zookeeper-数据与存储
1. Zookeeper技术内幕
1.1. 数据与存储
1.1.1. 内存数据
数据结构:
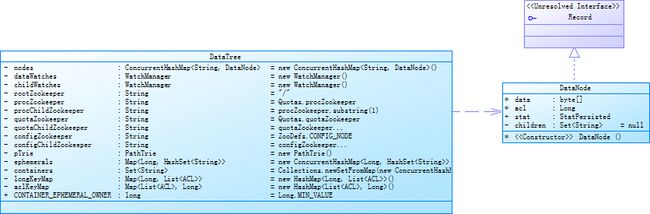
ZooKeeper的数据模型是一棵树,而从使用角度看, Zookeeper就像一个内存数据库一样。在这个内存数据库中,存储了整棵树的内容,包括所有的节点路径、节点数据及其ACL信息等,Zookeeper会定时将这个数据存储到磁盘上。
1.1.2. 事物日志
那么ZooKeeper 在运行过程中会在事物日志目录下建立一个名字为version-2的子目录,该目录确定了当前ZooKeeper使用的事务日志格式版本号。也就足说,等到下次某个ZooKeeper版本对事务日志格式进行变更时,这个目录也会有所变更。
事物日志文件目录截图

文件内容按照如下的顺序写入:
- fileheader
- magic //”ZKSN”
- version //2
- dbid //-1
- fileheader
- crcvalue1–校验和,校验下面的txtEntry
- txtEntry1
- hdr
- clientId
- cxid
- zxid
- time
- type(包括createSession、closeSession、create、create2、createContainer、delete、deleteContainer、reconfig、setData、setACL、error、multi)
- hdr
- –不通的hdr.type,有不同的txn
- txn(createSession)
- timeOut
- txn
- txn(closeSession、create、create2)
- path
- data
- acl
- ephemeral
- parentCVersion//父节点的版本号cversion
- txn
- txn(createContainer)
- path
- data
- acl
- parentCVersion
- txn
- txn(delete、deleteContainer)
- path
- txn
- txn(reconfig、setData)
- path
- data
- version
- txn
- txn(setACL)
- path
- acl
- version
- txn
- txtEntry1
- EOR 0x42–B,标识一个事物记录结束
- crcvalue2–校验和,校验下面的txtEntry
- txtEntry2
- hdr
- hdr
- txn
- txn
- txtEntry2
使用二进制编辑器打开事物日志文件,可以看到类似如下所示文件内容—这就是序列化之后的事务日志文件。

使用工具类(org.apache.zookeeper.server.LogFormatter)解析事物日志文件,输出内容如下:



第一行:
- ZooKeeper Transactional Log File with dbid 0 txnlog format version 2
这一行是事物日志的文件头信息,这里输出的主要是事物日志的DBID和日志格式版本号。
- 16-11-19 下午01时12分48秒 session 0x15554779e59002c cxid 0x0 zxid 0x600000075 createSession 40000
这一行就是一次客户端会话创建的事务操作日志,其中我们不难看出,从左向右分别记录事物操作时间、客户端会话ID、CXID (客户端的操作序列号)、ZXID、操作类型和会话超时时间。
- 16-11-19 下午12时04分00秒 session 0x15554779e59000f cxid 0x1 zxid 0x600000027 create ’/zookeeper/test,#2f7a6f6f6b65657065722f74657374,v{s{31,s{‘digest,’foo:Jfg7TYUBs/6KEtdDWd5OB6bdD2Q=}}},F,2
日志写入
