Hadoop2.x深入详解
HDFS分布式文件系统详解
NameNode:是一个中心服务器,单一节点,负责管理文件系统的命名空间以及客户端对文件的访问;NameNode负责文件元数据的操作,DataNode负责处理文件内容的读写请求,跟文件内容相关的数据流不经过NameNode,只会询问他与哪一个DataNode联系,否则NameNode会成为系统的瓶颈;副本存放在哪些DataNode上有NameNode来控制,根据全局情况做出块放置决定,读取文件NameNode尽量让用户先读取最近的副本,降低块消耗和读取时延;NameNode全权管理数据块的复制,它周期性的从集群的每个Datanode接手心跳信号和块状态报告,接收到心跳信号意味着该DataNode节点正常工作,块状态报告包含了一个DataNode上所有数据块的列表。
一个数据块在DataNode以文件存储在磁盘上,包括两个文件,一个数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。DataNode启动后向NameNode注册,通过后,周期性(1个小时)的向NameNode上报所有的块信息。心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或者删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。集群运行中可以安全加入和退出一些机器。
在core-site.xml配置文件中配置的数据存储目录/data/tmp/dfs下,有如下文件夹:data(datanode存放数据)、name(namenode存放数据)、namesecondary(secondarynamenode存放数据)。
文件切成块默认大小128M,以块为单位,每个块有多个副本存储在不同的机器上,副本数可在文件生成时指定默认是3。(配置或者命令都可以)
可以创建、删除、移动或者重命名文件,当文件创建、写入和关闭之后不能修改文件内容。
1、数据损坏处理
当DataNode读取block的时候,它会计算checksum,如果计算后的checksum与block创建时值不一样,说明该block已经损坏。Client读取其他DataNode上的block。NameNode标记该块已经损坏,然后复制block达到预期设置的文件备份数。并删除损坏的块。DataNode在其文件创建后三周验证其checksum。
2、HDFS交互式shell使用
(1)文件操作
$ bin/hdfs dfs ……
-chgrp
-chmod
-chown
-ls
-mkdir
-put/get
-rm
-rmdir
-test
-text(2)集群管理
-report 集群状态信息 50070端口也可以看
-safemode 安全模式
-refresh 新增节点后刷新public class Test {
static final String PATH = "hdfs://hadoop-senior.ibeifeng.com:8020/";
static final String DIR = "hdfs://hadoop-senior.ibeifeng.com:8020/d1";
static final String FILE = "/d1/hello";
public static void main(String[] args) throws Exception {
//获取fileSystem
FileSystem fileSystem = getFileSystem();
// 创建文件夹 hadoop dfs -mkdir /d1
mkdir(fileSystem);
// 删除文件夹 hadoop dfs -rm /d1
remove(fileSystem);
// 上传文件 hadoop dfs -put src des
putData(fileSystem);
// 下载文件 hadoop dfs -get src des
getData(fileSystem);
// 浏览文件夹hadoop dfs -ls /
list(fileSystem);
}
private static void list(FileSystem fileSystem) throws IOException {
FileStatus[] listStatus = fileSystem.listStatus(new Path("/"));
for (FileStatus fileStatus : listStatus) {
String idDir = fileStatus.isDir() ? "文件夹" : "文件";
String permission = fileStatus.getPermission().toString();
short replication = fileStatus.getReplication();
long len = fileStatus.getLen();
String path = fileStatus.getPath().toString();
System.out.println(idDir + "\t" + permission + "\t" + replication
+ "\t" + len + "\t" + path);
}
}
private static void getData(FileSystem fileSystem) throws IOException {
FSDataInputStream in = fileSystem.open(new Path(FILE));
IOUtils.copyBytes(in, System.out, 1024, true);
}
