深度学习(二十一):循环神经网络RNN
这是一系列深度学习的介绍,本文不会涉及公式推导,主要是一些算法思想的随笔记录。
适用人群:深度学习初学者,转AI的开发人员。
编程语言:Python
参考资料:吴恩达老师的深度学习系列视频
吴恩达老师深度学习笔记整理
唐宇迪深度学习入门视频课程
深度学习500问
RNN&LSTM
笔记下载:深度学习个人笔记完整版
序列模型(Sequence Model)
首先我们要明确什么是序列数据,摘取百度百科词条:时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。
这是时间序列数据的定义,当然这里也可以不是时间,比如文字序列,DNA序列,但总归序列数据有一个特点——后面的数据跟前面的数据有关系。
序列模型的应用

如上图,在进行语音识别时,给定了一个输入音频片段 X,并要求输出对应的文字记录Y 。这个例子里输入和输出数据都是序列模型,因为X 是一个按时播放的音频片段,输出Y是一系列单词。
音乐生成问题是使用序列数据的另一个例子,在这个例子中,只有输出数据Y 是序列,而输入数据X可以是空集,也可以是个单一的整数,这个数可能指代你想要生成的音乐风格,也可能是你想要生成的那首曲子的头几个音符。
在处理情感分类时,输入数据 X是序列,你会得到类似这样的输入:“There is nothing to like in this movie.”,你认为这句评论对应几星?
序列模型在DNA序列分析中也十分有用,你的DNA可以用A、C、G、T四个字母来表示。所以给定一段DNA序列,你能够标记出哪部分是匹配某种蛋白质的吗?
在机器翻译过程中,你会得到这样的输入句:“Voulez-vou chante avecmoi?”(法语:要和我一起唱么?),然后要求你输出另一种语言的翻译结果。
在进行视频行为识别时,你可能会得到一系列视频帧,然后要求你识别其中的行为。
在进行命名实体识别时,可能会给定一个句子要你识别出句中的人名。
等等,除了上述的应用,NLP是序列模型中最常见的问题,具体应用可以参照我的另一篇博客:自然语言处理研究的问题
RNN(Recurrent Neural Network)
RNN(Recurrent Neural Network)是一类用于处理序列数据的神经网络。
与普通神经网络的区别
RNN 的目的使用来处理序列数据。 在传统的神经网络模型中, 是从输入层到隐含层再到输出层, 层与层之间是全连接的, 每层之间的节点是无连接的。 但是这种普通的神经网络对于很多问题却无能无力。 例如, 你要预测句子的下一个单词是什么, 一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。
RNN 之所以称为循环神经网路, 即一个序列当前的输出与前面的输出也有关。 具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中, 即隐藏层之间的节点不再无连接而是有连接的, 并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
理论上, RNN 能够对任何长度的序列数据进行处理。 但是在实践中, 为了降低复杂性往往假设当前的状态只与前面的几个状态相关。
RNN结构

如上,x是输入序列,o是输出序列,s是隐藏单元,除了有像普通神经网络的从x到s,s到o的信息流,各个隐藏层之间是有连接的, 并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
循环神经网络用的激活函数经常是tanh,不过有时候也会用ReLU。
RNN的前向传播

如上图是RNN的前向传播示意图,隐藏层的输入a<0>一般用零向量处理,让我们看看每个隐藏单元的结构:
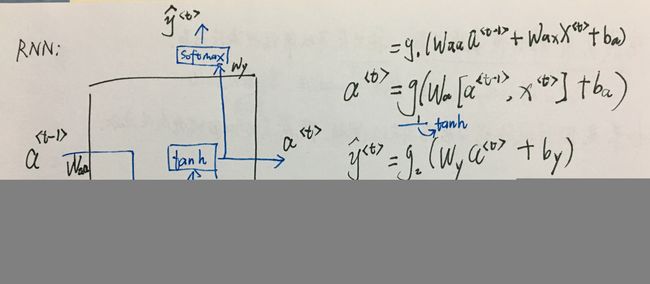
如上图,激活单元输出a,有两个分支,一个作为输出y的输入,一个作为下一层隐藏层的输入,对于前者,常用softmax作为激活函数(如图中g2),后者常用tanh作为激活函数(如图中g1)。


