Linux中Hadoop 集群搭建
零、下载Hadoop:
http://archive.cloudera.com/cdh5/cdh/5/?tdsourcetag=s_pctim_aiomsg
一、集群规划:
搭建的 hadoop 集群由 3 台服务器组成,分别叫做 master,salve1 和 slave2。其中 master 作为主节点,slave1 和 slave2 作为从节点。
二、网络配置:
1.查看 3 个节点的主机名是否和规划的一致:
[root@master~]# hostname
master
[root@slave1~]# hostname
slave1
[root@slave2~]# hostname
slave2
2.关闭 3 个节点的防火墙并禁止开机启动:
[root@master~]# systemctl stop firewalld
[root@master~]# systemctl disable firewalld
[root@slave1~]# systemctl stop firewalld
[root@slave1~]# systemctl disable firewalld
[root@slave2~]# systemctl stop firewalld
[root@slave2~]# systemctl disable firewalld
3.分别编辑 3 个节点的 /etc/hosts 文件,配置 IP 和域名:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.199.99 master
192.168.199.101 slave1
192.168.199.102 slave2
# ip在前 主机名在后,完成配置后 主机名可以代替ip使用
4.使用 ping 命令检测 3 个节点间网络是否畅通:
ping master
ping slave1
ping slave2
三、配置 SSH 免密登录:
在 Hadoop 的运行过程中需要不断的登录 3 个节点执行执行命。我们需要配置 SSH 免密登录,省去输入密码的操作,提高效率。
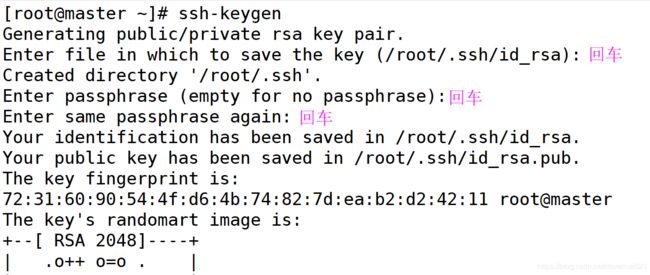
1.在 3 个节点分别执行 ssh-keygen 命令生成 SSH 操作需要的公钥和私钥。命令执行过程中需要输入 3 次回车:
2.在 3 个节点分别执行 ls /root/.ssh 命令查看生成的文件是否完整:
[root@master ~]# ls /root/.ssh
id_rsa id_rsa.pub
[root@slave1~]# ls /root/.ssh
id_rsa id_rsa.pub
[root@slave2~]# ls /root/.ssh
id_rsa id_rsa.pub
3.使用 ping 验证 3 个节点的之间网络是否畅通。
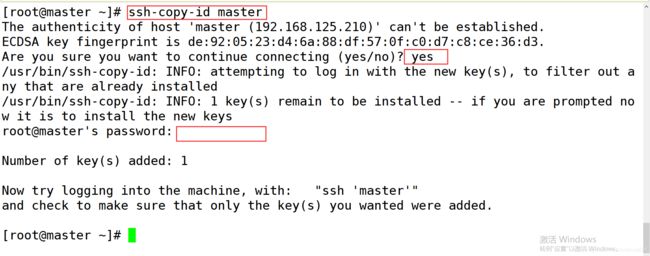
4.在 3 个节点分别执行 ssh-copy-id master 命令发送公钥给 master 节点。根据提示输入 yes 和 master 的密码:
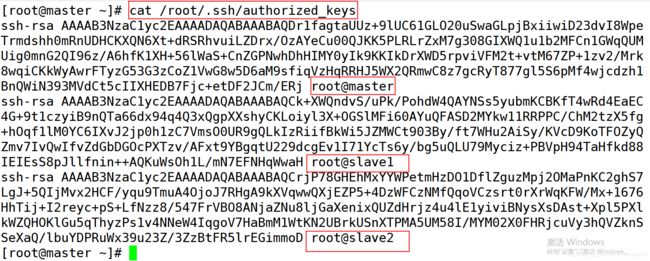
5.在 master 上执行 cat /root/.ssh/authorized_keys 命令查看是否成功收集到 3 个节点的公钥:
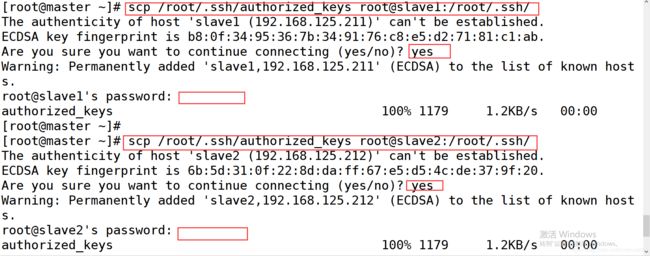
