Hyperledger Fabric的PBFT源码分析(一)
一、PBFT的原理概述
1.算法公式:
replicaCount int 变量定义在pbftCore结构体中
N (N在代码中对应replicaCount整型变量)是所有replicas的集合,每一个replica用一个整数来表示,如{ 0, 1, 2, 3,...N - 1 }
N-1 = 3f -----> f = N- 1/3
f 是最大可容忍的出错节点,也就是说准许错为1/3
2.图解PBFT执行过程
客户端发过来的请求其实是发给主replica,这里假设所得还没有选出主replica
这里大家估计也可以看出来图3和图4是一样的,其实这是一个互相确认的过程
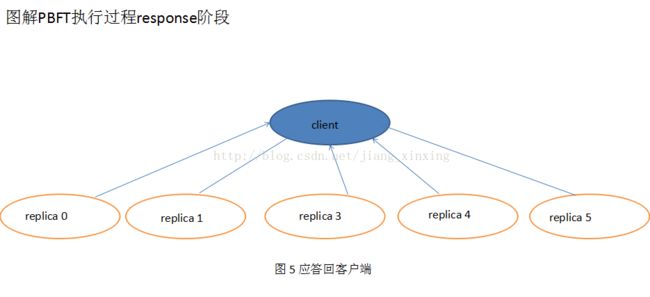
客户端
Client---->REQUEST--->replicas
1. REQUEST携带 operation, timestamp,给每一个REQUEST加上时间戳,这样后来的REQUEST会有高于前面的时间戳
2.replicas会接收请求,如果他们验证了条请求,就会将它写入到自己的log中。在共识算法保证下每个replica完成对该请求的执行后直接将回复返回给client:
3.REPLY携带当前的view序号和时间戳,还有replica节点的编号,会返回执行结果
4.共识算法中有一个weak certificate,在这里,client也会等待weak certificate:即有f+1个replicas回复,并且它们的回复拥有相同的 t 和 r,由于至多有f个faulty replicas,所以确保了回复是合法的。我们叫这个weak certificate为 reply certificate。
5.处于active状态每一个replica会与每一个的client共享一份秘钥。
pre-prepare阶段
1.主节点收到来自Client的一条请求并分配了一个编号给这个请求,
2.主节点会广播一条PRE-PREPARE信息给备份节点,
3.这个PRE-PREPARE信息包含该请求的编号、所在的view和自身的一个digest。
4.直到该信息送达到每一个备份节点,接下来就看收到信息的备份节点们同不同意
5.主节点分配给该请求的这个编号n,即是否accept这条PRE-PREPARE信息,
6.如果一个备份节点accept了这条PRE-PREPARE,它就会进入下面的prepare阶段。
prepare阶段
1.备份节点进入prepared阶段后,广播一条PREPARE信息给主节点和其它的备份节点,直到PREPARE信息都抵达那三个节点。同时,该备份节点也会分别收到来自其它备份节点的PREPARE信息。
2.该备份节点将综合这些PREPARE信息做出自己对编号n的最终裁决。当这个备份节点开始综合比较来自其它两个备份节点的PREPARE信息和自身的PREPARE信息时,如果该备份节点发现其它两个节点都同意主节点分配的编号,又看了一下自己,自己也同意主节点的分配,a quorum certificate with the PRE-PREPARE and 2 f matching PREPARE messages for sequence number n, view v, and request m,如果一个replica达到了英文所说的条件,比如就是上面的斜体字描述的一种情况,那么我们就说该请求在这个replica上的状态是prepared,该replica就拥有了一个证书叫prepared certificate。那我们是不是就可以说至此排序工作已经完成,全网节点都达成了一个一致的请求序列呢,每一个replica开始照着这个序列执行吧。这是有漏洞的,设想一下,在t1时刻只有replica 1把请求m(编号为n)带到了prepared状态,其他两个备份节点replica 2, replica 3还没有来得及收集完来自其它节点的PREPARE信息进行判断,那么这时发生了view change进入到了一个新的view中,replica 1还认为给m分配的编号n已经得到了一个quorum同意,可以继续納入序列中,或者可以执行了,但对于replica 2来说,它来到了新的view中,它失去了对请求m的判断,甚至在上个view中它还有收集全其他节点发出的PREPARE信息,所以对于replica 2来说,给请求m分配的编号n将不作数,同理replica 3也是。那么replica 1一个人认为作数不足以让全网都认同,所以再新的view中,请求m的编号n将作废,需要重新发起提案。所以就有了下面的commit阶段。
需要注意的是,该备份节点会将自己收到的PRE-PREPARE和发送的PREPARE信息记录到自己的log中。
该备份节点发出PREPARE信息表示该节点同意主节点在view v中将编号n分配给请求m,不发即表示不同意。
如果一个replica对请求m发出了PRE-PREPARE和PREPARE信息,那么我们就说该请求m在这个replica节点上处于pre-prepared状态。
Commit阶段
紧接着prepare阶段,当一个replica节点发现有一个quorum同意编号分配时,它就会广播一条COMMIT信息给其它所有节点告诉他们它有一个prepared certificate了。与此同时它也会陆续收到来自其它节点的COMMIT信息,如果它收到了2f+1条COMMIT(包括自身的一条,这些来自不同节点的COMMIT携带相同的编号n和view v),我们就说该节点拥有了一个叫committed certificate的证书,请求在这个节点上达到了committed状态。此时只通过这一个节点,我们就能断定该请求已经在一个quorum中到达了prepared状态,寄一个quorum的节点们都同意了编号n的分配。当请求m到达commited状态后,该请求就会被该节点执行。
由此观之核心代码执行的过程如下

二、共识算法代码解析
1.代码目录结构

// GetEngine returns initialized peer.Engine
//============================================================================
//它初始化一个consenter和一个helper,并互相把一个句柄赋值给了对方。
//这样做的目的,就是为了可以让外部调用内部,内部可以调用外部
//============================================================================
func GetEngine(coord peer.MessageHandlerCoordinator) (peer.Engine, error) {
var err error
engineOnce.Do(func() {
engine = new(EngineImpl)
engine.helper = NewHelper(coord)
engine.consenter = controller.NewConsenter(engine.helper)
engine.helper.setConsenter(engine.consenter)
engine.peerEndpoint, err = coord.GetPeerEndpoint()
engine.consensusFan = util.NewMessageFan()
go func() {
logger.Debug("Starting up message thread for consenter")
// The channel never closes, so this should never break