private static void putData(FileSystem fileSystem) throws IOException {
FSDataOutputStream out = fileSystem.create(new Path(FILE));
FileInputStream in = new FileInputStream("C:/readme.txt");
IOUtils.copyBytes(in, out, 1024, true);
}
private static void remove(FileSystem fileSystem) throws IOException {
fileSystem.delete(new Path(DIR), true);
}
private static void mkdir(FileSystem fileSystem) throws IOException {
fileSystem.mkdirs(new Path(DIR));
}
private static FileSystem getFileSystem() throws IOException,
URISyntaxException {
FileSystem fileSystem = FileSystem.get(new URI(PATH),
new Configuration());
return fileSystem;
}
}NameNode的数据存放在两个地方
内存当中
本地磁盘
fsimage 格式化文件系统就是为了生成这个文件
edits
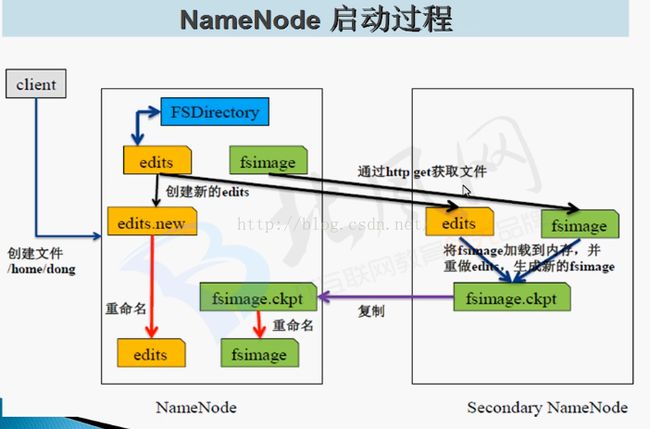
第一次启动,格式化HDFS后,目的生成fsimage
Start NameNode执行这个命令后,会read fsimage 文件
Start DataNode向NameNode注册,block report(块汇报)
接下来执行命令
create dir /user/beifeng/tmp -> write [edits]
put files /user/beifeg/tmp(*-site.xml) -> write [edits]
delete file /user/beifeng/tmp/core-site.xml -> write [edits]
第二次启动
Start NameNode执行这个命令后,会read fsimage;read edits;
生成一个新的fsimage (合并fsimage和edits)
生成新的edits 这个时候edits为null
Start DataNode向NameNode注册;block report(块汇报)
接下来执行命令
create dir /user/beifeng/tmp -> write [edits]
put files /user/beifeg/tmp(*-site.xml) -> write [edits]
delete file /user/beifeng/tmp/core-site.xml -> write [edits] NameNode中的编辑日志文件太大的话如何处理。定期(默认一个小时一次)合并fsimage和edits生成新的fsimage 给NameNode
6、安全模式safemode
等待DataNodes向NameNode发送block report,(datanodes blocks)/(total blocks) = 99.99%s时,安全模式结束。在安全模式下可以查看文件系统的文件,不能改变文件系统的命令空间,如创建、上传、删除文件等操作。
$ bin/hdfs dfsadmin –safemode
enter
leave
get yarn架构详解
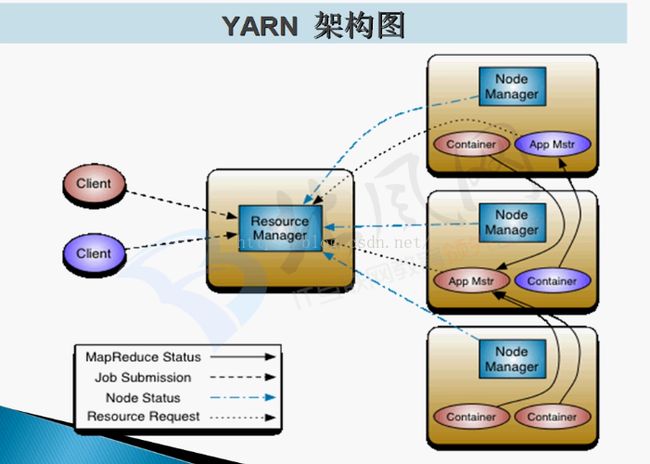
Yarn的架构
在Yarn中,JobTracker被分为两部分:ResouceManager(RM)和ApplicationMaster(AM)
MR v1主要由三部分组成:编程模型(API)、数据处理引擎(MapTask和ReduceTask)和运行环境(JobTracker和TaskTracker);
Yarn继承了MR v1的编程模型和处理引擎,改变的只是运行环境,所以对编程没有什么影响。
RM负责资源调度,AM负责任务调度:RM负责整个集群的资源管理与调度;NodeManager(NM)负责单个节点的资源管理与调度;NM定时的通过心跳的形式与RM进行通信,报告节点的健康状态与内存使用情况;AM通过与RM交互获取资源,然后通过与NM交互,启动计算任务。
在Yarn的框架管理中,无论是AM从RM申请资源,还是NM管理自己所在节点的资源,都是通过Container进行的。Container是Yarn的资源抽象,此处的资源包含内存和CPU等。
- ResourceManager:全局资源管理器,整个集群只有一个,负责集群资源的统一管理和调度分配。
功能:处理客户端请求;启动/监控ApplicationMaster;监控NodeManager;资源分配和调度。 - NodeManager:整个集群有多个,负责单节点资源管理和使用。
功能:单个节点上的资源管理和任务管理;处理来自ResourceManager的命令;处理来自ApplicationMaster的命令。
NodeManger管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。定时的想RM汇报本节点上资源使用情况和各个Container的运行状态。 - ApplicationMaster:管理一个在Yarn内运行的应用程序的每个实例。
