Kafka mirroring (MirrorMaker) 和 uReplicator 快速开始
文章目录
- 一、问题背景
- 二、MirrorMaker认识
- Kafka MirrorMaker基本特性
- 三、uReplicator
- uReplicator 概述
- Impact on Overall Stability (对整体稳定性的影响)
- uReplicator Controller
- uReplicator Worker
- SimpleConsumer in uReplicator Worker
- Topic Partition Assignment Management 主题分区 分配管理
- Add new topic
- Delete existing topic
- Expand partitions for existing topic
- Add/remove new uReplicator worker
- Cluster Expansion/Shrinking (集群扩展/收缩)
- Cluster status monitoring/validation
- 四、对比
- MirrorMaker不能满足uber的原因
- uber为什么开发uReplicator
- 使用案例
- uReplicator 编译安装测试
- 参考
一、问题背景
跨数据中心场景下,kafka集群部署模式
参考URL: https://blog.csdn.net/douliw/article/details/60307846
大型的分布式软件,发展到一定阶段,一个数据中心满足不了需求,通常在一个城市会有多个数据中心,一个城市的多个数据中心通过专线连接,延迟比较小。
如果还是满足不了需求,例如你在世界各地都有用户,不可能让美国用户访问中国的服务,延迟非常严重。在一个城市无法做到容灾,例如,发生地震,整个城市都不可用了,这时候,你需要建立跨地域的数据中心。
一旦跨数据中心部署,如何让Kafka高可用?MirrorMaker就是为了解决这个问题而生。
二、MirrorMaker认识
官方: https://kafka.apache.org/documentation.html#basic_ops_mirror_maker
Kakfa MirrorMaker是Kafka 官方提供的跨数据中心的流数据同步方案,其实现原理是通过从Source Cluster消费消息,然后将消息生产到Target Cluster,即普通的消息生产和消费。用户只要通过简单的consumer配置和producer配置,启动Mirror,就可以实现准实时的数据同步。
跟踪 bin/kafka-mirror-maker.sh
exec $(dirname $0)/kafka-run-class.sh kafka.tools.MirrorMaker "$@"
kafka代码搜索关键字 MirrorMaker 发现竟然是scala编写 MirrorMaker.scala
Kafka MirrorMaker基本特性
在Target Cluster没有对应Topic时,Kafka MirrorMaker会自动为我们在Target Cluster上创建一个一模一样(Topic Name、分区数量、副本数量)的topic。如果Target Cluster存在相同的Topic则不进行创建,并且MirrorMaker运行Source Cluster和Target Cluster的Topic的分区数量和副本数量不同。
您可以运行许多这样的镜像进程来提高吞吐量和容错性(如果一个进程死了,其他进程将接管额外的负载)。
The source and destination clusters are completely independent entities: they can have different numbers of partitions and the offsets will not be the same. For this reason the mirror cluster is not really intended as a fault-tolerance mechanism (as the consumer position will be different); for that we recommend using normal in-cluster replication. The mirror maker process will, however, retain and use the message key for partitioning so order is preserved on a per-key basis.
