利用Darket 和YOLOV3训练自己的数据集(制作VOC)
darkenet源码:https://github.com/pjreddie/darknet.git
1. 配置Darknet
- 下载darknet源码:
git clone https://github.com/pjreddie/darknet - 进入darknet目录:
cd darknet - 如果是cpu直接make,否则需要修改Makefile,设置cuda和cudnn路径:
GPU=1
CUDNN=1
NVCC=/usr/local/cuda-8.0/bin/nvcc- 如果需要调用摄像头,还要设置
OPENCV=1,这里注意一下,如果设置了OPENCV=1,进行测试的时候可能会有错,这个我在github上看到是因为opencv版本太高导致的,可以切换为opencv2进行测试 - 下载yolov3的模型文件
wget https://pjreddie.com/media/files/yolov3.weights - 进行测试:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
2. 制作VOC数据集
这里介绍一下如何制作PASCAL VOC数据集,首先来看VOC数据集的结构:
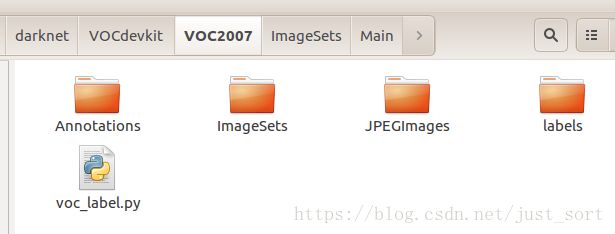
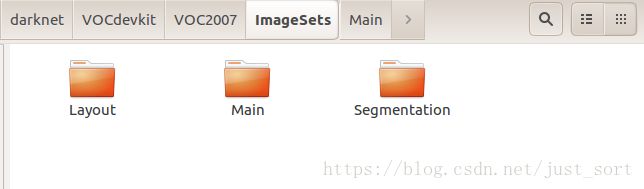
我们训练自己的数据时只需要修改Annotations、ImageSets、JPEGImages 三个文件夹,请自动忽略voc_label。接下来就可以先搞定Annotations这个文件夹,这个文件夹下存储的是每一张图片对应的boundingbox坐标,是这种格式:
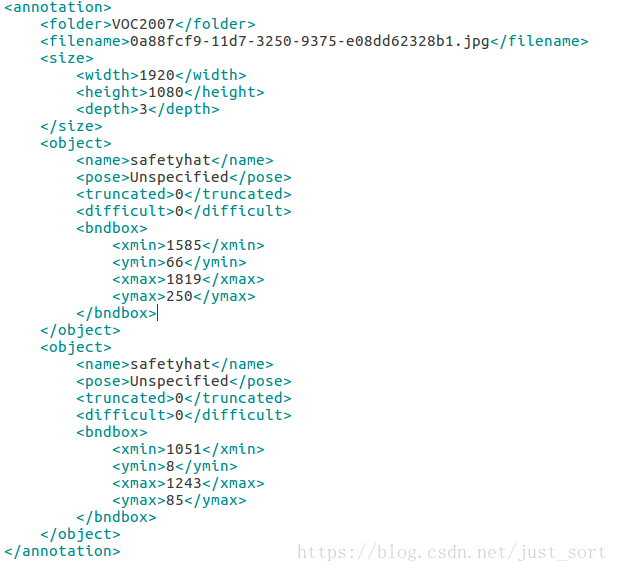

,在制作这个文件夹下的xml之前请先把训练数据集放到JPEGImages下。然后可以使用我下面的脚本生成Annotations的各个xml。
#coding=utf-8
import os, sys
import glob #用来查找特定文件名的文件
from PIL import Image
#Safety Hat图片位置
src_img_dir = "/home/zxy/PycharmProjects/Acmtest/input/train"
#Safety Hat图片的groundtruth的文件位置
src_txt_dir = "/home/zxy/PycharmProjects/Acmtest/gt/train_labels.txt"
src_xml_dir = "/home/zxy/PycharmProjects/darknet/VOCdevkit/VOC2007/Annotations"
img_Lists = glob.glob(src_img_dir + '/*.jpg')
#图片名
img_basenames = []
for item in img_Lists:
img_basenames.append(os.path.basename(item))
print(len(img_basenames))
image_names = []
for item in img_basenames:
temp1, temp2 = os.path.splitext(item)
image_names.append(temp1)
# open the crospronding txt file
now_gt = {}
fopen = open(src_txt_dir, 'r')
lines = fopen.readlines()
i = 0
for num, line in enumerate(lines):
temp1, temp2 = line.split(',')
if(len(temp2.replace('\n', '').strip())!=0):
t1, t2, t3, t4 = temp2.replace('\n', '').strip().split(' ')
# print("*%s %s %s %s*" % (t1, t2, t3, t4))
# print(temp2.replace('\n', '').strip().split(' '))
if temp1 not in now_gt.keys():
now_gt[temp1] = [[t1, t2, t3, t4]]
else:
now_gt[temp1].append([t1, t2, t3, t4])
else:
now_gt[temp1] = []
print(num , ' is processing ... ')
print(len(now_gt.keys()))
total = 0
for img in image_names:
total += 1
im = Image.open((src_img_dir+'/'+img+'.jpg'))
width, height = im.size
xml_file = open((src_xml_dir + '/' + img + '.xml'), 'w')
xml_file.write('\n' )
xml_file.write(' VOC2007 \n')
xml_file.write(' ' + str(img) + '.jpg' + '\n')
xml_file.write(' \n' )
xml_file.write(' ' + str(width) + '\n')
xml_file.write(' ' + str(height) + '\n')
xml_file.write(' 3 \n')
xml_file.write(' \n')
for img_each_label in now_gt[img+".jpg"]:
spt = img_each_label
cnt = len(img_each_label) // 4
for i in range(0, cnt):
xml_file.write(' )
xml_file.write(' ' + str("safetyhat") + '\n')
xml_file.write(' Unspecified \n')
xml_file.write(' 0 \n')
xml_file.write(' 0 \n')
xml_file.write(' \n' )
xml_file.write(' ' + str(spt[i*4+0]) + '\n')
xml_file.write(' ' + str(spt[i*4+1]) + '\n')
xml_file.write(' ' + str(spt[i*4+2]) + '\n')
xml_file.write(' ' + str(spt[i*4+3]) + '\n')
xml_file.write(' \n')
xml_file.write(' \n')
xml_file.write('')
