高斯混合模型(GMM)及其EM算法的理解
一个例子
高斯混合模型(Gaussian Mixed Model)指的是多个高斯分布函数的线性组合,理论上GMM可以拟合出任意类型的分布,通常用于解决同一集合下的数据包含多个不同的分布的情况(或者是同一类分布但参数不一样,或者是不同类型的分布,比如正态分布和伯努利分布)。
如图1,图中的点在我们看来明显分成两个聚类。这两个聚类中的点分别通过两个不同的正态分布随机生成而来。但是如果没有GMM,那么只能用一个的二维高斯分布来描述图1中的数据。图1中的椭圆即为二倍标准差的正态分布椭圆。这显然不太合理,毕竟肉眼一看就觉得应该把它们分成两类。
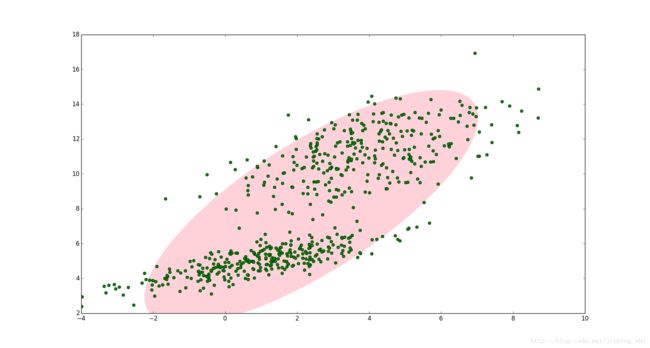
图1
这时候就可以使用GMM了!如图2,数据在平面上的空间分布和图1一样,这时使用两个二维高斯分布来描述图2中的数据,分别记为 N ( μ 1 , Σ 1 ) \mathcal{N}(\boldsymbol{\mu}_1, \boldsymbol{\Sigma}_1) N(μ1,Σ1)和 N ( μ 2 , Σ 2 ) \mathcal{N}(\boldsymbol{\mu}_2, \boldsymbol{\Sigma}_2) N(μ2,Σ2). 图中的两个椭圆分别是这两个高斯分布的二倍标准差椭圆。可以看到使用两个二维高斯分布来描述图中的数据显然更合理。实际上图中的两个聚类的中的点是通过两个不同的正态分布随机生成而来。如果将两个二维高斯分布 N ( μ 1 , Σ 1 ) \mathcal{N}(\boldsymbol{\mu_1}, \boldsymbol{\Sigma}_1) N(μ1,Σ1)和 N ( μ 2 , Σ 2 ) \mathcal{N}(\boldsymbol{\mu}_2, \boldsymbol{\Sigma}_2) N(μ2,Σ2)合成一个二维的分布,那么就可以用合成后的分布来描述图2中的所有点。最直观的方法就是对这两个二维高斯分布做线性组合,用线性组合后的分布来描述整个集合中的数据。这就是高斯混合模型(GMM)。
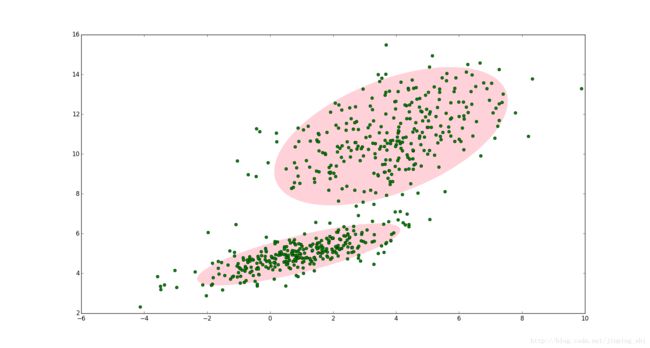
图2
高斯混合模型(GMM)
设有随机变量 X \boldsymbol{X} X,则混合高斯模型可以用下式表示:
p ( x ) = ∑ k = 1 K π k N ( x ∣ μ k , Σ k ) p(\boldsymbol{x}) = \sum_{k=1}^K\pi_k \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k) p(x)=k=1∑KπkN(x∣μk,Σk)
其中 N ( x ∣ μ k , Σ k ) \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k) N(x∣μk,Σk)称为混合模型中的第 k k k个分量(component)。如前面图2中的例子,有两个聚类,可以用两个二维高斯分布来表示,那么分量数 K = 2 K = 2 K=2. π k \pi_k πk是混合系数(mixture coefficient),且满足:
∑ k = 1 K π k = 1 \sum_{k=1}^K\pi_k = 1 k=1∑Kπk=1
0 ≤ π k ≤ 1 0 \leq \pi_k \leq 1 0≤πk≤1
实际上,可以认为 π k \pi_k πk就是每个分量 N ( x ∣ μ k , Σ k ) \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k) N(x∣μk,Σk)的权重。
