Tokyo Tyrant(TTServer)介绍和安装 以及配置
Tokyo Cabinet 是日本人Mikio Hirabayashi 开发的一款DBM 数据库,该数据库读写非常快,哈希模式写入100 万条数据只需0.643 秒,读取100 万条数据只需0.773 秒,是Berkeley DB 等DBM 的几倍。
Tokyo Tyrant 是由同一作者开发的Tokyo Cabinet 数据库网络接口。它拥有Memcached兼容协议,也可以通过HTTP 协议进行数据交换。


Tokyo Tyrant 是由同一作者开发的Tokyo Cabinet 数据库网络接口。它拥有Memcached兼容协议,也可以通过HTTP 协议进行数据交换。
Tokyo Tyrant 加上Tokyo Cabinet,构成了一款支持高并发的分布式持久存储系统,对任何原有Memcached 客户端来讲,可以将Tokyo Tyrant 看成是一个Memcached,但是,它的数据是可以持久存储的。
本文记录在linux上的安装过程:
1) 安装Tokyo Cabinet
在安装Tokyo Tyrant之前,首先需要安装Tokyo Cabinet。
安装过程非常简单,标准流程如下:
gunzip tokyocabinet-1.4.45.tar.gz
tar xvf tokyocabinet-1.4.45.tar
cd tokyocabinet-1.4.45/
./configuration
make
make install
注意configuration时可能会发现缺少一些依赖包,需要自行安装。
2) 安装Tokyo Tyrant
Tokyo Cabinet安装完成之后继续安装Tokyo Tyrant。安装过程同样简单,依然是标准流程:
tar xvf tokyocabinet-1.4.45.tar
cd tokyocabinet-1.4.45/
./configuration
make
make install
3) 启动
启动tt最简单的方式,直接输入命令
ttserver
可以看到默认使用1978端口,监听所有地址。
也可以指定端口与进程文件:/home/openpf/app/tokyotyrant-1.1.41/bin/ttserver -port 9032 -pid /home/openpf/app/tokyotyrant-1.1.41/data/tt_account2/tt_9032.pid /home/openpf/app/tokyotyrant-1.1.41/data/tt_account2/tt_account2.tch
对于Tokyo Tyrant的启动, 除了直接ttserver外,还有另外一个办法就是使用Tokyo Tyrant脚本。Tokyo Tyrant脚本默认地址为/usr/local/sbin/ttservctl,提供方便实用的命令如start / stop / restart / hup,最后还是调用ttserver.
至此,tt server安装完成,可以使用了。
4) 验证
为了验证安装后的tt是否可以使用,我们可以做一些简单的验证。
Tokyo Tyrant的安装包自带了一个检测工具,进入Tokyo Tyrant解压后的目录,执行make check
可以看到有Writing Test / Reading Test / Removing Test / Random Concatenating Test / Miscellaneous Test / Wicked Writing Test / Typical Access Test / Threading Test 等多种测试方式被执行,并打印出测试结果。
5)测试
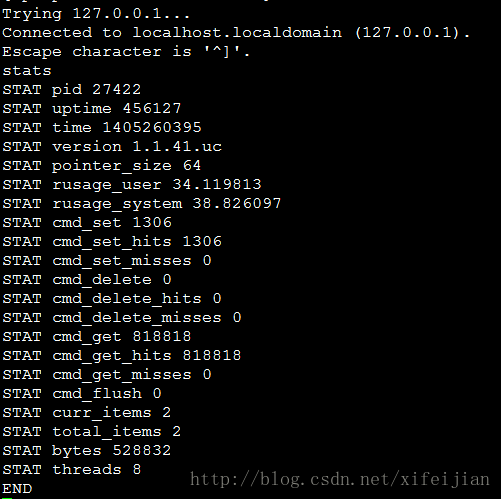
telnet 127.0.0.1 9032,如果顺利,你可以看到可以连通,键入stats然后回车,可以看到一些类似如下的状态信息。
请注意:在32位操作系统下,Tokyo Cabinet的单个数据库文件不能超过2G,而在64位操作系统下则没有这一限制。所以推荐使用64位操作系统和CPU。
启动参数介绍
ttserver命令可以启动一个数据库实例。因为数据库已经实现了Tokyo Cabinet的抽象API,所以可以在启动的时候指定数据库的配置类型。
支持的数据库类型有:
- 内存hash数据库
- 内存tree数据库
- hash数据库
- B+ tree数据库
命令通过下面的格式来使用,‘dbname’制定数据库名,如果省略,则被视作内存hash数据库。
ttserver [-host name] [-port num] [-thnum num] [-tout num] [-dmn] [-pid path] [-log path] [-ld|-le] [-ulog path] [-ulim num] [-uas] [-sidnum] [-mhost name] [-mport num] [-rts path] [-ext path] [-extpc name period] [-mask expr] [dbname]
下面来说这些参数的功能:
- 数据库名的命名方式被Tokyo Cabinet的抽象API指定。
- 如果数据库名为"*",表示内存hash数据库。
- 如果数据库名为"+"表示内存tree数据库。
- 如果数据库名为".tch",则数据库为hash数据库。
- 如果数据库名的后缀为".tcb",数据库将为B+ tree数据库。
- 如果数据库名的后缀为".tcf"。则数据库将为fixed-length数据库。
- 如果数据库名的后缀为".tct",则数据将为一个table数据库(有表的概念)。
数据库的调整参数通过数据库名的延伸来指定,通过"#"分开,每个参数通过一个参数名和值来指定,用"="隔开。
1、内存hash数据库支持"bnum", "capnum", 和 "capsiz"
2、
内存tree数据库支持"capnum" 和 "capsiz",
capnum指定记录的最大容量,capsiz指定最大的内存使用量(在内存数据库中),记录通过存储的顺序移除。
3、hash数据库支持"mode", "bnum", "apow", "fpow", "opts", "rcnum", 和 "xmsiz".
