显著性检测论文(一)
1、Deep Contrast Learning for Salient Object Detection(深度对比学习显著性检测) cvpr2016
Guanbin Li Yizhou Yu
Department of Computer Science, The University of Hong Kong
背景
因为深度神经网络强大的特征提取,显著性检测有了很大的进步。然而,存在的基于cnn的方法操作在patch level而不是pixel level。导致显著图是模糊的,尤其是在显著目标边缘。另外,image patchs被视为独立的样本,甚至当它们是重叠的时候,造成了很大的计算和存储冗余。这篇论文提出一个端到端的深度对比网络来克服这些。 网络包括两个部分,一个pixel-level fully convolutional stream和一个segment-wise spatial pooling stream。第一步产生一个显著图,第二步产生 segment-wise features和显著性间断点。最后一个全连接CFR模型可以合并改善。
介绍
根据感知上的研究表明,视觉对比是视觉显著性最重要的因素。在以前的工作中,视觉对比是大量的手工的low-level features(像颜色亮度纹理),在pixel级别和segment级别。但手工特征不鲁棒。
使用CNN提取特征包含高层语义信息,因为这些cnn在目标识别数据集上预训练。(有三篇cnn显著性检测文章)。然而所有这些cnn方法都是操作在patch level而不是poxel level。结果,这些方法至少要运行cnn至少几千次得到显著图,训练和测试都很消耗时间和空间。
这篇文章,受到全卷积网络的启发,提出了一个端到端的深度对比网络。网络包括两部分,其中一个是多尺度全连接网络MS-FCN,输入原始图片直接产生一个像素级的显著图,MS-FCN不仅能产生不同尺度的语义特征,还能通过多尺度特征图捕捉微妙的视觉对比来显著性推断。另一个segment-level spatial pooling产生超像素级别的显著图。最后把这两个融合。
相关工作
有一些应用深度学习到显著性检测的尝试,G. Li and Y. Yu. Visual saliency based on multiscale deep features. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015.
Deep networks for saliency detection via local estimation and global search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3183–3192, 2015
Saliency detection by multi-context deep learning.
Deep image saliency computing via progressive representation learning.
然而这些方法都把local image patches作为独立训练和测试样本,有很大的计算消耗。这个限制可以被端到端的方法解决,已经被成功运动到语义分割上。论文运用了改进的全连接网络。这篇论文可视为第一个运用端到端cnn来发现视觉对比信息的工作。
3.深度对比网络
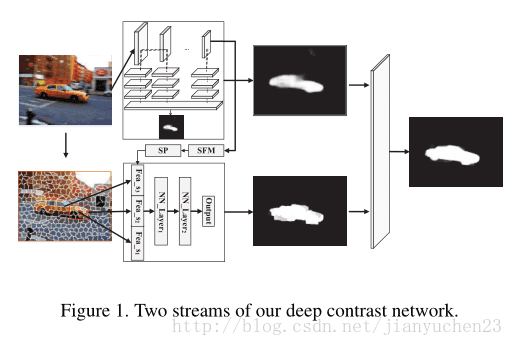
MS-FCN,通过利用多尺度卷积层的视觉对比产生一个原图八分之一分辨率的显著图S1。segment-wise spatial pooling通过空间池化和单个超像素的显著性判断产生一个在超像素级的显著图。最后用一个kernels是1*1的卷积层合并。
MS-FCN
目的是设计一个端到端的卷积网络,其可以看作是一个回归网络,输入图像映射成像素级的显著图。
首先,这个网络要足够深来产生多级别的特征,来在不同的尺度检测显著性物体。其次,能够发现细微视觉对比。最后,微调一个已存在的模型。
我们选择VGG16作为预训练模型。其最后两个全连接层转换为1*1kernel的卷积层如同FCN网络。
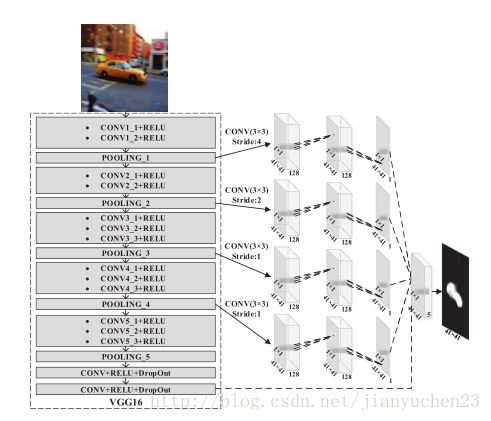
每个pooling后都加上三层,再加上最后输出叠在一起,最终卷积计算特征图。保证大小一致。
从各个层都提取出特征来,通过连接,得到最显著的特征位置。
segment-level saliency inference
显著性目标经常有不规则形状,相应的显著图有间断点沿着目标边界。多尺度FCN在像素级没有处理好这个问题。这一部分用来解决区域和区域边界显著性的视觉对比。
首先把原始图片分解为超像素,给每个超像素计算一个mask在5-3的feature map。5-3中的每个activation都在原图上有一个感受野。
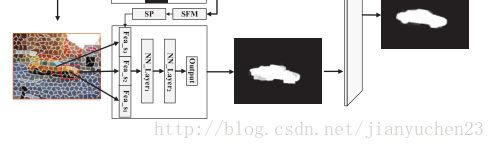
为了发现segment-level视觉对比,对每一个超像素,我们观察三个空间聚集特征向量来自三个嵌套和逐渐增大的窗口。,这三个是被考虑的超像素,其紧邻的超像素们和整个图在Conv5-3。最后经过两个全连接层产生显著图S2。
这是 Visual saliency based on multiscale deep features的改进。
it only takes 1.5 seconds for the trained model (DCL) to detect salient objects in a testing image with 400x300 pixels。 it only takes 1.5 seconds for the trained model (DCL) to detect salient objects in a testing image with 400x300 pixels
2.Instance-Level Salient Object Segmentation(实例级显著性检测)
CVPR_2017
Guanbin Li 1,2 Yuan Xie 1 Liang Lin 1 Yizhou Yu 2∗
1 Sun Yat-sen University 2 The University of Hong Kong

