Facebook 推荐算法
https://code.fb.com/core-data/recommending-items-to-more-than-a-billion-people/
Recommending items to more than a billion people
网络上数据的增长使得在完整数据集上使用许多机器学习算法变得更加困难。特别是对于个性化问题,数据采样通常不是一种选择,因此有必要创新分布式算法设计,以便我们可以扩展到这些不断增长的数据集。
协同过滤(CF)是重要的应用领域之一。 CF是一种推荐的系统技术,可帮助人们发现与其最相关的项目。在Facebook上,这可能包括页面,群组,活动,游戏等。 CF基于这样的想法,即最佳推荐来自具有相似品味的人。换句话说,它使用志同道合的人的历史项目评级来预测某人如何评估项目。
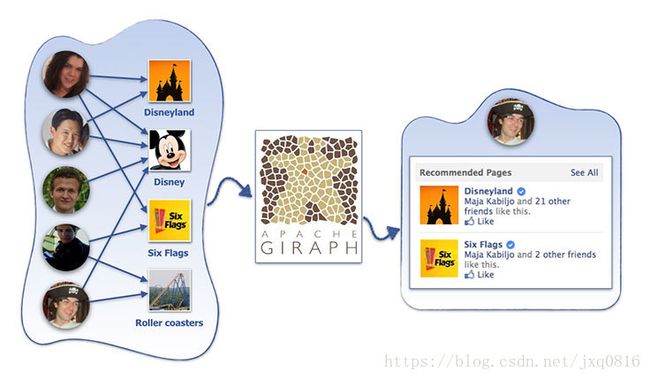
CF和Facebook规模
Facebook的CF平均数据集拥有1000亿个评级,超过10亿用户和数百万个项目。相比之下,着名的Netflix Prize推荐竞赛包含一个拥有1亿个评级,480,000个用户和17,770个电影(项目)的大型工业数据集。从那以后,该领域有了更多的发展,但我们读到的最大数量至少比我们处理的数字小两个数量级。
我们面临的挑战是设计一个分布式算法,该算法将扩展到这些海量数据集以及如何克服由于我们数据的某些属性引起的问题(例如偏斜的项目程度分布,或隐式参与信号而不是评级)。
正如我们将在下面讨论的那样,现有解决方案中使用的方法无法有效处理我们的数据大小。简而言之,我们需要一个新的解决方案。我们已经写过Apache Giraph,一个用于分布式迭代和图形处理的强大平台,以及我们为满足我们的需求所做的工作。我们还编写了一个用于图形分区的开发应用程序。 Giraph在大量数据集上运行良好,易于扩展,我们在开发高性能应用程序方面拥有丰富的经验。因此,Giraph是我们解决这个问题的明智选择。
矩阵分解
CF的常用方法是通过矩阵分解,其中我们将问题视为具有一组用户和一组项,以及表示已知用户对项进行评级的非常稀疏的矩阵。我们想要预测此矩阵中的缺失值。为此,我们将每个用户和每个项目表示为潜在特征的向量,使得这些向量的点积与项目的已知用户评级紧密匹配。期望对项目的未知用户评级也可以通过相应特征向量的点积来近似。我们想要最小化的最简单的目标函数形式是:
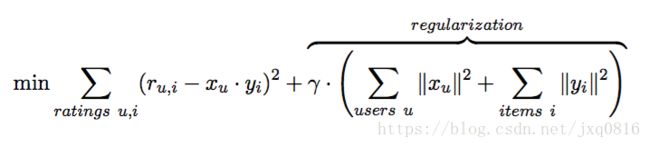
这里,r是已知的用户到项目评级,x和y是我们试图找到的用户和项目特征向量。由于存在许多自由参数,我们需要正则化部分来防止过度拟合和数值问题,其中γ是正则化因子。
目前在合理的时间内找到上述公式的最优解是不可行的,但是存在从随机特征向量开始并逐渐改进解的迭代方法。经过一些迭代后,特征向量的变化变得非常小,并且达到了收敛。有两种常用的迭代方法。
随机梯度下降优化
随机梯度下降(SGD)优化在许多其他问题中成功实施。该算法以随机顺序循环遍历训练数据中的所有评级,并且对于每个已知评级r,它进行预测r *(基于向量x和y的点积)并计算预测误差e。然后我们通过在梯度的相反方向上移动它们来修改x和y,从而为x和y的每个特征产生某些更新公式。
交替最小二乘
当有两个因变量(在我们的例子中,向量x和y)时,交替最小二乘(ALS)是与非线性回归模型一起使用的另一种方法。该算法固定一个参数(用户向量x),同时通过最小化二次形式最优地求解另一个(项向量y)。该算法在固定用户向量和更新项目向量之间交替,并固定项目向量和更新用户向量,直到满足收敛标准。
标准方法和问题
为了以分布式方式有效地解决上述公式,我们首先研究了与Giraph设计相似的系统如何做到(使用消息传递而不是map / reduce)。标准方法对应于将用户和项目都作为图形的顶点,边缘表示已知的评级。然后,SGD / ALS的迭代将在图的所有边缘发送用户和/或项目特征向量并进行本地更新。