print(total)生成了Annotation文件夹下的xml之后,就可以生成Main下的4个txt文件,这四个文件夹中存储的时上一步中xml文件的文件名。trainval和 test内容相加为所有xml文件,train和val内容相加为trainval。代码如下:
import os
import random
trainval_percent = 0.5
train_percent = 0.5
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open(txtsavepath+'/trainval.txt', 'w')
ftest = open(txtsavepath+'/test.txt', 'w')
ftrain = open(txtsavepath+'/train.txt', 'w')
fval = open(txtsavepath+'/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()最后一步是生成YOLO要用的VOC标签格式,首先下载格式转化文件:wget https://pjreddie.com/media/files/voc_label.py,gedit打开voc_label.py,进行修改
# 因为没有用到VOC2012的数据,要修改年份
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
# 修改检测的物体种
classes = ["safetyhat"]运行voc_label.py,即可完成文件转化。用train和val的数据一起用来训练,所以需要合并文件:cat 2007_train.txt 2007_val.txt > train.txt,其中voc_label.py是在这个目录下运行的:

OK啦,VOC数据集就制作完了,可以进行yolov3训练了。
3. yolov3训练数据
修改pascal数据的cfg文件,打开cfg/voc.data文件,进行如下修改:
classes= 1 # 自己数据集的类别数
train = /home/xxx/darknet/train.txt # train文件的路径
valid = /home/xxx/darknet/2007_test.txt # test文件的路径
names = /home/xxx/darknet/data/voc.names #用绝对路径
backup = backup #模型保存的文件夹 注意需要在darknet文件夹下,新建名为backup的文件夹,否则训练过程报错:Couldn’t open file: backup/yolov3-voc.backup。最后,打开data/voc.names文件,对应自己的数据集修改类别。
下载Imagenet上预先训练的权重,wget https://pjreddie.com/media/files/darknet53.conv.74
修改cfg/yolov3-voc.cfg,首先修改分类数为自己的分类数,然后注意开头部分训练的batchsize和subdivisions被注释了,如果需要自己训练的话就需要去掉,测试的时候需要改回来,最后可以修改动量参数为0.99和学习率改小,这样可以避免训练过程出现大量nan的情况,最后把每个[yolo]前的filters改成18这里怎么改具体可以看这个issule:https://github.com/pjreddie/darknet/issues/582, 改完之后就可以训练我们的模型了./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 。
4. 训练过程参数的意义
- Region xx: cfg文件中yolo-layer的索引;
- Avg IOU:当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1;
- Class: 标注物体的分类准确率,越大越好,期望数值为1;
- obj: 越大越好,期望数值为1;
- No obj: 越小越好;
- .5R: 以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本
- 0.75R: 以IOU=0.75为阈值时候的recall;
- count:正样本数目。
- 待补充ing
Loaded: 0.000034 seconds
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000009, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: 0.790078, Class: 0.996943, Obj: 0.777700, No Obj: 0.001513, .5R: 1.000000, .75R: 0.833333, count: 6
Region 106 Avg IOU: 0.701132, Class: 0.998590, Obj: 0.710799, No Obj: 0.000800, .5R: 0.857143, .75R: 0.571429, count: 14
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000007, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: 0.688576, Class: 0.998360, Obj: 0.855777, No Obj: 0.000512, .5R: 1.000000, .75R: 0.500000, count: 2
Region 106 Avg IOU: 0.680646, Class: 0.998413, Obj: 0.675553, No Obj: 0.000405, .5R: 0.857143, .75R: 0.428571, count: 7
Region 82 Avg IOU: 0.478347, Class: 0.999972, Obj: 0.999957, No Obj: 0.000578, .5R: 0.000000, .75R: 0.000000, count: 1
Region 94 Avg IOU: 0.901106, Class: 0.999994, Obj: 0.999893, No Obj: 0.000308, .5R: 1.000000, .75R: 1.000000, count: 1
Region 106 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000025, .5R: -nan, .75R: -nan, count: 0
Region 82 Avg IOU: 0.724108, Class: 0.988430, Obj: 0.765983, No Obj: 0.003308, .5R: 1.000000, .75R: 0.400000, count: 5
