BigBrother的大数据之旅Day 10 hive(1)
HIVE
1 一些概念
HIve存在的目的:非编程人员使用mapreduce进行分析
HIVE:是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。

HIVE 的driver(核心)包含:
解释器: (解析器) 解释输入的hql语句
编译器: hql转化为语法树>查询块>查询计划>物理计划(MR job)>优化执行
优化器: 找到最优化程序进行执行
执行器
ANTLR词法语法分析工具解析hql

HIVE的数据包含 元数据和数据:
元数据:表字段,字段类型等,可以放入到mysql等关系型数据库
数据:以文件的形式存放在hdfs上
2 hive 执行流程
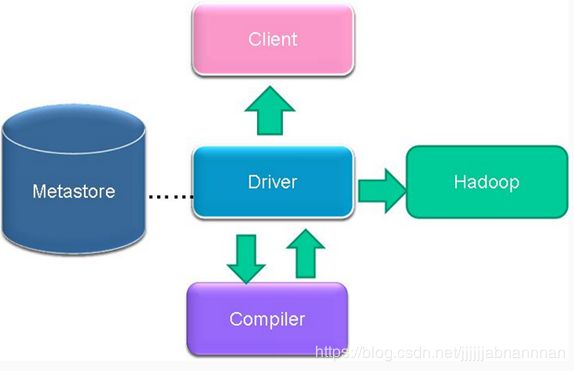
- clinet提交hql到driver
- driver到metastore中查询是否存在元数据
- metstore返回结果到driver
- driver向编译器提交
- 编译器返回结果(将hql转换为操作符)
- driver和hadoop中的hdfs进行交互(操作)
- 最后返回结果给client
3 hive搭建的三种模式
(1) local模式(内置derby数据库)
(2) 单用户模式 (MySQL)
(3) 多用户模式 (Mysql)
hive 上的表是个目录,

local模式,
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:derby:;databaseName=metastore_db;create=truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>org.apache.derby.jdbc.EmbeddedDrivervalue>
property>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
property>
<property>
<name>hive.metastore.localname>
<value>truevalue>
property>
configuration>
注:使用derby存储方式时,运行hive会在当前目录生成一个derby文件和一个metastore_db目录。这种存储方式的弊端是在同一个目录下同时只能有一个hive客户端能使用数据库,否则会报错

<configuration>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive_remote/warehousevalue>
property>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://localhost/hive_remote?createDatabaseIfNotExist=truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>hivevalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>passwordvalue>
property>
<property>
<name>hive.metastore.localname>
<value>truevalue>
property>
configuration>
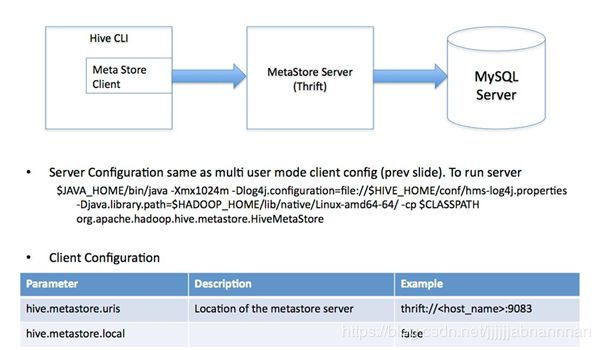
MetaStore server配置文件 (目录+数据库连接4要素)
需要事先把MySQL数据连接的jiar放到lib下
<configuration>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
property>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://192.168.57.6:3306/hive?createDatabaseIfNotExist=truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123456value>
property>
configuration>
Metastore的客户端配置文件
<configuration>
<property>
<name>hive.metastore.localname>
<value>falsevalue>
property>
<property>
<name>hive.metastore.urisname>
<value>thrift://192.168.57.5:9083value>
property>
configuration>
a 服务器端需要开启服务
启动 hive --service mettastore
b hive默认的数据库default的目录为在warehourse.dir的/
如果创建了其他数据库,会在warehoures.dir/创建
虽然他们在逻辑上是同级的,但是在物理上是层级的
4 HIVE操作
创建表
①Create Table Like:
CREATE TABLE empty_key_value_store LIKE key_value_store;
只在hdfs中创建一个目录,不开启mapreduce任务
不复制数据,只复制表结构
②Create Table As Select (CTAS)
CREATE TABLE new_key_value_store
AS
SELECT columA, columB FROM key_value_store;
在hdfs中复制数据,只开启map任务,reducer个数为0
复制数据
drop database restrict(默认,不包括下面的表) | cascade (级联删除,包括下面的表)
FILEDS_TERMINATED BY 字段被什么截取
COLLECTION
create table tb_user(
id int,
name string,
hobby array,
addrs map
)
hive 分为内部表和外部表
内部表–managed(默认为内部表在创建的时候不需要添加关键词)
存储在hive.metastore.warehourse.dir (默认) 可以通过location进行制定路径
表删除,元数据和数据也删除
外部表–external
数据存在外部,删除是,只删除元数据,不会对数据有影响,可能数据以前就存在了
describe 表, 查看表的描述
或者describe formatted 表 查看详细信息
describe extended 表 查看详细信息
java对象 —> 序列化 >> json
(传统)
记录 >> hdfs (序列化–持久化)
row formatted delimited
后面加分隔符
如 filed terminated by ’ ,’
collection terminated by ‘-’
将本地文件加载到数据表中,使用表中设置
hive > load data local inpath ‘root/xx.txt’ into table tb_user1
ctreate table xx like ex_XX : 复制表,无数据
create table xx as select * from xx: 复制表,有数据
分区的目的:为了更快从数据库中拿出想要的数据
分区就是先创建目录,再把数据放进去
create tablex (id int,content String) partitioned by(dt string,hour string)
双分区,以dt为目录,子目录为hour
单分区 partionteed by (dt string)
dt目录
alter table tb_user5 add partiton (age=36,sex=“female”)
alter table tb drop
alter table tb_user5 drop partition (age=20,sex=male),(age=21,sex=female)
删除单分区的两个区数据:
aleter table tabn drop partiton (age=20),partiton (age=21)
show parations 表名称
msck repair
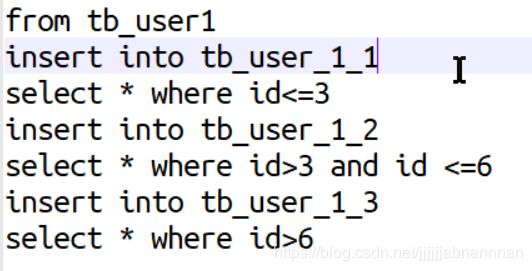
后面可以加分区
delete 需要 事务,hive默认不支持事务,所以默认不能使用delete命令
truncate不需要事务,可以使用truncate table xxx 进行清空表(截断)
beeline和hiveServer2 进行配合使用
1 ,在node3上启动hiveServer2
![]()
!close 退出链接
!quit 退出程序

