
在 IBM Bluemix 云平台上开发并部署您的下一个应用。
Apache Spark 是加州大学伯克利分校的 AMPLabs 开发的开源分布式轻量级通用计算框架。由于 Spark 基于内存设计,使得它拥有比 Hadoop 更高的性能(极端情况下可以达到 100x),并且对多语言(Scala、Java、Python)提供支持。其一栈式设计特点使得我们的学习和维护成本大大地减少,而且其提供了很好的容错解决方案。
本文将详细地介绍如何使用 Spark Streaming 流计算并结合 Kafka、Flume 等实时处理搜索词、订单以及订单搜索词来关联系统的设计。
业务场景分析
首先我们来了解业务场景。我们每天都有来自各大搜索引擎搜索的数据,并根据相关的关键字进入到我们的相关产品页面,用户可能会购买这些产品,我们现在需要分析的是哪些搜索词带来的订单比较多,然后根据分析结果多投放这些转化率比较高的关键词,从而为我们带来更多的收益。原先我们的做法是每天凌晨分析前一天的日志数据,这种方式实时性不高,而且由于日志量比较大(目前每秒达到 6000+条日志),单台机器处理已经达到了瓶颈。经过调研,综合分析,最后我们选择了使用 Spark Streaming + Kafka+Flume 来处理这些日志,并且运行在 YARN 上以应对遇到的问题。
回页首
系统设计
先来看下我们系统的设计图,如图 1 所示:
图 1. 案例系统设计图
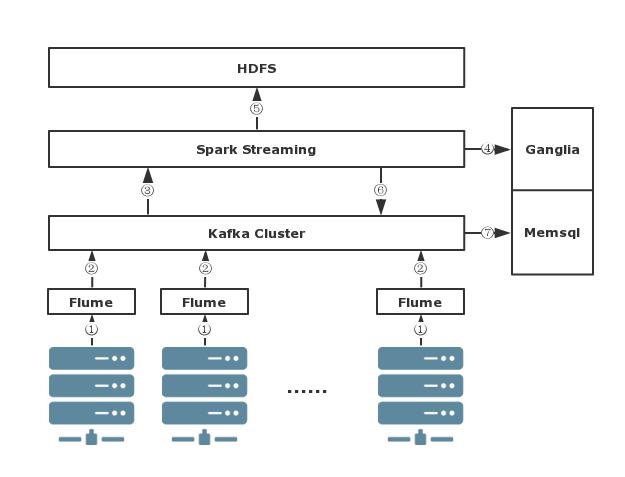
- 业务日志是分布到各台服务器上。由于业务量比较大,所以日志都是按小时切分的,我们采用 Flume 实时收集这些日志(图中步骤①),然后发送到 Kafka 集群(图中步骤②)。Flume 实时收集插件是我们自己开发的,支持处理小时日志切割、断点续传、失败重试、任何一条日志都可以追溯到源等。在入 Kafka 的时候为了使得日志能够均匀地分布在 Kafka 集群的各台机器上,我们按照一定的规则进行分区。这里为什么不直接将原始日志直接发送到 Spark Streaming 呢?因为一方面将原始日志通过 Flume 发送到 Kafka 可以共享给其他项目,甚至是其他部门使用;另一方面假设 Spark Streaming 作业挂掉了,也不会影响到日志的实时收集。
- 日志实时到达 Kafka 集群后,我们再通过 Spark Streaming 实时地从 Kafka 拉数据(图中步骤③),然后解析日志、根据一定的逻辑过滤一些爬虫日志、订单搜索词关联等业务处理。从 Kafka 中拉数据我们使用到 Spark 的 KafkaUtils.createDirectStream API,代码片段如下:
清单 1. 创建 DStream
val sparkConf = new SparkConf().setAppName("OrderSpark") val sc = new SparkContext(sparkConf) val ssc = new StreamingContext(sc, Seconds(2)) val kafkaParams = Map[String, String]("metadata.broker.list" -> brokerAddress, "group.id" -> groupId) val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, Set(topic))返回的
messages 是一个 DStream,它是对 RDD 的封装,其上的很多操作都类似于 RDD。createDirectStream 函数是 Spark 1.3.0 开始引入的,其内部实现是调用 Kafka 的低层次 API,Spark 本身维护 Kafka 偏移量等信息,所以可以保证数据零丢失(但是有些情况下可能会导致数据被读取了两次),我们可以通过下面的代码获取 Kafka 各个分区的读偏移量。清单 2. 获取 Kafka 的读偏移量
messages.foreachRDD(rdd => { val offsets = rdd.asInstanceOf[HasOffsetRanges].offsetRanges offsets.foreach(offset => println(offset.partition + ": OffSet:" + offset.untilOffset)) })offsets 类型是 Array[OffsetRange],存储的是 Topic 每个分区编号及其偏移量信息。我们可以对 offsets 进行计算,并将这些偏移量信息发送到 Ganglia,甚至发到 Zookeeper 分别用于读数据监控 Spark 作业和监控 Kafka 消息(图中步骤④)。
- 为了能够在 Spark Streaming 程序挂掉后又能从断点处恢复,我们每隔 2 秒进行一次 Checkpoint,这些 Checkpoint 文件是存储在 HDFS 上(图中步骤⑤)的。在 Checkpoint 目录中主要存储两种数据:MetaDate checkpointing 和 Data checkpointing。我们可以手动在程序里面加入以下代码,如清单 3 所示:
清单 3. 对 Streaming 程序设置 checkpoint
ssc.checkpoint(checkpointDirectory)
如果我们需要从 checkpoint 目录中恢复,我们可以使用 StreamingContext 中的 getOrCreate 函数。如清单 4 所示:
清单 4. 从 checkpoint 目录恢复
