Tensorflow Serving部署tensorflow、keras模型详解
写在篇前
本篇介绍如何使用Tensorflow Serving组件导出训练好的Tensorflow模型,并使用标准tensorflow model server来部署深度学习模型预测服务。tensorflow model server主要负责管理新的导出模型并运行gRPC服务以方便终端用户调用。下面的代码都可以在我的实战项目github CaptchaIdentifier或者jefferyUstc MnistOnKeras中找到。
理论知识
Key Conception
Servables
Servable是Tensorflow Serving的核心抽象,是客户端用于执行计算的基础对象,其大小和粒度是灵活的。Tensorflow serving可以在单个实例的生命周期内处理一个或多个版本的Servable,这样既可以随时加载新的算法配置,权重或其他数据;也能够同时加载多个版本的Servable,支持逐步发布和实验。由此产生另外一个概念:Servable stream,即是指Servable的版本序列,按版本号递增排序。Tensorflow Serving 将 model 表示为一个或者多个Servables,一个Servable可能对应着模型的一部分,例如,a large lookup table 可以被许多 Tensorflow Serving 共享。另外,Servable不管理自己的生命周期,这一点后面会另作探讨。典型的Servable包括:
- Tensorflow SavedModelBundle (
tensorflow::Session) - lookup table for embedding or vocabulary lookups
Loaders
Loaders管理Servables的生命周期。Loader API 是一种支持独立于特定算法,数据或产品用例的通用基础架构。具体来说,Loaders标准化了用于加载和卸载Servable的API。
Sources
Sources 是可以寻找和提供 Servables 的模块,每个 Source 提供了0个或者多个Servable streams,对于每个Servable stream,Source 都会提供一个Loader实例。
Managers
管理 Servable 的整个的生命周期,包括:
- loading Servables
- serving Servables
- unloading Servables
Managers监听Sources并跟踪所有版本。Managers尝试满足、响应Sources的请求,但是如果所请求的资源不可用,可能会拒绝加载相应版本。Managers也可以推迟“卸载”。例如,Managers可能会等待到较新的版本完成加载之后再卸载(基于保证始终至少加载一个版本的策略)。
Core
Tensorflow Serving core 负责管理Servables的Lifecycle和metrics,将Servables和loaders看作黑箱(opaque objects)。
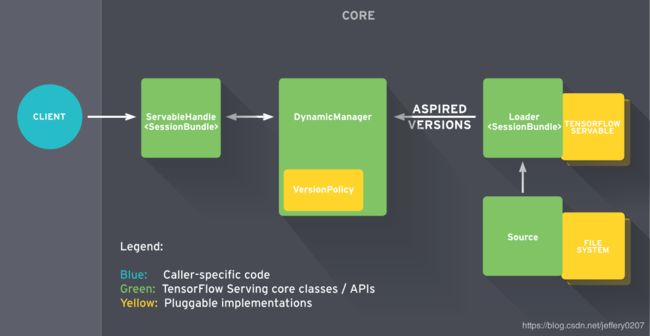
Fig1.Servable Lifecycle
简而言之():
- Sources create Loaders for Servable Versions.
- Loaders are sent as Aspired Versions to the Manager, which loads and serves them to client requests.
