Centos7搭建Hadoop 2.X伪分布式环境并运行wordcount MapReduce示例
1. 下载Hadoop
在 Apache的 Hadoop项目界面找到hadoop的 hadoop下载地址
http://hadoop.apache.org/releases.html
因为直接从Apache官方下载文件速度很慢,所以在表格下面选择别的镜像站地址。
在弹出的界面中会推荐一个下载速度很快的国内镜像站。
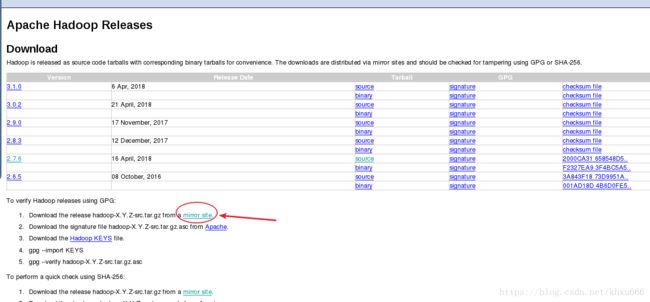

选择其中某个版本的hadoop下载,因为现在市面上绝大部分的学习资料都是以hadoop 2.x 为基础,所以推荐大家下载hadoop 2.x的版本。
没有安装图形界面的系统可以直接在命令行中使用下面的wget命令下载文件
wget http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-2.7.6/hadoop-2.7.6.tar.gz
2. 配置ssh免密码登录
以下操作均在root用户中进行,centos7 可以在命令行中使用 su 命令,输入密码后进入root用户。并且默认centos系统中已经正确的配置好了java环境
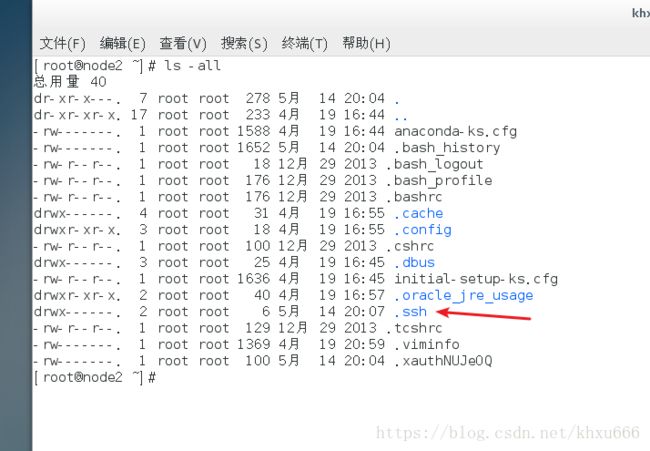
- 进入当前用户目录,找到 .ssh 文件夹
cd ~ //切换到当前用户的用户目录下
ls -all //查看当前用户目录下的所有文件查看当前用户的目录下是否有 .ssh 文件夹,如果没有就自己创建一个
- 生成私钥和公钥
cd .ssh
ssh-keygen -t rsa // 生成公钥和私钥,期间系统会询问密钥的保存位置,直接一路回车确认即可
cp id_rsa.pub authorized_keys // 复制公钥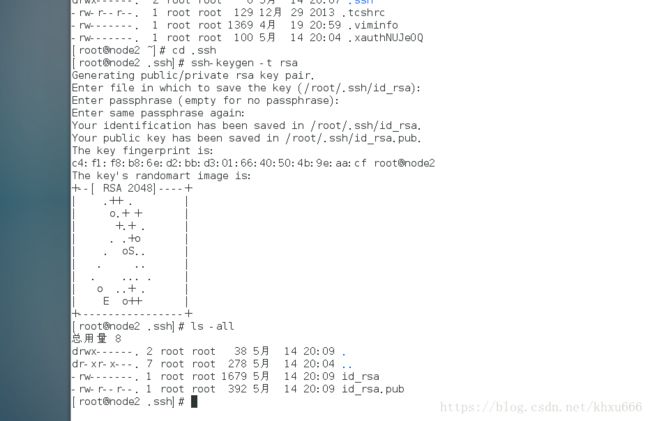
- 验证ssh免密码登录是否成功
ssh localhost //ssh登录本机,第一次登录可能需要输入一次密码,退出之后再登录就不需要了
exit
如果在输入ssh localhost之后出现 报错:Permission denied (publickey,gssapi-keyex,gssapi-with-mic)
这是因为ssh公钥验证失败导致的错误,这个错误的解决办法可以参照别人的博客:
以root用户远程登录Linux报错:Permission denied
ssh 公钥认证报错:Permission denied解决
3. 安装配置Hadoop
以下操作均在root用户中进行,centos7 可以在命令行中使用 su 命令,输入密码后进入root用户。并且默认centos系统中已经正确的配置好了java环境
- 解压Hadoop源文件
tar -xzvf hadoop-2.7.6.tar.gz //解压Hadoop安装包