ctrl+v 然后输入!xmllint -format -,记得删除第一行xml的,这个命令会自动生成一个xml的头
load命令的使用和区别
load data inpath ‘/test/data.txt’ into table day_table partition(dt=“dt2”); --hdfs 移动文件到hive中
load data local inpath ‘/test/data.txt’ into table day_table partition(dt=“dt2”); --本地上传(复制)文件到hive中
form tableA(一个mapreduce所以要提前到这个位置)
insert into tableB
select *
inset into tableC
select num where
insert overwrite table D(此处有table关键字)
select id,name
数据调优: 减少IO次数,减少IO量
beeline必须和hiveserver2配合使用
①Beeline 要与HiveServer2配合使用
②服务端启动hiveserver2
③客户的通过beeline两种方式连接到hive
a)beeline -u jdbc:hive2://localhost:10000/default -n root
b)beeline
c)beeline> !connect jdbc:hive2://:/;auth=noSasl root 123
④默认 用户名、密码不验证
通过JDBC连接hive
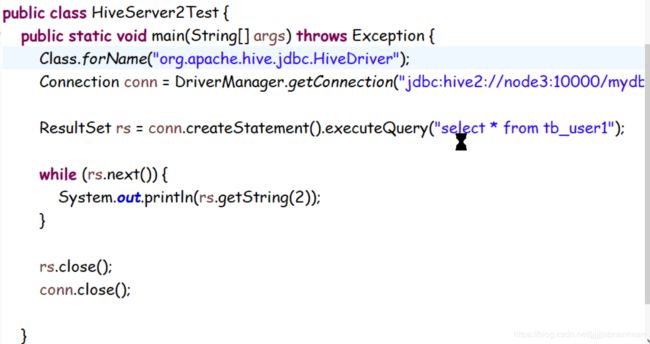
step1: 在服务器上启动 hiveserver2和hive – sevice metasotre
step2: 编写java项目,导入hive的jar包,如果不知道导入哪些,全部导入就可以
step3:写代码
public class MainClass {
private static String dirvername = "org.apache.hive.jdbc.HiveDriver";
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Class.forName(dirvername);
String url ="jdbc:hive2://node1:10000/default";
String username = "root";
String password = "huxiede";
Connection conn = DriverManager.getConnection(url,username,password);
Statement stmt = conn.createStatement();
String sql = "select * from tb_user limit 4";
ResultSet executeQuery = stmt.executeQuery(sql);
while(executeQuery.next()){
System.out.print(executeQuery.getInt(1));
System.out.println(executeQuery.getString(2));
}
}
}
启动的时候,千万不要用其他客户端连接,可能会出现端口被占用
错误如下:
java.sql.SQLException: Could not open client transport with JDBC Uri: jdbc:hive2://localhost:10000/default: java.net.ConnectException: 拒绝连接
其实上另一个客户端连接着呢,断开就好
create table wc_result
(
word string,
count int
)
> form (select explode(split(line,’ ')) word from wc) t
> insert into wc_result
> select word,conut(word) group by word;
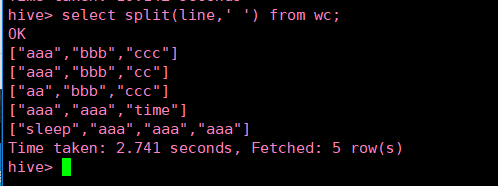
from (select explode(split(line,’ ')) word from wc) t
insert into wc_result
bc:hive2://localhost:10000/default: java.net.ConnectException: 拒绝连接
其实上另一个客户端连接着呢,断开就好
create table wc_result
> (
> word string,
> count int
> )
> > form (select explode(split(line,' ')) word from wc) t
> > insert into wc_result
> > select word,conut(word) group by word;
[外链图片转存中...(img-UShuGLRu-1565614086851)]
from (select explode(split(line,' ')) word from wc) t
insert into wc_result
select word,count(word) group by word;