功能:数据切分;为应用程序申请资源,并进一步分配给内部任务;任务监控和容错。负责协调来自ResourceManager的资源,开通过NodeManager监视容器的执行和资源使用(CPU、内存等资源的分配) - Container:Yarn中的资源抽象,封装某个节点上多维度资源,如内存、CPU、磁盘网络等,当AM向RM申请资源时,RM向AM返回的资源便是用Container表示的。Yarn会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
功能:对任务运行环境的抽象;描述一系列信息;任务运行资源(节点、内存、CPU);任务启动命令;任务运行环境
Yarn资源管理和调度
资源调度和资源隔离是Yarn作为一个资源管理系统,最重要和最基础的两个功能,资源调度由ResourceManager完成,而资源隔离由各个NodeManager实现。
ResourceManager将某个NodeManager上资源分配给任务(这就是所谓的“资源调度”)后,NodeManager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证,这就是所谓的资源隔离。
当谈及到资源时,我们通常指内存、CPU和IO三种资源。Hadoop YARN同时支持内存和CPU两种资源的调度。内存资源的多少会决定任务的生死,如果内存不够,任务可能会运行失败,相比之下,CPU资源则不同,它只会决定任务运行的快慢,不会对生死产生影响。
Yarn运行用户配置每个节点上可用的物理内存资源,注意:这里是“可用的”,因为一个节点上的内存会被若干个服务共享,比如一部分给yarn,一部分给hdfs,一部分给hbase等等。
Yarn的执行流程:
- 用户向Yarn中提交应用程序,其中包括AM程序,启动AM的命令,用户程序等。
- RM为该程序分配第一个Container,并与对应的NM通讯,要求它在这个Container中启动应用程序AM。
- AM首先向RM注册,这样用户可以直接通过RM查看应用程序的运行状态,然后将为各个任务申请资源,并监控它的运行状态,直到运行结束。重复4-7步骤。
- AM采用轮询的方式通过RPC协议向RM申请和领取资源
- 一旦AM申请到资源后,便与对应的NM通讯,要求它启动任务
- NM为任务设置好运行环境(包括环境变量,JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
- 应用程序运行完成后,AM向RM注销并关闭自己。
配置CPU和内存的大小:
yarn.nodemanager.resource.memory-mb
4096 4G内存 默认8G
yarn.nodemanager.resource.cpu-vcores
4 4核 默认8核
MapReduce编程模型
一种分布式计算模型,解决海量数据的计算问题。MapReduce将整个并行计算过程抽象到两个函数:
1、Map:对一些独立元素组成的列表的每一个元素进行指定的操作,可以高度并行。
1.1 读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。
1.2 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
1.3 对输出的key、value进行分区。
1.4 对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中。
1.5 (可选)分组后的数据进行归约。2、Reduce:对一个列表的元素进行合并。
2.1 对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
2.2 对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
2.3 把reduce的输出保存到文件中。一个简单的MapReduce程序只需要指定map(),reduce()、input、output,剩下的事由框架完成。
MapReduce编程实例(wordcount)
public class WordCountApp extends Configured implements Tool{
static final String INPUT_PATH = "hdfs://hadoop-senior.ibeifeng.com:8020/hello";
static final String OUT_PATH = "hdfs://hadoop-senior.ibeifeng.com:8020/out";
public static void main(String[] args) throws Exception {
ToolRunner.run(new WordCountApp(), args);
}
public static void run(String[] args) throws Exception {
INPUT_PATH = args[0];
OUT_PATH = args[1];
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
final Path outPath = new Path(OUT_PATH);
if (fileSystem.exists(outPath)) {
fileSystem.delete(outPath, true);
}
final Job job = new Job(conf, WordCountApp.class.getSimpleName());
//打成jar包运行
job.setJarByClass(WordCountApp.class);
// 1.1指定读取的文件位于哪里
FileInputFormat.setInputPaths(job, INPUT_PATH);
