JVM优化调试使用心得与线上CPU100%原因分析
因为线上系统遇到CPU100%的问题,这种问题在流量较大时比较常见,因为JDK自身有很多JVM调试工具,如jps、jstack、jmap、jhat、jstat等使用工具,在实际工作中使用这些工具进行调试是十分必要的,一般通过以下步骤就能定位并解决CPU100%的问题,文章是自己很早写的,现在重拾一下,下面只做简单介绍,这些都可以在线上服务器上执行。
一、 jstack
jstack用来查Java进程内的线程堆栈信息。语法格式如下:1 |
jstack [option] pid |
-l,除了堆栈打印出额外的锁信息,在发生死锁时可以用jstack -l pid来观察锁持有情况 |
-m mixed mode,不仅会输出Java堆栈信息,还会输出C/C++堆栈信息(比如Native方法) |

图1 自动部署平台jstack -l堆栈信息

图2 堡垒机查看应用进程id
另外如果线上发生cpu使用过高的情况,jstack则可以快速定位到线程堆栈,具体的操作思路是获java进程中最耗费cup的线程,并得出其堆栈信息,根据堆栈定位到具体代码,这在JVM性能调试中使用得很多,这个操作得再堡垒机上运行.
第一步先找出应用的进程ID,这个在上文已经说过,本文使用的是是30086:
接下来得到当前进程内最耗费CPU的线程,使用top -Hp 30086,输出如下:
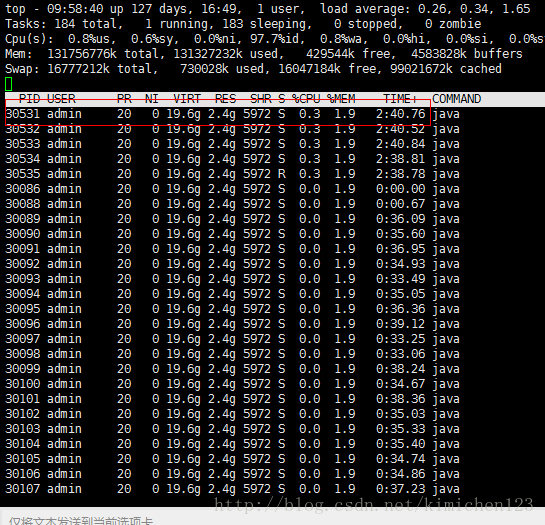
图3 查看最耗时的线程
printf "%x\n" 30531 |
jstack 30531| grep 7743 |
"UMP-WriteLog2FileThread-aliveLogger" daemon prio=10 tid=0x00007f8a04010000 nid=0x7743 sleeping[0x00007f8ac2ae9000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at com.jd.ump.profiler.util.MessagesStore$WriteLog2File.run(MessagesStore.java:85)
at java.lang.Thread.run(Thread.java:745)
Locked ownable synchronizers:
- None
"GC task thread#0 (ParallelGC)" prio=10 tid=0x00007f8c60020000 nid=0x7589 runnable
而在cpu暴增的情况下,观察jstack线程,会得到以下的新增,定位到具体代码。

图4 定位至问题代码行
二、 jmap
jmap用来查看堆内存使用状况,这个可以直接在deploy里面使用,最后在日志路径下载
jmap语法格式如下:
1 |
jmap [option] pid |
jmap -permstat pid |

