华为在深度学习平台上的优化实践
“Kubernetes Meetup 中国 2017”——北京站3.18落幕啦!本次分享嘉宾彭靖田来自华为,他的分享题目是《华为在深度学习平台上的优化实践》。实录将从深度学习平台的架构、优化等几个方面,介绍华为在深度学习平台上的实践。本文由才云科技供稿。
彭靖田:华为中软大数据工程师。2016年毕业于浙大竺可桢学院求是科学班,加州大学圣迭戈分校访问学者。毕业加入华为后,主要从事深度学习平台的设计和研发工作,专注开源社区。先后在 TensorFlow 社区独立贡献了 Mnist 分布式模型、VariableAsGradients、InitWithoutInitializer 等特性。同时,从 Kubernetes v1.3开始,参与维护 Kubernetes 社区 CentOS 平台相关脚本。
今天第一部分主要讲华为在深度学习方面的应用需求以及华为在深度学习平台遇到的一些挑战。第二部分是讲华为深度学习平台的架构、优化以及经验。

这两年,深度学习取得了突破性发展。尤其是在语音识别和图像识别这两方面。
在 ImageNet 图像分类任务上,AI 现在的错误率2.9%已经超越人类5%了。去年的 AlphaGo 又一次在围棋领域打败了人类顶尖高手李世石。今年年初的时候,AlphaGo 2.0 Master 大败中日韩三国高手,围棋领域也被 AI 突破。最近深度学习还被应用在在图像风格迁移 Prisma 和皮肤癌诊断。

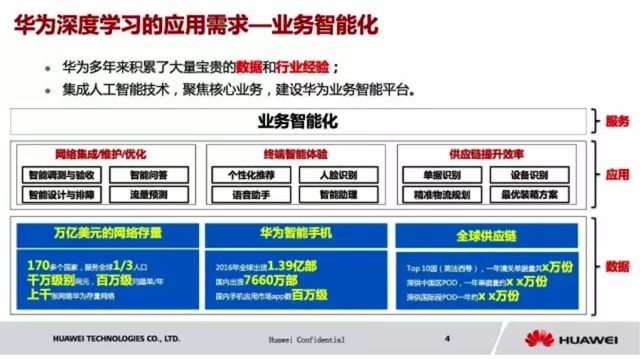
那么华为面临的是一个怎样的深度学习应用需求呢?答案是,要做业务的智能化。
华为多年来积累了大量宝贵的数据和行业经验。虽然大家这么多年来接触的可能就是华为手机,华为终端,华为路由器,但是其实华为主营的是运营商业务。大家可以看到,华为有一个达到万亿美元的网络存量,服务全球三分之一的人口,业务开展范围辐射到全球170多个国家。那么如何通过 AI 技术来提升我们的服务质量?
搭建深度学习平台会遇到哪些挑战呢?我觉得可以分下面4部分来讲:
1.深度神经网络本身具有模型复杂,计算量大,训练数据多,通信密集的困难
2.支持大模型(更深更宽的网络)
3.支持多框架(TensorFlow,MXNet等)
4.支持大规模 GPU 集群的调度
从这四个角度可以描述遇到的挑战。

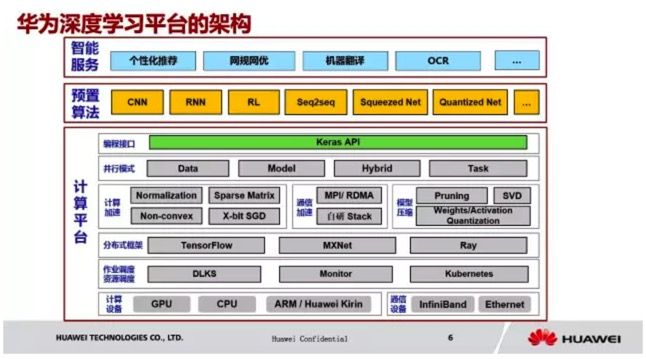
我们对外提供智能服务,内置了 CNN,RNN,RL 等模型。同时支持数据并行,模型并行,混合并行和任务并行四种并行模式。并且,我们在平台上实现了计算加速,通信加速和模型压缩等优化技术。底层我们实现了自己的一套作业调度引擎,对接 Kubernetes 的资源调度。硬件平台兼容 CPU/GPU/ARM 和我们华为的麒麟芯片,网络兼容 Ethernet 和 InfiniBand。
Normalization 是深度学习领域常用的优化技术,Batch Normalization 已经在 CNN 领域取得了广泛应用。ICLR 2017 Hinton 提出的 Layer Normalization 则有效解决了 RNN 的计算加速问题,两者本质都是在解决深层网络梯度弥散/爆炸的问题。