源集群和目标集群是完全独立的实体:它们可以有不同数量的分区,并且偏移量将不相同。因此,镜像集群并不是真正的容错机制(因为使用者的位置不同);为此,我们建议使用正常的集群内复制。但是,mirror maker进程将保留并使用消息key进行分区,这样就可以在每个key的基础上保留
顺序。
三、uReplicator
uReplicator: Uber Engineering’s Robust Apache Kafka Replicator
参考URL: https://eng.uber.com/ureplicator/
uReplicator是uber内部的解决方案,扩展了MirrorMaker,追求可靠性、零数据丢失和易用性,已开源。
在Uber,我们使用ApacheKafka作为连接生态系统不同部分的消息总线。我们从骑手和驾驶员应用程序收集系统和应用程序日志以及事件数据。然后我们通过Kafka将这些数据提供给各种下游消费者。
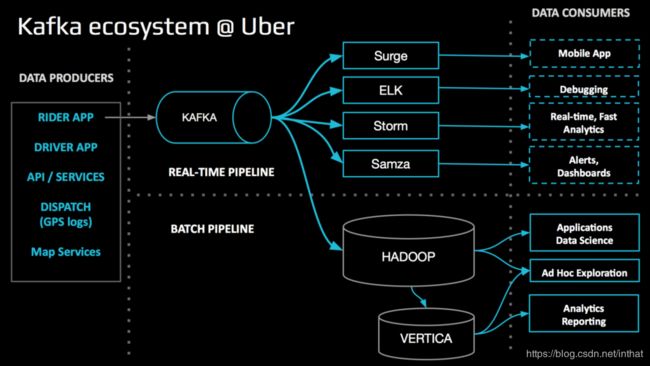 Kafka中同时为实时管道和批处理管道提供数据。前一种数据用于计算业务指标、调试、警报和仪表盘等活动。批处理管道数据更具探索性,例如ETL到ApacheHadoop和HP Vertica。
Kafka中同时为实时管道和批处理管道提供数据。前一种数据用于计算业务指标、调试、警报和仪表盘等活动。批处理管道数据更具探索性,例如ETL到ApacheHadoop和HP Vertica。
In this article, we describe uReplicator, Uber’s open source solution for replicating Apache Kafka data in a robust and reliable manner. This system extends the original design of Kafka’s MirrorMaker to focus on extremely high reliability, a zero-data-loss guarantee, and ease of operation. Running in production since November 2015, uReplicator is a key piece of Uber’s multi–data center infrastructure.
在本文中,我们描述了Uber的开源解决方案uReplicator,它以一种健壮可靠的方式复制ApacheKafka数据。该系统扩展了卡夫卡的原设计,将重点放在极高的可靠性、零数据丢失保证和易操作性上。自2015年11月投入生产以来,uReplicator是Uber多数据中心基础设施的关键组成部分。
考虑到Uber中大量使用Kafka,我们最终会在不同的数据中心使用多个集群。对于各种用例,我们需要查看这些数据的全局视图。例如,为了计算与trips相关的业务指标,我们需要从所有数据中心收集信息并在一个地方对其进行分析。为了实现这一点,我们一直使用kafka包附带的开源mirrormaker工具在数据中心之间复制数据,如下所示。
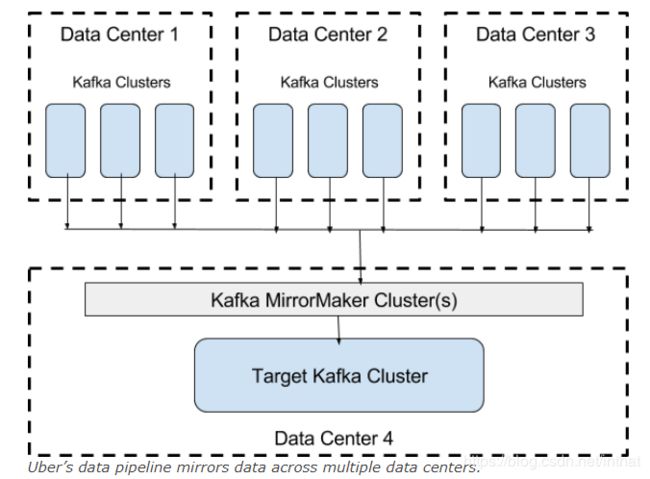 mirrormaker(作为kafka 0.8.2的一部分)本身非常简单。它使用高级kafka消费者从源集群中获取数据,然后将这些数据输入kafka生产者,将其转储到目标集群中。
mirrormaker(作为kafka 0.8.2的一部分)本身非常简单。它使用高级kafka消费者从源集群中获取数据,然后将这些数据输入kafka生产者,将其转储到目标集群中。
uReplicator 概述
uReplicator: Uber Engineering’s Robust Apache Kafka Replicator
参考URL: https://eng.uber.com/ureplicator/
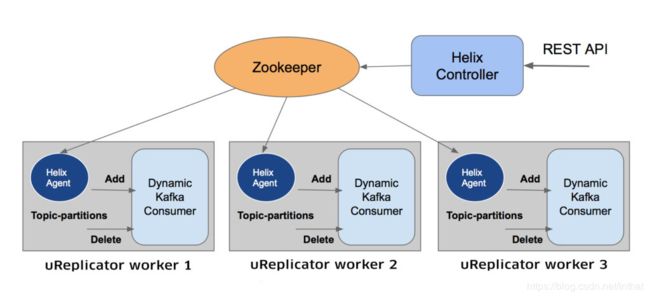
uReplicator的各个组件以不同的方式工作,以实现可靠性和稳定性:
- Helix uReplicator controller
Helix uReplicator 控制器实际上是一个节点集群,它有几个职责:
-
分发主题分区并将其分配给每个工作进程
-
处理添加/删除主题/分区
-
处理添加/删除uReplicator workers
-
检测节点故障并重新分布这些特定的主题分区
-
管理员使用ZooKeeper来完成所有这些任务。它还公开了一个简单的RESTAPI,以便添加/删除/修改要镜像的主题。
-
A uReplicator worker
uReplicator worker类似于kafka镜像功能中 a worker process,它将一组主题分区从源集群复制到目标集群。uReplicator控制器不是重新平衡过程,而是确定uReplicator的分配。此外,我们不使用卡夫卡高级消费者,而是使用一个称为DynamicKafkaConsumer的简化版本。 -
A Helix agent
每当发生更改(添加/删除主题分区)时,每个uReplicator worker 的Helix代理都会收到通知。反过来,它通知dynamickafkaconsumer添加/删除主题分区。 -
A DynamicKafkaConsumer instance
每个UReplicator worker 上都存在一个dynamickAfkaConsumer实例,它是对高级使用者的修改。它删除了重新平衡部分,并添加了一个动态添加/删除主题分区的机制。
例如,假设我们要向现有的uReplicator集群添加一个新主题。事件流程如下:
- Kafka admin adds the new topic to the controller using the following command:
curl
- uReplicator控制器计算出testTopic的分区数,并将主题分区映射到活跃的workers。然后它更新ZooKeeper元数据以反映此映射。
Each corresponding Helix agent receives a callback with notification of the addition of these topic-partitions. In turn, this agent invokes the addFetcherForPartitions function of DynamicKafkaConsumer.
每个对应的Helix代理都会收到一个回调,其中包含添加这些主题分区的通知。反过来,该代理调用dynamickafkaconsumer的addFetcherForPartitions函数。
- dynamickafkaconsumer随后注册这些新分区,找到相应的leader brokers,并将它们添加到fetcher线程以开始数据镜像(同步)。
有关实现的更多详细信息,请参阅ureapplicator设计wiki (https://github.com/uber/uReplicator/wiki)。
Impact on Overall Stability (对整体稳定性的影响)
自从8个月前uReplicator首次在Uber上投入生产以来,我们还没有看到它出现过任何一个产品问题(与实施前几乎每周都会出现的某种故障形成对比)。下图描述了向生产中的mirroring tool (镜像工具)白名单添加新主题的场景。第一个图显示了每个UReplicator工作人员拥有的主题分区总数。每添加一个新主题,此计数都会增加。
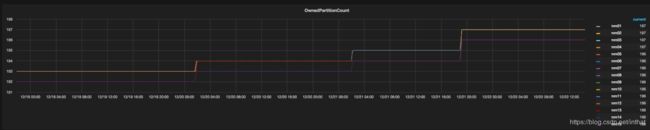 第二个图显示了流向目标集群的相应的UReplicator流量。没有一段时间不活动或负荷高峰,不像Kafka MirrorMaker:
第二个图显示了流向目标集群的相应的UReplicator流量。没有一段时间不活动或负荷高峰,不像Kafka MirrorMaker:
 总之,uReplicator的好处包括:
总之,uReplicator的好处包括:
稳定性:重新平衡现在只在启动期间以及添加或删除节点时发生。此外,它只影响主题分区的一个子集,而不会像以前那样导致完全不活动。
更简单的可伸缩性:现在向现有集群添加一个新节点要简单得多。由于分区分配现在是静态的,所以我们只能智能地将分区的一个子集移动到新节点。其他主题分区不受影响。
操作简单:uber的新镜像工具支持动态白名单。在添加/删除/扩展Kafka主题时,现在不需要重新启动集群。
零数据丢失:ureapplicator保证零数据丢失,因为它只在目标集群上持久化数据之后提交检查点。
uReplicator Controller
uReplicator控制器内部使用一个Helix 控制器进行封装,并处理所有集群管理负载。
Helix Controller
helix是一个通用的集群管理框架,用于自动管理托管在节点集群上的分区、复制和分布式资源。Helix可以在节点故障和恢复、集群扩展和重新配置时自动重新分配资源。
在这个设计中,我们使用helix来管理集群中的所有节点并分配主题分区。我们将每个Kafka主题定义为一个Helix 资源,每个Kafka主题分区定义为一个Helix 分区。helix控制器注册online offline状态模型和定制的平衡逻辑,以管理工作节点和主题分区分配。Helix中定义的IDealstates是面向uReplicator workers的真实主题分区映射,它从源Kafka流中进行消费,并生成到目标Kafka集群。
作为集群管理器,Helix控制器还公开REST端点以接受添加/更新/删除主题的请求。

uReplicator Worker
A uReplicator worker registers itself as a Helix participant. The worker accepts requests from the controller to start/stop consuming for a particular topic partition
uReplicator worker将自己注册为Helix participant。worker 接受来自控制器的请求,以开始/停止消费特定主题分区。
SimpleConsumer in uReplicator Worker
为了充分解决高层次消费者造成的再平衡问题,我们使用了SimpleConsumer。它支持自动添加新主题,并且在分区leaders更改或添加新分区时不会影响现有主题。
Topic Partition Assignment Management 主题分区 分配管理
Add new topic
When you add a new topic to the controller, it assigns each partition to the worker currently serving the minimum number of partitions. Note: If auto topic whitelisting is enabled, the controller auto-whitelists topics in both source and destination Kafka clusters.
当您向控制器添加新主题时,它会将每个分区分配给当前最小分区数的worker。注意:如果启用自动主题白名单,则控制器自动白名单源和目标Kafka集群中的主题。
Delete existing topic