1.创建事物日志文件
当ZooKeeper服务器启动完成需要进行第一次事务日志的写入,或是上一个事务日志写满的时候,都会处于与事务日志文件断开的状态,即ZooKeeper服务器没有和任意一个日志文件相关联。因此,在进行事务日志写入前,Zookeeper首先会判断FileTxnLog组件是否已经关联了一个可写的事物日志文件。如果没有关联上事务日志文件,那么就会使用与该事务操作关联的ZXID作为后缀创建一个事物日志文件,同时构建事务日志文件头信息(包含魔数magic、事务日志格式版本version和dbid),并立即写入这个事物日志文件中去。
2.确定事务日志文件是否需要扩容(预分配)。
当检测到当前务日志文件剩余空间不足4096字节(4KB)时,就会开始进行文件空间扩容。在现行文件大小的基础上,将文件大小增加65536KB (64MB),然后使用“0”(\0)填充这些被扩容的文件空间。
那么ZooKeeper为什么要进行事务日志文件的磁盘空间预分配呢?对客户端的每一次事务操作,ZooKeeper都会将其写人事务日志文件中。因此,事物日志的写入性能直接决定了ZooKeeper服务器对事务请求的响应,也就是说,事务写入近似可以被看作是一个磁盘I/O的过程。严格地讲,文件的不断追加写入操作会触发底层磁盘I/O为文件开辟新的磁盘块,即磁盘Seek。因此,为了避免磁盘Seek的频率,提高磁盘I/O的效率,ZooKeeper在创建事物日志的时候就会进行文件空间“预分配”——在文件创建之初就向操作系统预分配一个很大的磁盘块,默认是64MB,而一旦已分配的文件空间不足4KB 时,那么将会再次“预分配”,以避免随着每次事物的写入过程中文件大小增长带来的Seek开销,直至创建新的事务日志。
3.事物序列化
事务序列化包括对事务头和事务体的序列化,分别是对TxnHeader(事务头)和Record (事务体)的序列化。其中事务体又可分为会话创建事务(CreateSessionTxn)、节点创建事务(CreateTxn)、节点删除事务(DeleteTxn)和节点数据更新事务 (SetDataTxn)等。
4.生成Checksum。
为了保证事务日志文件的完整性和数据的准确性,ZooKeeper在将事务日志写入文件前,会根据步骤3中序列化产生的字节数组来计算Checksum。ZooKeeper默认使用Adler32算法来计算Checksum值。
5.写入事务日志文件流。
将序列化后的事务头、事务体及Checksum值写入到文件流中去。此时由于 ZooKeeper使用的足BufferedOutputStream,因此写人的数据并非真正被写入到磁盘文件上。
6.事务日志刷入磁盘。
在步骤5中,已经将事务操作写人文件流中,但是由于缓存的原因,无法实时地写入磁盘文件中,因此我们需要将缓存数据强制刷入磁盘中,在步骤1中我们已经将每个事物日志文件对应的文件流放入streamsToFlush,因此这里会从 streamsToFlush 中提取出文件流,并调用FileChannel.force(boolean metaData)接口来强制将数据刷入磁盘文件中去。force接口对应的其实是底层的fsync接口,是一个比较耗费磁盘I/O资源的接口,因此ZooKeeper允许用户控制是否需要主动调用该接口,以通过系统属性zookeeper.forceSync来设置。
1.1.3. 数据快照
和事物日志类似,zookeeper的快照数据也是使用特定的磁盘目录进行存储,读者也可以通过dataDir属性进行配置。在运行的过程中会在该目录下创建一个名为version-2的目录,改目录切丁了当前zookeeper使用的快照数据格式版本号。
快照文件目录截图

文件内容按照如下的顺序写入:
- fileheader
- magic //”ZKSN”
- version //2
- dbid //-1
- fileheader
- count(会话数量)
- id //会话ID
- timeout //会话超时
- id
- timeout
- …
- map//int acls数量
- long//acl的key
- acls
- acl