6.在 master 上分别执行以下命令,把 authorized_keys 文件发送给 slave1 和 slave2:
[root@master ~]# scp /root/.ssh/authorized_keys root@slave1:/root/.ssh/
[root@master ~]# scp /root/.ssh/authorized_keys root@slave2:/root/.ssh/
执行过程中按照提示输入 yes 和密码
7.在 3 个节点上分别按顺序执行以下命令,按照提示输入 yes 或密码。
ssh master
exit
ssh slave1
exit
ssh slave2
exit
8.以上有任意一步出错可以删除 3 个节点上 /root/.ssh 文件夹,然后从第 1 步开始重新执行。
四、在 master 上安装 jdk
略:看基本操作 https://blog.csdn.net/ilovehua521/article/details/84257485
五、在 master 上安装 hadoop
1.上传 hadoop 的安装包到 /root 目录,并解压。
2.移动解压后的文件到 /usr/local/hadoop 文件夹。
3.在环境变量文件/etc/profile的最后添加以下内容:
export HADOOP_HOME=/usr/local/hadoop export
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
4.刷新环境变量source /etc/profile并使用 hadoop version 验证是否安装成功:
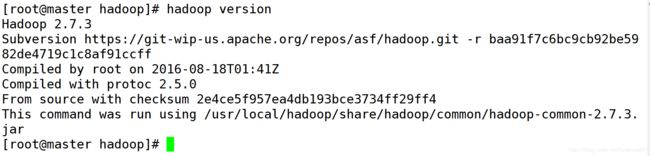
六、配置 master 上的 hadoop
hadoop 的配置文件都在 /usr/local/hadoop/etc/hadoop 目录中,我们需要修改的配置文件共有 7 个。
1.编辑 slaves 文件,设置集群的子节点。删除 localhost,添加 slave1 和 slave2:
[root@master haoop]# vi slaves
slave1
slave2
2.编辑 hadoop-env.sh 文件,修改第 25 行的 JAVA_HOME 为 jdk 的安装目录。(在 vi 中显示行号 使用 :set number):

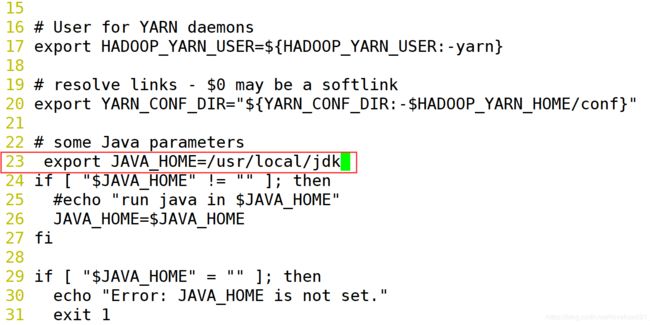
3.编辑 yarn-env.sh 文件,修改第 23 行内容。删除 # 解注释这行配置,修改 JAVA_HOME 为 jdk 的安装目录。
4.编辑 core-site.xml 文件,完整内容如下:
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/usr/local/hadoop/hdfs
5.编辑 hdfs-site.xml 文件,完整内容如下:
dfs.namenode.secondary.http-address
hdfs://master:50090
6.编辑 yarn-site.xml 文件,完整内容如下:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
master
7.重命名 mapred-site.xml.template 文件为 mapred-site.xml,并编辑。完整内容如下:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