具体来说就是:
-
Source 为指定的服务(磁盘中检测模型权重的新版本)创建Loader,Loader里包含了服务所需要的元数据(模型);
-
Source 使用回调函数通知 Manager 的 Aspired Version(Servable version的集合);
-
Manager 根据配置的Version Policy决定下一步的操作(是否 unload 之前的Servable,或者 load 新的Servable);
-
如果 Manager 判定是操作安全的,就会给 Loader 要求的resource并让 Loader 加载新的版本;
-
客户端向 Manager 请求服务,可以指定服务版本或者只是请求最新的版本。Manager 返回服务端的处理结果;
Extensibility
Tensorflow Serving提供了几个可扩展的entry point,用户可以在其中添加自定义功能。
Version Policy
Version Policy(版本策略)可以指定单个Servable stream中的版本加载和卸载顺序。它包括Availability Preserving Policy(在卸载旧版本之前加载并准备好新版本)和Resource Preserving Policy(在加载新版本之前先卸载旧版本)。
Source
New Sources可以支持新的文件系统,云产品和算法后端,这主要和创建自定义Source有关。
Loaders
Loaers是添加算法、数据后端的扩展点。Tensorflow就是这样一种算法后端。例如,用户将实现一个新的Loader,以便对新的Servable机器学习模型实例的访问和卸载。
Batcher
将多个请求批处理为单个请求可以显着降低计算成本,尤其是在存在诸如GPU的硬件加速器的情况下。Tensorflow Serving包括一个请求批处理小部件,它允许客户端轻松地将请求中特定类型的计算进行批量处理。
代码实战
关于部署,我们采用docker tensorflow/serving, 如果你不熟悉docker, 可以参考我之前的博客Docker详解。docker serving具有以下几个属性需要注意:
- RESTful API的端口是8501
- gRPC的端口号是8500(可以根据需要开启其中一个端口或两个同时开启)
- 可选环境变量
MODEL_NAME,默认是model - 可选环境变量
MODEL_BASE_PATH,默认是/models
基本用法
# 基本用法
$ docker pull tensorflow/serving:latest # this is not supported for gpu
$ docker pull tensorflow/serving:latest-gpu # for gpu
$ docker run [--runtime=nvidia] -p 8500:8500 -p 8501:8501 \
--mount type=bind,source=/path/to/my_model/,target=/models/my_model \
--mount type=bind,source=/path/to/my/models.config,target=/models/models.config
--model_config_file=/models/models.config --enable_batching=true
[--per_process_gpu_memory_fraction=0.5] -e MODEL_NAME=my_model \
MODEL_BASE_PATH=/models -t tensorflow/serving &
tensorflow_model_server更多用法,请参考以下说明:
usage: tensorflow_model_server Flags: --port=8500 int32 Port to listen on for gRPC API --rest_api_port=0 int32 Port to listen on for HTTP/REST API. If set to zero HTTP/REST API will not be exported. This port must be different than the one specified in --port. --rest_api_num_threads=160 int32 Number of threads for HTTP/REST API processing. If not set, will be auto set based on number of CPUs. --rest_api_timeout_in_ms=30000 int32 Timeout for HTTP/REST API calls. --enable_batching=false bool enable batching --batching_parameters_file="" string If non-empty, read an ascii BatchingParameters protobuf from the supplied file name and use the contained values instead of the defaults. --model_config_file="" string If non-empty, read an ascii ModelServerConfig protobuf from the supplied file name, and serve the models in that file. This config file can be used to specify multiple models to serve and other advanced parameters including non-default version policy. (If used, --model_name, --model_base_path are ignored.) --model_name="default" string name of model (ignored if --model_config_file flag is set --model_base_path="" string path to export (ignored if --model_config_file flag is set, otherwise required) --file_system_poll_wait_seconds=1 int32 interval in seconds between each poll of the file system for new model version --flush_filesystem_caches=true bool If true (the default), filesystem caches will be flushed after the initial load of all servables, and after each subsequent individual servable reload (if the number of load threads is 1). This reduces memory consumption of the model server, at the potential cost of cache misses if model files are accessed after servables are loaded. --tensorflow_session_parallelism=0 int64 Number of threads to use for running a Tensorflow session. Auto-configured by default.Note that this option is ignored if --platform_config_file is non-empty. --ssl_config_file="" string If non-empty, read an ascii SSLConfig protobuf from the supplied file name and set up a secure gRPC channel --platform_config_file="" string If non-empty, read an ascii PlatformConfigMap protobuf from the supplied file name, and use that platform config instead of the Tensorflow platform. (If used, --enable_batching is ignored.) --per_process_gpu_memory_fraction=0.000000 float Fraction that each process occupies of the GPU memory space the value is between 0.0 and 1.0 (with 0.0 as the default) If 1.0, the server will allocate all the memory when the server starts, If 0.0, Tensorflow will automatically select a value. --saved_model_tags="serve" string Comma-separated set of tags corresponding to the meta graph def to load from SavedModel. --grpc_channel_arguments="" string A comma separated list of arguments to be passed to the grpc server. (e.g. grpc.max_connection_age_ms=2000) --enable_model_warmup=true bool Enables model warmup, which triggers lazy initializations (such as TF optimizations) at load time, to reduce first request latency. --version=false bool Display version