这篇论文主要是提出了在显著性检测的基础上,对显著性区域的个体进一步分割。分为三步,前两步还是在多尺度显著性检测网络上大致提取和修整边缘,然后识别个体。
文章中提到了一些之前做显著性比较好的论文,就有上边那篇。但是说这些基本都是在VGG多层网络内部学习对比,他们的输出都是来自同样大小的感受野,在不同尺度的图像上可能表现不好。这里提到了上边论文的输出只有原始大小的八分之一,对小的显著性物体不准确。
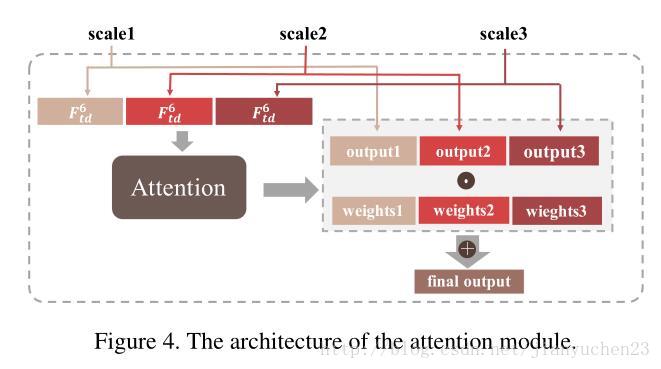
该网络包括单个平行流处理同一张图片不同尺度的输入,一个注意力模型融合三个流的结果。然后MCG产生一些显著性物体建议。最后 全连接CRF模型提高空间统一性和轮廓定位。
相关工作包括三个部分,显著性检测,目标框建议,实例分割。
目标框产生主要包括两种方法,一是产生许多框选择好的,其他是合并图像分割。这在目标检测中广泛使用,但并不是非常适合显著性检测。这里用的框生成是在显著性物体轮廓检测的基础上。