When you delete an existing topic from the controller, it removes this topic from idealStates. Then, the corresponding uReplicator workers get online-to-offline transition messages and drop those topic partitions.
从控制器中删除现有主题时,它会从idealstates中删除此主题。然后,相应的ureapplicator workers 将得到online-to-offline消息,并删除这些主题分区。
Expand partitions for existing topic
When you expand a topic in the controller, it assigns expanded partitions, using the same mechanism as adding new topic. Note: If auto topic whitelisting is enabled, topic expansion in uReplicator happens automatically.
在控制器中扩展主题时,它使用与添加新主题相同的机制分配扩展的分区。注意:如果启用了自动主题白名单,则会自动在ureapplicator中某个主题扩展分区。
Add/remove new uReplicator worker
uReplicator controller registers a listener on live uReplicator instance changes. Whenever uReplicator workers are added/removed, this listener is notified and schedules a rebalance job with a configurable delay (default is 2 minutes). After 2 minutes, the rebalance job starts and checks the current cluster status to determine whether to rebalance. By adding fixed delay here, the controller won’t do a rebalance in the presence of Zookeeper disconnection/reconnection issues or rolling restarting uReplicator workers. Rebalancing only happens when a machine is added or during a failure scenario.
uReplicator控制器注册了一个侦听器关于在线uReplicator 实例改变时。每当添加/删除uReplicator workers 时,都会通知此侦听器,并使用可配置的延迟(默认为2分钟)安排重新平衡作业。2分钟后,重新平衡作业将启动并检查当前集群状态,以确定是否重新平衡。通过在此处添加固定延迟,控制器将不会在出现Zookeeper断开/重新连接问题或滚动重新启动应用程序工作线程时执行重新平衡。重新平衡仅在添加计算机或出现故障时发生。
Cluster Expansion/Shrinking (集群扩展/收缩)
Usually in production, we deploy three controllers, one of which is the leader. All uReplicator workers join the cluster as Helix participants and wait for the topic partitions assignment. The controller detects any new uReplicator workers added or existing workers removed and rebalances the cluster accordingly.
通常在生产中,我们会部署三个控制器,其中一个是领导者。所有的ureapplicator workers作为Helix participants (参与者)加入集群,并等待主题分区分配。控制器检测添加和删除任何新的ureapplicator workers ,并相应地重新平衡集群。
Cluster status monitoring/validation
The controller periodically checks current idealStates and externalView to make sure they are aligned and reports mismatching topics and partitions to metrics. The controller has the option to create a Kafka observer, which periodically fetches topic information from Kafka. In this case, the controller also compares topic info from Kafka brokers with the controller assignment. If the number of partitions assigned differs from what a broker has, the controller reports mismatch topics and partitions metrics.