// 指定如何对输入文件进行格式化,把输入文件每一行解析成键值对
job.setInputFormatClass(TextInputFormat.class);
// 1.2 指定自定义的map类
job.setMapperClass(MyMapper.class);
// map输出的类型。如果的类型与类型一致,则可以省略
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 1.3 分区
//job.setPartitionerClass(HashPartitioner.class);
// 设置reduce任务数,有一个reduce任务运行
job.setNumReduceTasks(1);
// 1.4 TODO 排序、分组
// 1.5 TODO 规约
// 2.2 指定自定义reduce类
job.setReducerClass(MyReducer.class);
// 指定reduce的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 2.3 指定写出到哪里
FileOutputFormat.setOutputPath(job, outPath);
// 指定输出文件的格式化类
job.setOutputFormatClass(TextOutputFormat.class);
//把job提交运行 true表示打印结果信息
job.waitForCompletion(true);
}
/**
* KEYIN 即k1:表示行的偏移量
* VALUEIN 即v1:表示行文本内容
* KEYOUT 即k2:表示行中出现的单词
* VALUEOUT 即v:2表示行中出现的单词的次数,固定值1
*/
static class MyMapper extends
Mapper {
private Text word = new Text();
private LongWritable one = new LongWritable(1);
protected void map(LongWritable k1, Text v1, Context ctx)
throws java.io.IOException, InterruptedException {
StringTokenizer st = new StringTokenizer(v1, "\t");
while(st.hasMoreTokens()){
word.set(st.nextToken());
ctx.write(word, one);
}
};
}
/**
* KEYIN 即k2:表示行中出现的单词
* VALUEIN 即v2:表示行中出现的单词的次数
* KEYOUT 即k3:表示文本中出现的不同单词
* VALUEOUT 即v3:表示文本中出现的不同单词的总次数
*/
static class MyReducer extends
Reducer {
protected void reduce(Text k2, java.lang.Iterable v2s,Context ctx)
throws java.io.IOException, InterruptedException {
long times = 0L;
for (LongWritable count : v2s) {
times += count.get();
}
ctx.write(k2, new LongWritable(times));
};
}
} 自定义的类型必须实现Writable,如果需要排序还必须实现 Comparable
public class KpiApp extends Configured implements Tool{
static final String INPUT_PATH = "hdfs://hadoop-senior.ibeifeng.com:8020/wlan";
static final String OUT_PATH = "hdfs://hadoop-senior.ibeifeng.com:8020/out";
public static void main(String[] args) throws Exception {
ToolRunner.run(new KpiApp(), args);
}
public static void run(String[] args) throws Exception {
INPUT_PATH = args[0];
OUT_PATH = args[1];
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
final Path outPath = new Path(OUT_PATH);
if (fileSystem.exists(outPath)) {
fileSystem.delete(outPath, true);
}
final Job job = new Job(conf, KpiApp.class.getSimpleName());
//打成jar包运行
job.setJarByClass(KpiApp.class);
// 1.1指定读取的文件位于哪里
FileInputFormat.setInputPaths(job, INPUT_PATH);
// 指定如何对输入文件进行格式化,把输入文件每一行解析成键值对
job.setInputFormatClass(TextInputFormat.class);
// 1.2 指定自定义的map类
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(KpiWritable.class);
// 1.3 分区
