hadoop入门7
Hive是什么?其体系结构简介(配合sql就会HIVE)最终还是转换成Map/Reduce
Hive的安装与管理
HiveQL数据类型,表以及表的操作
HiveQL查询数据
Hive的Java客户端
Hive的自定义函数UDF Hive的作用是数据挖掘,配合sql
Hive是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储,查询和分析存储在Hadoop中的大规模数据的机制。可以对数据进行操作。语法和MySql是一样的,有了更多的扩展。
优点:可以对数据仓库中的数据进行计算及更定
缺点:不能读数据进行实时修改,将保存数据进行分析计算。 如果不复杂:HIVE,很复杂:UDF
主要为了保存数据,进行分析计算。一次写入,多次分析。部署在hadoop集群上的。定义了简单的类SQL查询语言,称为HQL,允许熟悉SQL的用户查询数据。 Hive依赖HDFS和Yarn。
HIVE:是SQL解析引擎,将SQL语句转义成M/R,然后在Hadoop执行。
Hive的表其实就是HDFS的目录/文件夹,按表明把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。 表->文件夹 数据->文件
用户接口:包括CLI(命令行,脚本),JDBC/ODBC,WebUI 源数据存储,通常存储在关系数据库中 解释器,编译器,优化器,执行器 Hadoop:用HDFS进行存储,利用MapReduce进行计算。
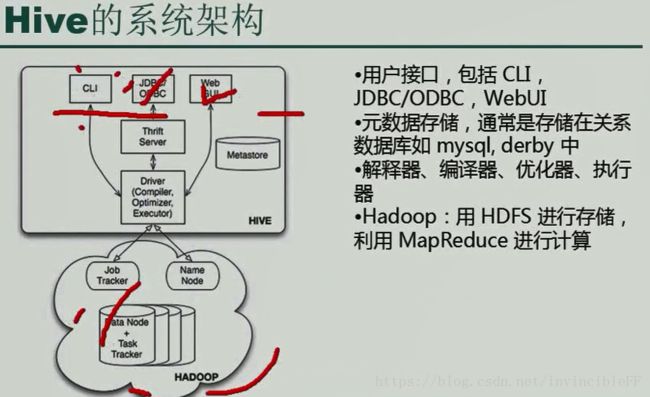
Hive将元数据存储在数据库中(metastore),目前只支持mysql,derby,oracle。
Hive的数据存储在HDFS中,大部分的查询由MapReduce完成,包含*的查询。全表扫描则不会产生该任务select * from table。
Hive是数据仓库,有自己的一套语法:HQL,将语句转换成Map/Reduce,提交到Yarn上,依赖HDFS。操作最多的方式CLI。Hive的表是存放在HDFS上,相互对应,表明->文件夹,内容->文件。 metastore来记录元数据,哪些字段,多少行等内容。
Zookeeper->HDFS->yarn
bin目录和conf目录。本身所属用户和所属组:502 games chown -R root:root Apache... 将所属的目录更改为root。
调用 ./hive 进入到hive的命令行当中去。
hive> fuishow databases;
create table student(id int,name string);
show tables; 就会多一张表 show create table student;
添加数据:load data local inpath '/root/student.txt' into table student;
//添加本地文件数据到student表中去。
还有一个关于列表之间的分隔符,系统是不知道的,因此需要指定一下,不然则是null.
create table teacher (id bigint, name string) row format delimited fields terminated by '\t' 行的分隔符是由'\t' 结束的。
select * from teacher ordey by id desc; 按照id降序,以前需要写一个Map/Reduce,现在只需要写一个SQL语句就OK了。 缺点:延迟太高。时间很长。
创建一个库:
create database itcast;
create table user;
默认的数据库是oderby,这是有缺陷的,如果多个链接的话就不能正常执行,计算通过不同的目录来进行访问时也会出现不出现同一个库的场景,这就导致了我们需要配置mysql为hive的数据库源,这样当你生成一个表的时候里面的字段,主键及表内容里面都记录在了Mysql里面,这是十分方便的。
Hive的语法:
create table student (id bigint,name string) row format delimit fields terminated by '\t' //根据\t生成一个表; //默认目录user hive warehourse上
操作:在mysql中插入该表的描述信息,其次在HDFS上创建一个文件夹,表明和文件夹名一样。 在TBLS上保存了该数据库的信息,表明,所属 COLUMNUS_V2表明了代表的字段内容,id和name。 SDS:处理HDFS上的哪一表上的数据。
hivd> load data local inpath '/root/student.txt' into table student.