mv hadoop-2.7.6 /opt // 将解压后的安装包移动到别的地方,方便管理。- 配置hadoop环境变量
vim /etc/profile //配置系统变量,配置之后可在全局任意地方使用Hadoop命令打开文件之后,在文件的最后面添加hadoop的配置信息
export HADOOP_HOME=/opt/hadoop-2.7.6 //这个地方记得修改成自己Hadoop安装目录的地址
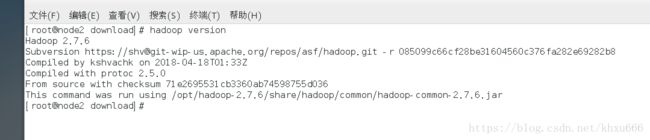
export PATH=$HADOOP_HOME/bin:$PATH 使配置文件生效
source /etc/profile 之后可以输入命令验证配置是否正确生效
- 修改hadoop配置文件
修改 /opt/hadoop-2.7.6/etc/hadoop/ 下面的hadoop配置文件 hadoop-env.sh 、hdfs-site.xml 、 core-site.xml 这三个文件
cd /opt/hadoop-2.7.6/etc/hadoop/ //切换到Hadoop配置文件所在的目录1 . hadoop-env.sh
将文件中的
export JAVA_HOME=${JAVA_HOME}修改为
export JAVA_HOME=/opt/java/jdk1.8.0_171 //把原来的相对地址更改为绝对地址2 . hdfs-site.xml
补充最后的属性:
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
configuration>
3 . core-site.xml
在文件的最后补充:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
configuration>- 启动hadoop
cd /opt/hadoop-2.7.6/bin //切换到Hadoop安装目录下的bin目录
hdfs namenode -format //第一次启动Hadoop,要格式化namenode,之后再启动就不需要再格式化了
cd /opt/hadoop-2.7.6/sbin //切换到Hadoop安装目录下的sbin目录
./start-dfs.sh //启动Hadoop
jps //查看已经开启的进程,看namenode,datanode是否开启
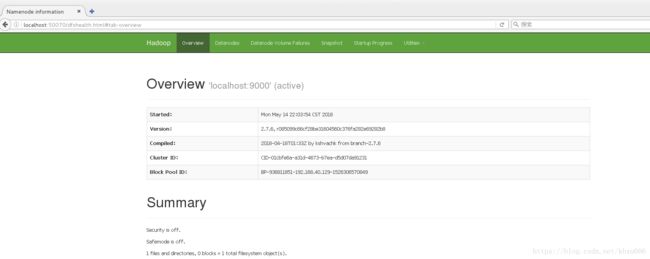
在centos系统的浏览器中输入 http://localhost:50070 查看运行在本机上的hadoop的运行状态
4. 配置YARN
修改 /opt/hadoop-2.7.6/etc/hadoop 目录下的YARN配置文件
cd /opt/hadoop-2.7.6/etc/hadoop
mv mapred-site.xml.template mapred-site.xml //首先复制YARN配置文件1 . mapred-site.xml