- acl
- acls
- long//acl的key
- acls
- acl
- acl
- acls
- path1
- node1
- data
- acl
- stat
- cZxid:创建节点时的事物ID
- ctime:创建节点的时间
- mZxid:节点最新一次更新时的事物ID
- mtime:最近一次节点更新的时间
- pZxid:该节点的子节点列表最后一次被修改时的事物ID,如果没有子节点,则为当前节点的cZxid
- cversion:子节点更新次数
- dataVersion:节点数据更新次数
- aclVersion:节点acl更新次数
- ephemeralOwner:如果节点为ephemeral节点则该值为sessionid,否则为0
- dataLength:该节点数据的长度
- stat
- node1
- path2
- node2
- node2
- /zookeeper/quota
- val–以上数据的校验和
- path:/ –path的值为’/’,结束文件
使用工具类(org.apache.zookeeper.server.SnapshotFormatter)解析快照文件,输出内容如下:
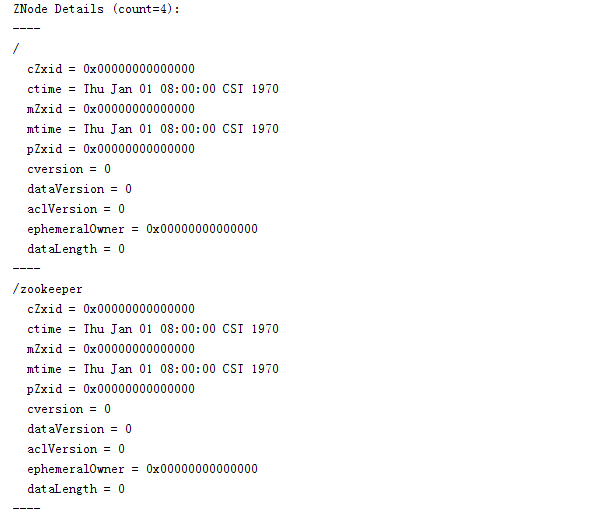

输出的仅仅是数据节点的元信息,并没有输出每个节点的数据内容。
数据结构:

将内存数据库写入快照数据文件中,其实就是一个序列化过程。
针对客户端的每一次事务操作,ZooKeeper都会将它们记录到事物日志中,当然,ZooKeeper同时也会将数据变更应用到内存数据库中。另外,ZooKeeper会在进行若干次事务日志记录之后,将内存数据库的全最数据Dump到本地文件中,这个过程就是数据快照。可以使用snapCount参数来配置每次数据快照之间的事物操作次数,即ZooKeeper会在snapCount次事务日志记录后进行一个数据快照。
数据快照的过程
1.确定是否需要进行数据快照。
每进行一次事务日志记录之后,ZooKeeper都会检测当前是否需要进行数据快照。 理论上进行snapCount次事务操作后就会开始数据快照,但是考虑到数据快照对ZooKeeper所在机器的整体性能的影响,需要尽量避免ZooKecper集群中的所 有机器在间一时刻进行数据快照。因此ZooKeeper在具体的实现中,并不是严格地按照这个策略执行的,而是采取“过半随机”策略,即符合如下条件就进行数据快照:
logCount> (snapCount / 2 + randRoll)
其中logCount代表了当前已经纪录的事务日志数虽,randRoll为1~snapCount/2 之间的随机数,因此上面的条件就相当于:如果我们配置的snapCount值为默认的100000,那么ZooKeeper会在50000~100000次事务日志记录后进行一次数据快照。
2.切换事物日志文件。
满足上述条件之后,Zookeeper就要开始进行数据快照首先是进行事务日志文件的切换。所谓的事务日志文件切换是指当前的事务日志已经“写满”(已经写入了snapCount个事务日志),需要重新创建一个新的事务日志。
3.创建数据快照异步线程。
为了保证数据快照过程不影响ZooKeeper的主流程,这里需要创建一个单独的异步线程来进行数据快照。
4.获取全最数据和会话信息。
数据快照本质上就是将内存中的所有数据节点信息(DataTree)和会话信息保存到本地磁盘中去。因此这里会先从ZKDatabase中获取到DataTree和会话信息。
5.生成快照数据文件名。
在“文件存储”部分,我们已经提到快照数据文件名的命名规则。在这一步中, ZooKeeper会根据当前已提交的最大zxid来生成数据快照文件名。
6.数椐序列化。
接下来就幵始真正的数据序列化了。在序列化时首先会序列化文件头信息,这里的文件头和事物务日志中的一致,同样也包含魔数、版本号和dbid信息。然后在对会话信息和DataTree分別进行序列化,同时生成一个Checksum, —并写入快照数据文件中去。
1.1.4. 初始化
数据加载的整体流程

快照文件加载流程