select * from student limit 2; //不会执行MapReduce
select sum(id) from student; //首先转换成Map/Reduce
创建一张外部表: Table类型:MANAGED_TABLE:默认:被管理的表。
外部表:先有数据,后有表。创建一张表来指向这些数据。
在hive的状态下查HDFS上的文件: hive> dfs -ls / 原方式:hadoop fs -ls /
创建
hive>mkdir /data
hive> dfs -put /root/student.txt /data/a.txt
hive> dfs -put /root/student.txt /data/b.txt
hive>create external table ext_student (id int,name string) row format delimited fields terminated by '\t' location '/data' //创建一个外部分区表,指向data目录,这样data就是一个表了。然后里面的数据就都可以被查出来了
select * from ext_student 八条数据就出来了
只要将数据放入到该表的目录下,就可以查出来这些数据,不管是内部表还是外部表都OK。
外部表和先建表是一样的,只要在该目录下就OK。TBLS:默认MANAGED_TABLE
外部表:TXTERNAL_TABLE 然后查看COLUMNS_V2查看有哪些字段 最后查看SDS:查询哪里的数据,对应的HDFS上的信息在哪里,每一个表都对应着一个目录,只要将数据放在该目录下就可以进行查询了。HIVE是一个数据仓库,用来进行数据挖掘的,挖掘HDFS里面的内容,将SQL语句,转化为Map/Reduce任务,然后转换到Yarn上。
分区表:将数据进行分区,需要2013年的数据直接定位在2013上。否则就需要进行一个全篇扫描,效率底下,提高查询效率,优先考虑分区表。创建分区表:
hive> create external table beauties (id bigint,name string, size double) partitioned by (nation string) row format delimited fields terminated by '\t' location '/beauty' 首先将元数据信息保存在mysql里面,在HDFS上面创建一个目录,HDFS上就有了beauty目录。
locad data local inpath '/root/b.c' into table beauties partition (nation='China')
//将这里面的内容导出到HDFS中去,同时指明一个分区为China。
//告知mysql我在HDFS里面添加了一条记录,添加了一个partition的分区记录。
hive> alter table beauties add partition (nation='Japan') location "/baeuty/japan"
例子:hive> create table sms (id bigint, content string, area string) partitioned by (area string) row format delimited fields terminated by '\t' //创建一个分区表,根据区域来进行分区
两张表进行关联:select t.account,u.name,t.income,t.expenses,t.surplus from user_info u join (select account,sum(income) as income,sum(expenses) as expenses, sum(income - expenses) as surplus from trade_detail) group by account t on u.account=t.account
将mysq当中的数据直接导入到hive当中:hive笔记
hive> create table trade_detail (id bigint,account string,income double,exepenses double, times string) row format delimited fields terminated by '\t' ; 在hive里面创建了一张表
hive>create table user_info (id int, account string,name string ,age int ) row format delimited fields terminated by '\t' //创建两张表,将mysql数据导入到hive的表里面
sqoop import --connect jdbc:mysql://192.168.1.10:3306/itcast --username root --password 123 --table trade_detail --hive-import --hive-overwrite --hive-table trade_detail --fields-terminated-by '\t'
sqoop import --connect jdbc:mysql://192.168.1.10:3306/itcast --username root --password 123 --table user_info --hive-import --hive-overwrite --hive-table user_info --fields-terminated-by '\t'
