Inductive Representation Learning On Large Graphs【阅读笔记】
前言
Network Embedding 旨在为图中的每个顶点学习得到特征表示。近年的Deepwalk,LINE, node2vec, SDNE, DNGR等模型能够高效地、直推式(transductive)地得到节点的embedding。然而,这些方法无法有效适应动态图中新增节点的特性, 往往需要从头训练或至少局部重训练。斯坦福Jure教授组提出一种适用于大规模网络的归纳式(inductive)学习方法-GraphSAGE,能够为新增节点快速生成embedding,而无需额外训练过程。
大部分直推式表示学习的主要问题有:
- 缺乏权值共享(Deepwalk, LINE, node2vec)。节点的embedding直接是一个N*d的矩阵, 互相之间没有共享学习参数。
- 输入维度固定为|V|。无论是基于skip-gram的浅层模型还是基于autoencoder的深层模型,输入的维度都是点集的大小。训练过程依赖点集信息的固定网络结构限制了模型泛化到动态图的能力,无法为新加入节点生成embedding。
模型
本文提出了一种基于邻居特征聚集的方法,由以下三部分组成:
- 邻居采样。因为每个节点的度是不一致的,为了计算高效, 为每个节点采样固定数量的邻居。
- 邻居特征聚集。通过聚集采样到的邻居特征,更新当前节点的特征。网络第k层聚集到的 邻居即为BFS过程第k层的邻居。
训练。既可以用获得的embedding预测节点的上下文信息(context),也可以利用embedding做有监督训练。
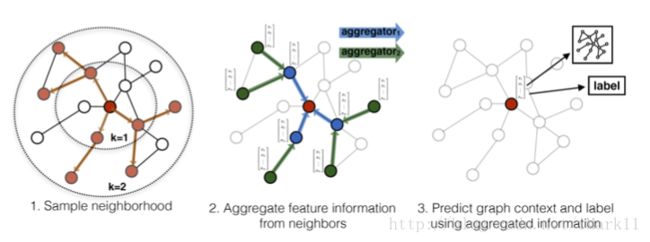
在实践中,每个节点的receptive field设置为固定大小,且使用了均匀采样方法简化邻居选择过程。作者设计了四种不同的聚集策略,分别是Mean、GCN、LSTM、MaxPooling。Mean Aggregator: 对所有对邻居节点特征取均值。
- GCN Aggregator: 图卷积聚集W(PX),W为参数矩阵,P为邻接矩阵的对称归一化矩阵,X为节点特征矩阵。
- LSTM Aggregator: 把所有节点按随机排列输入LSTM,取最终隐状态为聚集之后对表示。
- Pooling Aggregator: 邻接特征经过线性变换化取各个位置上对最大值。
模型最终的损失函数为edge-wise loss,也使用了负采样方法。![]()
代码解析
GraphSAGE代码的开源地址here。在此,我针对部分关键代码进行解析。
首先,邻接表的构建和采样分布在minibatch.py和neigh_samplers.py中,
def construct_adj(self):
adj = len(self.id2idx)*np.ones((len(self.id2idx)+1, self.max_degree))
deg = np.zeros((len(self.id2idx),))
for nodeid in self.G.nodes():
if self.G.node[nodeid]['test'] or self.G.node[nodeid]['val']:
continue
neighbors = np.array([self.id2idx[neighbor]
for neighbor in self.G.neighbors(nodeid)
if (not self.G[nodeid][neighbor]['train_removed'])])
deg[self.id2idx[nodeid]] = len(neighbors)
if len(neighbors) == 0:
continue
if len(neighbors) > self.max_degree:
neighbors = np.random.choice(neighbors, self.max_degree, replace=False)
elif len(neighbors) < self.max_degree:
neighbors = np.random.choice(neighbors, self.max_degree, replace=True)
adj[self.id2idx[nodeid], :] = neighbors
return adj, degclass UniformNeighborSampler(Layer):
"""
Uniformly samples neighbors.
Assumes that adj lists are padded with random re-sampling
"""
def __init__(self, adj_info, **kwargs):
super(UniformNeighborSampler, self).__init__(**kwargs)
self.adj_info = adj_info
def _call(self, inputs):
ids, num_samples = inputs
adj_lists = tf.nn.embedding_lookup(self.adj_info, ids)
adj_lists = tf.transpose(tf.random_shuffle(tf.transpose(adj_lists)))
adj_lists = tf.slice(adj_lists, [0,0], [-1, num_samples])
return adj_lists可以看出:在构建邻接表时,对度数小于max_degree的点采用了有重复采样,而对于度数超过max_degree的点采用了无重复采样。
接下来,在真正为每个batch内的目标点选取receptive field点时,其代码在model.py中,如下:
def sample(self, inputs, layer_infos, batch_size=None):
""" Sample neighbors to be the supportive fields for multi-layer convolutions.
Args:
inputs: batch inputs
batch_size: the number of inputs (different for batch inputs and negative samples).
"""
if batch_size is None:
batch_size = self.batch_size
samples = [inputs]
# size of convolution support at each layer per node
support_size = 1
support_sizes = [support_size]
for k in range(len(layer_infos)):
t = len(layer_infos) - k - 1
support_size *= layer_infos[t].num_samples
sampler = layer_infos[t].neigh_sampler
node = sampler((samples[k], layer_infos[t].num_samples))
samples.append(tf.reshape(node, [support_size * batch_size,]))
support_sizes.append(support_size)
return samples, support_sizes这里采样的过程与BFS过程相似,首先找到一个目标节点,之后是该节点的一阶邻居节点,再之后是所有一阶节点的一阶节点。参见该issue。
资源列表
Paper: https://arxiv.org/abs/1706.02216
Code: https://github.com/williamleif/GraphSAGE
Project page: http://snap.stanford.edu/graphsage