for msg := range engine.consensusFan.GetOutChannel() {
engine.consenter.RecvMsg(msg.Msg, msg.Sender)
}
}()
})
return engine, err
}
//==============================================================================
// NewConsenter constructs a Consenter object if not already present
//==============================================================================
//==============================================================================
//调用controller获取一个plugin,当选择是pbft算法时,它会调用pbft.go 里的
//GetPlugin(c consensus.Stack)方法,在pbft.go里面把所有的外部参数读进算法内部
//==============================================================================
func NewConsenter(stack consensus.Stack) consensus.Consenter {
plugin := strings.ToLower(viper.GetString("peer.validator.consensus.plugin"))
if plugin == "pbft" {
logger.Infof("Creating consensus plugin %s", plugin)
return pbft.GetPlugin(stack)
}
logger.Info("Creating default consensus plugin (noops)")
return noops.GetNoops(stack)
}
controller目录下是共识插件选择模块的函数
---->HyperLedger提供了两种算法PBFT和noops
---->默认单节点情况下使用noops即相当于没有共识算法
func NewConsenter(stack consensus.Stack) consensus.Consenter {
plugin := strings.ToLower(viper.GetString("peer.validator.consensus.plugin"))
if plugin == "pbft" {
logger.Infof("Creating consensus plugin %s", plugin)
return pbft.GetPlugin(stack)
}
logger.Info("Creating default consensus plugin (noops)")
return noops.GetNoops(stack)
}函数中可以看出目前Hyperledger Fabric只支持PBFT和NOOPS
executor和helper是两个相互依赖的模块
---->主要提供了共识算法和外部衔接的一块代码。主要负责事件处理的转接
helper
--->这里面主要包含了对外部接口的一个调用,比如执行处理transaction,stateupdate,持久化一些对象等
noops
--->noops相当于没有共识算法
pbft
---> HyperLedger的默认共识算法
util
--->交互需要的工具包,最主要的一个实现的功能就是它的消息机制。
func GetPlugin(c consensus.Stack) consensus.Consenter {
if pluginInstance == nil {
pluginInstance = New(c)
}
return pluginInstance
}
func New(stack consensus.Stack) consensus.Consenter {
handle, _, _ := stack.GetNetworkHandles()
id, _ := getValidatorID(handle)
switch strings.ToLower(config.GetString("general.mode")) {
case "batch":
return newObcBatch(id, config, stack)
default:
panic(fmt.Errorf("Invalid PBFT mode: %s", config.GetString("general.mode")))
}
}//==============================================================================//在newobcbatch时,会初始化得到一个pbftcore的一个实例,这个是算法的核心模块。//并此时会启动一个batchTimer(这个batchTimer是一个计时器,//当batchTimer timeout后会触发一个sendbatch操作,这个只有primary节点才会去做)。//当然此时会创建一个事件处理机制,这个事件处理机制是各个模块沟通的一个bridge。//==============================================================================
func newObcBatch(id uint64, config *viper.Viper, stack consensus.Stack) *obcBatch {
var err error
op := &obcBatch{
obcGeneric: obcGeneric{stack: stack},
}
op.persistForward.persistor = stack
logger.Debugf("Replica %d obtaining startup information", id)
op.manager = events.NewManagerImpl() // TODO, this is hacky, eventually rip it out
op.manager.SetReceiver(op)
etf := events.NewTimerFactoryImpl(op.manager)
op.pbft = newPbftCore(id, config, op, etf)
op.manager.Start()
blockchainInfoBlob := stack.GetBlockchainInfoBlob()
op.externalEventReceiver.manager = op.manager
op.broadcaster = newBroadcaster(id, op.pbft.N, op.pbft.f, op.pbft.broadcastTimeout, stack)
op.manager.Queue() <- workEvent(func() {
op.pbft.stateTransfer(&stateUpdateTarget{
checkpointMessage: checkpointMessage{
seqNo: op.pbft.lastExec,
id: blockchainInfoBlob,
},
})
})
op.batchSize = config.GetInt("general.batchsize")