val ssc = StreamingContext.getOrCreate(checkpointDirectory, creatingFunc = () => { //程序恢复逻辑 }) ssc.start() ssc.awaitTermination() ssc.stop() - 为了使得计算完的程序共享给其他 Job 或者其他业务线,我们将分析、关联好的数据重新发送到 Kafka(图中步骤⑥)。为了节省 Kafka 数据存储空间,所以只保存近 7 天的数据量。
清单 5. 业务逻辑处理
val windowsResult = messages.filter(//爬虫过滤规则) .combineByKey[TreeSet[OrderEntry]](TreeSet[OrderEntry](_), _ += _, _ ++= _, new HashPartitioner(numPartition)) .reduceByKeyAndWindow((x: TreeSet[OrderEntry], y: TreeSet[OrderEntry]) => x ++= y, (x: TreeSet[OrderEntry], y: TreeSet[OrderEntry]) => x --= y, Minutes(120), Seconds(2), numPartition, (item: (String, TreeSet[OrderEntry])) => item._2.size != 0) - 最后,我们单独启动了一个程序从 Kafka 中实时地将分析好的数据存到 MemSql 中用于持久化存储(图中步骤⑦)。MemSql 是一款基于内存的分布式关系数据库,它通过将数据存储在内存中,并将 SQL 语句预编译为 C++而获得极速的执行效率。而且兼容 MySQL,速度要比 MySQL 快 30 倍,能实现每秒 150 万次事务。目前 MemSql 数据库提供了免费的社区版。
回页首
监控
系统部署上线之后,我们无法保证系统 7x24 小时都正常运行,即使是在运行着,我们也无法保证 Job 不堆积、是否及时处理 Kafka 中的数据;而且 Spark Streaming 系统本身就不很稳定。所以我们需要实时地监控系统,包括监控 Flume、Kafka 集群、Spark Streaming 程序。我们所有的监控都是使用 Ganglia,一旦检测到异常,系统会自己先重试是否可以自己恢复,如果不行,就会给我们发送报警邮件,甚至是打电话。这里我简单地介绍一下如何监控 Kafka 和 Spark Streaming。
监控 Kafka
Kafka 内部为我们提供了许多 Metrics 属性(详见 kafka/metrics/KafkaMetricsGroup.scala 文件),这些 Metrics 属性可以通过 JMX 获取,Java 自带的 Jconsole 就可以,如下图:
图 2.Java 监视和管理控制台
但是这个只能静态的观察,无法提供报警等功能。值得高兴的是,我们可以编写 RMI 程序来分析这些 Metrics 属性,然后就可以将我们需要的数据发送到 Ganglia。这里简单的给出一个实例:
清单 6. 解析 Kafka Metrics 属性
import java.lang.management.MemoryUsage
import javax.management._
import javax.management.openmbean.CompositeData
import javax.management.remote.{JMXConnector, JMXConnectorFactory, JMXServiceURL}
import com.yammer.metrics.reporting.JmxReporter.GaugeMBean
object RmiMonitor {
def main(args: Array[String]) {
val jmxUrl = new JMXServiceURL("service:jmx:rmi:///jndi/rmi://l-kafkaCluster.com:1099/jmxrmi")
val connector = JMXConnectorFactory.connect(jmxUrl)
val con = connector.getMBeanServerConnection
val beanSet = con.queryMBeans(null, null)
val beans = beanSet.toArray(new Array[ObjectInstance](0))
.sortWith((o1, o2) => o1.getClassName.compare(o2.getClassName) < 0)
for (instance <- beans) {
val objectName = instance.getObjectName
println("%s %s".format(instance.getClassName, objectName))
}
}
}
上述程序可以列出 Kafka 提供的所有 Metrics 属性类名称,我们可以根据自己需求获取需要的数据。下面是我使用 Ganglia 监控 OrderSpark Topic 的分区 1 大小的监控图形:
图 3. 使用 Ganglia 监控 OrderSpark Topic 的分区 1 大小的监控图形

正常情况下,一直都会有数据发送到 Kafka 的,所有监控分区 1 的大小图形肯定是线性增加的。如果检测到直线,那肯定没有数据发送到 Kafka,这时候就该报警了。当然,我们还可以监控每个主题分区的偏移量等等。