模型导出
tensorflow模型
import tensorflow as tf
from mymodel import captcha_model as model
import os
def export_model(checkpoint_path,
export_model_dir,
model_version
):
"""
:param checkpoint_path: type string, original model path(a dir)
:param export_model_dir: type string, save dir for exported model
:param model_version: type int best
:return:no return
"""
with tf.get_default_graph().as_default():
input_images = tf.placeholder(tf.float32, shape=[None, 100, 120, 1], name='input_images')
output_result, _ = model(input_images, keep_prob=1.0, trainable=False)
saver = tf.train.Saver()
with tf.Session() as sess:
ckpt_state = tf.train.get_checkpoint_state(checkpoint_path)
model_path = os.path.join(checkpoint_path,
os.path.basename(ckpt_state.model_checkpoint_path))
saver.restore(sess, model_path)
print('step1 => Model Restored successfully from {}'.format(model_path))
# set-up a builder
export_path_base = export_model_dir
export_path = os.path.join(
tf.compat.as_bytes(export_path_base),
tf.compat.as_bytes(str(model_version)))
builder = tf.saved_model.builder.SavedModelBuilder(export_path)
print('step2 => Export path(%s) ready to export trained model' % export_path)
tensor_info_input = tf.saved_model.utils.build_tensor_info(input_images)
tensor_info_output = tf.saved_model.utils.build_tensor_info(output_result)
# prediction_signature
prediction_signature = (
tf.saved_model.signature_def_utils.build_signature_def(
inputs={'images': tensor_info_input},
outputs={'result': tensor_info_output},
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME))
print('step3 => prediction_signature created successfully')
builder.add_meta_graph_and_variables(
# tags:SERVING,TRAINING,EVAL,GPU,TPU
sess, [tf.saved_model.tag_constants.SERVING],
signature_def_map={
'predict_images': prediction_signature,
})
print('step4 => builder successfully add meta graph and variables\nNext is to export model...')
builder.save(as_text=True)
print('Done exporting!')
if __name__ == '__main__':
export_model(
'./model_data',
'./my_model',
1
)
上面模型导出后将产生以下两个文件(夹):
-
saved_model.pbis the serialized tensorflow::SavedModel. It includes one or more graph definitions of the model, as well as metadata of the model such as signatures. -
variablesare files that hold the serialized variables of the graphs.
关于上面的代码,我主要做一点关于signatureDefs的说明,一共有三种signature,包括classification(用于分类问题)、predict(用于分类、回归等一切问题)、regression(用于回归问题)。据资料显示,Classify API比Predict API更高级,更具体。Classify接受tensorflow.serving.Input(包装tf.Examples列表)作为输入,并生成类和分数作为输出,用于分类问题;另一方面,Predict API以tensor作为输入和输出,可用于回归,分类和其他类型问题。
# 其他类型signature用法
# classification_signature
classification_signature = (
tf.saved_model.signature_def_utils.build_signature_def(
inputs={
tf.saved_model.signature_constants.CLASSIFY_INPUTS: '1'
},
outputs={
tf.saved_model.signature_constants.CLASSIFY_OUTPUT_CLASSES: '2',
tf.saved_model.signature_constants.CLASSIFY_OUTPUT_SCORES: '3'
},
method_name=tf.saved_model.signature_constants.CLASSIFY_METHOD_NAME
))
# regression_signature
regression_signature = (
tf.saved_model.signature_def_utils.build_signature_def(
inputs={
tf.saved_model.signature_constants.REGRESS_INPUTS: '1'
},
outputs={
tf.saved_model.signature_constants.REGRESS_OUTPUTS: '2',
},
method_name=tf.saved_model.signature_constants.REGRESS_METHOD_NAME
))
keras模型
def export_model(model,
export_model_dir,
model_version
):
"""
:param export_model_dir: type string, save dir for exported model
:param model_version: type int best
:return:no return
"""
with tf.get_default_graph().as_default():
# prediction_signature
tensor_info_input = tf.saved_model.utils.build_tensor_info(model.input)
tensor_info_input = tf.saved_model.utils.build_tensor_info(model.output)
prediction_signature = (
tf.saved_model.signature_def_utils.build_signature_def(
inputs={'images': tensor_info_input}, # Tensorflow.TensorInfo
outputs={'result': tensor_info_input},
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME))
print('step1 => prediction_signature created successfully')
# set-up a builder
export_path_base = export_model_dir
export_path = os.path.join(
tf.compat.as_bytes(export_path_base),
tf.compat.as_bytes(str(model_version)))
builder = tf.saved_model.builder.SavedModelBuilder(export_path)
builder.add_meta_graph_and_variables(
# tags:SERVING,TRAINING,EVAL,GPU,TPU
sess=K.get_session(),
tags=[tf.saved_model.tag_constants.SERVING],
signature_def_map={'prediction_signature': prediction_signature,},
)
print('step2 => Export path(%s) ready to export trained model' % export_path, '\n starting to export model...')