在最后修改:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>2 . yarn-site.xml
在最后修改:
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
configuration>运行YARN,验证是否成功
cd /opt/hadoop-2.7.6/sbin
./start-yarn.sh //开启YARN
jps
在浏览器中输入 http://localhost:8088 查看YARN管理的集群状态

5. 运行MapReduce示例(Wordcount)
Wordcount是MapReduce的入门示例程序,相当于我们在学某个编程语言时写的Hello World示例一样。这个程序可以统计某个文件中,各个单词出现的次数。Wordcount程序的jar包已经放置在hadoop安装目录下的 /share/hadoop/mapreduce 文件夹中。
本次我们使用hadoop安装包下自带的几个文件,测试Wordcount程序的运行效果。
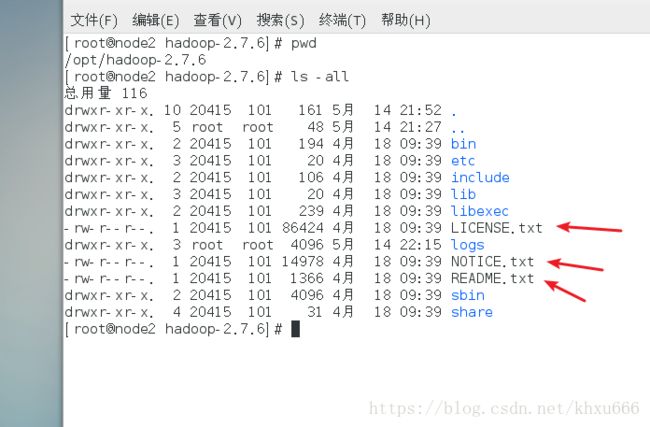
cd /opt/hadoop-2.7.6
ls -all 可以看到在hadoop的安装目录下有几个txt文件,我们使用这几个文件中的某个文件作为Wordcount的测试文件。
- 上传文件到HDFS
hadoop fs -mkdir /input //在HDFS的根目录下新建 input 目录
hadoop fs -put NOTICE.txt /input //将本地的NOTICE.txt文件上传到HDFS的 input 目录下
hadoop fs -ls -R / //查看文件是否成功上传到HDFS上面
可以看到,已经成功的在本机的HDFS的根目录下创建了 input 文件夹,并将NOTICE.txt文件上传到了HDFS上的 input 文件夹下面。

- 运行Wordcount示例程序
使用hadoop jar 命令, 后面先指定程序虽用jar包的路径,后面是要运行的程序的名称,最后是输入文件和输出路径,这个命令要根据自己本机Hadoop的配置做相应的修改。
hadoop jar /opt/hadoop-2.7.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /input /output
hadoop fs -ls -R / //查看程序运行后产生的文件
hadoop fs -cat /output/part-r-00000 //查看程序最终的运行结果
可以看到,在运行Wordcount程序之后,HDFS上面产生了很多的文件,其中 /output/part-r-00000 文件就是程序最终的运行结果。查看该文件可以看到:
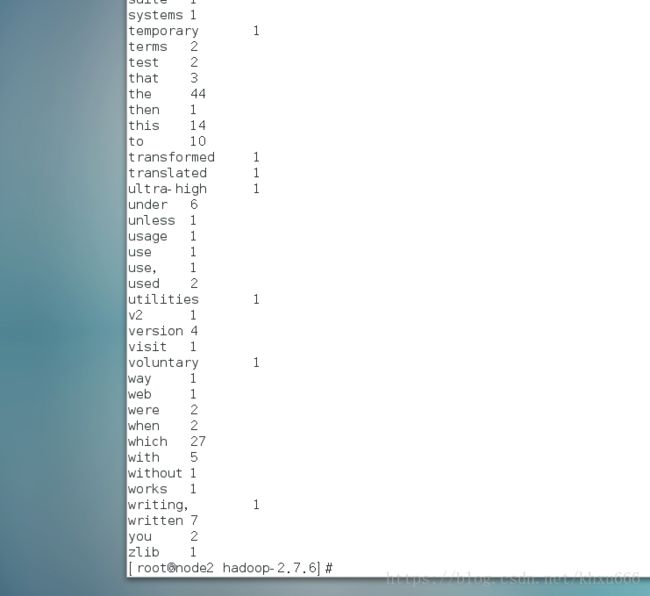
这说明已经成功的运行了Wordcount示例程序。