控制器定期检查当前的idealstate和externalview,以确保它们是对齐的,并将不匹配的主题和分区报告给metrics。控制器可以选择创建一个kafka观察者,该观察者定期从kafka获取主题信息。在这种情况下,控制器还将来自Kafka代理的主题信息与控制器分配进行比较。如果分配的分区数与代理的分区数不同,则控制器将报告不匹配的主题和分区度量。
四、对比
MirrorMaker设计的当前使用 Kafka 高级消费者使用给定区域 Kafka 集群中的数据。 通过这种设计,高级使用者( 由于主题。源群集问题。网络问题等的添加/删除) 中的rebalancing会影响通过Mirrormaker复制的所有主题。
简单操作:易于扩展群集,不需要重新启动白名单主题服务器
MirrorMaker不能满足uber的原因
uReplicator: Uber Engineering’s Robust Apache Kafka Replicator
参考URL: https://eng.uber.com/ureplicator/
尽管我们最初的mirrormaker设置已经足够了,但我们很快就遇到了可伸缩性问题。随着主题数量和数据速率(字节/秒)的增加,我们开始看到延迟的数据传递或数据完全丢失,从而导致生产问题和数据质量下降。对于Uber的特定用例,现有mirrormaker工具(从0.8.2开始)的一些主要问题如下:
-
Expensive rebalancing.(昂贵的再平衡)
如前所述,每个镜子制作者工作人员都使用一个高级消费者。这些消费者通常会经历一个重新平衡的过程。这些消费者通常会经历一个重新平衡的过程。这个过程可能需要很长的时间;我们观察到在某些情况下大约有5-10分钟没有活动。这是一个问题,因为它违反了我们的端到端延迟保证。此外,经过32次再平衡尝试后,消费者可以放弃,永远陷入困境。不幸的是,我们亲眼目睹了几次。在每次重新平衡后,我们都看到类似的流量:
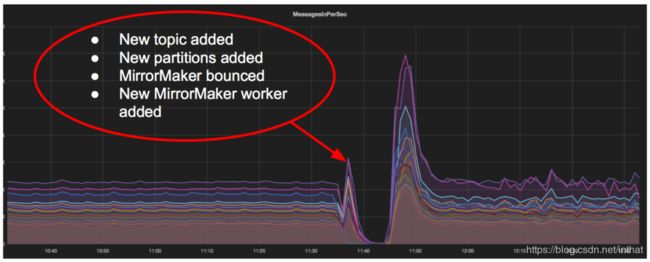 在重新平衡期间的不活动之后,MirrorMaker有大量的数据需要处理。这导致了目标集群上的流量激增,随后导致了所有下游消费者的流量激增,从而导致生产中断和端到端延迟增加。
在重新平衡期间的不活动之后,MirrorMaker有大量的数据需要处理。这导致了目标集群上的流量激增,随后导致了所有下游消费者的流量激增,从而导致生产中断和端到端延迟增加。 -
Difficulty adding topics (添加主题困难)
我们必须在镜像工具中指定主题的白名单,以控制跨广域网链路的数据流数量。对于kafka mirrormaker,这个白名单是完全静态的,我们需要重新启动mirrormaker集群来添加新的主题。重启成本很高,因为它迫使高级消费者重新平衡。这成了一个操作上的噩梦! -
Possible data loss(可能的数据丢失)
旧的mirrormaker有一个问题,它似乎在最新的版本中被修复,自动偏移提交可能导致数据丢失。高级消费者自动提交已提取消息的偏移量。如果在mirrormaker验证它是否确实将消息写入目标集群之前发生故障,那么这些消息将丢失。 -
Metadata sync issues (元数据同步问题)
我们还遇到了配置更新方式的操作问题。为了添加或删除白名单中的主题,我们在一个配置文件中列出了所有最终的主题名称,该文件在mirrormaker初始化期间读取。有时配置在其中一个节点上更新失败。这导致了整个集群的崩溃,因为不同的mirrormaker workers 在要复制的主题列表上没有达成一致。
uber为什么开发uReplicator
我们考虑了以下解决上述问题的备选方案:
a.分为多个MirrorMaker集群。以上列出的大多数问题都是由高水平的消费者再平衡过程造成的。减少其影响的一种方法是限制由一个mirrormaker集群复制的主题分区的数量。因此,我们最终将得到几个mirrormaker集群,每个集群复制要聚合的主题的子集。
好处:
–添加新主题很容易。只需创建一个新集群。
–mirrormaker集群重启速度很快。
弊端:
–这是另一个操作上的噩梦:我们必须部署和维护多个集群。
b.使用Apache Samza进行复制。由于问题出在高层消费者身上(从0.8.2开始),一种解决方案是使用Kafka SimpleConsumer,并添加缺少的领导选举和分区分配部分。流处理框架ApacheSamza已经静态地将分区分配给 workers。然后,我们可以简单地使用samza作业将数据复制和聚合到目的地。
好处:
–高度稳定可靠。
–易于维护。我们可以使用一个作业复制许多主题。
–作业重新启动对复制流量的影响最小。
弊端:
–它仍然是非常静态的。我们需要重新启动作业以添加和/或删除主题。