Region 94 Avg IOU: 0.752382, Class: 0.996165, Obj: 0.848303, No Obj: 0.002020, .5R: 1.000000, .75R: 0.500000, count: 8
Region 106 Avg IOU: 0.652267, Class: 0.998596, Obj: 0.646115, No Obj: 0.000728, .5R: 0.818182, .75R: 0.545455, count: 11
Region 82 Avg IOU: 0.755896, Class: 0.999879, Obj: 0.999514, No Obj: 0.001232, .5R: 1.000000, .75R: 1.000000, count: 1
Region 94 Avg IOU: 0.749224, Class: 0.999670, Obj: 0.988916, No Obj: 0.000441, .5R: 1.000000, .75R: 0.500000, count: 2
Region 106 Avg IOU: 0.601608, Class: 0.999661, Obj: 0.714591, No Obj: 0.000147, .5R: 0.750000, .75R: 0.250000, count: 4
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000011, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: 0.797704, Class: 0.997323, Obj: 0.910817, No Obj: 0.001006, .5R: 1.000000, .75R: 0.750000, count: 4
Region 106 Avg IOU: 0.727626, Class: 0.998225, Obj: 0.798596, No Obj: 0.000121, .5R: 1.000000, .75R: 0.500000, count: 2
Region 82 Avg IOU: 0.669070, Class: 0.998607, Obj: 0.958330, No Obj: 0.001297, .5R: 1.000000, .75R: 0.000000, count: 2
Region 94 Avg IOU: 0.832890, Class: 0.999755, Obj: 0.965164, No Obj: 0.000829, .5R: 1.000000, .75R: 1.000000, count: 1
Region 106 Avg IOU: 0.613751, Class: 0.999541, Obj: 0.791765, No Obj: 0.000554, .5R: 0.833333, .75R: 0.333333, count: 12
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000007, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: 0.816189, Class: 0.999966, Obj: 0.999738, No Obj: 0.000673, .5R: 1.000000, .75R: 1.000000, count: 2
Region 106 Avg IOU: 0.756419, Class: 0.999139, Obj: 0.891591, No Obj: 0.000712, .5R: 1.000000, .75R: 0.500000, count: 12
12010: 0.454202, 0.404766 avg, 0.000100 rate, 2.424004 seconds, 768640 images
Loaded: 0.000034 seconds这断代码展示了一个批次(batch),批次大小的划分根据yolov3-voc.cfg的subdivisions参数。在我使用的 .cfg 文件中 batch =256,subdivision = 8,所以在训练输出中,训练迭代包含了32组,每组又包含了8张图片,跟设定的batch和subdivision的值一致。
- 批输出 针对上面的bacth的最后一行输出来说,12010代表当前训练的迭代次数,0.454202代表总体的loss,0.404766 avg代表平均损失,这个值越低越好,一般来说一旦这个数值低于0.060730 avg就可以终止训练了。0.0001代表当前的学习率,2.424004 seconds代表当前批次花费的总时间。768640代表3002*256代表当前训练的图片总数。
5. yolov3模型的批量测试和位置输出
预测时的命令为:./darknet detect cfg/yolov3-voc.cfg yolov3-voc_900.weights test3.jpg ,需要批量测试需要修改yolo.c文件后重新编译,修改后的代码为:
void validate_yolo(char *cfgfile, char *weightfile)
{
network net = parse_network_cfg(cfgfile);
if(weightfile){
load_weights(&net, weightfile);
}
set_batch_network(&net, 1);
fprintf(stderr, "Learning Rate: %g, Momentum: %g, Decay: %g\n", net.learning_rate, net.momentum, net.decay);
srand(time(0));
char *base = "results/comp4_det_test_";
//list *plist = get_paths("data/voc.2007.test"); # 生成过程见官网,表示需要test的文件的路径
list *plist = get_paths("/home/pjreddie/data/voc/2007_test.txt"); # .txt文件为需要test的文件的绝对路径,和train.txt是相同的形式
//list *plist = get_paths("data/voc.2012.test");
char **paths = (char **)list_to_array(plist);
layer l = net.layers[net.n-1];
int classes = l.classes;
int square = l.sqrt;
int side = l.side;
int j;
FILE **fps = calloc(classes, sizeof(FILE *));
for(j = 0; j < classes; ++j){