注意:这个时候导数据默认时是先导入到HDFS中,导入到一个临时的目录,再把它给load进来,调用hive里面的命令,这个时候就需要将hive添加到环境变量下面去了。在公司当中sqoop用的很多。
hive的UDF:
存储过程是输入和输出,没有返回值,函数则是有返回值的。extendsUDF。自定义函数名称:evaluate。
public station Map
static{
nationMap.put("China","中国");
nationMap.put("China","中国");
nationMap.put("China","中国");
}
Text t=new Text();
public Text evaluate(Text nation){
String nation_e=nation.toString();
String name= nationMap.get(nation_e);
if(name==null){
name="火星人";
}
t.set(name);
return t;
}
路径:通知HIVE,我现在已经定义了一个UDF,需要注册该UDF。
1.添加jar包 hive> add jar /root/NationUDF.jar
2.添加临时函数 create temporary function getNation as cn.itcast.hive.udf.nationUDF
3.调用 select id,name,size,getNation(nation) as nation_name from beauties order by size desc
4.将查询结果保存到HDFS中
数据收集工具-flume
1.flume负责采集产生的日志并写入HDFS中。2.接着进行清洗过滤。3.进行Hive,Pig进行计算。4.将结果保存起来。最好将数据导入到关系型数据库中。 收集数据->过滤->计算->导入数据
负载均衡服务器:负责消息的转发。轮询策略,权重策略。三者之间session共享。
Flume就是一个Agent组件,Source是用来采集数据的,Channel暂时存放数据,Sink将数据写入到某种介质中去
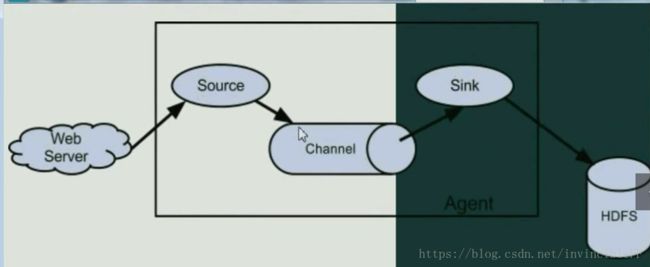
Source:可以用来各种组合,https等。Channel缺点是容易丢失,暂时存放数据。Sink:写入到介质中,可以进行各种的组合。 有很多种Sink,很多种Source。很多种Channel。
Flume收集数据:
只要安装jdk就可以了。在机器上单独地部署flume,bin下面有一个脚本flume-ng,conf里面的内容,配置文件,第一个修改mv flume-env.sh.template flume-env.sh 把JAVA的路径导进来 。 采集数据并写入到HDFS上,因此这里需要配置Source,Channel,Sink。
定义一个Agent:基于多Agent:多个代理采集数据,包含Source,Channel,Sink。
1.定义agent名字, a4.sources=r1
a4.channels=c1
a4.sinks=k1 //定义了一个Agent及他们的名字
2.具体定义
a4.sources.r1.type=spoldir //监听一个目录,只要放数据就会写入进来,并且写入到Channel中,再写给Sink
a4.sources.r1.spoolDir = /root/logs //监听目录内容
a4.channels.c1.type=memory
a4.channels.c1.capacity=10000 //容纳多少条数据
a4.channels.c1.transactionCapacity=100
3.定义sink
a4.sinks.k1.type=hdf
a4.sinks.k1.hdfs.path=hdfs://ns1/flume/%y%m%d
a4.sinks.k1.hdfs.filePrefix=events- //生成日志前缀
a4.sinks.k1.hdfs.fileType=DataStream //纯文本方式
a4.sinks.k1.hdfs.rollCount=0 //多少条数据flush成一个文件,10条等
a4.sinks.k1.hdfs.rollSize=134217728 //文件达到128M时生成一个文件
a4.sinks.k1.hdfs.rollInterval=60 HDFS上的文件达到60生成一个文件。
#定义拦截器,为消息添加时间戳,这样就可以查找到数据发送过来的事件了。
a4.sources.r1.interceptors = i1
a4.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
4.组装Source,Channel,以及Sink
#组装source、channel、sink
a4.sources.r1.channels = c1
a4.sinks.k1.channel = c1
启动flume: bin/flume-ng agent -n(agent名称) a4 -c(配置信息) conf -f(什么类型的source,chennel等) conf/a4.conf -Dflume.root.logger=INFO,(指定运行时参数,把日志打出来)console。 需要一些jar包,hadoop的jar包。根据情况逐一导包。运行后就一直打印调试日志,这个时候上传包过来、添加映射,这样才知道对应的主机名到底是什么ip内容。
总结:利用flume,通过指定一个文件夹,如果该文件夹的内容有稍微的改动,就会被记录到HDFS中去,利用的是一个Agent。