builder.save(as_text=True)
print('Done exporting!')
if __name__ == '__main__':
model = keras_model()
model.compile(loss=categorical_crossentropy,
optimizer=Adadelta(lr=0.1),
metrics=['accuracy'])
model.load_weights('./model_data/weights.hdf5')
model.summary()
export_model(
model,
'./export_model',
1
)
模型部署
Method1
docker run -d --name serving_base tensorflow/serving
docker cp models/<my model> serving_base:/models/<my model>
docker commit --change "ENV MODEL_NAME " serving_base <my container>
docker kill serving_base
method2
docker pull tensorflow/serving
# assume below model is your model
git clone https://github.com/tensorflow/serving
TESTDATA="$(pwd)/serving/tensorflow_serving/servables/tensorflow/testdata"
docker run -t --rm -p 8501:8501 \
-v "$TESTDATA/saved_model_half_plus_two_cpu:/models/half_plus_two" \
-e MODEL_NAME=half_plus_two \
tensorflow/serving &
# Query the model using the predict API
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
模型请求
利用grpc请求获取inference结果,代码如下:
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
import tensorflow as tf
import numpy as np
import grpc
def request_server(img_np,
server_url,
model_name,
signature_name,
input_name,
output_name
):
"""
below info about model
:param model_name:
:param signature_name:
:param output_name:
:param input_name:
:param img_np: processed img , numpy.ndarray type [h,w,c]
:param server_url: TensorFlow Serving url,str type,e.g.'0.0.0.0:8500'
:return: type numpy array
"""
characters = 'abcdefghijklmnopqrstuvwxyz'
# connect channel
channel = grpc.insecure_channel(server_url)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
# set up request
request = predict_pb2.PredictRequest()
request.model_spec.name = model_name # request.model_spec.version = "1"
request.model_spec.signature_name = signature_name
request.inputs[input_name].CopyFrom(
tf.contrib.util.make_tensor_proto(img_np, shape=list(img_np.shape)))
# get response
response = stub.Predict(request, 5.0)
# res_from_server_np = np.asarray(response.outputs[output_name].float_val)
res_from_server_np = tf.make_ndarray(response.outputs[output_name])
s = ''
for character in res_from_server_np[0]:
s += characters[character]
return s
扩展
这里再讨论一下如何配置Model Server, 可以通过--model_config_file=/models/models.config指定配置文件的路径,基本配置如下:
model_config_list {
config {
name: 'my_first_model'
base_path: '/tmp/my_first_model/'
}
config {
name: 'my_second_model'
base_path: '/tmp/my_second_model/'
}
}
每个ModelConfig指定一个要提供的模型,包括其名称和Model Server应该查找要提供的模型的路径。默认情况下,服务器将提供版本号最大的版本。可以通过更改model_version_policy字段来覆盖此默认值。
// 同时提供两个版本
model_version_policy {
specific {
versions: 42
versions: 43
}
}
有时,为模型版本添加一个间接级别会很有帮助, 可以为当前客户端应查询的任何版本分配别名,例如“stable”,而不是让所有客户都知道他们应该查询版本42。
model_version_policy {
specific {
versions: 42
versions: 43
}
}
version_labels {
key: 'stable'
value: 42
}
version_labels {
key: 'canary'
value: 43
}