//job.setPartitionerClass(HashPartitioner.class);
// 设置reduce任务数,有一个reduce任务运行
//job.setNumReduceTasks(1);
// 1.4 TODO 排序、分组
// 1.5 TODO 合并、规约
// 2.2 指定自定义reduce类
job.setReducerClass(MyReducer.class);
// 指定reduce的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(KpiWritable.class);
// 2.3 指定写出到哪里
FileOutputFormat.setOutputPath(job, outPath);
// 指定输出文件的格式化类
job.setOutputFormatClass(TextOutputFormat.class);
//把job提交运行
job.waitForCompletion(true);
}
static class MyMapper extends Mapper {
@Override
protected void map(LongWritable key,Text value,Context context)
throws IOException, InterruptedException {
String[] splited = value.toString().split("\t");
String msisdn = splited[1];
Text k2 = new Text(msisdn);
KpiWritable v2 = new KpiWritable(splited[6], splited[7],splited[8], splited[9]);
context.write(k2, v2);
}
}
static class MyReducer extends Reducer {
@Override
protected void reduce(Text k2,Iterable v2s,Context context)
throws IOException, InterruptedException {
long upPackNum = 0L;
long downPackNum = 0L;
long upPayLoad = 0L;
long downPayLoad = 0L;
for (KpiWritable kpiWritable : v2s) {
upPackNum += kpiWritable.upPackNum;
downPackNum += kpiWritable.downPackNum;
upPayLoad += kpiWritable.upPayLoad;
downPayLoad += kpiWritable.downPayLoad;
}
KpiWritable v3 = new KpiWritable(upPackNum + "", downPackNum + "",upPayLoad + "", downPayLoad + "");
context.write(k2, v3);
}
}
}
class KpiWritable implements Writable {
long upPackNum;
long downPackNum;
long upPayLoad;
long downPayLoad;
public KpiWritable() {
}
public KpiWritable(String upPackNum, String downPackNum, String upPayLoad,String downPayLoad) {
this.upPackNum = Long.parseLong(upPackNum);
this.downPackNum = Long.parseLong(downPackNum);
this.upPayLoad = Long.parseLong(upPayLoad);
this.downPayLoad = Long.parseLong(downPayLoad);
}
@Override
public void readFields(DataInput in) throws IOException {
this.upPackNum = in.readLong();
this.downPackNum = in.readLong();
this.upPayLoad = in.readLong();
this.downPayLoad = in.readLong();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upPackNum);
out.writeLong(downPackNum);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
}
@Override
public String toString() {
return upPackNum + "\t" + downPackNum + "\t" + upPayLoad + "\t"+ downPayLoad;
}
} Combiners编程
/**
* 问:为什么使用Combiner?
* 答:Combiner发生在Map端,对数据进行规约处理,数据量变小了,传送到reduce端的数据量变小了,传输时间变短,作业的整体时间变短。
*
* 问:为什么Combiner不作为MR运行的标配,而是可选步骤哪?
* 答:因为不是所有的算法都适合使用Combiner处理,例如求平均数。
*
* 问:Combiner本身已经执行了reduce操作,为什么在Reducer阶段还要执行reduce操作哪?
