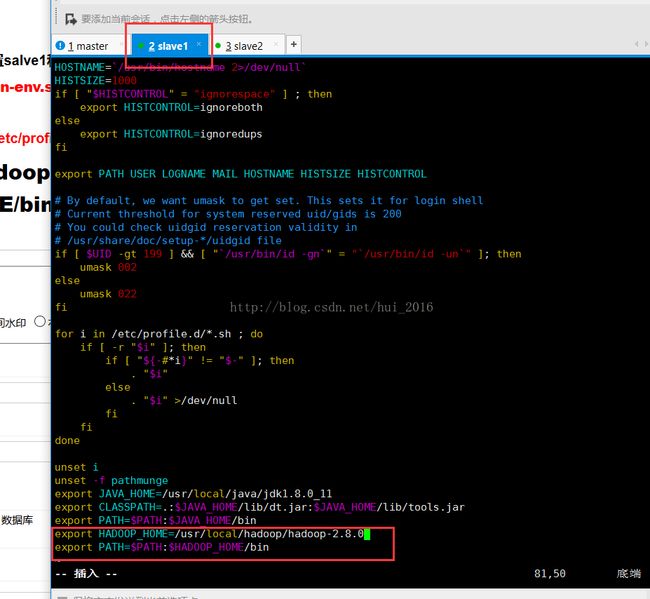
OK ,接下来就要配置slave1和slave2的环境变量了 同样的 vim /etc/profile 在最后加上
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.8.0
export PATH=$PATH:$HADOOP_HOME/bin

输入命令格式化一个新的分布式文件系统 bin/hdfs namenode -format (只在master机上格式化,从机不用)
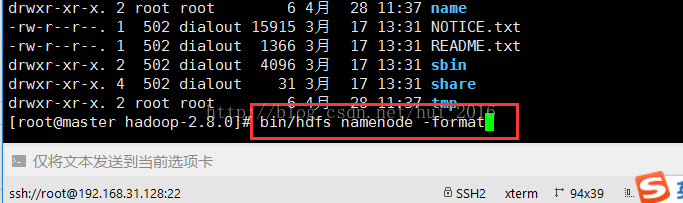
等待格式化...

格式化成功
OK ,现在可以启动hadoop了(注:只需要在master机启动即可,master会启动其他的子节点)
在hadoop-2.8.0目录下进行启动,启动命令:
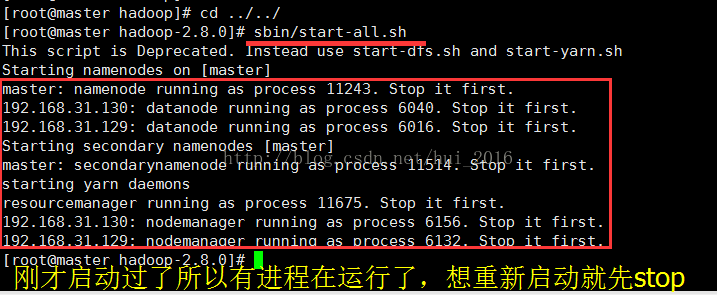
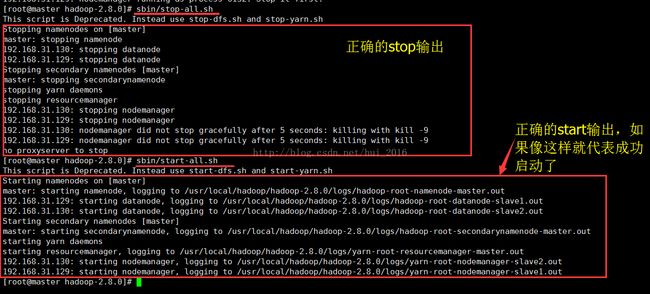
全部启动sbin/start-all.sh(我一般用这个比较多),也可以分开sbin/start-dfs.sh、sbin/start-yarn.sh
停止命令:sbin/stop-all.sh