此解决方案存在一些问题:
大量的网络流量:这是所有分布式矩阵分解算法的主要瓶颈。由于我们在图形的每个边缘发送一个特征向量,因此在一次迭代中通过线路发送的数据量与#Ratings * #Features成比例(在我们使用的文本中此处和后面的#作为'number of'的表示法) 。对于1000亿次评级和100次双重功能,每次迭代可产生80 TB的网络流量。在这里,我们假设用户和项目是随机分布的,我们忽略了一些评级可以生活在同一个工人身上的事实(平均而言,这应该乘以因子1 - (1 / #Workers))。请注意,由于具有较大度数的项目,智能分区无法大量减少网络流量,并且无法解决我们的问题。
我们的数据集中的一些项目非常受欢迎,因此项目度分布高度倾斜:这可能导致内存问题 - 每个项目都接收度* #Features数据量。例如,如果一个项目具有1亿个已知评级并且使用了100个双重功能,则仅此项目将接收80 GB的数据。大学位项目也会导致处理瓶颈(因为每个顶点都是原子处理的),每个人都会等待几个最大程度的项目完成。
这并没有完全在原始公式中实现SGD:每个顶点都使用它在迭代开始时收到的特征向量,而不是它们的最新版本。例如,假设项目A对用户B和C有评级。在顺序解决方案中,我们首先更新A和B,获得A'和B',然后更新A'和C.使用此解决方案,B和C将使用A进行更新,A是迭代开始时项目的特征向量。 (这是通过一些无锁并行执行算法实现的,可以减慢收敛速度。)
我们的解决方案 - 旋转混合方法
主要问题是在每次迭代中发送所有更新,因此我们需要一种新技术来组合这些更新并发送更少的数据。首先,我们尝试利用聚合器并使用它们来分发项目数据,但我们尝试用于组合项目特征向量的部分更新的公式都没有奏效。
我们最终提出了一种方法,要求我们通过工人到工作人员的消息传递来扩展Giraph框架。用户仍然是图表的顶点,但项目在#Workers不相交的部分中分区,每个部分都存储在其中一个工作人员的全局数据中。我们将所有工人放在一个圆圈中,并在每次超级步骤后按顺时针方向旋转项目,方法是将包含每个工人的项目的工人到工人的消息发送到该行中的下一个工作人员。

因此,在每个超级步骤中,我们处理工作人员当前项目的工作者用户评级的一部分,因此在#Workers超越之后处理所有评级。让我们分析以前解决方案遇到的问题:
网络流量数量:对于SGD,在一次迭代中通过线路发送的数据量与#Items * #Features * #Workers成比例,并且它不再取决于已知级别的数量。对于1000万个项目,100个双功能和50个工作人员,这总共带来了400 GB,比标准方法小20倍。因此,对于#Workers <= #Ratings / #Items,旋转方法表现更好,即如果工人数量小于平均项目程度。在我们使用的所有数据集中,我们忽略较小的项目,因为它们不代表好的建议,可能只是噪音,因此平均项目非常大。我们将在下面讨论ALS。
倾斜项目学位:这不再是问题 - 用户顶点是唯一正在处理的项目,项目从不保存有关其用户评级的信息。
SGD计算:在顺序解决方案中这是相同的,因为在任何时间点只有一个版本的特征向量,而不是将它们的副本发送给许多工作者并基于此进行更新。
使用ALS进行计算比使用SGD更棘手,因为我们需要所有项目/用户特征向量才能更新用户/项目。事实上,ALS的更新方式是我们正在求解A * X = B类型的矩阵方程,其中A是#Features x #Features矩阵,B是1 x #Features向量,A和B是/用户计算的项目特征向量。形成项目/用户的所有已知评级。因此,在更新项目时,我们可以旋转A和B而不是仅旋转它们的特征向量,在每个#Workers超级步骤中更新它们,最后计算新的特征向量。这将增加#Items *#Features2 * #Workers的网络流量。根据所有数据维度之间的比率,这比某些项目的标准方法更好,但对某些项目则不然。
