Tensorflow实现基于RNN的文本分类任务的注意力机制
要点:
该教程为深度学习tensorflow实现文本分类任务的注意力机制,实现可视化注意力文本。
环境配置:
Wn10+CPU i7-6700
Pycharm2018
Tensorflow 1.8.0
Tensorboard 1.8.0
笔者信息:Next_Legend QQ:1219154092 人工智能 自然语言处理 图像处理 神经网络
——2018.8.8于天津大学
一、下载代码
该代码见笔者的资源下载部分https://download.csdn.net/download/jinyuan7708/10592063
代码不需要改动,只需要配置好环境和安装好相应的库,就可以训练和测试了。
二、相应的库文件
tensorflow 1.8.0
tensorboard 1.8.0
numpy
keras
tqdm
三、工程目录文件
该项目主要包括attention.py train.py utils.py visualize.py四个文件夹
其中train.py文件是训练模型的文件,运行后会生成model.data-00000-of-00001、model.index、model.meta以及checkpoint文件,也就是训练生成的模型文件。
四、核心代码
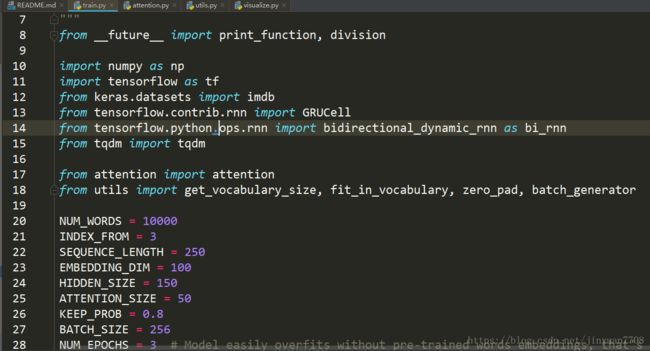


train.py文件代码
from __future__ import print_function, division
import numpy as np
import tensorflow as tf
from keras.datasets import imdb
from tensorflow.contrib.rnn import GRUCell
from tensorflow.python.ops.rnn
import bidirectional_dynamic_rnn as bi_rnn
from tqdm import tqdm
from attention import attention
from utils import get_vocabulary_size, fit_in_vocabulary, zero_pad, batch_generator
NUM_WORDS = 10000
INDEX_FROM = 3
SEQUENCE_LENGTH = 250
EMBEDDING_DIM = 100
HIDDEN_SIZE = 150
ATTENTION_SIZE = 50
KEEP_PROB = 0.8
BATCH_SIZE = 256
NUM_EPOCHS = 3 # Model easily overfits without pre-trained words embeddings, that's why train for a few epochs
DELTA = 0.5
MODEL_PATH = './model'
# Load the data set
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=NUM_WORDS, index_from=INDEX_FROM)
# Sequences pre-processing
vocabulary_size = get_vocabulary_size(X_train)
X_test = fit_in_vocabulary(X_test, vocabulary_size)
X_train = zero_pad(X_train, SEQUENCE_LENGTH)
X_test = zero_pad(X_test, SEQUENCE_LENGTH)
# Different placeholders
with tf.name_scope('Inputs'):
batch_ph = tf.placeholder(tf.int32, [None, SEQUENCE_LENGTH], name='batch_ph')
target_ph = tf.placeholder(tf.float32, [None], name='target_ph')
seq_len_ph = tf.placeholder(tf.int32, [None], name='seq_len_ph')
keep_prob_ph = tf.placeholder(tf.float32, name='keep_prob_ph')
# Embedding layer
with tf.name_scope('Embedding_layer'):
embeddings_var = tf.Variable(tf.random_uniform([vocabulary_size, EMBEDDING_DIM], -1.0, 1.0), trainable=True)
tf.summary.histogram('embeddings_var', embeddings_var)
batch_embedded = tf.nn.embedding_lookup(embeddings_var, batch_ph)
# (Bi-)RNN layer(-s)
rnn_outputs, _ = bi_rnn(GRUCell(HIDDEN_SIZE), GRUCell(HIDDEN_SIZE),
inputs=batch_embedded, sequence_length=seq_len_ph, dtype=tf.float32)
tf.summary.histogram('RNN_outputs', rnn_outputs)
# Attention layer
with tf.name_scope('Attention_layer'):
attention_output, alphas = attention(rnn_outputs, ATTENTION_SIZE, return_alphas=True)
tf.summary.histogram('alphas', alphas)
# Dropout
drop = tf.nn.dropout(attention_output, keep_prob_ph)
# Fully connected layer
with tf.name_scope('Fully_connected_layer'):
W = tf.Variable(tf.truncated_normal([HIDDEN_SIZE * 2, 1], stddev=0.1)) # Hidden size is multiplied by 2 for Bi-RNN
b = tf.Variable(tf.constant(0., shape=[1]))
y_hat = tf.nn.xw_plus_b(drop, W, b)
y_hat = tf.squeeze(y_hat)
tf.summary.histogram('W', W)
with tf.name_scope('Metrics'):
# Cross-entropy loss and optimizer initialization
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=y_hat, labels=target_ph))
tf.summary.scalar('loss', loss)
optimizer = tf.train.AdamOptimizer(learning_rate=1e-3).minimize(loss)
# Accuracy metric
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.round(tf.sigmoid(y_hat)), target_ph), tf.float32))
tf.summary.scalar('accuracy', accuracy)
merged = tf.summary.merge_all()
train_batch_generator = batch_generator(X_train, y_train, BATCH_SIZE)
test_batch_generator = batch_generator(X_test, y_test, BATCH_SIZE)
train_writer = tf.summary.FileWriter('./logdir/train', accuracy.graph)
test_writer = tf.summary.FileWriter('./logdir/test', accuracy.graph)
session_conf = tf.ConfigProto(gpu_options=tf.GPUOptions(allow_growth=True))
saver = tf.train.Saver()
if __name__ == "__main__":
with tf.Session(config=session_conf) as sess:
sess.run(tf.global_variables_initializer())
print("Start learning...")
for epoch in range(NUM_EPOCHS):
loss_train = 0
loss_test = 0
accuracy_train = 0
accuracy_test = 0
print("epoch: {}\t".format(epoch), end="")
# Training
num_batches = X_train.shape[0] // BATCH_SIZE
for b in tqdm(range(num_batches)):
x_batch, y_batch = next(train_batch_generator)
seq_len = np.array([list(x).index(0) + 1 for x in x_batch]) # actual lengths of sequences
loss_tr, acc, _, summary = sess.run([loss, accuracy, optimizer, merged],
feed_dict={batch_ph: x_batch,
target_ph: y_batch,
seq_len_ph: seq_len,
keep_prob_ph: KEEP_PROB})
accuracy_train += acc
loss_train = loss_tr * DELTA + loss_train * (1 - DELTA)
train_writer.add_summary(summary, b + num_batches * epoch)
accuracy_train /= num_batches
# Testing
num_batches = X_test.shape[0] // BATCH_SIZE
for b in tqdm(range(num_batches)):
x_batch, y_batch = next(test_batch_generator)
seq_len = np.array([list(x).index(0) + 1 for x in x_batch]) # actual lengths of sequences
loss_test_batch, acc, summary = sess.run([loss, accuracy, merged],
feed_dict={batch_ph: x_batch,
target_ph: y_batch,
seq_len_ph: seq_len,
keep_prob_ph: 1.0})
accuracy_test += acc
loss_test += loss_test_batch
test_writer.add_summary(summary, b + num_batches * epoch)
accuracy_test /= num_batches
loss_test /= num_batches
print("loss: {:.3f}, val_loss: {:.3f}, acc: {:.3f}, val_acc: {:.3f}".format(
loss_train, loss_test, accuracy_train, accuracy_test
))
train_writer.close()
test_writer.close()
saver.save(sess, MODEL_PATH)
print("Run 'tensorboard --logdir=./logdir' to checkout tensorboard logs.")
五、训练过程