监控 Spark Streaming 程序
上面提到使用 KafkaUtils.createDirectStream API 时我们可以在程序内部维护 Kafka 消费的偏移量,我们可以将这些偏移量发送到 Ganglia。在 Spark 内部提供了一个 Source 类,我们可以继承它来实现自定义的 Source,比如本文自定义 Kafka OffSet 的 Source,如清单 7 所示:
清单 7. 自定义 Spark 作业的 Source
class KafkaOffsetSource(val kafkaOffset: KafkaOffset) extends Source {
override val sourceName = "OrderSpark"
override val metricRegistry = new MetricRegistry()
metricRegistry.register(MetricRegistry.name("KafkaOffsets"), new Gauge[Long] {
override def getValue: Long = kafkaOffset.offset
})
}
并且在 Streaming 程序里面启动这个 Source。
清单 8. 在程序里面使用自定义的 Source
val source = new KafkaOffsetSource(kafkaOffset) SparkEnv.get.metricsSystem.registerSource(source)
最后在$SPARK_HOME/conf/metrics.properties 文件启用 Ganglia 监控。
清单 9. 将收集到的数据发送到 Ganglia 中
driver.sink.ganglia.class=org.apache.spark.metrics.sink.GangliaSink driver.sink.ganglia.host=l-ganglia.com driver.sink.ganglia.port=8649 driver.sink.ganglia.period=10 driver.sink.ganglia.ttl=1 driver.sink.ganglia.mode=multicast
然后运行我们的 Spark Streaming 程序,一段时间后我们就可以监控到 Kafka 消费的偏移量:
图 4. Kafka 消费的偏移量监控图形
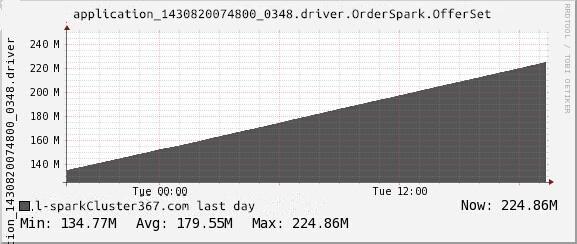
当然,Spark 内部也有很多的 Metrics 属性,比如 active Jobs、memory Used 等等都可以通过 Ganglia 里面监控到。这个相当方便。
回页首
经验总结及注意事项
1、我们在程序里面使用的是 KafkaUtils.createDirectStream API 从 Kafka 读取数据,其内部会启动 N 个线程来分别处理 Topic 中的 N 个分区的数据(也就是一对一),而且这些 core 是会一直被占用,所以在启动程序的时候需要配置足够的 core 来计算。比如 Topic 有 4 个分区,那么您必须在启动 Spark Streaming 的时候配置大于 4+1+m 个的 core,其中的 4 个 core 用于从 Topic 的每个分区读数据,另外一个 core 用于启动 Driver 进程(可以通过 spark.driver.cores 参数配置多个 core,默认是 1),剩下的 m 个 core 用于处理其他的计算。
2、创建 StreamingContext 的时候(对应上面清单 1 的 val ssc = new StreamingContext(sc, Seconds(2)) 片段),我们需要特别考虑如何设置第二个参数,它的含义是每隔多久触发一次批处理计算。这个值不能过小,否则可能频繁的 Akka 通信导致大量的作业堆积;这个值也不能过大,否则系统的实时性就不高了。一个经验性的建议就是我们可以先将这个值设置为 Seconds(10),再通过观察 WEB UI 页面,逐渐减小这个值,如果 WEB UI 中刚好没有出现作业堆积,那么这个值就是您程序的最佳值。
3、在计算的时候,为了减少内存或者带宽的使用,建议使用 KryoSerializer,并注册需要序列化的实体。KryoSerializer 的不足之处就是不支持所有的 Java 类。对于这种情况有两个建议:(1)、尽量使用能够序列化的类;(2)、如果实在是需要使用某个类 A,但是这个类无法使用 KryoSerializer,那么我们可以写个子类继承 A 和 Serializer,然后就可以解决这个问题。
4、在将结果写回到 Kafka 的时候,尽量不要每次都创建 Producer 类,一个可行的方法是在每个 Executor 端只创建一个 Producer 实体,然后缓存到内存,供每次写 Kafka 的时候共用,这样可以非常块地将数据写回 Kafka;而且只创建有限个 Producer 实体,对 Kafka 集群也是相当有益的(因为如果频繁的创建 Producer 实体,可能会导致 Kafka 集群挂掉)。
回页首
Spark Streaming 的不足
1、系统有时无法从 Checkpoint 中恢复,而且如果您修改了程序的逻辑也是无法从 Checkpoint 恢复。而且有些对象无法从 Checkpoint 恢复,比如广播变量、累加器等。
2、Spark Streaming 框架本身不是很稳定,无法保证 7x24 小时运行。