GMM的应用
GMM常用于聚类。如果要从 GMM 的分布中随机地取一个点的话,实际上可以分为两步:首先随机地在这 K 个 Component 之中选一个,每个 Component 被选中的概率实际上就是它的系数 π k \pi_k πk ,选中 Component 之后,再单独地考虑从这个 Component 的分布中选取一个点就可以了──这里已经回到了普通的 Gaussian 分布,转化为已知的问题。
将GMM用于聚类时,假设数据服从混合高斯分布(Mixture Gaussian Distribution),那么只要根据数据推出 GMM 的概率分布来就可以了;然后 GMM 的 K 个 Component 实际上对应 K K K个 cluster 。根据数据来推算概率密度通常被称作 density estimation 。特别地,当我已知(或假定)概率密度函数的形式,而要估计其中的参数的过程被称作『参数估计』。
例如图2的例子,很明显有两个聚类,可以定义 K = 2 K=2 K=2. 那么对应的GMM形式如下:
p ( x ) = π 1 N ( x ∣ μ 1 , Σ 1 ) + π 2 N ( x ∣ μ 2 , Σ 2 ) p(\boldsymbol{x}) =\pi_1 \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu}_1, \boldsymbol{\Sigma}_1) + \pi_2 \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu}_2, \boldsymbol{\Sigma}_2) p(x)=π1N(x∣μ1,Σ1)+π2N(x∣μ2,Σ2)
上式中未知的参数有六个: ( π 1 , μ 1 , Σ 1 ; π 2 , μ 2 , Σ 2 ) (\pi_1, \boldsymbol{\mu}_1, \boldsymbol{\Sigma}_1; \pi_2, \boldsymbol{\mu}_2, \boldsymbol{\Sigma}_2) (π1,μ1,Σ1;π2,μ2,Σ2). 之前提到GMM聚类时分为两步,第一步是随机地在这 K K K个分量中选一个,每个分量被选中的概率即为混合系数 π k \pi_k πk. 可以设定 π 1 = π 2 = 0.5 \pi_1 = \pi_2 = 0.5 π1=π2=0.5,表示每个分量被选中的概率是0.5,即从中抽出一个点,这个点属于第一类的概率和第二类的概率各占一半。但实际应用中事先指定 π k \pi_k πk的值是很笨的做法,当问题一般化后,会出现一个问题:当从图2中的集合随机选取一个点,怎么知道这个点是来自 N ( x ∣ μ 1 , Σ 1 ) N(\boldsymbol{x}|\boldsymbol{\mu}_1, \boldsymbol{\Sigma}_1) N(x∣μ1,Σ1)还是 N ( x ∣ μ 2 , Σ 2 ) N(\boldsymbol{x}|\boldsymbol{\mu}_2, \boldsymbol{\Sigma}_2) N(x∣μ2,Σ2)呢?换言之怎么根据数据自动确定 π 1 \pi_1 π1和 π 2 \pi_2 π2的值?这就是GMM参数估计的问题。要解决这个问题,可以使用EM算法。通过EM算法,我们可以迭代计算出GMM中的参数: ( π k , x k , Σ k ) (\pi_k, \boldsymbol{x}_k, \boldsymbol{\Sigma}_k) (πk,xk,Σk).