* 答:combiner操作发生在map端的,处理一个任务所接收的文件中的数据,不能跨map任务执行;只有reduce可以接收多个map任务处理的数据。
*
*/
//1.5 TODO 规约
job.setCombinerClass(MyCombiner.class);
static class MyCombiner extends Reducer{
protected void reduce(Text k2, java.lang.Iterable v2s, Context ctx)
throws java.io.IOException ,InterruptedException {
long times = 0L;
for (LongWritable count : v2s) {
times += count.get();
}
ctx.write(k2, new LongWritable(times));
}
} Partitioner编程
/**
* 分区的例子必须打成jar运行
* 用处: 1.根据业务需要,产生多个输出文件
* 2.多个reduce任务在运行,提高整体job的运行效率
*/
//1.3 指定分区类
job.setPartitionerClass(KpiPartitioner.class);
job.setNumReduceTasks(2);
static class KpiPartitioner extends HashPartitioner{
@Override
public int getPartition(Text key, LongWritable value, int numReduceTasks) {
return (key.toString().length()==11)?0:1;
}
} Shuffle执行流程详解
MR执行过程
Step1:
Input输入
InputFormat读取数据转换成
FileInputFormat
TextInputFormat
DBInputFormat
Step2:
Map阶段
Map(KEYIN,VALUEIN,KEYOUT,VALUEOUT)
默认情况下:
KEYIN:偏移量 LongWritable
VALUE:内容 TEXT
Step3:
Shuffle阶段
Map端输出,output:
output输出首先是到内存,后面spill(溢写到磁盘),可能有很多文件。
分区 partition (指定哪些map给哪些reduce处理)
排序sort
很多小文件,spill
合并merge
排序sort
最后变成大文件 –>Map Task运行机器的本地磁盘
Reduce端输入
Reduce Task会到Map Task运行机器上拷贝要处理的数据。
合并merge
排序sort
分组group :将相同key的value放在一起
总的来说:
分区:partitioner
排序:sort
拷贝:copy
分组:group
压缩:compress(map阶段大文件)
合并:combiner(Map任务端的reduce,不是所有情况都适用)
Step4:
Reduce阶段
Reduce(KEYIN,VALUEIN,KEYOUT,VALUEOUT)
Step5:
Output输出
OutputFormat
FileOutputFormat
TextOutputFormat:默认情况每个输出一行,key、value的中间分隔符为\t,
默认调用key和value的toString()方法。
DBOutputFormat 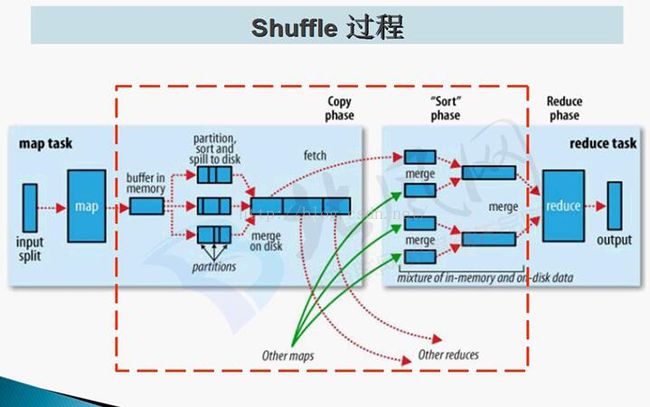
MapReduce调优
1、Shuffle过程
compress压缩调优 (Map端输出压缩)Combiner调优 (Map端输出组合)
2、Map阶段
Map阶段排序小文件合并因子配置
mapreduce.task.io.sort.factor
10
Map阶段输出到内存大小设置
mapreduce.task.io.sort.mb
10
达到内存多少开始spill到磁盘
mapreduce.map.sort.spill.percent
0.8
如果设置reducer任务数为0,map端不会执行combiner,sort,merge操作,会直接输出无序结果(读一行,输一行),
输出的文件数量,与map task的数量匹配(一个Input split对应一个map task)。
3、reduce阶段
设置reduce任务
通常情况一个block就对应一个map任务进行处理,reduce任务如果人工不去设置的话就一个。reduceReduce任务个数该如何设置,程序中通过job.setNumReduceTask(2)2个。Reduce任务的数量是根据程序慢慢调。