七、配置 slave
1. 把 master 安装好的文件复制给 slave:
以下命令都在 master 上执行
使用 scp -r /usr/local/jdk/ root@slave1:/usr/local/ 命令拷贝 jdk 文件夹给 slave1。
使用 scp -r /usr/local/jdk/ root@slave2:/usr/local/ 命令拷贝 jdk 文件夹给 slave2。
使用 scp -r /usr/local/hadoop/ root@slave1:/usr/local/ 命令拷贝 hadoop 文件夹给 slave1。
使用 scp -r /usr/local/hadoop/ root@slave2:/usr/local/ 命令拷贝 hadoop 文件夹给 slave2。
使用 scp /etc/profile root@slave1:/etc/profile 命令拷贝 profile 文件给 slave1。
使用 scp /etc/profile root@slave2:/etc/profile 命令拷贝 profile 文件夹 slave2。
2.配置 slave:
分别在 slave1 和 slave2 上刷新环境变量,然后验证 jdk 和 hadoop 是否安装成功。
注意:
有的时候需要去 slave1 和 slave2 的 /etc/profile 中vi 查看并 wq 一下 然后刷新环境变量才有效
八、格式化 hadoop
注意:格式化操作如果成功,绝对不能执行第二次。
在 master 上执行 hdfs namenode -format 格式化主节点。如果成功会看到 successfully formatted. 提示信息,需要耐心寻找。
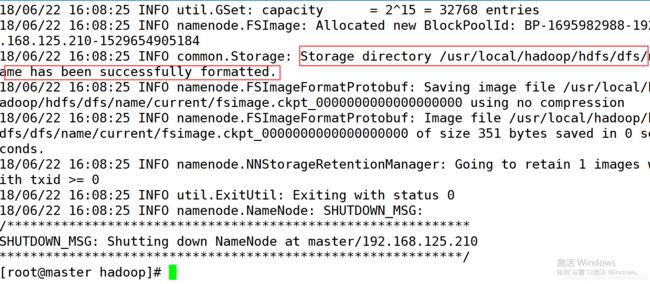
如果没有说明格式化失败,需要删除 3 个节点上的 /usr/local/hadoop 文件夹,然后回到第五步重新开始操作。
九、hadoop 的启动和关闭
格式化成功后我们就可以使用 hadoop 集群了。关闭电脑之前,一定先关闭启动的集群,否则可能导致集群损坏,需要重新安装。无论是启动命令还是关闭命令都只需要在 master 执行即可。
1.启动命令
a.使用 start-dfs.sh 启动 hdfs 功能。
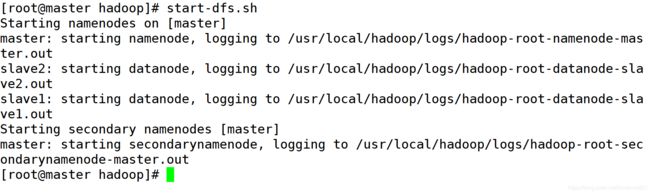
b.使用 start-yarn.sh 启动 yarn 功能。

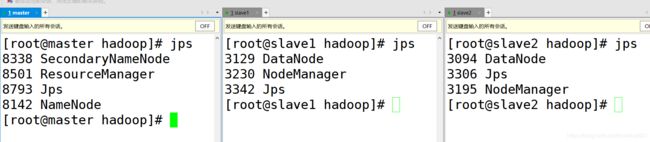
c.分别在 3 个节点执行 jps 命令查看进程。和图片保持一致说明启动成功,没有任何错误。否则关闭集群,并删除 3 个节点的 /usr/local/hadoop 文件夹。然后回到第五步重新开始操作。
2.网页验证:
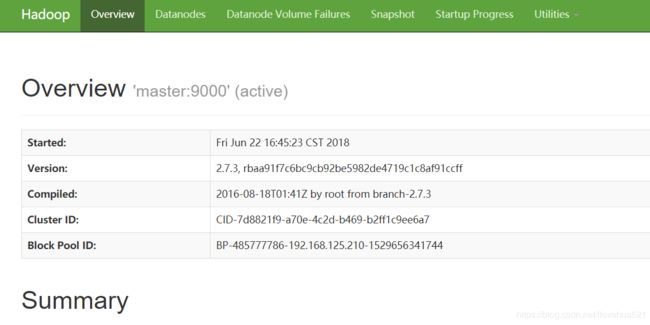
1.浏览器输入 http://master-ip(如192.168.199.99):50070 查看 hdfs 管理页面。
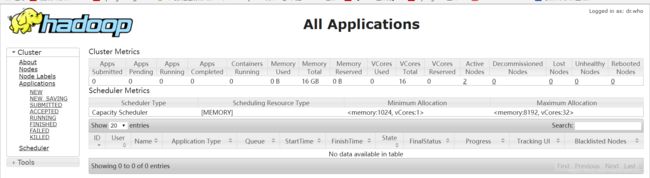
2.浏览器输入http://master-ip(如192.168.199.99):8088 查看 yarn 管理页面。
3.关闭命令:
a.使用 stop-dfs.sh 关闭 hdfs 功能。
b.使用 stop-yarn.sh 关闭 yarn 功能。