GMM参数估计过程
GMM的贝叶斯理解
在介绍GMM参数估计之前,先改写GMM的形式,改写之后的GMM模型可以方便地使用EM估计参数。GMM的原始形式如下:
(1) p ( x ) = ∑ k = 1 K π k N ( x ∣ μ k , Σ k ) p(\boldsymbol{x}) = \sum_{k=1}^K\pi_k \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k) \tag{1} p(x)=k=1∑KπkN(x∣μk,Σk)(1)
前面提到 π k \pi_k πk可以看成是第 k k k类被选中的概率。我们引入一个新的 K K K维随机变量 z \boldsymbol{z} z. z k ( 1 ≤ k ≤ K ) z_k (1 \leq k \leq K) zk(1≤k≤K)只能取0或1两个值; z k = 1 z_k = 1 zk=1表示第 k k k类被选中的概率,即: p ( z k = 1 ) = π k p(z_k = 1) = \pi_k p(zk=1)=πk;如果 z k = 0 z_k = 0 zk=0表示第 k k k类没有被选中的概率。更数学化一点, z k z_k zk要满足以下两个条件:
z k ∈ { 0 , 1 } z_k \in \{0,1\} zk∈{0,1}
∑ K z k = 1 \sum_K z_k = 1 K∑zk=1
例如图2中的例子,有两类,则 z \boldsymbol{z} z的维数是2. 如果从第一类中取出一个点,则 z = ( 1 , 0 ) \boldsymbol{z} = (1, 0) z=(1,0);,如果从第二类中取出一个点,则 z = ( 0 , 1 ) \boldsymbol{z} = (0, 1) z=(0,1).
z k = 1 z_k=1 zk=1的概率就是 π k \pi_k πk,假设 z k z_k zk之间是独立同分布的(iid),我们可以写出 z \boldsymbol{z} z的联合概率分布形式,就是连乘:
(2) p ( z ) = p ( z 1 ) p ( z 2 ) . . . p ( z K ) = ∏ k = 1 K π k z k p(\boldsymbol{z}) = p(z_1) p(z_2)...p(z_K) = \prod_{k=1}^K \pi_k^{z_k} \tag{2} p(z)=p(z1)p(z2)...p(zK)=k=1∏Kπkzk(2)
因为 z k z_k zk只能取0或1,且 z \boldsymbol{z} z中只能有一个 z k z_k zk为1而其它 z j ( j ≠ k ) z_j (j\neq k) zj(j̸=k)全为0,所以上式是成立的。
图2中的数据可以分为两类,显然,每一類中的数据都是服从正态分布的。这个叙述可以用条件概率来表示:
p ( x ∣ z k = 1 ) = N ( x ∣ μ k , Σ k ) p(\boldsymbol{x}|z_k = 1) = \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k) p(x∣zk=1)=N(x∣μk,Σk)
即第 k k k类中的数据服从正态分布。进而上式有可以写成如下形式:
(3) p ( x ∣ z ) = ∏ k = 1 K N ( x ∣ μ k , Σ k ) z k p(\boldsymbol{x}| \boldsymbol{z}) = \prod_{k=1}^K \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)^{z_k} \tag{3} p(x∣z)=k=1∏KN(x∣μk,Σk)zk(3)
上面分别给出了 p ( z ) p(\boldsymbol{z}) p(z)和 p ( x ∣ z ) p(\boldsymbol{x}| \boldsymbol{z}) p(x∣z)的形式,根据条件概率公式,可以求出 p ( x ) p(\boldsymbol{x}) p(x)的形式:
(4) p ( x ) = ∑ z p ( z ) p ( x ∣ z ) = ∑ z ( ∏ k = 1 K π k z k N ( x ∣ μ k , Σ k ) z k ) = ∑ k = 1 K π k N ( x ∣ μ k , Σ k ) \begin{aligned} p(\boldsymbol{x}) &= \sum_{\boldsymbol{z}} p(\boldsymbol{z}) p(\boldsymbol{x}| \boldsymbol{z}) \\ &= \sum_{\boldsymbol{z}} \left(\prod_{k=1}^K \pi_k^{z_k} \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)^{z_k} \right ) \\ &= \sum_{k=1}^K \pi_k \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k) \end{aligned} \tag{4} p(x)=z∑p(z)p(x∣z)=z∑(k=1∏KπkzkN(x∣μk,Σk)zk)=k=1∑KπkN(x∣μk,Σk)(4)