乍一看蒙圈了,这是什么鬼来着,我什么时候把192.168.31.130192.168.31.129这两个IP连起来写过了?看到ssh这三个字母的时候我还以为是我配置的ssh免密码登录出现问题了呢,想想不对呀,明明用 ssh+ip时可以免密码登录呀,然后仔细的看了报错的提示,
大概意思是说:不能解析这个主机名 192.168.31.130192.168.31.129,名称是未知的
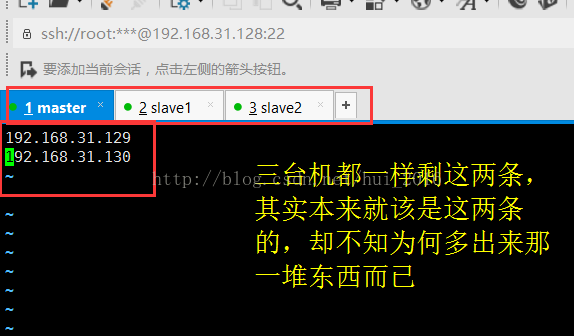
想了一下没想出来,就开始一顿的度娘,希望度娘能帮我,可是网上虽有相近的错误但是却无法解决我的错误,于是就自己回头看报错的详细信息,发现我的master和两个salve启动都是没有问题的就是多了 192.168.31.130192.168.31.129 这个东西,就想着难道是之前配置的slaves文件出现错误了??,不应该呀,自己也不会傻到把这个东西写进去的。没办法就进入slaves文件看了看,我去 这一看直接吓尿了,出现了什么?如图所示:
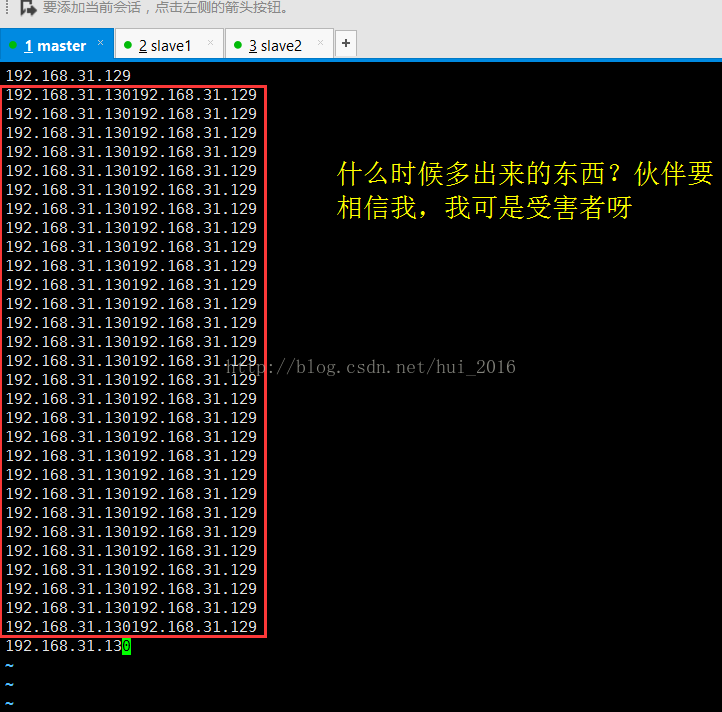
这里有,slave1和slave2会不会也有? 啊啊啊....还真有!!!!!
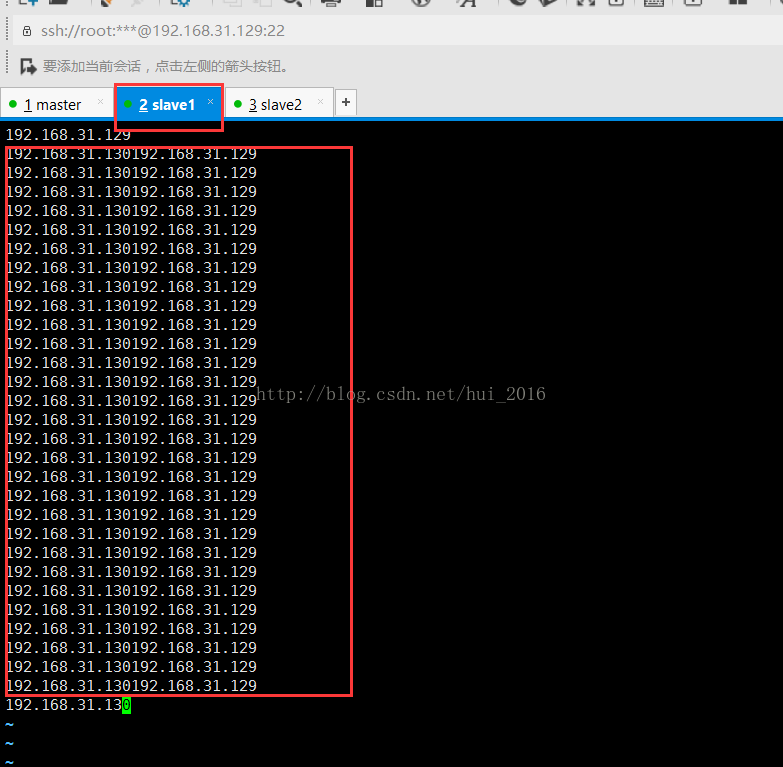
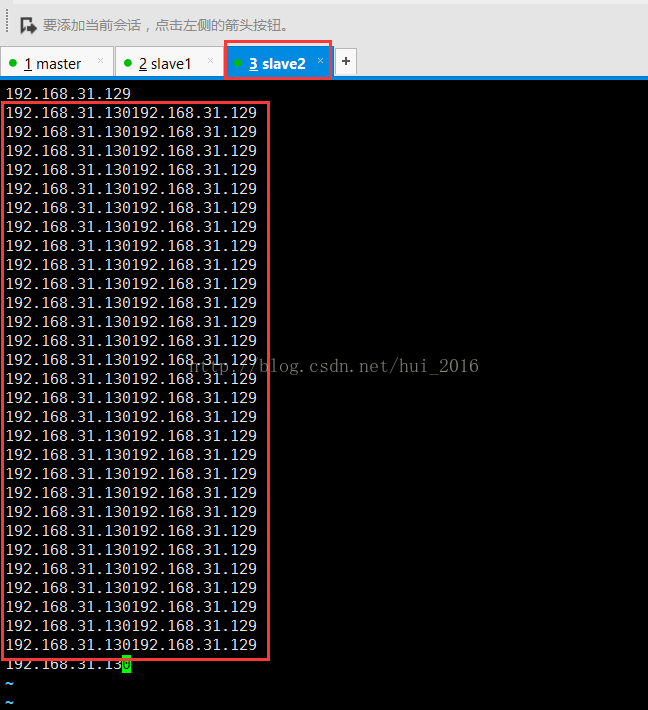
赶紧把红框里的那一堆东西删了 三台都删掉
删了之后重新启动,发现 如下图:
先stop-all 然后在start-all
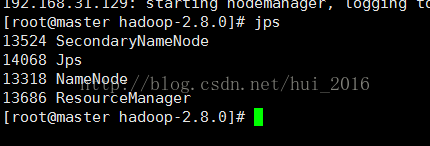
通过 命令 jps 查看master和slave1、slave2的启动进程
master:
13524 SecondaryNameNode
14068 Jps
13318 NameNode
13686 ResourceManager
slave1:
6852 NodeManager
7094 Jps
6727 DataNode