RNN的反向传播——BPTT
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。
BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。
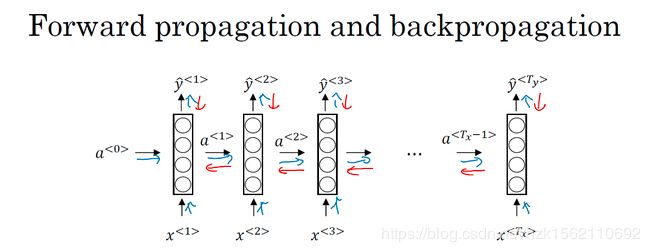
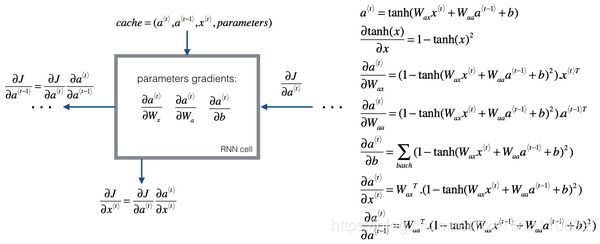
如上红色线即为反向传播方向,我们定义损失函数为交叉熵损失函数(Cross Entropy Loss),这是关于单个位置上或者说某个时间步上某个单词的预测值的损失函数L,然后得出整个序列的代价函数L,如下图所示:

RNN反向传播示意图:
RNN的缺点
1.计算量太大,不必要记住离自己太远的信息,即不擅长捕获长期依赖关系
2.计算过程中可能会梯度消失:很深很深的网络,100层,甚至更深,对这个网络从左到右做前向传播然后再反向传播。我们知道如果这是个很深的神经网络,从输出y_hat得到的梯度很难传播回去,很难影响靠前层的权重,很难影响前面层的计算。RNN具有同样的问题。
RNN的结构类型
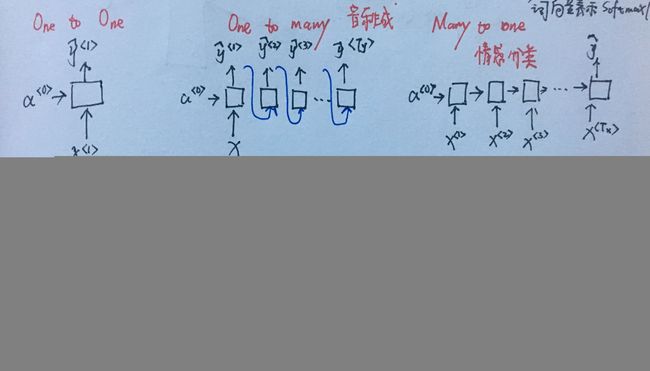
如上图,按照输入和输出的长度(输入长度Tx,输出长度Ty),分为以下几种类型结构:
一对一
这个可能没有那么重要,这就是一个小型的标准的神经网络,输入x然后得到输出y。
一对多
这种1 VS N的结构可以处理的问题有:
1.从图像生成文字(image caption),此时输入的X就是图像的特征,而输出的y序列就是一段句子
2.从类别生成语音或音乐等
分如下两种方式输入:
- 只在序列开始进行输入计算,其它 time step 输入为 0

- 把输入信息X作为每个阶段的输入

多对一
输入是一个序列,输出是一个单独的值而不是序列,这种结构通常用来处理序列分类问题。如输入一段文字判别它所属的类别,输入一个句子判断其情感倾向,输入一段视频并判断它的类别等等。
可以对最后一个 h 进行输出变换,或对所有的 h 进行平均后再进行输出变换(注意:初始状态神经元的数量必定和隐层神经元的数量一致)

多对多(Tx=Ty)
这种是同步的序列到序列的模式,即输入和输出等长,由于这个限制的存在,经典RNN的适用范围比较小,但也有一些问题适合用经典的RNN结构建模,如:计算视频中每一帧的分类标签。因为要对每一帧进行计算,因此输入和输出序列等长。 还有命名实体识别问题。

多对多(Tx!=Ty)
这种事异步的序列到序列的模式,结构又叫 Encoder-Decoder 模型,也可称之为 Seq2Seq 模型。我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。Encoder-Decoder 模型可以有效的建模输入序列和输出序列不等长的问题。

由于这种 Encoder-Decoder 结构不限制输入和输出的序列长度,因此应用的范围非常广泛,比如:
- 机器翻译:Encoder-Decoder的最经典应用,事实上这一结构就是在机器翻译领域最先提出的
- 文本摘要:输入是一段文本序列,输出是这段文本序列的摘要序列
- 阅读理解:将输入的文章和问题分别编码,再对其进行解码得到问题的答案
- 语音识别:输入是语音信号序列,输出是文字序列。