(注:上式第二个等号,对 z \boldsymbol{z} z求和,实际上就是 ∑ k = 1 K \sum_{k=1}^K ∑k=1K。又因为对某个 k k k,只要 i ≠ k i \ne k i̸=k,则有 z i = 0 z_i = 0 zi=0,所以 z k = 0 z_k=0 zk=0的项为1,可省略,最终得到第三个等号)
可以看到GMM模型的(1)式与(4)式有一样的形式,且(4)式中引入了一个新的变量 z \boldsymbol{z} z,通常称为隐含变量(latent variable)。对于图2中的数据,『隐含』的意义是:我们知道数据可以分成两类,但是随机抽取一个数据点,我们不知道这个数据点属于第一类还是第二类,它的归属我们观察不到,因此引入一个隐含变量 z \boldsymbol{z} z来描述这个现象。
注意到在贝叶斯的思想下, p ( z ) p(\boldsymbol{z}) p(z)是先验概率, p ( x ∣ z ) p(\boldsymbol{x}| \boldsymbol{z}) p(x∣z)是似然概率,很自然我们会想到求出后验概率 p ( z ∣ x ) p(\boldsymbol{z}| \boldsymbol{x}) p(z∣x):
(5) γ ( z k ) = p ( z k = 1 ∣ x ) = p ( z k = 1 ) p ( x ∣ z k = 1 ) p ( x , z k = 1 ) = p ( z k = 1 ) p ( x ∣ z k = 1 ) ∑ j = 1 K p ( z j = 1 ) p ( x ∣ z j = 1 ) = π k N ( x ∣ μ k , Σ k ) ∑ j = 1 K π j N ( x ∣ μ j , Σ j ) \begin{aligned} \gamma(z_k) &= p(z_k = 1| \boldsymbol{x}) \\ &= \frac{p(z_k = 1) p(\boldsymbol{x}|z_k = 1)}{p(\boldsymbol{x}, z_k = 1)} \\ &= \frac{p(z_k = 1) p(\boldsymbol{x}|z_k = 1)}{\sum_{j=1}^K p(z_j = 1) p(\boldsymbol{x}|z_j = 1)} \\ &= \frac{\pi_k \mathcal{N}(\boldsymbol{x|\boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k})}{\sum_{j=1}^K \pi_j \mathcal{N}(\boldsymbol{x|\boldsymbol{\mu}_j, \boldsymbol{\Sigma}_j})} \end{aligned} \tag{5} γ(zk)=p(zk=1∣x)=p(x,zk=1)p(zk=1)p(x∣zk=1)=∑j=1Kp(zj=1)p(x∣zj=1)p(zk=1)p(x∣zk=1)=∑j=1KπjN(x∣μj,Σj)πkN(x∣μk,Σk)(5)
(第2行,贝叶斯定理。关于这一行的分母,很多人有疑问,应该是 p ( x , z k = 1 ) p(\boldsymbol{x}, z_k = 1) p(x,zk=1)还是 p ( x ) p(\boldsymbol{x}) p(x),按照正常写法,应该是 p ( x ) p(\boldsymbol{x}) p(x)。但是为了强调 z k z_k zk的取值,有的书会写成 p ( x , z k = 1 ) p(\boldsymbol{x}, z_k = 1) p(x,zk=1),比如李航的《统计学习方法》,这里就约定 p ( x ) p(\boldsymbol{x}) p(x)与 p ( x , z k = 1 ) p(\boldsymbol{x}, z_k = 1) p(x,zk=1)是等同的)
(第3行,全概率公式)
(最后一个等号,结合(3)(4))
上式中我们定义符号 γ ( z k ) \gamma(z_k) γ(zk)来表示来表示第 k k k个分量的后验概率。在贝叶斯的观点下, π k \pi_k πk可视为 z k = 1 z_k=1 zk=1的先验概率。