这就是为什么我们的旋转方法和标准方法的融合提供了一个很好的解决方案。通过在某种程度上查看项目,在标准方法中,与之关联的网络流量是度* #Features,并且使用我们的轮换方法,它是#Workers *#Features2。我们仍然会使用标准方法更新<#Workers * #Features degree项目,我们将对所有大型项目使用旋转方法来显着提高性能。例如,对于100个双重功能和50个工作人员,选择方法的项目学位限制大约为5,000。
为了求解矩阵方程A * X = B,我们需要找到逆A-1。我们使用开源库JBLAS,它具有最有效的矩阵逆实现。
由于SGD和ALS共享相同的优化公式,因此也可以组合这些算法。 ALS比SGD计算复杂。我们提供了一个选项来组合一些SGD迭代,然后是ALS的单次迭代。对于某些数据集,这已被证明对离线度量(例如,均方根误差或平均平均水平)有帮助。
我们遇到过大学项目的数字问题。有几种方法可以解决这个问题(忽略这些项目或对它们进行抽样),但我们正在使用基于项目和用户级别的正则化。这使用户和项目向量的值保持在一定的值范围内。
评估数据和参数
为了衡量建议的质量,我们可以使用现有数据的样本在运行实际A / B测试之前计算一些离线指标,这表明我们的估计与实际用户偏好之间的差异。这两种算法都有许多超参数,可以通过交叉验证进行调整以获得最佳建议。我们还提供其他选项,例如添加用户和项目偏差。
输入评级可以清楚地分为两个数据集(培训和测试)。这在测试数据包含所有训练实例之后的时间间隔内的所有用户操作的情况下非常有用。否则,为了构建测试数据,我们随机选择每个用户T = 1并将它们与训练分开。
在算法期间,对于一定百分比的用户,我们对所有未评级的项目(即,不在训练集中的项目)进行排名,并在排名的推荐列表中观察训练和测试项目的位置。然后我们可以评估以下指标:平均排名(排名列表中的位置,所有测试项目的平均值),位置精度1/10/100,所有测试项目的平均准确度(MAP)等。此外,我们计算均方根误差(RMSE),它放大了绝对值的贡献。
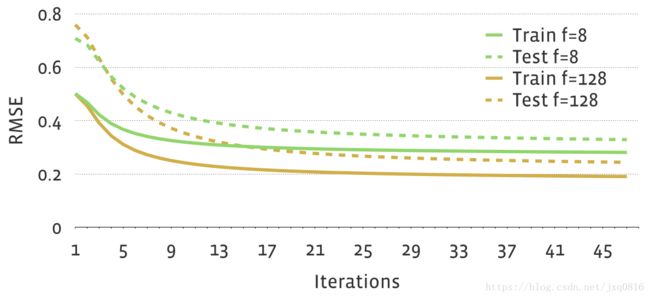
物品推荐计算
为了获得所有用户的实际建议,我们需要找到每个用户具有最高预测评级的项目。在处理庞大的数据集时,即使我们将问题分发给更多的工作人员,检查每个(用户,项目)对的点积也变得不可行。我们需要一种更快捷的方法来为每个用户找到前K个推荐值,或者对它有一个很好的近似。
一种可能的解决方案是使用球树数据结构来保存我们的项目向量。球树是二叉树,其中叶子包含项目向量的一些子集,并且每个内部节点定义围绕其子树内的所有向量的球。对于查询向量和球内的任何向量,使用点积上限的公式,我们可以进行贪婪的树遍历,首先进入更有希望的分支,并且修剪不能包含解决方案的子树比我们更好已经找到了。这种方法显示比查看每对方法快10-100倍,因此在合理的时间内搜索我们数据集的建议。我们还添加了一个选项,以便在查找最佳建议时允许指定的错误,从而进一步加快计算速度。
可以近似解决问题的另一种方法是通过基于项目特征向量聚类项目 - 这减少了查找顶级群集推荐的问题,然后基于这些顶级群集提取实际项目。这种方法加速了计算,同时基于实验结果略微降低了推荐的质量。另一方面,群集中的项目是相似的,我们可以通过从每个群集中获取有限数量的项目来获得各种建议。请注意,我们在Giraph之上也有k-means聚类实现,并且在计算中合并这一步骤非常简单。
与MLlib比较
Spark MLlib是一个非常流行的机器学习库,包含该领域领先的开源实现之一。 2014年7月,Databricks团队在Spark上发布了他们的ALS实施的性能数据。实验是在亚马逊评论数据集的缩放副本上进行的,该数据集最初包含3500万个评级并且进行了五次迭代。
