面试-8种 常用数据结构总结
1976年,一个瑞士计算机科学家写一本书《Algorithms + Data Structures = Programs》。即:算法 + 数据结构 = 程序。40多年过去了,这个等式依然成立。
很多代码面试题都要求候选者深入理解数据结构,不管你来自大学计算机专业还是编程培训机构,也不管你有多少年编程经验。有时面试题会直接提到数据结构,比如“给我实现一个二叉树”,然而有时则不那么明显,比如“统计一下每个作者写的书的数量”。
什么是数据结构?
数据结构是计算机存储、组织数据的方式。对于特定的数据结构(比如数组),有些操作效率很高(读某个数组元素),有些操作的效率很低(删除某个数组元素)。程序员的目标是为当前的问题选择最优的数据结构。
为什么我们需要数据结构?
数据是程序的核心要素,因此数据结构的价值不言而喻。无论你在写什么程序,你都需要与数据打交道,比如员工工资、股票价格、杂货清单或者电话本。在不同场景下,数据需要以特定的方式存储,我们有不同的数据结构可以满足我们的需求。
8种常用数据结构
- 数组
- 栈
- 队列
- 链表
- 图
- 树
- 前缀树
- 哈希表
1. 数组
数组(Array)大概是最简单,也是最常用的数据结构了。其他数据结构,比如栈和队列都是由数组衍生出来的。
下图展示了1个数组,它有4个元素:
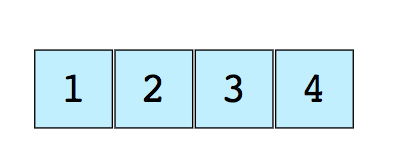
每一个数组元素的位置由数字编号,称为下标或者索引(index)。大多数编程语言的数组第一个元素的下标是0。
根据维度区分,有2种不同的数组:
- 一维数组(如上图所示)
- 多维数组(数组的元素为数组)
数组的基本操作
- Insert - 在某个索引处插入元素
- Get - 读取某个索引处的元素
- Delete - 删除某个索引处的元素
- Size - 获取数组的长度
常见数组代码面试题
- 查找数组中第二小的元素
- 查找第一个没有重复的数组元素
- 合并2个排序好的数组
- 重新排列数组中的正数和负数
2. 栈
撤回,即Ctrl+Z,是我们最常见的操作之一,大多数应用都会支持这个功能。你知道它是怎么实现的吗?答案是这样的:把之前的应用状态(限制个数)保存到内存中,最近的状态放到第一个。这时,我们需要栈(stack)来实现这个功能。
栈中的元素采用LIFO (Last In First Out),即后进先出。
下图的栈有3个元素,3在最上面,因此它会被第一个移除:

栈的基本操作
- Push — 在栈的最上方插入元素
- Pop — 返回栈最上方的元素,并将其删除
- isEmpty — 查询栈是否为空
- Top — 返回栈最上方的元素,并不删除
常见的栈代码面试题
- 使用栈计算后缀表达式
- 使用栈为栈中的元素排序
- 检查字符串中的括号是否匹配正确
内存中的堆栈和数据结构堆栈不是一个概念,可以说内存中的堆栈是真实存在的物理区,数据结构中的堆栈是抽象的数据存储结构。
1.内存中的堆栈
1)寄存器:最快的存储区, 由编译器根据需求进行分配,我们在程序中无法控制.
2)栈:存放基本类型的变量数据和对象的引用,但对象本身不存放在栈中,而是存放在堆(new 出来的对象)或者常量池中(字符串常量对象存放在常量池中。)
3)堆:存放所有new出来的对象。
4)静态域:存放静态成员(static定义的)
5)常量池:存放字符串常量和基本类型常量(public static final)。
6)非RAM存储:硬盘等永久存储空间
内存空间在逻辑上分为三部分:代码区、静态数据区和动态数据区,动态数据区又分为栈区和堆区。
代码区:存储方法体的二进制代码。高级调度(作业调度)、中级调度(内存调度)、低级调度(进程调度)控制代码区执行代码的切换。
静态数据区:存储全局变量、静态变量、常量,常量包括final修饰的常量和String常量。系统自动分配和回收。
栈区:存储运行方法的形参、局部变量、返回值。由系统自动分配和回收。
例如 int method(int a){int b;}栈中存储参数a、局部变量b、返回值temp。
堆区:new一个对象的引用或地址存储在栈区,指向该对象存储在堆区中的真实数据。由程序员分配和回收(Java中由JVM虚拟机的垃圾回收机制自动回收)。
例如 Class Student{int num; int age;} main方法中Student stu = new Student();分配堆区空间中存储的该对象的num、age,变量stu存储在栈中,里面的值是对应堆区空间的引用或地址。
2.数据结构中的堆栈
栈:是一种连续存储的数据结构,特点是存储的数据先进后出。
堆:是一棵完全二叉树结构,特点是父节点的值大于(小于)两个子节点的值(分别称为大顶堆和小顶堆)。它常用于管理算法执行过程中的信息,应用场景包括堆排序,优先队列等。
3. 队列
队列(Queue)与栈类似,都是采用线性结构存储数据。它们的区别在于,栈采用LIFO方式,而队列采用先进先出,即FIFO(First in First Out)。
下图展示了一个队列,1是最上面的元素,它会被第一个移除:
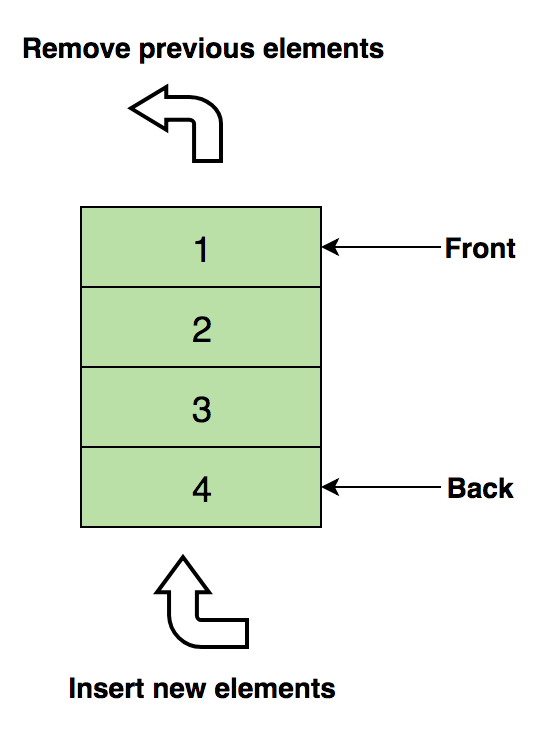
队列的基本操作
- Enqueue — 在队列末尾插入元素
- Dequeue — 将队列第一个元素删除
- isEmpty — 查询队列是否为空
- Top — 返回队列的第一个元素
常见的队列代码面试题
- 使用队列实现栈
- 倒转队列的前K个元素
- 使用队列将1到n转换为二进制
4. 链表
链表(Linked List)也是线性结构,它与数组看起来非常像,但是它们的内存分配方式、内部结构和插入删除操作方式都不一样。
链表是一系列节点组成的链,每一个节点保存了数据以及指向下一个节点的指针。链表头指针指向第一个节点,如果链表为空,则头指针为空或者为null。
链表可以用来实现文件系统、哈希表和邻接表。
下图展示了一个链表,它有3个节点:

链表分为2种:
- 单向链表
- 双向链表
链表的基本操作
- InsertAtEnd — 在链表结尾插入元素
- InsertAtHead — 在链表开头插入元素
- Delete — 删除链表的指定元素
- DeleteAtHead — 删除链表第一个元素
- Search — 在链表中查询指定元素
- isEmpty — 查询链表是否为空
常见的队列代码面试题
- 倒转1个链表
- 检查链表中是否存在循环
- 返回链表倒数第N个元素
- 移除链表中的重复元素
5. 图
图(graph)由多个节点(vertex)构成,节点之间阔以互相连接组成一个网络。(x, y)表示一条边(edge),它表示节点x与y相连。边可能会有权值(weight/cost)。
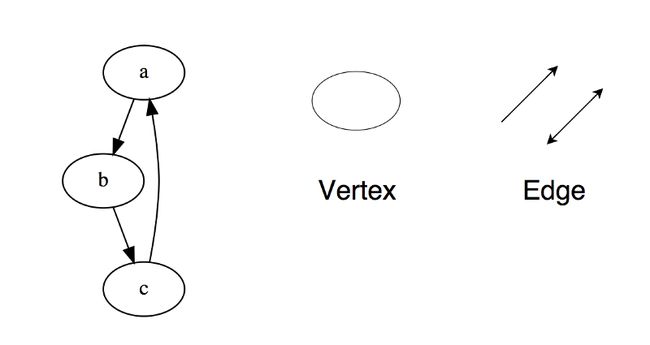
图分为两种:
- 无向图
- 有向图
在编程语言中,图有可能有以下两种形式表示:
- 邻接矩阵(Adjacency Matrix)
- 邻接表(Adjacency List)
遍历图有两周算法
- 广度优先搜索(Breadth First Search)
- 深度优先搜索(Depth First Search)
常见的图代码面试题
- 实现广度优先搜索
- 实现深度优先搜索
- 检查图是否为树
- 统计图中边的个数
- 使用Dijkstra算法查找两个节点之间的最短距离
6. 树
树(Tree)是一个分层的数据结构,由节点和连接节点的边组成。树是一种特殊的图,它与图最大的区别是没有循环。
树被广泛应用在人工智能和一些复杂算法中,用来提供高效的存储结构。
下图是一个简单的树以及与树相关的术语:

树有很多分类:
- N叉树(N-ary Tree)
- 平衡树(Balanced Tree)
- 二叉树(Binary Tree)
- 二叉查找树(Binary Search Tree)
- 平衡二叉树(AVL Tree)
- 红黑树(Red Black Tree)
- 2-3树(2–3 Tree)
其中,二叉树和二叉查找树是最常用的树。
常见的树代码面试题
- 计算树的高度
- 查找二叉平衡树中第K大的元素
- 查找树中与根节点距离为k的节点
- 查找二叉树中某个节点所有祖先节点
7. 前缀树
前缀树(Prefix Trees或者Trie)与树类似,用于处理字符串相关的问题时非常高效。它可以实现快速检索,常用于字典中的单词查询,搜索引擎的自动补全甚至IP路由。
下图展示了“top”, “thus”和“their”三个单词在前缀树中如何存储的:

单词是按照字母从上往下存储,“p”, “s”和“r”节点分别表示“top”, “thus”和“their”的单词结尾。
常见的树代码面试题
- 统计前缀树表示的单词个数
- 使用前缀树为字符串数组排序
8. 哈希表
哈希(Hash)将某个对象变换为唯一标识符,该标识符通常用一个短的随机字母和数字组成的字符串来代表。哈希可以用来实现各种数据结构,其中最常用的就是哈希表(hash table)。
哈希表通常由数组实现。
哈希表的性能取决于3个指标:
- 哈希函数
- 哈希表的大小
- 哈希冲突处理方式
下图展示了有数组实现的哈希表,数组的下标即为哈希值,由哈希函数计算,作为哈希表的键(key),而数组中保存的数据即为值(value):

常见的哈希表代码面试题
- 查找数组中对称的组合
- 确认某个数组的元素是否为另一个数组元素的子集
- 确认给定的数组是否互斥
参考
- Fundebug博客 - Node.js面试题之2017
- Fundebug博客 - 快速掌握JavaScript面试基础知识(一)
- Fundebug博客 - 快速掌握JavaScript面试基础知识(二)
- Fundebug博客 - 快速掌握JavaScript面试基础知识(三)
- GeeksforGeeks
关于Fundebug
Fundebug专注于JavaScript、微信小程序、微信小游戏、支付宝小程序、React Native、Node.js和Java实时BUG监控。 自从2016年双十一正式上线,Fundebug累计处理了9亿+错误事件,得到了Google、360、金山软件等众多知名用户的认可。欢迎免费试用!

版权声明:
转载时请注明作者Fundebug以及本文地址:
https://blog.fundebug.com/2018/08/27/code-interview-data-structure/