`rcnum'指定最大的缓存记录数。如果它不大于零,那么缓存记录不可用。默认不可用。
xmsiz 指定外部内存的大小。如果不大于0,内存不可用。默认是67108864,即64M。
`bnum' 指定bucket存储桶的数量。如果指定的数目不大于0,将会使用默认的数值131071.推荐数量应该在所有需要存储的记录总数的0.4-4倍
`apow' 跟一个key关联的记录数,2的N次方表示. 如果不指定,默认2^4=16.
`fpow' specifies the maximum number of elements of the free block pool by power of 2. 默认2^10=1024.
`opts' 指定选项,位或:`HDBTLARGE' 指定数据库的大小通过使用64位数组桶能够超过2G。
`HDBTDEFLATE' 指定每个记录被Deflate encoding压缩。
`HDBTBZIP' 指定每个记录被BZIP2 encoding压缩
`HDBTTCBS'指定每个记录被 TCBS encoding压缩
4、B+ tree数据库支持"mode", "lmemb", "nmemb", "bnum", "apow", "fpow", "opts", "lcnum", "ncnum", 和 "xmsiz".
5、Fixed-length 数据库 支持 "mode", "width", and "limsiz".
6、Table 数据库支持 "mode", "bnum", "apow", "fpow", "opts", "rcnum", "lcnum", "ncnum", "xmsiz", 和 "idx"
"idx"指定表的索引。
"mode"可以包含 "w" 写, "r" 读, "c" 创建, "t" 截断,"e" 无锁,和"f" 非阻塞锁。默认的的mod为"wc"。
例如如下启动参数:
./ttserver -port 9032 -pid ~/app/tokyotyrant-1.1.41/data/tt_account2/tt_9032.pid ~/app/tokyotyrant-1.1.41/data/tt_account2/tt_account2.tch
通过Memcache协议使用ttserver
通过telnet 127.0.0.1 9032 telnet连接到到启动的实例。
以下我们通过add增加key为key1和value为value1的数据。
通过get key1获取数据。(
)
|
add key1 1 0 6
value1
STORED
get key1
VALUE key1 0 6
value1
END
|
编写php脚本
| $mem=new Memcache(); $mem->connect("127.0.0.1",9032); $mem->add("key2","xifeijian"); print_r( $mem->get("key2")); echo " "; $mem->add("key3",array("value3"=>"this is xifeijian")); echo $mem->get("key3"); ?> |
运行后输出:(在服务器上直接执行php脚本,如果在浏览器中访问,效果就更加直观。)
需要注意的问题
序列化问题
如果你熟悉memcache协议,或者你曾经用php的memcache来使用ttserver,你可能马上就发现了上面的问题。
比如我们key3是一个数组,但是我们取回来的是一个序列化的字符串,没有自动反序列化,在memcached服务器上是会自动反序列化的。
通过上面的telnet示例我们可以看到,我们add key1的时候设置flag参数为1,但是我们get回来的时候,返回的flag参数是0,实际上,ttserver是没有存储flag参数的,统一的都使用0,这就造成了php使用时不会自动反序列化,当然,如果你使用压缩参数,一样会有这样的问题。
怎么样解决这个问题,如果要修改ttserver的代码实为不方便。我们完全可以在php,或者我们的客户端来控制。
比如value我们统一的都序列化后存储,取出来的时候我们再反序列化。
自增问题
| //使用ttserver自增 $mem=new Memcache(); $mem->connect("127.0.0.1",9032); var_dump($mem->increment("incr")); //结果为int(1) ?> |
| //使用memcache自增 $mem=new Memcache(); $mem->connect("127.0.0.1",9023); var_dump($mem->increment("incr")); //结果为bool(false) ?> |
我们看到同样的代码用在memcache返回了失败(false)。我们可以在php手册上看到这样一句话“
Memcache::increment()
does not create an item if it didn't exist.”但是同样的,用在ttserver上就是成功的。这一点要特别注意。
参考:http://blog.csdn.net/xifeijian/article/details/37744131