PLDA源代码分析(1)-PLDA_Train
本博文转载于http://write.blog.csdn.net/postedit?ref=toolbar
说明:此处的LDA对应于Linear Discriminant Analysis,PLDA即对应于Probabilistic LDA. 该代码对应的文章为ICCV2007 paper Probabilistic Linear Discriminant Analysis for Inferences About Identity,源代码可以从 Prince Vision Lab处下载。虽然源码虽然不长结构比较清楚,但是运用到了一定的矩阵知识,所以对源码分析稍作分析。
1、PLDA 训练(Training)源码分析
2、PLDA识别(Recognition)源码分析
3、PLDA相关应用
基本问题
PLDA的基本模型如下:
Learning LIV Models给出数据集
 ,利用EM算法求得参数
,利用EM算法求得参数
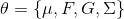 :
:
E-Step:计算两个期望:
其中:


M-Step:计算更新三个参数:
其中均值不变,Diag操作是取矩阵对角元素构成一个对角阵,B和
 分别如下所示:
分别如下所示:
分别如下所示:
PLDA_Train.m共有三个函数,其中PLDA_Train是EM算法的主函数,getExpectedValuePLDA是计算期望的子函数,trainPCA是初始化F的PCA过程。
PLDA_Train
输入参数:
- Data:d*n的训练数据,d为样本维数,n为样本个数。
- ImageID:n*m的一个稀疏矩阵,m表示有多少个人,若ImageID[i][j]=1那么表示第i个样本来自第j个人。
- N_ITER:EM算法迭代次数
- N_F,N_G:因子个数,即矩阵F和G的第二维(其第一维是d)
相关初始化:
- 去均值,后面计算PCA,E-Step,M-Step就不用再减去均值
- meanVec = mean(Data, 2);%d*1维向量,存每一维特征均值
- N_DATA = size(Data, 2);
- Data = double(Data) - repmat(meanVec, 1, N_DATA);
- EM算法初始化
- OBS_DIM = size(Data, 1); % 样本特征维数d
- G = randn(OBS_DIM, N_G); %G随即初始化
- %Sigma是对角矩阵,初始化为一个列向量来表示,方便存储和提高运算效率。
- Sigma = 0.01 .* ones(OBS_DIM, 1);
- clusterMeans = (Data * ImageID) * (diag(1 ./ (sum(ImageID))));
- F = trainPCA(clusterMeans);
- F = F(:, 1:N_F);
EM算法迭代过程:
- for cIter = 1 : N_ITER
- %E-Step
- %M-Step
- end
- 更新
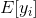 和
和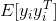 ,这里Eh是
,这里Eh是 和EhhSum是
和EhhSum是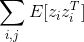 ,二者均为矩阵。
,二者均为矩阵。
- [Eh EhhSum] = getExpectedValuesPLDA(F, G, Sigma, Data, ImageID);
- 更新B
- xhSum = zeros(size(Data,1), size(Eh, 1));
- for cData = 1 : N_DATA
- xhSum = xhSum + Data(:, cData) * Eh(:, cData)';
- end;
- FGEst = xhSum * inv(EhhSum) ;
- 更新
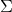
若Data如下所示:

那么mean(Data*Data',2)如下所示:
后面一部分也类似。
- Sigma = mean(Data .* Data - (FGEst * Eh) .* Data,2);
- 根据B的定义取得F和G
- F = FGEst(:, 1 : N_F);
- G = FGEst(:, N_F + 1 : end);
getExpectedValuesPLDA
主要思想:
该子程序主要计算
和
,二者均为矩阵。前半部分预先计算 即样本个数为repeatValues(repeatValues为每个人的样本数目)的指,后半部分具体计算这两个矩阵。
即样本个数为repeatValues(repeatValues为每个人的样本数目)的指,后半部分具体计算这两个矩阵。
预处理打表
计算表的大小,如PLDA_Train_Demo.m中repeatValues=[2,3,4]共三种情况,那么nRepeatValues=3为循环的个数,invTermsAll存储
的值。
- repeatValues = unique(sum(ImageID));
- nRepeatValues = length(repeatValues);
- invTermsAll = cell(nRepeatValues, 1);
- for cRepeatVal = 1 : nRepeatValues
- thisRepVal = repeatValues(cRepeatVal);
- ...
- invTermsAll{repeatValues(cRepeatVal)} = invTerm;
- end
对于每个thisRepVal,易知
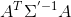 是一个 (N_HID_DIM+thisRepVal*N_HID_DIM_NOISE)* (N_HID_DIM+thisRepVal*N_HID_DIM_NOISE)大小的矩阵如下:
是一个 (N_HID_DIM+thisRepVal*N_HID_DIM_NOISE)* (N_HID_DIM+thisRepVal*N_HID_DIM_NOISE)大小的矩阵如下:
那些下面代码段就是分块对矩阵进行赋值,其中左上角矩阵维数是H_HID_DIM*H_HID_DIM,其他矩阵维数是N_HID_DIM_NOISE*N_HID_DIM_NOISE。
- ATISigA(1:N_HID_DIM,1:N_HID_DIM) = thisRepVal*weightedF'*F;
- for cMat = 1:thisRepVal
- ATISigA(N_HID_DIM+(cMat-1)*N_HID_DIM_NOISE+1:N_HID_DIM+cMat*N_HID_DIM_NOISE,1:N_HID_DIM) = weightedG'*F;
- ATISigA(1:N_HID_DIM,N_HID_DIM+(cMat-1)*N_HID_DIM_NOISE+1:N_HID_DIM+cMat*N_HID_DIM_NOISE) = weightedF'*G;
- ATISigA(N_HID_DIM+(cMat-1)*N_HID_DIM_NOISE+1:N_HID_DIM+cMat*N_HID_DIM_NOISE,...
- N_HID_DIM+(cMat-1)*N_HID_DIM_NOISE+1:N_HID_DIM+cMat*N_HID_DIM_NOISE) = weightedG'*G;
- end;
有了
计算期望值
外循环是每个人,内循环计算特定人所有样本的期望值,更新期望和。- for cInd = 1 : N_INDIV
- for cFaces = 1 : nFaces
- Eh(:,thisImIndex(cFaces)) = thisEh(thisIndex);
- EhhSum=EhhSum+thisEhh(thisIndex,thisIndex);
- end
- end
- nFaces = full(sum(ImageID(:,cInd)));
- thisImIndex = find(ImageID(:,cInd));
- dataAll = x(:,thisImIndex).*repmat(1./Sigma,1,nFaces);
- ATISigX = zeros(N_HID_DIM+nFaces*N_HID_DIM_NOISE,1);
- ATISigX(1:N_HID_DIM,:) = sum(F'*dataAll,2);
- for cIm = 1 : nFaces
- ATISigX(N_HID_DIM+(cIm-1)*N_HID_DIM_NOISE+1:N_HID_DIM+cIm*N_HID_DIM_NOISE,:) = G'*dataAll(:,cIm);
- end;
- thisEh = invTerm*ATISigX;
- thisEhh = invTerm+thisEh*thisEh';
最后就是for循环更新
- for cFaces = 1 : nFaces
- thisIndex = [1:N_HID_DIM N_HID_DIM+(cFaces-1)*N_HID_DIM_NOISE+1:N_HID_DIM+cFaces*N_HID_DIM_NOISE];
- Eh(:,thisImIndex(cFaces)) = thisEh(thisIndex);
- EhhSum=EhhSum+thisEhh(thisIndex,thisIndex);
- end
trainPCA
PCA过程,详见 SVD和PCA