基于Kubernetes的Spark集群部署实践
-
快速部署:安装1000台级别的Spark集群,在Kubernetes集群上只需设定worker副本数目replicas=1000,即可一键部署。
-
快速升级:升级Spark版本,只需替换Spark镜像,一键升级。
-
弹性伸缩:需要扩容、缩容时,自动修改worker副本数目replicas即可。
-
高一致性:各个Kubernetes节点上运行的Spark环境一致、版本一致
-
高可用性:如果Spark所在的某些node或pod死掉,Kubernetes会自动将计算任务,转移到其他node或创建新pod。
-
强隔离性:通过设定资源配额等方式,可与WebService应用部署在同一集群,提升机器资源使用效率,从而降低服务器成本。
docker build -t index.caicloud.io/spark:1.5.2 . docker build -t index.caicloud.io/zeppelin:0.5.6 zeppelin/
docker login index.caicloud.io docker pull index.caicloud.io/spark:1.5.2 docker pull index.caicloud.io/zeppelin:0.5.6
docker login index.docker.io docker pull index.docker.io/caicloud/spark:1.5.2 docker pull index.docker.io/caicloud/zeppelin:0.5.6
# namespace/namespace-spark-cluster.yaml apiVersion: v1 kind: Namespace metadata: name: "spark-cluster" labels: name: "spark-cluster"
创建Namespace: $ kubectl create -f namespace/namespace-spark-cluster.yaml 查看Namespace: $ kubectl get ns NAME LABELS STATUS defaultActive spark-cluster name=spark-cluster Active 使用Namespace: (${CLUSTER_NAME}和${USER_NAME}可在kubeconfig文件中查看) $ kubectl config set-context spark --namespace=spark-cluster --cluster=${CLUSTER_NAME} --user=${USER_NAME} $ kubectl config use-context spark
# replication-controller/spark-master-controller.yaml kind: ReplicationController apiVersion: v1 metadata: name: spark-master-controller spec: replicas: 1 selector: component: spark-master template: metadata: labels: component: spark-master spec: containers: - name: spark-master image: index.caicloud.io/spark:1.5.2 command: ["/start-master"] ports: - containerPort: 7077 - containerPort: 8080 resources: requests: cpu: 100m
创建Master-ReplicationController: $ kubectl create -f replication-controller/spark-master-controller.yaml replicationcontroller "spark-master-controller" created
# service/spark-master-service.yaml kind: Service apiVersion: v1 metadata: name: spark-master spec: ports: - port: 7077 targetPort: 7077 selector: component: spark-master
创建Master-Service: $ kubectl create -f service/spark-master-service.yaml service "spark-master"created
# service/spark-webui.yaml kind: Service apiVersion: v1 metadata: name: spark-webui namespace: spark-cluster spec: ports: - port: 8080 targetPort: 8080 selector: component: spark-master
创建spark-webui-service: $ kubectl create -f service/spark-webui.yaml service "spark-webui" created
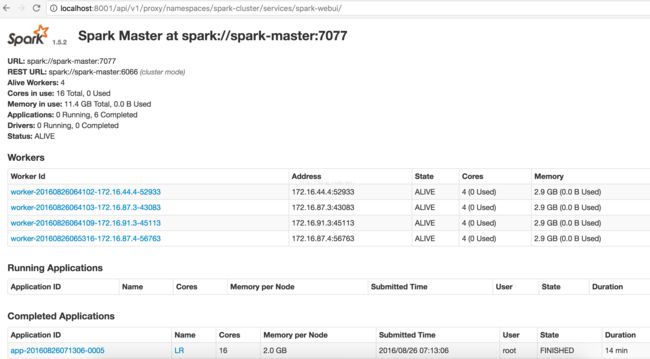
$ kubectl get rc NAME DESIRED CURRENT AGE spark-master-controller 1 1 23h $ kubectl get svc NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE spark-master 10.254.106.297077/TCP 1d spark-webui 10.254.66.138 8080/TCP 18h $ kubectl get pods NAME READY STATUS RESTARTS AGE spark-master-controller-b3gbf 1/1 Running 0 23h