–我们需要重新启动作业以添加更多workers (从Samza 0.9开始)。
–主题扩展需要明确处理。
c. 使用基于 Helix 消费者。最终,我们决定使用基于Helix 的卡夫卡消费者。在本例中,我们使用apache helix将分区分配给工人,每个工人使用simpleconsumer复制数据。
赞成的意见:
好处:
–添加和删除主题非常简单。
–向mirrormaker集群添加和删除节点非常简单。
–由于操作原因(仅用于升级),我们不需要重新启动集群。
–非常可靠和稳定。
弊端:
这引入了对Helix 的依赖。(这很好,因为Helix 本身非常稳定,我们可以将一个Helix 集群用于多个mirrormaker集群。)
Kafka MirrorMaker with Helix is built for resolving high level consumers rebalancing pain point.
Helix provides a good interface to interact with zookeeper and manages/rebalances a stateful
mapping for instance to simple consumer mapping.
Kafka Mirrormaker with Helix是为解决高层次消费者重新平衡痛点而打造的。
helix提供了一个与zookeeper交互并管理/重新平衡一个稳定的实例到simple 消费者映射。
使用案例
百亿访问量的监控平台如何炼成?
参考URL: https://blog.csdn.net/enweitech/article/details/78909276
WiFi 万能钥匙:
为了实现多机房间数据同步,我们主要是利用 kafka 跨数据中心部署的高可用方案,在对比分析了 MirrorMaker、uReplicator 后,我们决定基于 uReplicator 进行二次开发,主要是因为当 MirrorMaker 节点发生故障时,数据复制延迟较大,对于动态添加 topic 则需要重启进程、黑白名单管理完全静态等。
虽然 uReplicator 针对 MirrorMaker 进行了大量优化,但在我们的大量测试之后仍遇到众多问题,我们需要具备动态管理 MirrorMaker 进程的能力,同时我们也不希望每次都重启 MirrorMaker进程。
uReplicator 编译安装测试
官方: https://github.com/uber/uReplicator/wiki/uReplicator-User-Guide#2-quick-start
uReplicator, Apache Kafka Mirrormaker的改进
参考URL: https://www.helplib.com/GitHub/article_142792
- github 下载代码
- 构建uReplicator
mvn clean package -DskipTests
[INFO] Reactor Summary for uReplicator 2.0.0-SNAPSHOT:
[INFO]
[INFO] uReplicator ........................................ SUCCESS [ 40.165 s]
[INFO] uReplicator-Common ................................. SUCCESS [ 25.353 s]
[INFO] uReplicator-Controller ............................. SUCCESS [ 25.313 s]
[INFO] uReplicator-Worker ................................. SUCCESS [01:21 min]
[INFO] uReplicator-Manager ................................ SUCCESS [ 39.625 s]
[INFO] uReplicator-Distribution ........................... SUCCESS [ 23.794 s]
[INFO] uReplicator-Worker-3.0 ............................. SUCCESS [ 33.476 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
- 设置本地测试环境
为了本地测试uReplicator ,你需要2个系统,一个是kafka一个是zookeeper。
参考
https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=27846330