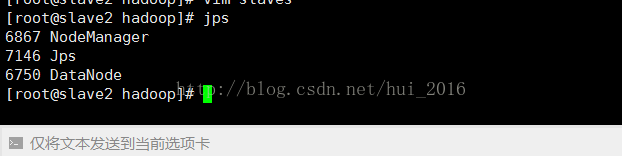
salve2:
6867 NodeManager
7146 Jps
6750 DataNode
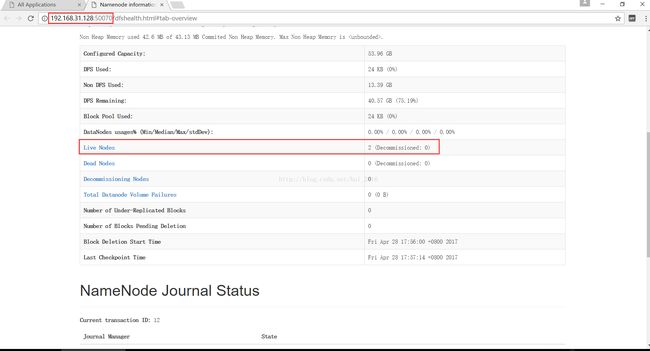
也可以通过web访问的方式查看hadoop
http://192.168.31.128:8088

http://192.168.31.128:50070
总结:到现在为止所有的配置和测试搭建都已成功了,先给自己掌声鼓励下,大数据时代的水远远不止于搭建了一个hadoop集群这么浅,还有更深的海洋需要我们去征服,去探索....大家一起加油一起成长,最后说一句:如果你也搭建成功了,顶一下呗
如果此文章有什么不对的地方请路过的大神指出,以免误人子弟