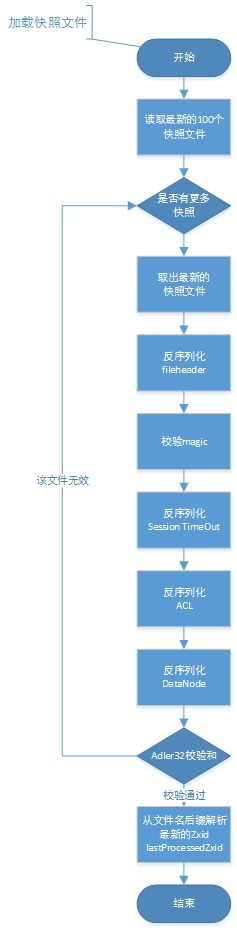

1.处理快照文件
完成内存数据库的初始化之后,zookeeper就可以开始从磁盘中恢复数据了。每一个快照数据文件中都保存了zookeeper服务器近似全量的数据,因此首先从这些快照文件开始加载。
2. 获取最新的100个快照文件
—般在ZooKeeper服务器运行一段时间之后,磁盘上都会保留许多个快照文件。另外由于毎次数据快照过程中,ZooKeeper都会将全最数据Dump到磁盘快照文件中,因此往往更新时间最晚的那个文件包含最新的全量数据。那么是否我们只需要这个最新的快照文件就可以了呢?在ZooKeeper的实现中,会获取最新的至多100个快照文件(如果磁盘上仅存在不到100个快照文件,那么就获取所有这些快照文件)。
3.解析快照文件
获取到这至多100个文件之后,ZooKeeper会开始“逐个”进行解析。每个快照文件都是内存数据序列化到磁盘的二进制文件,因此在这里需要对其进行反序列化,生成DataTree对象和sessionsWithTimeouts集合。同时在这个过程中,还会进行文件的checksum校验以确定快照文件的正确性。
需要注意的一点是,虽然获取到的是100个快照文件,但其实在“逐个”解析过程中,如果正确性校验通过的话,那么通常只会解析最新的那个快照文件。换句话说,只有当最新的快照文件不可用的时候,才会逐个进行解析,直到将这100个文件全部解析完。如果所有快照文件都解析完后还是无法成功恢复一个完整的DataTree和sessionsWithTimeouts, 则认为无法从磁盘中加载数据,服务器启动失败。
4. 获取最新的ZXID
完成上面的步骤后,就已经基于快照文件构建了一个完整的DataTree实例 和sessionsWithTimeouts集合了。此时根据这个快照文件的文件名就可以解析出一个最新的ZXID: zxid_for_snap,该ZXID代表了ZooKeeper开始进行数据快照的时刻。
5.处理事务日志
在经过上面的处理过程,此时ZooKeeper服务器内存中已经有了一份近似全量的数据,现在开始就要通过事务日志来更新增量数据。
6.获取所有zxid_for_snap之后提交的事务
到这里,我们已经获取到快照数据的最新ZXID。ZooKeeper中数椐的快照机制决定了快照文件中并非包含了所有的事务操作。但是未被包含在快照文件中的那部分事务操作是可以通过数据订正来实现的。因此这里我们只需要从事物日志中获取所有ZXID比上步得到的zxid_for_snap大的事务操作。
7.事务应用
获取到所有ZXID大于zxid_for_snap的事务后,将其逐个应用到之前基于快照数据文件恢复出来的DataTree和sessionsWithTimeouts中去。
在事务应用的过程中,还有一个细节需要我们注意,每当有一个事务被应用到内存数据库中去后,ZooKeeper同时会回调PlayBackListener监听器,将这一事务操作记录转换成Proposal,并保存到ZKDatabase.committedLog中,以便Follower进行快速同步。
1.1.5. 数据同步
ZooKeeper集群服务器启动的过程中提到,整个集群完成 Leader选举之后,Learner会向Leader服务器进行注册。当Learner服务器向Leader完成注册后,就进入数据同步环节,简单地讲,数据同步过程就是Leader服务器将那些没存在Learner服务器上提交过的事务请求同步给Learner服务器,大体上如下图所示。

获取Learner状态
在注册Learner的最后阶段,Learner服务器会发送给Leader服务器一个ACKEPOCH数据包,Leader会从这个数据包中解析出该Learner的currentEpoch和lastZxid。
数据同步初始化
在开始数据同步之前,Leader服务器会进行数据同步初始化,首先会从ZooKeeper的内存数据库中提取出事务请求对应的提议缓存队列(下面我们用“提议缓存队列”来指代该队列):proposals,同时完成对以下三个ZXID值的初始化。