显著性区域检测和轮廓检测都可以看作是二元像素标签问题,全卷积网络可以用在这两个检测问题上。
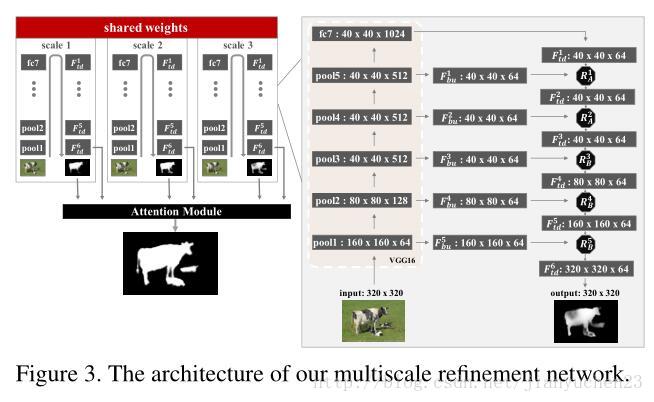
a multiscale refinement network (MSRNet)来进行显著性区域和轮廓检测,MSRnet是三个VGG网络和一个注意力模型来融合。上述两个任务既需要低层线索也需要高层语义信息,一幅图像的信息从低层到高层转化成高级语义信息,同时高层信息也需要从高到低的结合底层信息,像颜色和纹理,来产生高分辨率的区域和边缘检测结果。因此,该网络应该考虑bottom-up and top-down信息传播并且输出的显著图和输入图有相同的分辨率。所以,这个refined VGG网络本质上是一个VGG网络加上了top-down refinment process。
把原始VGG转换为FCN,这是bottom-up。然后利用了top-down和attention来处理得到显著性图。
花费0.6s在显著性区域检测或者轮廓检测上,20s实现显著性实例分割,其中需要18s产生物体框。
3、Visual Saliency Based on Multiscale Deep Features(基于多尺度深度特征的视觉显著性)
cvpr 2015
Guanbin Li Yizhou Yu
Department of Computer Science, The University of Hong Kong
state-of-the-art performance在所有的公共标准上。
显著性是一种视觉对比,图像的某一部分和相邻部分或者图片其他区域相比很突出。所以计算图像的显著性,我们的模型应该评估这种对比度在被考虑的区域以及其周围和图像其他部分之间。
因此,我们提取多尺度的CNN特征在每一个图像区域来自三个嵌套切逐渐增大的窗口,分别是被考虑的区域,相邻的区域,和整个图像。
CNN特征还没有被应用到显著性检测,因为它要学的是周围区域的对比而不是图像区域的内容。这篇论文提出一种简单但有效的方法应用到显著性检测中。

深度卷积网络的上部由一个输出层和两个全连接层构成。输入需要一个图像分解成许多不重叠的区域。三个CNN网络提取的特征进入两个全连接层,每一个有300个神经元,进入输出层实现two-way softmax产生二值标签。
CNN有五个卷积层和两个全连接层,特征来自倒数第二个全连接层,有4096个。许多方法可以应用到不重叠区域分割,这里先超像素再图论分割方法(04年一篇论文)。
400*300像素的花费8s来检测。

4、基于全卷积网络的显著性物体检测
首先用全卷积网络对图像进行分割,同时利用网络中间层提取的特征,结合全局和局部对比度生成显著图,然后利用显著图所表征的图像显著性信息,引导分割图像得到检测结果。该方法借助于全卷积网络语义分割的优势,提取的显著性物体区域具有高度完整性。本方法使用已训练完成的应用于图像分割的全卷积网络,无需额外的参数训练过程,计算速度较快。

一般而言,显著性检测算法首先要进行图像的特征提取,然后基于这些提
取的特征来预测图像的显著性。传统的人工特征提取方法需要精细的设计,并
且这种特征设计依赖于大量的先验专业知识,这种人工设计的特征通常来说其
使用情况范围也比较局限。而深度学习网络通过对原始信号进行逐层特征变换,
将样本在原空间的特征表示变换到新的特征空间,自动地学习得到层次化的特
征表示。这种特征表示随着层次的提高而越来越抽象,比如,低层特征提取图
像的色彩,边缘等信息,高层特征提取语义信息(人,动物)。这种特征通过网
络自动学习获得,对原图像信息具有很强的表征作用。
我们采用全卷积网络对输入图像进行前向计算,得到分割后的图像,同时
我们采用全卷积网络中的特征表示,来进行显著图的计算。本方法采用的全卷
积网络为 Long 提出的模型[119],使用 FCN-8s 网络。全卷积网络随着层数
增加特征图分辨率逐渐减小,对原图像的结构表征越模糊,而特征随着层数增
加越来越具有抽象意义,我们希望特征能对图像结构有较精细的表征,同时具
有更强的语义信息,基于平衡考虑,选取 pool3 层的输出特征。
得到特征表示后,我们采用一种简单、直观的显著图计算方法,和Arhcanta显著性方法类似,利用全局对比度和局部对比度计算显著图利用全局对比度和局部对比度计算显著图。全局对比度表示特征与全局特征的差异,局部对比度表示与周围区域特征的差异。这样就得到了显著图。但该显著图是用网络的中间层特征计算得到,分辨率小于原图像的分辨率,需要通过线性插值进行放大,即得到与原图像尺寸一
致的显著图。

方法计算显著图仅利用已训练完成的全卷积网络的
中间层特征,不需额外的特征提取过程。全卷积网络有着很强的语义分割能力,能有效地将图像分割成各个不同的部分,而图像中引起人眼视觉注意的显著目标通常也具有很强的语义信息,在显著性物体检测中,我们希望能将显著性物体均匀地、完整地提取出来,这一目标借助于分割图像能很好地实现出来。