图5 类加载器信息
jmap -heap pid |
jmap -heap pid查看进程堆内存使用情况,包括使用的GC算法、堆配置参数和各代中堆内存使用情况,因为已经调整过堆内存为2G,而NewRatio的比例为2,说明新生代和老年代的大小为1比2,老年代过大很多时候使得内存无法释放,同时老年代过大,很大程度上浪费了内存,这里可以在在启动的环境变量中修改-XX:NewRatio=1
,可以找运维调整一下。
PROCESS PATH:/export/Domains/m.jd.id/server1
DATETIME: 2016-06-01 08:51:28
EXECUTE COMMAND:/export/servers/jdk1.7.0_71/bin/jmap -heap 30086
using thread-local object allocation.
Parallel GC with 23 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 2147483648 (2048.0MB)
NewSize = 1310720 (1.25MB)
MaxNewSize = 17592186044415 MB
OldSize = 5439488 (5.1875MB)
NewRatio = 2
SurvivorRatio = 8
PermSize = 21757952 (20.75MB)
MaxPermSize = 1073741824 (1024.0MB)
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 704643072 (672.0MB)
used = 355307136 (338.8472900390625MB)
free = 349335936 (333.1527099609375MB)
50.42370387486049% used
From Space:
capacity = 5767168 (5.5MB)
used = 3899552 (3.718902587890625MB)
free = 1867616 (1.781097412109375MB)
67.61641068892045% used
To Space:
capacity = 5767168 (5.5MB)
used = 0 (0.0MB)
free = 5767168 (5.5MB)
0.0% used
PS Old Generation
capacity = 1431830528 (1365.5MB)
used = 1389572200 (1325.199317932129MB)
free = 42258328 (40.300682067871094MB)
97.04865015980438% used
PS Perm Generation
capacity = 110100480 (105.0MB)
used = 58882144 (56.154388427734375MB)
free = 51218336 (48.845611572265625MB)
53.480369931175595% used
35733 interned Strings occupying 4872992 bytes.
jmap -dump:format=b,file=dumpFileName |
我们同样在deploy里面使用Dump:
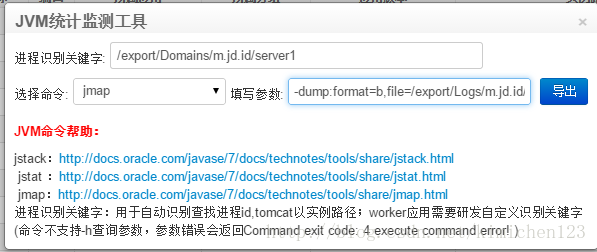
图6自动部署dump文件命令
dump出来的文件用IBM heapAnalysis工具查看,使用命令打开下载下来的dump文件:
java -Xmx3000m -jar ha396.jar fileName
![]()
图7 IBM分析堆内存使用大写
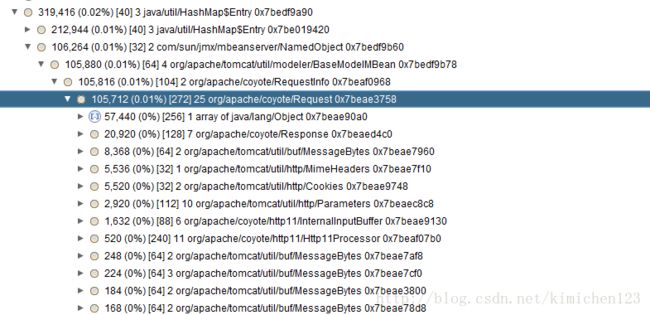
图8 TreeView查看具体使用场合
分析代码,在压测时,cpu接近100%,而堆内存中有接近一半是HashMap,占了44%,800多M。
再使用TreeView我们发现,大部分的HashMap是tomcat在处理request时使用,这也与压测时每分钟上万的请求不谋而合。
三、jstat
1 |
jstat [ generalOption | outputOptions vmid [interval[s|ms] [count]] ] |
|
PROCESS PATH:/export/Domains/m.jd.id/server1
DATETIME: 2016-06-01 08:48:53
EXECUTE COMMAND:/export/servers/jdk1.7.0_71/bin/jstat -gc 30086 500 20
S0C S1C S0U S1U EC EU OC OU PC PU YGC YGCT FGC FGCT GCT
9728.0 10240.0 0.0 864.0 678912.0 635616.5 1398272.0 1249792.7 107520.0 57499.5 2433 474.174 1 6.717 480.891
9728.0 9728.0 1824.0 0.0 679936.0 153569.9 1398272.0 1249976.7 107520.0 57499.5 2434 474.433 1 6.717 481.150
