Hadoop3.1.0集群环境搭建
Hadoop3.1.0集群环境搭建
系统环境:
主机系统:win10
虚拟机系统:VM14+CentOS7
前面的文章我使用的系统是CentOS 6.7 ,由于CentOS 7 与CentOS 6 有很大变化,不能落后了,所以这次我改用 CentOS 7 系统来学习了,以后的文章也都使用CentOS 7 系统来进行。
今天就写一下,Hadoop 集群搭建的过程吧,学习的开始先把环境搭建好。
如果没有安装虚拟机的可以参考我以前的文章:
虚拟机安装教程:虚拟机安装教程
关于虚拟机的网络配置以及JDK的安装也可以参考:虚拟机的网络配置及JDK安装
虚拟机安装后或者克隆后无法上网可参考:虚拟机克隆的方法
关于Hadoop安装包下载可以参考:Apache Hadoop 下载的方法
关于CentOS 6 和 CentOS 7 的一些不同配置命令:从CentOS 6 到 CentOS 7
准备好以上内容后就可以来学习Hadoop集群的搭建了,我使用的环境是:虚拟机 CentOS 7、宿主机 win10、虚拟机软件 VMware Workstation 14,所需软件及文件可从网络上下载,我的公众号后台『大数据专栏』回复 18904 获取下载链接。
1.启动虚拟机
启动我们安装好的虚拟机,虚拟机已安装 JDK 1.8 并配置好网络连接。
2.环境配置
我们先来配置一下系统环境:
由于后面需要用到主机名,所以我讲一下主机名修改的命令
在 root 账户下修改主机名:执行 vi /etc/hostname 此文件的内容即为主机名,重启后生效。我这里修改主机名为 centos71

修改IP和主机名映射关系:
执行:vi /etc/hosts

3.准备三台虚拟机
搭建Hadoop集群环境我们需要 三台机器,也就是三台虚拟机。注意已安装 JDK,未安装JDK的课参考前面教程
我们可以通过克隆得到 三台配置以及系统环境 相同的机器,前面我使用CentOS6.7 克隆之后无法上网,这次使用CentOS 7 克隆后没有出现无法上网的问题,但是有时能行有时又不行,我不知道什么原因,为了能稳定连接网络后续少点烦恼,建议还是重新配置一下克隆后的虚拟机,建议参看我之前的网络配置(请从第四段开始看):
下面说明了使用root账户执行的请先执行 su 切换为 root 账户,返回 普通 账户 则执行 exit;
我们仍需要修改
『主机名、IP、以及主机名 和 IP 的映射关系』
root 账户下执行 vi /etc/sysconfig/network-scripts/ifcfg-ensXX

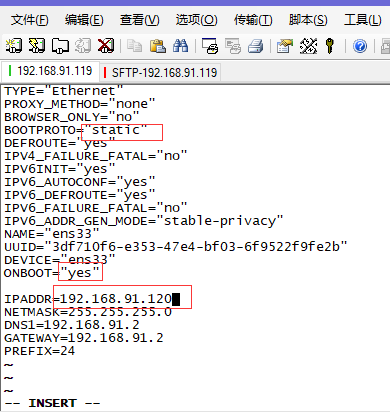
关于网络配置可参考前面的文章:
配置好后保存退出,执行重置网卡命令:service network restart
由于我的笔记本配置一般,我设置开机不启动图形化界面:
systemctl set-default multi-user.target (命令行界面)
systemctl set-default graphical.target (图形化界面)
我们有了三台机器并且网络没问题,就可以进行下面的Hadoop集群环境搭建了。
为了操作方便我使用 SecureCRT 连接三个虚拟机进行操作
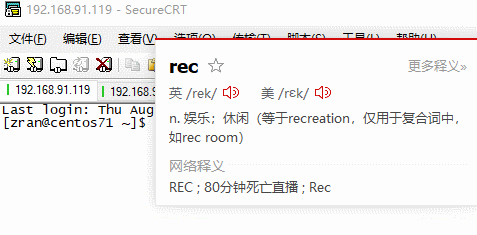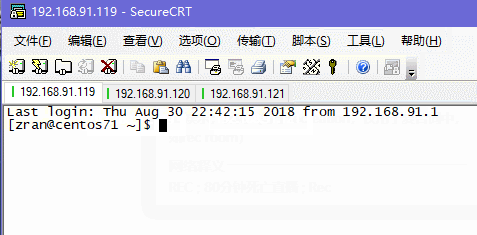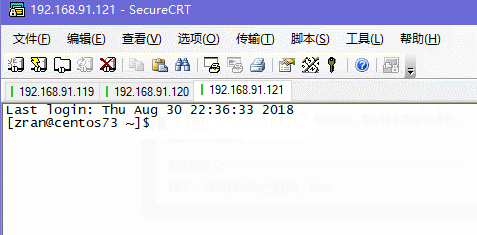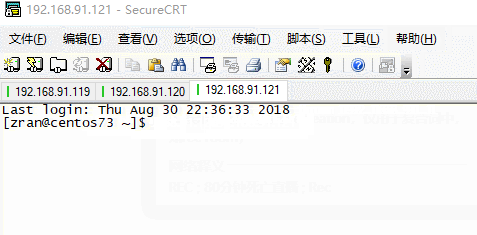
我三台机器的主机名 ip分别为:
centos71 192.168.91.119
centos72 192.168.91.120
centos73 192.168.91.121
建议:我的笔记本配置一般,运行三个虚拟机有点吃力,我们一般人的电脑配置可能都比较低,所以我建议和我一样,我将centos71 设置启动图形化界面配置;设置 2g 内存,因为后面可能在centos71上安装IDE编写代码;centos72 和 centos73 则分配 1g 内存,设置只启动命令行界面。
本次搭建 Hadoop 集群环境 我将centos71作为管理节点(NameNode),centos72 和 centos73 则作为 存储节点(DataNode),如果对NameNode及DataNode没有相关概念的后面我会再补充。
注意下面操作需要在三台机器上都操作
1.
网络配置
给三台机器配置IP和主机名映射,为了后面可以使用主机名代替IP在局域网内通过主机名访问服务器。我们需要给每台机器都配置这三台ip 主机名映射。
root账户下 执行 vi /etc/hosts
添加另外两台机器的 ip映射 三台机器都需要配置