kubectl proxy --port=8001
# replication-controller/spark-worker-controller.yaml kind: ReplicationController apiVersion: v1 metadata: name: spark-worker-controller spec: replicas: 4 selector: component: spark-worker template: metadata: labels: component: spark-worker spec: containers: - name: spark-worker image: index.caicloud.io/spark:1.5.2 command: ["/start-worker"] ports: - containerPort: 8081 resources: requests: cpu: 100m
$ kubectl create -f replication-controller/spark-worker-controller.yaml replicationcontroller"spark-worker-controller" created
$ kubectl get pods | grep worker
NAME READY STATUS RESTARTS AGE
spark-worker-controller-1h0l7 1/1 Running 0 4h
spark-worker-controller-d43wa 1/1 Running 0 4h
spark-worker-controller-ka78h 1/1 Running 0 4h
spark-worker-controller-sucl7 1/1 Running 0 4h
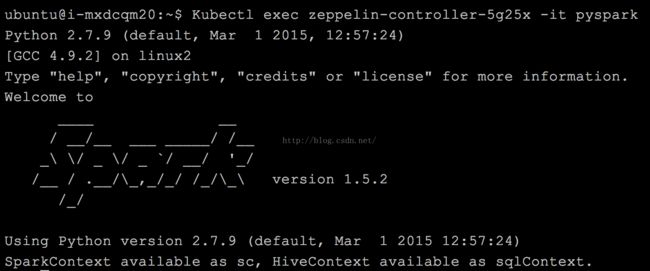
$ kubectl exec spark-worker-controller-1h0l7 -it bash
$ cd /opt/spark
# 提交python spark任务
./bin/spark-submit \
--executor-memory 4G \
--master spark://spark-master:7077 \
examples/src/main/python/wordcount.py \
"hdfs://hadoop-namenode:9000/caicloud/spark/data"
# 提交scala spark任务
./bin/spark-submit
--executor-memory 4G
--master spark://spark-master:7077
--class io.caicloud.LinearRegression
/nfs/caicloud/spark-mllib-1.0-SNAPSHOT.jar
"hdfs://hadoop-namenode:9000/caicloud/spark/data"
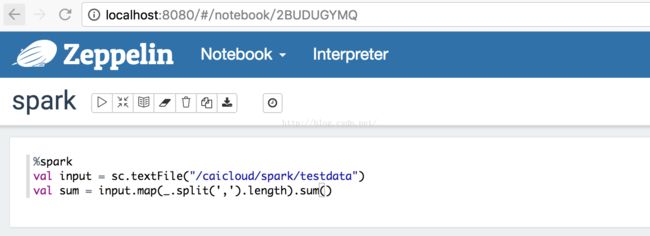
$ kubectl create -f replication-controller/zeppelin-controller.yaml
replicationcontroller "zeppelin-controller"created
查看zeppelin:
$ kubectl get pods -l component=zeppelin
NAME READY STATUS RESTARTS AGE
zeppelin-controller-5g25x 1/1 Running 0 5h
$ kubectl port-forward zeppelin-controller-5g25x 8080:8080
$ sudo apt-get install nfs-common
$ sudo mkdir -p /data1T5
$ sudo mount -t nfs 10.57.*.33:/data1T5 /data1T5
$ kubectl create -f nfs/nfs_pv.yaml
$ kubectl create -f nfs/nfs_pvc.yaml
# nfs/nfs_pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: spark-cluster
spec:
capacity:
storage: 1535Gi
accessModes:
- ReadWriteMany
nfs:
server: 10.57.*.33
path: "/data1T5"
# nfs/nfs_pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: spark-cluster
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1535Gi
$ kubectl delete rc spark-master-controller
$ kubectl create -f nfs/spark-master-controller.nfs.yaml
$ kubectl delete rc spark-worker-controller
$ kubectl create -f nfs/spark-worker-controller.nfs.yaml
$ kubectl exec spark-worker-controller-1h0l7 -it bash
root@spark-worker-controller-1h0l7:/# ls -al /data1T5/