Endeca Relevance Ranking(相关度排序)
Relevance Ranking Module 详解
Exact:(精确匹配)
将整个结果进行一个分层,最高的层次,即最先呈现给用户的层次,是完全精确匹配term的,第二层是将term 拆分后匹配的层次,第三层就是其他命中的层次。
举个例子,比如现在sku.displayName这个property 有Nike Shoes, Nike XM Shoes,Nike-Shoes,"Nike Shoes"等,那么最高层会将Nike Shoes放在第一层,然后包含Nike 或者 Shoes放在第二个层次,然后其他的比如Nike-Shoes,"Nike Shoes"放在第三层。
Filed:(字段匹配)
根据search interface 里的字段在整个成员列表list的优先级别来设定的,排在最前面的优先级最高。
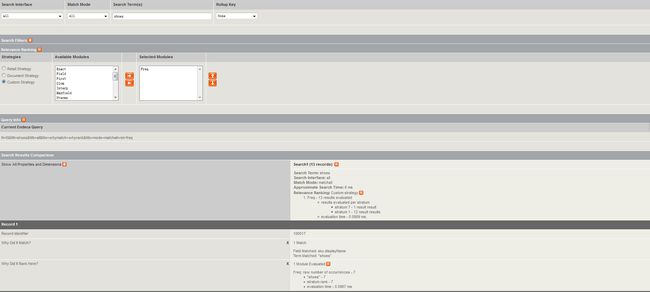
1 会对每一个结果打分
2 打分的依据是search interface 里的dimension/ property 成员的static filed rank
3 static field rank 是根据search interface 里的成员列表的顺序决定的。
对于cross-filed我们默认的分数是0,但是我们也可以在Developer Studio改变他的indexator.
举个例子:
MatchMode: All
SearchInterface: All
Search Term: Nike Plastic
Search Interface 里默认的字段:
material,color,displayName.(注意material是第一个,默认的rank值最高)
CROSS_FIELD_BOUNDARY="ALWAYS/ON-FAILURE"

当前Filed Match 如果匹配上material的,那么就会放在最上面一层,依次是sku.color,clor,sku.displaName等等。最后呈现给用户的就是依照这个层次放的顺序结果。
匹配的上的话那么
FieldMatch:materia
匹配不上的话:
Field: cross-field (null)
- stratum rank - 0
- evaluation time - 0.0012 ms
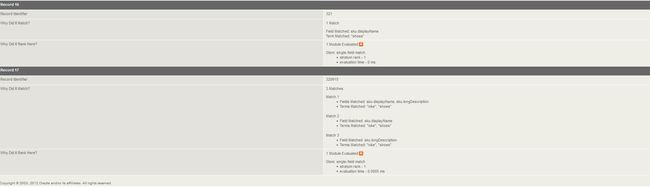
Frequency(Freq):
在result text里,基于用户的query term发生的次数进行一个打分,越多分数越高。
一般会分成1-N个层次:
那么取决于你的result text 包含这个terms的多少。如果只有1个,那么只有一层:
strata:1, 如果有N个,那么 stata:N
那么最多的会最先呈现给用户。
Glom:
对单字段的匹配优先于多字段的匹配。一般和MaxFiled module搭配使用。在这种模式下,MatchAny 对于 cross-fileds来讲是无效的的额,因为每一个单独的term
都可以是作为single-field.
假设当前
Search Terms: Nike Shoes
Search Interface: all
Match Mode: matchAll
当我搜索的时候,首先匹配Match All,即字段包含Nike 且包含 Shoes,那么才会进行相关度的排序。
然后针对单个字段排名,排名排完了,然后根据cross-filed是否启用,如果启用,那么glom
只有2层,如果没启用只有1层。在cross-field的时候,比如我有两个字段都包含Nike Shoes,那么多字段匹配才会把这个记录放在本层。
一般会考虑到要有足够的term来满足搜索,那么一般都会放在NTerms后面。
Interpreted:
1 非partial 的 match 排名排在partial的前面
2 单字段匹配排民优先于cross-field匹配
3 非拼写检查的排名排在拼写检查的前面
4 同义词匹配的排名在非同义词匹配的后面
5 Stemming匹配的排名排在非stemming的排名的后面
Maximum Field
其实和Field排名模块差不多,除了在跨字段匹配的时候有一点区别:
不像Filed,分配一个静态的分数给cross-filed 匹配,而MaxField会选择rank值对于匹配来讲最高的字段
Numfields
什么意思呢?根据结果集里面,当前匹配模式下,包含用户query term的字段越多,rank值越大,排名越靠前
比如:
RecordA:
sku.displayName:Nike Shoes
sku.description: Alert Frame Nike Shoes
RecordB:sku.displayName:Nike
因为Record A 有两个字段包含用户search的 query item。而RecordB只有一个字段,所以RecordA的 排名在Record的前面。
NTerms:
意思是用户提供的query terms, 包含的单词越多的,排名越靠前,越少的越在后面,比如Nike Shoes, 全部匹配的在rank值高于仅仅匹配一个Nike 或者Shoes的记录。

Phrase
表示用户的term 全部精确匹配或者 部分作为一个phrase进行匹配,匹配度越高,rank值越高,没有的匹配就排在最后面。
The Phrase options are:
• Rank based on length of subphrases
• Use approximate subphrase/phrase matching
• Apply spell correction, thesaurus, and stemming
Static
给每一个结果打分,打分基于一个数字或者常量值,要取决于搜索的类型和传递给模块的参数,第一个参数是property 或者dimension,第二个参数为排序参数。
For example, using the module Static(Availability,descending) would sort result records in descending
order with respect to their assignments from the Availability property. Using the module
Static(Title,ascending) would sort result records in ascending order by their Title property assignments.
Relevance Ranking strategies are used in two main contexts in the MDEX Engine:在MDEX Engine有两种排名策略:
1 在search interface里面配置
2 在查询级别去设置,然后覆盖掉search interface的排名策略。比如通过url 查询,在查询的时候我们可以设置参数:
Nrk=search-interface
Nrt=relrank-terms
Nrr=relrank-strategy
Nrm=relrank-matchmode
For Example:
&Nrk=All&Nrt=citrus&Nrr=maxfield&Nrm=matchall