l peerLastZxid:该Learner服务器最后处理的ZXID。
l minCommittedLog: Leader服务器提议缓存队列 committedLog中的最小ZXID。
l maxConmmittedLog: Leader服务器提议缓存队列committedLog中的最大ZXID。
ZooKeeper集群数据同步通常分为四类,分别是直接差异化同步(DIFF同步)、先回滚在差异化同步(TRUNC+DIFF同步)、仅回滚同步(TRUNC同步)和全量同步(SNAP 同步)在初始化阶段,Leader服务器会优先初始化以全量同步方式来同步数据,当然,这并非最终的数据同步方式,在以下步骤中,会根据Leader和Learner服务器之间的数据差异情况来决定最终的数据同步方式。
直接差异化同步(DIFF同步)
场景:peerLastZxid介于minCommittedLog 和maxCommittedLog 之间
对于这种场景,就使用差异化同步(DIFF同步)方式即可。Leader服务器会首先向这个Learner发送一个DIFF指令,用于通知Learner进入差异化数据同步阶段,Leader 服务器即将把一些Proposal同步给自己”。在实际Proposal同步过程中,针对每个Proposal, Leader服务器都会通过发送两个数据包来完成,分別是PROPOSAL内容数据包和COMMIT指令数据包,这和ZooKeeper运行时Leader和Follower之间的事务请求的提交过程是一致的。
举个例子来说,假如某个时刻Leader服务器的提议缓存队列对应的ZXID依次是:
0x500000001, 0x500000002, 0x500000003, 0x500000004. 0x500000005
而Learner服务器最后处理的ZX1D为0x500000003, 于是Leader服务器就会依次将 0x500000004和0x500000005两个提议同步给Learner服务器,同步过程中的数据包发送顺序如下表所示。
| 发送顺序 |
数据包类型 |
对应ZXID |
| 1 |
PROPOSAL |
0x500000004 |
| 2 |
COMMIT |
0x500000004 |
| 3 |
PROPOSAL |
0x500000005 |
| 4 |
COMMIT |
0x500000005 |
通过以上四个数据包的发送,Learner服务器就可以接收到自己和Leader服务器的所有差异数据。随后Leader还会立即发送一个 NEWLEADER指令,用于通知Learner,已经将提议缓存队列中的Proposal都同步给自己了。
下面我们再来看Learner对Leader发送过来的数据包的处理。根据上面讲解的Leader 服务器的数据包发送顺序,Learner会首先接收到一个DIFF指令,于是便确定了接下来进入DIFF同步阶段。然后依次收到上表中的四个数据包,Learner会依次将其应用到内存数据库中。Learner还会接收到来自Leader的NEWLEADER指令,此时Learner就会反馈给Leader —个ACK消息,表明自己确实完成了对提议缓存队列中Proposal的同步。
Leader在接收到来Learner的这个ACK消息以后,就认为当前Learner已经完成数据同步,同时进入“过半策略”等待阶段——Leader会和其他Learner服务器进行上述同样的数据同步流程,直到集群中有过半的Learner机器响应了Leader这个ACK消息。一但满足“过半策略”后,Leader服务器就会向所有已经完成数据同步的Learner发送一个UPTODATE指令,用来通知Learner已经完成数据同步,同时集群中已经有过半机器完成数据同步,集群已经具备了对外服务的能力了。
Learner在接收到这个来自Leader的UPTODATE指令后,会终止数据同步流程,然后向 Leader再次反馈一个ACK消息。
这个差异化同步过程中涉及的Leader和Learner之间的数据包通信如下图所示。

先回滚再差异化同步(TRUNC + DIFF 同步)