op.batchStore = nil
op.batchTimeout, err = time.ParseDuration(config.GetString("general.timeout.batch"))
if err != nil {
panic(fmt.Errorf("Cannot parse batch timeout: %s", err))
}
logger.Infof("PBFT Batch size = %d", op.batchSize)
logger.Infof("PBFT Batch timeout = %v", op.batchTimeout)
if op.batchTimeout >= op.pbft.requestTimeout {
op.pbft.requestTimeout = 3 * op.batchTimeout / 2
logger.Warningf("Configured request timeout must be greater than batch timeout, setting to %v", op.pbft.requestTimeout)
}
if op.pbft.requestTimeout >= op.pbft.nullRequestTimeout && op.pbft.nullRequestTimeout != 0 {
op.pbft.nullRequestTimeout = 3 * op.pbft.requestTimeout / 2
logger.Warningf("Configured null request timeout must be greater than request timeout, setting to %v", op.pbft.nullRequestTimeout)
}
op.incomingChan = make(chan *batchMessage)
op.batchTimer = etf.CreateTimer()
op.reqStore = newRequestStore()
op.deduplicator = newDeduplicator()
op.idleChan = make(chan struct{})
close(op.idleChan) // TODO remove eventually
return op
}
func newPbftCore(id uint64, config *viper.Viper, consumer innerStack, etf events.TimerFactory) *pbftCore {
var err error
instance := &pbftCore{}
instance.id = id
instance.consumer = consumer
//==============================================================================
// 4. 在初始化pbftcore时,在把所用配置读进的同时,创建了三个timer
//==============================================================================
//==========================================================================
//newViewTimer对应于viewChangeTimerEvent{},当这个timer在一定时间没有close时,
//就会触发一个viewchange事件
//==========================================================================
instance.newViewTimer = etf.CreateTimer()
//==========================================================================
//vcResendTimer对应viewChangeResendTimerEvent,发出viewchange过时时会
//触发一个将viewchange从新发送
//==========================================================================
instance.vcResendTimer = etf.CreateTimer()
//==========================================================================
//nullRequestTimer对应nullRequestEvent,如果主节点长期没有发送preprepare消息,
//也就是分配了seq的reqBatch。它timeout就认为主节点挂掉了然后发送viewchange消息
//==========================================================================
instance.nullRequestTimer = etf.CreateTimer()
instance.N = config.GetInt("general.N") //网络中验证器的最大数量赋值
//==================================================================================//
/*N是所有replicas的集合,每一个replica用一个整数来表示,依次为
{ 0, …, |N - 1 }
简单起见,我们定义
|N = 3f + 1
f 是最大可容忍的faulty节点
另外我们将一个view中的primary节点定义为replica p,
p = v mod |N
v 是view的编号,从0开始一直连续下去,这样可以理解为从replica 0 到 replica |N-1 依次当primary节点,当每一次view change发生时。
*/
//==================================================================================//
instance.f = config.GetInt("general.f") //默认的最大容错数量赋值
if instance.f*3+1 > instance.N { //默认的最大容错数量大于网络中验证器的最大数量
panic(fmt.Sprintf("need at least %d enough replicas to tolerate %d byzantine faults, but only %d replicas configured", instance.f*3+1, instance.f, instance.N))
}
instance.K = uint64(config.GetInt("general.K")) //检查点时间段赋值
//计算日志的大小值赋值,日志倍增器
instance.logMultiplier = uint64(config.GetInt("general.logmultiplier"))
if instance.logMultiplier < 2 {
panic("Log multiplier must be greater than or equal to 2")
}
//日志大小计算
instance.L = instance.logMultiplier * instance.K // 日志大小