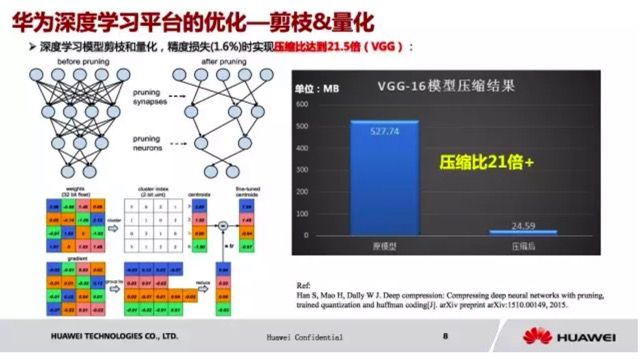
接下来讲讲基于剪枝和量化的模型压缩。
通常,在训练结束后,全连接层和卷积层有大量参数值是接近于0的,对于 inference 的贡献很少。我们可以设置一个接近0的 threshold,将小于它的值设为0。这样可以将稠密参数矩阵中大量0值点剪掉,转换为稀疏的参数矩阵,这一步剪枝可以实现9倍左右的压缩。但是压缩完之后,我们还是觉得不够,我们还可以做量化,虽然我们用32bit 的单精度去存储每一个 weight,但是这个 weight 真正的值的分布类型其实比较少。大部分的 weights 是比较靠近的,这个时候我们想做量化。我们把 32bit 的变成一个 2bit 的 Unit,整个参数的值,比如这个是I类,这个类型附近的值都用它来代替,其它也是一样的,那这样的话,我们就把 32bit 的 weights 变成了 2bit 的 weights。这样的压缩效果是16倍,但是后来发现,这样虽然压缩效果很好,但是对于准确率的影响是比较大的。所以我们就采用了8bit一个量化,压缩效果是4倍。
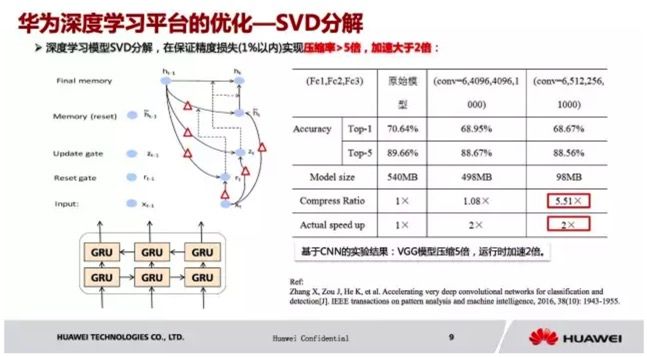
接下来讲的是 SVD 分解。
当参数很大的时候要怎么办呢,这个时候可以使用 SVD 分解,比如说我有一个大矩阵,换成三个小矩阵,进行瘦身,这样的好处是,被压缩了,因为存储变小了;第二个是量变小了,小了之后可以进行加速,SVD 分解,所以模型压缩也是一个很直观的方法。大家可以看到,经过5倍的压缩之后,损失几乎没有。
通信加速我们选择在高性能计算领域广泛使用的 MPI,我们开发了 MPI 版 TensorFlow,使用 MPI 传输数据,控制面仍然走 gRPC。我们用 MPI 的方式进行通信,在 VGG 上面,我们看到它提速了2.7倍,计算速度明显提升;加速比增长幅度也很大。
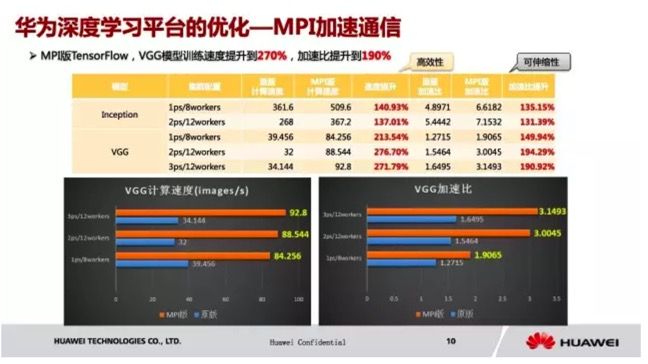
这个是我们自主研发的协议栈,大家看到,TensorFlow 在分布式的时候,如果要发送到另一个节点,减少了内核态向用户态的数据拷贝,仍然使 TensorFlow 的 gRPC,大概有40%的性能提升。