上述内容改写了GMM的形式,并引入了隐含变量 z \boldsymbol{z} z和已知 x {\boldsymbol{x}} x后的的后验概率 γ ( z k ) \gamma(z_k) γ(zk),这样做是为了方便使用EM算法来估计GMM的参数。
EM算法估计GMM参数
EM算法(Expectation-Maximization algorithm)分两步,第一步先求出要估计参数的粗略值,第二步使用第一步的值最大化似然函数。因此要先求出GMM的似然函数。
假设 x = { x 1 , x 2 , . . . , x N } \boldsymbol{x} = \{\boldsymbol{x}_1, \boldsymbol{x}_2, ..., \boldsymbol{x}_N\} x={x1,x2,...,xN},对于图2, x \boldsymbol{x} x是图中所有点(每个点有在二维平面上有两个坐标,是二维向量,因此 x 1 , x 2 \boldsymbol{x}_1, \boldsymbol{x}_2 x1,x2等都用粗体表示)。GMM的概率模型如(1)式所示。GMM模型中有三个参数需要估计,分别是 π \boldsymbol{\pi} π, μ \boldsymbol{\mu} μ和 Σ \boldsymbol{\Sigma} Σ. 将(1)式稍微改写一下:
(6) p ( x ∣ π , μ , Σ ) = ∑ k = 1 K π k N ( x ∣ μ k , Σ k ) p(\boldsymbol{x}|\boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}) = \sum_{k=1}^K\pi_k \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k) \tag{6} p(x∣π,μ,Σ)=k=1∑KπkN(x∣μk,Σk)(6)
为了估计这三个参数,需要分别求解出这三个参数的最大似然函数。先求解 μ k \mu_k μk的最大似然函数。样本符合iid,(6)式所有样本连乘得到最大似然函数,对(6)式取对数得到对数似然函数,然后再对 μ k \boldsymbol{\mu_k} μk求导并令导数为0即得到最大似然函数。
(7) 0 = − ∑ n = 1 N π k N ( x n ∣ μ k , Σ k ) ∑ j π j N ( x n ∣ μ j , Σ j ) Σ k ( x n − μ k ) 0 = -\sum_{n=1}^N \frac{\pi_k \mathcal{N}(\boldsymbol{x}_n | \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)}{\sum_j \pi_j \mathcal{N}(\boldsymbol{x}_n|\boldsymbol{\mu}_j, \boldsymbol{\Sigma}_j)} \boldsymbol{\Sigma}_k (\boldsymbol{x}_n - \boldsymbol{\mu}_k) \tag{7} 0=−n=1∑N∑jπjN(xn∣μj,Σj)πkN(xn∣μk,Σk)Σk(xn−μk)(7)
注意到上式中分数的一项的形式正好是(5)式后验概率的形式。两边同乘 Σ k − 1 \boldsymbol{\Sigma}_k^{-1} Σk−1,重新整理可以得到:
(8) μ k = 1 N k ∑ n = 1 N γ ( z n k ) x n \boldsymbol{\mu}_k = \frac{1}{N_k}\sum_{n=1}^N \gamma(z_{nk}) \boldsymbol{x}_n \tag{8} μk=Nk1n=1∑Nγ(znk)xn(8)
其中:
(9) N k = ∑ n = 1 N γ ( z n k ) N_k = \sum_{n=1}^N \gamma(z_{nk}) \tag{9} Nk=n=1∑Nγ(znk)(9)
(8)式和(9)式中, N N N表示点的数量。 γ ( z n k ) \gamma(z_{nk}) γ(znk)表示点 n n n( x n \boldsymbol{x}_n xn)属于聚类 k k k的后验概率。则 N k N_k Nk可以表示属于第 k k k个聚类的点的数量。那么 μ k \boldsymbol{\mu}_k μk表示所有点的加权平均,每个点的权值是 ∑ n = 1 N γ ( z n k ) \sum_{n=1}^N \gamma(z_{nk}) ∑n=1Nγ(znk),跟第 k k k个聚类有关。
同理求 Σ k \boldsymbol{\Sigma}_k Σk的最大似然函数,可以得到:
(10) Σ k = 1 N k ∑ n = 1 N γ ( z n k ) ( x n − μ k ) ( x n − μ k ) T \boldsymbol{\Sigma}_k = \frac{1}{N_k} \sum_{n=1}^N \gamma(z_{nk}) (x_n - \boldsymbol{\mu}_k)(x_n - \boldsymbol{\mu}_k)^T \tag{10} Σk=Nk1n=1∑Nγ(znk)(xn−μk)(xn−μk)T(10)
最后剩下 π k \pi_k πk的最大似然函数。注意到 π k \pi_k πk有限制条件 ∑ k = 1 K π k = 1 \sum_{k=1}^K\pi_k = 1 ∑k=1Kπk=1,因此我们需要加入拉格朗日算子:
ln p ( x ∣ π , μ , Σ ) + λ ( ∑ k = 1 K π k − 1 ) \ln p(\boldsymbol{x}|\boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}) + \lambda(\sum_{k=1}^K \pi_k -1) lnp(x∣π,μ,Σ)+λ(k=1∑Kπk−1)
求上式关于 π k \pi_k πk的最大似然函数,得到:
(11) 0 = ∑ n = 1 N N ( x n ∣ μ k , Σ k ) ∑ j π j N ( x n ∣ μ j , Σ j ) + λ 0 = \sum_{n=1}^N \frac{\mathcal{N}(\boldsymbol{x}_n | \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)}{\sum_j \pi_j \mathcal{N}(\boldsymbol{x}_n|\boldsymbol{\mu}_j, \boldsymbol{\Sigma}_j)} + \lambda \tag{11} 0=n=1∑N∑jπjN(xn∣μj,Σj)N(xn∣μk,Σk)+λ(11)
上式两边同乘 π k \pi_k πk,我们可以做如下推导:
(11.1) 0 = ∑ n = 1 N π k N ( x n ∣ μ k , Σ k ) ∑ j π j N ( x n ∣ μ j , Σ j ) + λ π k 0 = \sum_{n=1}^N \frac{\pi_k \mathcal{N}(\boldsymbol{x}_n | \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)}{\sum_j \pi_j \mathcal{N}(\boldsymbol{x}_n|\boldsymbol{\mu}_j, \boldsymbol{\Sigma}_j)} + \lambda \pi_k \tag{11.1} 0=n=1∑N∑jπjN(xn∣μj,Σj)πkN(xn∣μk,Σk)+λπk(11.1)
结合公式(5)、(9),可以将上式改写成:
(11.2) 0 = N k + λ π k 0 = N_k + \lambda \pi_k \tag{11.2} 0=Nk+λπk(11.2)
注意到 ∑ k = 1 K π k = 1 \sum_{k=1}^K \pi_k = 1 ∑k=1Kπk=1,上式两边同时对 k k k求和。此外 N k N_k Nk表示属于第个聚类的点的数量(公式(9))。对 N k , N_k, Nk,从 k = 1 k=1 k=1到 k = K k=K k=K求和后,就是所有点的数量 N N N:
(11.3) 0 = ∑ k = 1 K N k + λ ∑ k = 1 K π k 0 = \sum_{k=1}^K N_k + \lambda \sum_{k=1}^K \pi_k \tag{11.3} 0=k=1∑KNk+λk=1∑Kπk(11.3)
(11.4) 0 = N + λ 0 = N + \lambda \tag{11.4} 0=N+λ(11.4)
从而可得到 λ = − N \lambda = -N λ=−N,带入(11.2),进而可以得到 π k \pi_k πk更简洁的表达式:
(12) π k = N k N \pi_k = \frac{N_k}{N} \tag{12} πk=NNk(12)
EM算法估计GMM参数即最大化(8),(10)和(12)。需要用到(5),(8),(10)和(12)四个公式。我们先指定 π \boldsymbol{\pi} π, μ \boldsymbol{\mu} μ和 Σ \boldsymbol{\Sigma} Σ的初始值,带入(5)中计算出 γ ( z n k ) \gamma(z_{nk}) γ(znk),然后再将 γ ( z n k ) \gamma(z_{nk}) γ(znk)带入(8),(10)和(12),求得 π k \pi_k πk, μ k \boldsymbol{\mu}_k μk和 Σ k \boldsymbol{\Sigma}_k Σk;接着用求得的 π k \pi_k πk, μ k \boldsymbol{\mu}_k μk和 Σ k \boldsymbol{\Sigma}_k Σk再带入(5)得到新的 γ ( z n k ) \gamma(z_{nk}) γ(znk),再将更新后的 γ ( z n k ) \gamma(z_{nk}) γ(znk)带入(8),(10)和(12),如此往复,直到算法收敛。