9728.0 9728.0 1824.0 0.0 679936.0 359170.8 1398272.0 1249976.7 107520.0 57499.5 2434 474.433 1 6.717 481.150
9728.0 9728.0 1824.0 0.0 679936.0 558627.4 1398272.0 1249976.7 107520.0 57499.5 2434 474.433 1 6.717 481.150
9728.0 9728.0 0.0 5168.6 679936.0 17135.0 1398272.0 1250152.7 107520.0 57499.5 2435 474.582 1 6.717 481.299
9728.0 9728.0 0.0 5168.6 679936.0 273388.6 1398272.0 1250152.7 107520.0 57499.5 2435 474.582 1 6.717 481.299
9728.0 9728.0 0.0 5168.6 679936.0 448408.6 1398272.0 1250152.7 107520.0 57499.5 2435 474.582 1 6.717 481.299
9728.0 9728.0 0.0 5168.6 679936.0 672819.4 1398272.0 1250152.7 107520.0 57499.5 2435 474.582 1 6.717 481.299
9728.0 12288.0 9697.6 0.0 674816.0 130122.3 1398272.0 1252427.5 107520.0 57499.5 2436 474.825 1 6.717 481.542
9728.0 12288.0 9697.6 0.0 674816.0 336255.0 1398272.0 1252427.5 107520.0 57499.5 2436 474.825 1 6.717 481.542
9728.0 12288.0 9697.6 0.0 674816.0 529050.8 1398272.0 1252427.5 107520.0 57499.5 2436 474.825 1 6.717 481.542
9728.0 12288.0 9697.6 5104.5 674816.0 674816.0 1398272.0 1259470.2 107520.0 57499.5 2437 474.825 1 6.717 481.542
11776.0 12288.0 0.0 5360.5 674816.0 210927.2 1398272.0 1259470.2 107520.0 57499.5 2437 475.020 1 6.717 481.737
11776.0 12288.0 0.0 5360.5 674816.0 423921.2 1398272.0 1259470.2 107520.0 57499.5 2437 475.020 1 6.717 481.737
11776.0 12288.0 0.0 5360.5 674816.0 630101.4 1398272.0 1259470.2 107520.0 57499.5 2437 475.020 1 6.717 481.737
11776.0 11264.0 5376.7 0.0 676352.0 143384.7 1398272.0 1262235.9 107520.0 57499.5 2438 475.073 1 6.717 481.790
11776.0 11264.0 5376.7 0.0 676352.0 336295.4 1398272.0 1262235.9 107520.0 57499.5 2438 475.073 1 6.717 481.790
11776.0 11264.0 5376.7 0.0 676352.0 488193.1 1398272.0 1262235.9 107520.0 57499.5 2438 475.073 1 6.717 481.790
10752.0 11264.0 0.0 4240.5 676352.0 26658.1 1398272.0 1266075.6 107520.0 57499.5 2439 475.195 1 6.717 481.912
10752.0 11264.0 0.0 4240.5 676352.0 239910.6 1398272.0 1266075.6 107520.0 57499.5 2439 475.195 1 6.717 481.912
要明白上面各列的意义,先看JVM堆内存布局:

可以看出:
1 |
堆内存 = 年轻代 + 年老代 + 永久代 |
2 |
年轻代 = Eden区 + 两个Survivor区(From和To) |
现在来解释各列含义:
S0C、S1C、S0U、S1U:Survivor 0/1区容量和使用量 |
EC、EU:Eden区容量和使用量 |
OC、OU:年老代容量和使用量 |
PC、PU:永久代容量和使用量 |
YGC、YGT:年轻代GC次数和GC耗时 |
FGC、FGCT:Full GC次数和Full GC耗时 |
GCT:GC总耗时 |
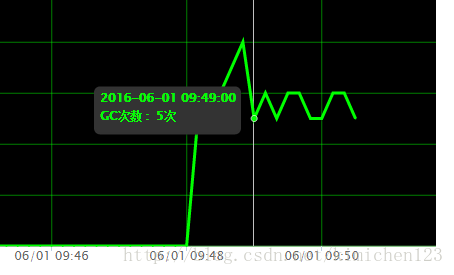
图9 JVM监控GC数据
以上就是基于JVM调试工具的部分使用心得,更多命令和细节在网上也能找到,这里就不一一列举了。