简单讲下我们在深度学习平台上的应用,神经机器翻译。大家知道,现在官方的神经机器翻译只有一个单机单卡版本的,训练速度比较慢。
我们以英语到法语的翻译为例,它其实先建立了英语和法语的语言模型,每一个词在它的语言模型里面都有一个对应的 embedded vector,比如我输入的是一个单词,再到 LSTM 里面,它会把所有的句子之类都存下来,这个信息的多少跟参数是有关系的,然后放到 decoder 那里,最后再放到 RNN 的网络,然后这边对应的也是一个个的单词,这些单词会被映射到法语里面。
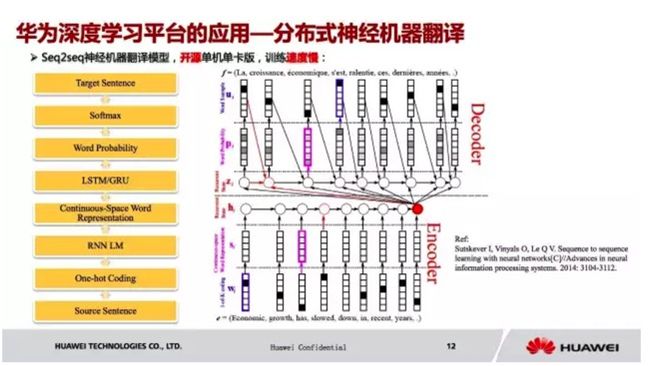
这一块的话,我们实现分布式神经机器翻译,2个节点,8个 GPU,处理速度提升4倍多,达到23316(words/s)。

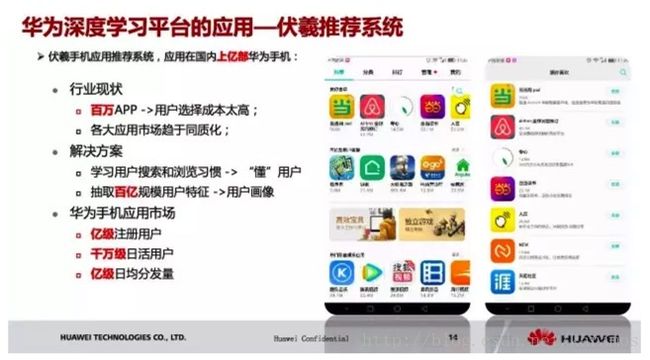
这个是在我们华为应用商城上线的伏羲推荐系统。现在大概有百万级的 App 在各大应用市场,同质化很严重。比如我想选用一个好用的 App,同类型的APP有好几十种,用户选择成本非常高。
现在的话,我们就去学习用户搜索和浏览习惯,做到真正去了解用户想要什么。第二个方法是抽取百亿规模的用户特征,画一个用户画像,实现华为有亿级的注册用户,千万级日活用户,所以点击转化量是非常高的。
总结一下,华为有着广泛的深度学习应用需求和优势,我们在为全球170多个国家提供服务,拥有万亿美元的网络存量和上亿终端用户数据,我们希望通过深度学习等技术将这些高价值数据利用起来,加速华为业务智能化转型。
第二,我们兼容原生的 TensorFlow 和 MXNet 接口。
第三,我们拥有自主研发的 MPI 版 TensorFlow 和自研协议栈。