//自动视图改变的时间段
instance.viewChangePeriod = uint64(config.GetInt("general.viewchangeperiod"))
//这个节点是否故意充当拜占庭;testnet用于调试
instance.byzantine = config.GetBool("general.byzantine")
//请求过程超时
instance.requestTimeout, err = time.ParseDuration(config.GetString("general.timeout.request"))
if err != nil {
panic(fmt.Errorf("Cannot parse request timeout: %s", err))
}
//重发视图改变之前超时
instance.vcResendTimeout, err = time.ParseDuration(config.GetString("general.timeout.resendviewchange"))
if err != nil {
panic(fmt.Errorf("Cannot parse request timeout: %s", err))
}
//新的视图超时
instance.newViewTimeout, err = time.ParseDuration(config.GetString("general.timeout.viewchange"))
if err != nil {
panic(fmt.Errorf("Cannot parse new view timeout: %s", err))
}
//超时持续
instance.nullRequestTimeout, err = time.ParseDuration(config.GetString("general.timeout.nullrequest"))
if err != nil {
instance.nullRequestTimeout = 0
}
//广播过程超时
instance.broadcastTimeout, err = time.ParseDuration(config.GetString("general.timeout.broadcast"))
if err != nil {
panic(fmt.Errorf("Cannot parse new broadcast timeout: %s", err))
}
//查看view发生
instance.activeView = true
//replicas的数量; PBFT `|R|`
instance.replicaCount = instance.N
logger.Infof("PBFT type = %T", instance.consumer)
logger.Infof("PBFT Max number of validating peers (N) = %v", instance.N)
logger.Infof("PBFT Max number of failing peers (f) = %v", instance.f)
logger.Infof("PBFT byzantine flag = %v", instance.byzantine)
logger.Infof("PBFT request timeout = %v", instance.requestTimeout)
logger.Infof("PBFT view change timeout = %v", instance.newViewTimeout)
logger.Infof("PBFT Checkpoint period (K) = %v", instance.K)
logger.Infof("PBFT broadcast timeout = %v", instance.broadcastTimeout)
logger.Infof("PBFT Log multiplier = %v", instance.logMultiplier)
logger.Infof("PBFT log size (L) = %v", instance.L)
//超时持续
if instance.nullRequestTimeout > 0 {
logger.Infof("PBFT null requests timeout = %v", instance.nullRequestTimeout)
} else {
logger.Infof("PBFT null requests disabled")
}
//在自动视图改变的时间段
if instance.viewChangePeriod > 0 {
logger.Infof("PBFT view change period = %v", instance.viewChangePeriod)
} else {
logger.Infof("PBFT automatic view change disabled")
}
// init the logs
//跟踪法定证书请求
instance.certStore = make(map[msgID]*msgCert)
//跟踪请求批次
instance.reqBatchStore = make(map[string]*RequestBatch)
//跟踪检查点设置
instance.checkpointStore = make(map[Checkpoint]bool)
//检查点状态; 映射lastExec到全局hash
instance.chkpts = make(map[uint64]string)
//跟踪视view change消息
instance.viewChangeStore = make(map[vcidx]*ViewChange)
instance.pset = make(map[uint64]*ViewChange_PQ)
instance.qset = make(map[qidx]*ViewChange_PQ)
//跟踪我们接收后者发送的最后一个新视图
instance.newViewStore = make(map[uint64]*NewView)
// initialize state transfer
//观察每一个replica最高薄弱点序列数
instance.hChkpts = make(map[uint64]uint64)
//检查点状态; 映射lastExec到全局hash
instance.chkpts[0] = "XXX GENESIS"
// 在我们使用视图改变期间最后超时
instance.lastNewViewTimeout = instance.newViewTimeout
//跟踪我们是否正在等待请求批处理执行
instance.outstandingReqBatches = make(map[string]*RequestBatch)
//对于所有已经分配我们可能错过的在视图改变期间的非检查点的请求批次
instance.missingReqBatches = make(map[string]bool)
//将变量的值恢复到初始状态
instance.restoreState()
// 执行视图改变的下一个序号
instance.viewChangeSeqNo = ^uint64(0) // infinity
//更新视图改变序列号
instance.updateViewChangeSeqNo()
return instance
}
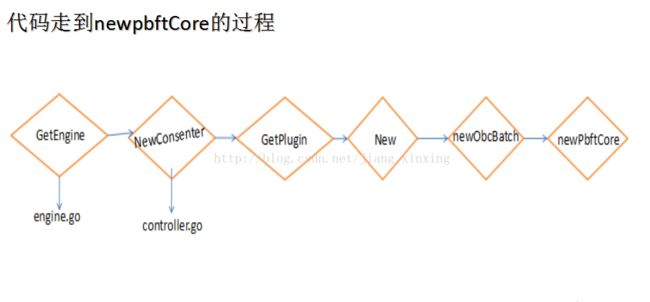
代码走到newPbftCore的过程,等待下周更新...........