笔者由于使用的 CPU来进行训练,所以速度比较慢,感兴趣的朋友可以考虑使用GPU来计算,可以大大减少训练模型的时间。如果不会搭建gpu环境的小伙伴可以参考我的另一篇Tensorflow gpu环境搭建 ,附上地址哈:
https://blog.csdn.net/jinyuan7708/article/details/79642924
六、训练结果
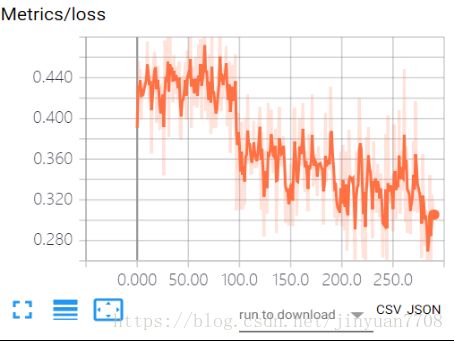
七、Tensorboard可视化

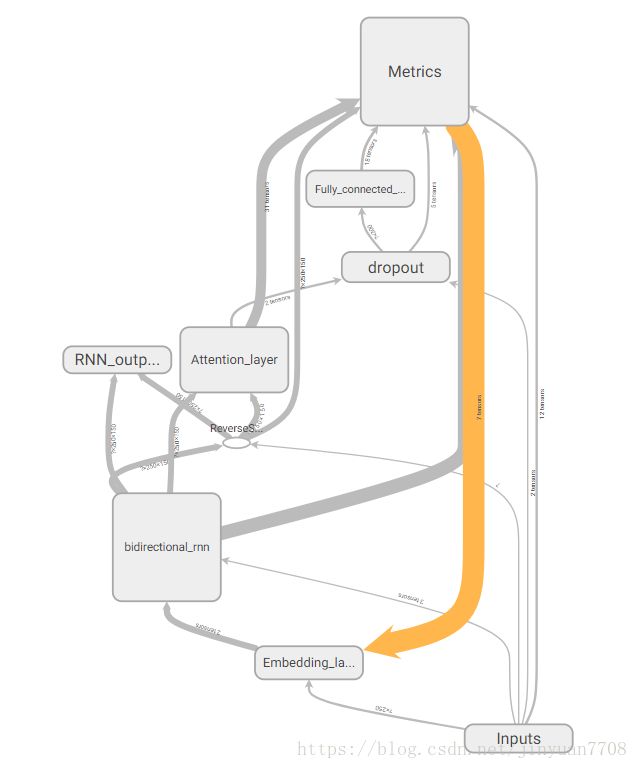
八、visualization可视化结果
得到模型后,再继续执行visualize.py文件,生成结果可视化。如下图:

至此,我们的教程就结束啦,代码等文件我上传到我的blog下载资源部分,欢迎大家下载批评指正哈!
代码地址:https://download.csdn.net/download/jinyuan7708/10592063