char buff[1024];
snprintf(buff, 1024, "%s%s.txt", base, voc_names[j]);
fps[j] = fopen(buff, "w");
}
box *boxes = calloc(side*side*l.n, sizeof(box));
float **probs = calloc(side*side*l.n, sizeof(float *));
for(j = 0; j < side*side*l.n; ++j) probs[j] = calloc(classes, sizeof(float *));
int m = plist->size;
int i=0;
int t;
float thresh = .001;
int nms = 1;
float iou_thresh = .5;
int nthreads = 2;
image *val = calloc(nthreads, sizeof(image));
image *val_resized = calloc(nthreads, sizeof(image));
image *buf = calloc(nthreads, sizeof(image));
image *buf_resized = calloc(nthreads, sizeof(image));
pthread_t *thr = calloc(nthreads, sizeof(pthread_t));
load_args args = {0};
args.w = net.w;
args.h = net.h;
args.type = IMAGE_DATA;
for(t = 0; t < nthreads; ++t){
args.path = paths[i+t];
args.im = &buf[t];
args.resized = &buf_resized[t];
thr[t] = load_data_in_thread(args);
}
time_t start = time(0);
for(i = nthreads; i < m+nthreads; i += nthreads){
fprintf(stderr, "%d\n", i);
for(t = 0; t < nthreads && i+t-nthreads < m; ++t){
pthread_join(thr[t], 0);
val[t] = buf[t];
val_resized[t] = buf_resized[t];
}
for(t = 0; t < nthreads && i+t < m; ++t){
args.path = paths[i+t];
args.im = &buf[t];
args.resized = &buf_resized[t];
thr[t] = load_data_in_thread(args);
}
for(t = 0; t < nthreads && i+t-nthreads < m; ++t){
char *path = paths[i+t-nthreads];
char *id = basecfg(path);
float *X = val_resized[t].data;
float *predictions = network_predict(net, X);
int w = val[t].w;
int h = val[t].h;
convert_yolo_detections(predictions, classes, l.n, square, side, w, h, thresh, probs, boxes, 0);
if (nms) do_nms_sort(boxes, probs, side*side*l.n, classes, iou_thresh);
print_yolo_detections(fps, id, boxes, probs, side*side*l.n, classes, w, h);
free(id);
free_image(val[t]);
free_image(val_resized[t]);
}
}
fprintf(stderr, "Total Detection Time: %f Seconds\n", (double)(time(0) - start));
}
void print_yolo_detections(FILE **fps, char *id, box *boxes, float **probs, int total, int classes, int w, int h)
{
int i, j;
for(i = 0; i < total; ++i){
float xmin = boxes[i].x - boxes[i].w/2.;
float xmax = boxes[i].x + boxes[i].w/2.;
float ymin = boxes[i].y - boxes[i].h/2.;
float ymax = boxes[i].y + boxes[i].h/2.;
if (xmin < 0) xmin = 0;
if (ymin < 0) ymin = 0;
if (xmax > w) xmax = w;
if (ymax > h) ymax = h;
for(j = 0; j < classes; ++j){
if (probs[i][j]) fprintf(fps[j], "%s %f %f %f %f %f\n", id, probs[i][j], xmin, ymin, xmax, ymax);
}
}
}然后执行:./darknet yolo valid cfg/yolov3-voc.cfg yolov3-voc_900.weights就可以在批量生成测试数据集的结果了。
6. 调参遇到的trick
- CUDA: out of memory 以及 resizing 问题?显存不够,调小batch,关闭多尺度训练:random = 0。
- YOLOV3训练出现nan的问题?在显存允许的情况下,可适当增加batch大小,可以一定程度上减少NAN的出现,动量参数可以调为0.99
- YOLOv3打印的参数都是什么含义?详见yolo_layer.c文件的forward_yolo_layer函数。
printf("Region %d Avg IOU: %f, Class: %f, Obj: %f, No Obj: %f, .5R: %f, .75R: %f, count: %d\n", net.index, avg_iou/count, avg_cat/class_count, avg_obj/count, avg_anyobj/(l.w*l.h*l.n*l.batch), recall/count, recall75/count, count);刚开始迭代,由于没有预测出相应的目标,所以查全率较低【.5R,0.75R】,会出现大面积为0的情况,这个是正常的。
- ing