关键指标:
浏览量:PV。是指所有用户浏览页面的综合,一个独立用户每打开一个页面就被记录1次。
分析:网站总浏览量,可以考核用户对于网站的兴趣,就像收视率对于电视剧一样。但是对于网站运营者来说,更重要的是每个栏目下的浏览量。
访客数UV(包括新访客数,新房客比例):Unit View:每个人的访问量。
定义:唯一访客数,一天之内网站的独立访客数,以Cookie为依据。
IP:大多数都是公网IP,但是可以查询出用户的地址是在哪里。
跳出率:跳出率很高:很失败。用户点击进来就会弹出去。
板块热度排行榜
crontab -e:编辑自己的定时器
* 1 * * * echo 111> /root/logs:每天凌晨1点执行一次命令
30 6 * * * 每天6点30分 30 6 1,15 * * 每个月的1号,15号
编写一个自动化脚本:
完成初始化功能:数据已经存在的情况下:1.在Hive下建表,外部分区表:
//创建一张外部分区表
create external table hmbbs(ip string,longtime string,url string) partitioned by () format delimited fields termianted by '\t' location '/cleaned';
写shell脚本自动化:
vim daily.sh 每天执行脚本
chomod +x dailly.sh //增加权限
根据map/reduce进行数据清洗:利用cleaner.jar用来清洗日志的。
hadoop jar cleaner.jar /flume/140630 /out140630
脚本里面调用 vim daily.sh CURRENT=`date +%y%m%d`
在其中写绝对路径,hadoop的bin目录
# /itcast/hadoop-2.2.2.2/bin/hadoop jar /root/cleaner.jar /flume/$CURRENT /cleaned/$CURRENT //清洗完的数据
#将清洗完的数据添加到HBase这个表中去。 select * from hmbbs; 分区表
跳转到hive的绝对路径下
开发步骤:
1.flume,用来采集数据:利用crontab -e 定时器来获取数据。
2.对数据进行清洗
3.使用hive进行数据的多维分析 建立一个外部分区表(语句写好,自动执行)
4.把hive分析结果通过sqoop导出到mysql中
5.提供视图工具供用户使用 通过页面展示出来 FreeChat
crontab -e
* 1 * * * echo 111> /root/logs 每天凌晨执行一次追加111到logs中去
*分*/1:代表每一分钟 *小时 *日 *月 *周 命令
自动化脚本:1.初始化:
//1.创建一张外部分区表
create external table hmbbs (ip string, logtime string, url string) partitioned by (logdate string) row format delimited fields terminated by '\t' location '/cleaned'
//2.创建一个shell脚本
touch daily.sh
chmod +x daily.sh 添加
//3.清理日志,通过一个写好的Map/Reduce ip,事件,url
hadoop jar cleaner.jar /flume/140630 /out140630 测试清理日志
vim daily.sh:定义时间变量 CURRENT=`date +%y%m%d`
echo $CURRENT 验证是否正确打印日期,写成一个变量
在shell脚本里面写绝对路径。
/itcast/hadoop-2.2.0/bin/hadoop jar /root/cleaner.jar /flume/$CURRENT /cleaned/$CURRENT 将清洗过的数据放入到该文件夹下
可以在外面使用: hive -e "show tables;" 即可,不用进入到hive里面去
hive -e "alter table hmbbs add partition logdate=$CURRENT location '/cleaned/$CURRENT' " //给mysql添加一个自动化分区,按照时间来进行分区
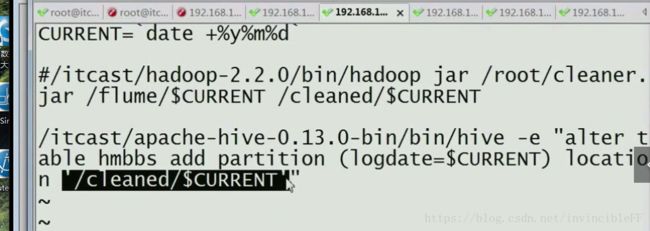
这里是shell脚本里面的内容:CURRENT是每天的时间。输入hive指令:表更我的hmbbs这张表,然后添加一个分区,分区的文件夹就是我的logdate里面的每日时间,接着链接到HDFS下的/cleaned的目录中去,就是清洗过的数据。
//4.通过hive进行分析:在脚本文件中
hive -e "select count(*) from hmbbs where logdate=$CURRENT"
//5.保存结果:create table pv_$CURRENT row format delimited fields terminated by '\t' as select count(*) from hmbbs where logdate=$CURRENT 放入到一张表中去。
//6.得到重点客户信息:查看谁每天点击20次,从高到低进行排列。
脚本文件中: hive -e "select $CURRENT,ip,count(*) as hit from hmbbs where logdate =$CURRENT group by ip having hits >20 order by hits desc limit 20"
将数据进行保存,创建一张表。