然后我们可以直接使用主机名代替 IP 了

2.
关闭防火墙
systemctl stop firewalld.service 关闭 防火墙
systemctl disable firewalld.service 禁止防火墙开机自启
3.
配置 SSH 免密登录
SSH 登录是指 两台机器之间通过 SSH 登录无需用户名和密码。
在 home 目录下执行:ssh-keygen -t rsa 生成密钥

执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥),默认存放在 个人home/.ssh目录下

接下来需要 将公钥拷贝到要免密登陆的目标机器上,给本机也复制一份
这里我们需要分别复制到 centos72 和 centos73,本机也要复制
首先进入个人home/.ssh 目录下执行:
ssh-copy-id centos71
ssh-copy-id centos72
ssh-copy-id centos73
我以复制到centos73为例:

同样,我们还需要分别在 centos72,centos73 这两台机器上执行:ssh-keygen -t rsa 并复制到其他两台机器上及本机,这样就配置好 SSH 免密登录了。
4.
下载安装Hadoop
官网下载hadoop的方法可参考:
下载好之后我们需要上传到虚拟机:
我将软件存放在 /home/apps 目录下
如果和我一样使用SecureCRT 可按alt+p 进行sftp传输,使用 put命令将hadoop安装包上传至虚拟机:
注意:
下面操作仅在centos71上操作
put 要上传文件的路径

我上传到了 home 目录下,接下来需要解压到安装目录里
执行:tar -zxvf hadoop-3.1.0.tar.gz -C apps/

接下来我们需要修改的配置文件在
/home/zran/apps/hadoop-3.1.0/etc/hadoop
我们需要修改的5个配置文件如图:
我这里下载的是hadoop3.1.0,
以前的版本:需要把 mapred.site.xml.template 改为 mapred.site.xml 此外 我发现以前的slaves 现在改名为 workers 了

接下来我们需要对这 6个 文件进行配置:
1.
hadoop-env.sh
需要指定 JAVA_HOME 的路径:
我们可以通过:echo $JAVA_HOME 查看已配置好的路径
我这里配置的路径是:/home/zran/apps/jdk1.8.0_181/

执行:vi hadoop-env.sh 进行修改
找到 export JAVA_HOME= .....这行改为我们实际配置的 JAVA_HOME 路径,并去掉 # 号注释