在下图中,我们将我们的旋转混合方法(我们在Giraph中实现)与标准方法(在Spark MLlib中实现,包括一些额外的优化,例如最多向机器发送一次特征向量),相同的数据进行了比较组。由于硬件差异(我们每台机器的处理能力大约是两倍),为了进行公平的比较,我们考虑了总CPU分钟数。旋转混合解决方案快了约10倍。
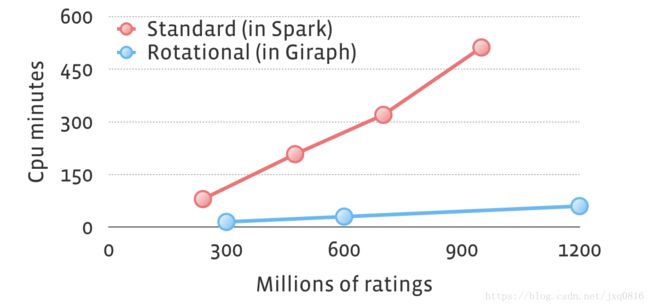
此外,使用标准方法进行实验的最大数据集具有35亿个评级。通过旋转混合方法,我们可以轻松处理超过1000亿的额定值。请注意,两者的结果质量相同,并且所有性能和可伸缩性增益都来自不同的数据布局和减少的网络流量.Facebook用例和隐式反馈
我们将此算法用于Facebook的多个应用程序,例如用于推荐您可能喜欢的页面或您应该加入的群组。如前所述,我们的数据集由超过10亿用户组成,通常有数千万个项目。实际上有更多的页面或组,但我们仅限于通过一定质量阈值的项目 - 最简单的版本是项目度数大于100.(有趣的是注意:另一方面,我们有一些非常大型页面 - Facebook“每个手机的Facebook”页面实际上被Facebook当前每月活跃用户的一半所喜欢。)
我们的第一次迭代包括页面喜欢/组连接作为正信号。 Facebook上的负面信号并不常见(负面信号包括不喜欢页面或在一段时间后离开一个组)。这也可能实际上并不意味着用户对该项目有负面反馈;相反,他或她可能对该主题或接收更新失去了兴趣。为了获得好的建议,非常需要从集合中的未评级对添加负项。以前的方法包括从未评级项目中随机挑选负面训练样本(导致有偏见的非最佳解决方案)或将所有未知评级视为负面,这极大地增加了算法的复杂性。在这里,我们通过考虑用户和项目程度(根据项目程度分布添加与用户程度成比例的负面评级)实施添加随机负面评级,并且权衡负评级小于正评级,因为我们未能学到好处采用均匀随机抽样方法的模型。
另一方面,我们有来自用户的隐式反馈(用户是否正在主动查看页面,喜欢或评论组中的帖子)。我们还为隐式反馈数据集实现了一个众所周知的基于ALS的算法。这种方法不是直接对评级矩阵进行建模,而是将数据视为二元偏好和置信度值的组合。然后,评级与观察到的用户偏好的置信水平相关,而不是与项目的明确评级相关。
运行矩阵分解算法后,我们有另一个Giraph工作,实际计算所有用户的最佳建议。
以下代码显示了使用我们的框架,调整参数和插入不同数据集是多么容易:
CFTrain(
ratings=CFRatings(table='cf_ratings'),
feature_vectors=CFVectors(table='cf_feature_vectors'),
features_size=128,
iterations=100,
regularization_factor=0.02,
num_workers=5,
)
CFRecommend(
ratings=CFRatings(table='cf_ratings'),
feature_vectors=CFVectors(table='cf_feature_vectors'),
recommendations=CFRecommendations(table='cf_recommendations'),
num_recommendations=50,
num_workers=10,
)
此外,可以通过扩展SGD或ALS计算简单地实现其他目标函数(例如秩优化或相邻模型)。
可扩展的CF.
推荐系统正在成为预测用户偏好的重要工具。我们的矩阵分解和计算顶级用户推荐框架能够有效处理Facebook拥有1000亿次评级的海量数据集。它易于使用,并可与其他方法一起使用。
我们正在考虑许多改进和算法,包括:
结合社交图和用户连接以提供更好的建议集
从以前的模型开始而不是随机初始化,用于反复学习
具有交叉验证的自动参数拟合,用于优化给定数据集的不同度量
在旋转期间尝试更好的分区和跳过不需要某些项目数据的机器
我们正积极致力于建立Giraph之上的建议和许多其他应用程序,因此请继续关注该领域中更多令人兴奋的功能和开发。