场景:针对上面的场景,我们已经介绍了直接差异化同步的详细过程。但是在这种场景中,会有一个罕见但是确实存在的特殊场景:设有 A 、 B 、 C 三台机器,假如某一时刻 B 是 Leader 服务器,此时的Leader_Epoch为 5 ,同时当前已经被集群中绝大部分机器都提交的 ZXID 包括: 0x500000001 和 0x500000002 。此时,Leader 正要处理 ZXID : 0x50000003,并且已经将该事务写入到了 Leader 本地的事务日志中去,就在 Leader 恰好要将该 Proposal 发送给其他 Follower 机器进行投票的时候,Leader 服务器挂了,Proposal没有被同步出去。此时 zooKeeper 集群会进行新一轮的 Leader 选举,假设此次选举产生的新的 Loader 是 A ,同时Leader_Epoch 变更为 6 ,之后 A 和 C 两台服务器继续对外进行服务,又提交了 0x600000001 和 0x600000002 两个事务。此时,服务器 B 再次启动,井开始数据同步。
简单地讲,上面这个场景就是 Leader 服务器在已经将事务记录到了本地事务日志中,但是没有成功发起Proposal流程的时候就挂了。在这个特殊场景中,我们看到, peerLastzxid 、minCommittedLog 和 maxCommittedLog 的值分别是 0x500000003 、 0x500000001和0x600000002.显然, peerLastzxid介于 minConlmittcdLog 和maxCommittedLog之间。对于这个特殊场景,就使用先回滚再差异化同步(TRUNC +DIFF 同步)的方式。当 Leader 服务器发现某个 Learner 包含了一条自己没有的事务记录,那么就需要让该 Learner进行事务回滚,回滚到 Leader 服务器上存在的,同时也是最接近于 peerLastzxid的ZXID 。在上面这个例子中, Leader 会需要Learner 回滚到 ZXID为0x500000002的事务记录。
先回滚再差异化同步的数据同步方式在具体实现上和差异化同步是一样的,都是会将差异化的Proposal发送给 Learner 。同步过程中的数据包发送顺序如下表所示。
| 发送顺序 |
数据包类型 |
对应ZXID |
| 1 |
TRUNC |
0x500000002 |
| 2 |
PROPOSAL |
0x600000001 |
| 3 |
COMMIT |
0x600000001 |
| 4 |
PROPOSAL |
0x600000002 |
| 5 |
COMMIT |
0x600000002 |
仅回滚同步(RUNC同步)
场景:peerLastzxid大于maxCommittedLog 。这种场景其实就是上述先回滚再差异化同步的简化模式, Leader 会要求 Learner 回滚到 ZXID 值为maxCommittedLog对应的事务操作,这里不再对该过程详细展开讲解。
全量同步(SNAP同步)
场景1:peerLastZxid小于minCommittedLog 。
场景2 :Leader服务器上没有提议缓存队列, peerLastZxid不等干 lastProcessedZxid ( Leader服务器数据恢复后得到的最大ZXID)。上述这两个场景非常类似,在这两种场景下, Leader服务器都无法直接使用提议缓存队列和 Learner进行数据同步,因此只能进行全量同步(SNAP 同步)。
所谓全量同步就是 Leader服务器将本机上的全量内存数据都同步给Learner。Leader服务器首先向Learner发送一个 SNAP指令,通知Learner即将进行全量数据同步。随后, Leader 会从内存数据库中获取到全量的数据节点和会话超时时间记录器,将它们序列化后传输给Learner 。Learner服务器接收到该全最数据后,会对其反序列化后载入到内存数据库中。
以上就是ZooKeeper 集群间机器的数据同步流程了。整个数据同步流程的代码实现主要在LearnerHandler和Learner 两个类中。