2.
core-site.xml
修改core-site.xml 文件
指定hadoop所使用的文件系统,以及将centos71作为namenode节点,设置hadoop运行时文件存储目录
我的配置如下:
fs.defaultFS
hdfs://centos71:9000
hadoop.tmp.dir
/home/zran/hadoopdata
3.
hdfs-site.xml
指定 HDFS 副本数量
注意:Hadoop3.1的namenode节点端口从50070改为9870端口了
dfs.replication
2
4.
mapred-site.xml
指定 MapReduce运行在yarn上
mapreduce.framework.name
yarn
5.
yarn-site.xml
指定 ResourceManager 服务节点
yarn.resourcemanger.hostname
centos71
yarn.nodemanager.aux-services
mapreduce_shuffle
6.
workers
之前我使用hadoop-2.6 这个文件名为 slaves ,现在3.0版本为 workers
在此文件添加 我们作为DataNode节点的两台台机器的主机名,如果我们只将centos71 作为 namenode不做为datanode的话,就不用在此文件中添加centos71了,我这里三台机器都做为 DataNode 节点
centos71
centos72
centos73
5.
将Hadoop发到另外两台机器
配置文件修改好后,我们需要将 hadoop 复制到centos72和centos73
执行命令:
scp -r /home/用户名/apps/hadoop-3.1.0/ 用户名@centos72:/home/用户名/apps/
scp -r /home/用户名/apps/hadoop-3.1.0/ 用户名@centos73:/home/用户名/apps/
等待传输完毕.......
6.
配置Hadoop 环境变量
三台机器都需要配置
root 账户下执行:vi /etc/profile
#HADOOP_HOME
export HADOOP_HOME=/home/zran/apps/hadoop-3.1.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
然后保存退出
执行 source /etc/profile 使配置生效
7.
初始化操作
完成以上步骤后,需要先格式化文件系统
在 NameNode 节点上执行,我上面的配置是将 centos71 作为 NameNodde 节点,centos72,centos73 作为 DataNode 节点
在 centos71 下执行格式化
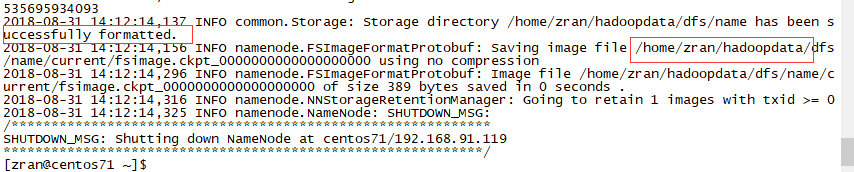
普通账户下 执行:hdfs namenode -format
格式化后卡伊看到成功的标志:
直接执行 hdfs 可查看 其命令和参数

8.
启动Hadoop
satrt-all.sh 启动Hadoop集群
stop-all.sh 关闭Hadoop集群
验证是否启动成功:
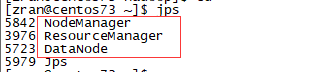
在centos71(NameNode节点)下执行:jps 可以看到如下进程

在centos72和centos73下执行:jps 可看到如下进程
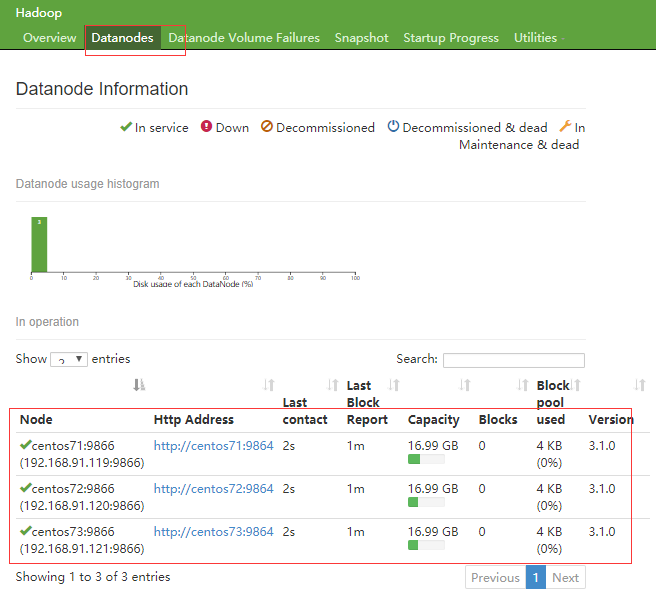
然后我们通过浏览器:访问
http://centos71:9870
在宿主机中可通过IP代替主机名访问
http://192.168.91.119:9870
就可以看到如下界面

配置过程中遇到的问题:
1.我配置好网络后于是执行 service network restart 报错:
Restart inge network (via sustemctl) : Job for network.service failed because the control process exited with error code……
于是从网上找到答案是 MAC 地址填错了,也就是HWADDR错了,修改后成功解决
2.执行 start-all.sh 报错
Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
ssh 免密登录配置可能出了点问题,我重新配置就可以了
3.由于我英语较烂,没去看官方文档,不知道hadoop3.1.0 版本的 NameNode 节点的默认端口改为 9870 了,我仍然在浏览器中访问50070端口,怎样都无法访问,使用jps查看进程正常, 但无法访问 NameNode 节点,后来从网上搜索才知道 端口更改了,端口改了,端口改了。。。由于这个原因,我几乎想放弃。。。本以为是系统的原因重新安装系统好多次都没用,机器是不会出错的,出错的是人是人!!!英语太重要了。。。
附:
官方文档链接:http://hadoop.apache.org/docs/r3.1.0/hadoop-project-dist/hadoop-common/SingleCluster.html
好了,就到这里了。
原文链接