EM算法
- 定义分量数目 K K K,对每个分量 k k k设置 π k \pi_k πk, μ k \boldsymbol{\mu}_k μk和 Σ k \boldsymbol{\Sigma}_k Σk的初始值,然后计算(6)式的对数似然函数。
- E step
根据当前的 π k \pi_k πk、 μ k \boldsymbol{\mu}_k μk、 Σ k \boldsymbol{\Sigma}_k Σk计算后验概率 γ ( z n k ) \gamma(z_{nk}) γ(znk)
γ ( z n k ) = π k N ( x n ∣ μ n , Σ n ) ∑ j = 1 K π j N ( x n ∣ μ j , Σ j ) \gamma(z_{nk}) = \frac{\pi_k\mathcal{N}(\boldsymbol{x}_n| \boldsymbol{\mu}_n, \boldsymbol{\Sigma}_n)}{\sum_{j=1}^K \pi_j \mathcal{N}(\boldsymbol{x}_n| \boldsymbol{\mu}_j, \boldsymbol{\Sigma}_j)} γ(znk)=∑j=1KπjN(xn∣μj,Σj)πkN(xn∣μn,Σn) - M step
根据E step中计算的 γ ( z n k ) \gamma(z_{nk}) γ(znk)再计算新的 π k \pi_k πk、 μ k \boldsymbol{\mu}_k μk、 Σ k \boldsymbol{\Sigma}_k Σk
μ k n e w = 1 N k ∑ n = 1 N γ ( z n k ) x n Σ k n e w = 1 N k ∑ n = 1 N γ ( z n k ) ( x n − μ k n e w ) ( x n − μ k n e w ) T π k n e w = N k N \begin{aligned} \boldsymbol{\mu}_k^{new} &= \frac{1}{N_k} \sum_{n=1}^N \gamma(z_{nk}) \boldsymbol{x}_n \\ \boldsymbol{\Sigma}_k^{new} &= \frac{1}{N_k} \sum_{n=1}^N \gamma(z_{nk}) (\boldsymbol{x}_n - \boldsymbol{\mu}_k^{new}) (\boldsymbol{x}_n - \boldsymbol{\mu}_k^{new})^T \\ \pi_k^{new} &= \frac{N_k}{N} \end{aligned} μknewΣknewπknew=Nk1n=1∑Nγ(znk)xn=Nk1n=1∑Nγ(znk)(xn−μknew)(xn−μknew)T=NNk
其中:
N k = ∑ n = 1 N γ ( z n k ) N_k = \sum_{n=1}^N \gamma(z_{nk}) Nk=n=1∑Nγ(znk) - 计算(6)式的对数似然函数
ln p ( x ∣ π , μ , Σ ) = ∑ n = 1 N ln { ∑ k = 1 K π k N ( x k ∣ μ k , Σ k ) } \ln p(\boldsymbol{x}|\boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}) = \sum_{n=1}^N \ln \left\{\sum_{k=1}^K \pi_k \mathcal{N}(\boldsymbol{x}_k| \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)\right\} lnp(x∣π,μ,Σ)=n=1∑Nln{k=1∑KπkN(xk∣μk,Σk)} - 检查参数是否收敛或对数似然函数是否收敛,若不收敛,则返回第2步。
Reference
- 漫谈 Clustering (3): Gaussian Mixture Model
- Draw Gaussian distribution ellipse
- Pang-Ning Tan 等, 数据挖掘导论(英文版), 机械工业出版社, 2010
- Christopher M. Bishop etc., Pattern Recognition and Machine Learning, Springer, 2006
- 李航, 统计学习方法, 清华大学出版社, 2012