Semi-Supervised Learning with Generative Adversarial Networks
[目录]
-
- 摘要
- SGAN 模型
- 结果
- 生成结果
- 分类结果
- 结论和展望
论文下载地址
摘要
通过使判别器网络输出类别标签将GAN扩展成半监督的。在一个N类别的数据集上训练生成模型G和判别模型D。训练时,D预测输入数据属于N个类别中的哪一个,加入一个额外的类别对应G的输出。我们证明,相对与普通的GAn,此方法可以用来生成一个更有效的分类器并可以生成高质量的样本。
生成式网络G 和判别器网络作为对抗对象同时训练,G接收一个噪声向量作为输入,输出衣服图像(样本),D 接收图像(样本)并输出该图像是否是来自G 的预测。训练G 以最大化D 犯错的概率,训练D 以最小化自己犯错的概率。基于这些想法,运用卷积神经网络的级联,可以生成高质量的输出样本(Denton)。最近,一个single generator network产生了更好的样本(Radford )。文中作者试图解决一个半监督分类任务并同时学习一个生成式模型。例如,我们可以在MNIST数据集上学习一个生成式模型时训练一个图像分类器,我们把它叫做C 。运用生成式模型在半监督学习任务上已经不是第一次了(Kingma)。这里,我们想用GANs做些类似的事。我们不是第一个用GAN 做半监督学习的。CatGAN(Springenberg, J. T. Unsupervised and Semi-supervised
Learning with Categorical Generative Adversarial Net-
works. ArXiv e-prints, November 2015.)对目标函数建模时考虑到了观察样本和预测样本类别分布间的互信息。在Radford等人的文章中,D学习到的特征复用在了分类器里。后者证明了所学特征表达式的实用性,但是仍有一些不好的特性。首先,D 学习到的表达式有助于C这一事实并不意外–看起来就很合理。然而,学习到一个好的C有助于D 的性能看起来也很合理。比如,分类器C的输出值中熵比较高的那些图像更有可能来自G。如果我们在了解了此fact之后,只是简单地运用D学到的表达式来增强C,这样没什么益处。第二,运用D学习到的表达式不能同时训练C和G 。为了提高效率,我们希望能做到这一点,但有一个更重要的动机。如果改善D 能改善C,并且若改善C就 能改善D ,那么我们可以利用一系列的反馈环路,3个分量(G,C,D)迭代地使彼此更好。
文章贡献:
1,我们对GANs做了一个新的扩展,允许他们同时学习一个生成式模型和一个分类器。我们把这个扩展叫做半监督GAN 或SGAN
2,我们表明SGAN在有限数据集上比没有生成部分的基准分类器 提升了分类性能。
3,我们证明,SGAN可以显著地提升生成样本的质量并降低生成器的训练时间。
SGAN 模型
一个标准GAN 中的判别器网络D 输出 一个关于输入图像来自数据生成分布中的概率。传统方法中,这由一个以单个sigmoid单元结束的前馈网络实现,但是,也可以由一个softmax输出层实现,每个类一个单元[real,fake]。 一旦进行这样的修改后,很容易看出D 有N+1个输出单元,对应[类1,类2,…,类N ,fake]。这种情况下,D也可以作为一个C。我们将此网络叫做 D/C。
训练SGAN 与训练GAN 类似,我们只是对 从数据生成分布中抽取的小批量的一半 使用高粒度标签(higher granularity labels )。训练D/C以最小化关于给定标签的负对数似然性(negative log likehood),训练G以最大化它。见Algorithm 1。我们没有用Goodfellow等人文中第三节提到的modified objective trick。(Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B.,Warde-Farley, D., Ozair, S., Courville, A., and Bengio,Y. Generative Adversarial Networks. ArXiv e-prints,June 2014.)

结果
本文的实验: 点击这里。
借鉴了:点击这里 (还包含了更多关于实验设置的细节)
生成结果
在MNIST数据集上实验来看SGAN 是否可以比一般GAN得到更好的生成样本。用一个与Radford类似的结构训练SGAN ,训练时用了真实的MNIST标签和只有real和fake的两种标签。注意,第二种配置与通常的GAN 语义上完全相同。图1包含了GAN和SGAN 两者生成的样本。SGAN 的输出明显比GAN 的输出更清晰。这看起来eau不同的初始化和网络架构中都是正确的,但是很难对不同的超参数进行样本质量的系统评估。


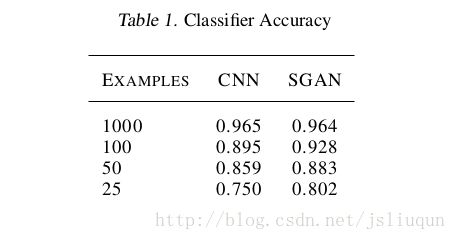
分类结果
在MNIST 上进行实验,看SGAN 的分类器部分在有限的训练集上是否可以比一个独立的分类器表现得更好。为了训练baseline(基线),我们在训练SGAN时没有更新G 。SGAN 胜过baseline,我们越缩减训练集,优势越明显。这表明forcing D 和C 共享权重提升了数据效率。表1展示了详细的性能数据。为了计算正确率,we took the maximum of the outputs not corresponding to the
FAKE label.对于每个模型,我们对学习率进行了随机搜索,并呈现出最佳结果。
结论和展望
1,共享D 和C 之间的部分权重(而不是全部),像dual autoencoder中一样(Sutskever, I., Jozefowicz, R., Gregor, K., Rezende, D., Lillicrap, T., and Vinyals, O. Towards Principled Unsupervised Learning. ArXiv e-prints, November 2015.)。这样可以让一些权重专属于判别,一些权重专属于分类。
2,让GAN 生成带类别标签的样本(Mirza)。然后要求D/C指派出是2N 个标签中的哪个[real-0,fake-0,real-1,fake-1,…,real-9,fake-9]。
3,引入一个ladder network(Rasmus)L 代替D/C,然后用来自G 的样本作为为标记的数据来训练L。