数据集成工具ETL到KAFKA
一、数据系统传统功能包括:
提供联机事务处理OLTP的操作性数据库以及提供在线分析处理OLAP的关系型数据仓库。
二、数据集成发展历史
ETL
Neha Narkhede(Confluent创始人,kafka)观点:ETL 已死,而实时流长存;
来自各种操作性数据库的数据会以批处理的方式加载到数据仓库的主模式中,批处理运行的周期可能是每天一次或两次。
这种数据集成过程通常称为抽取 - 转换 - 加载(extract-transform-load,ETL)。
单机数据库->分布式数据库
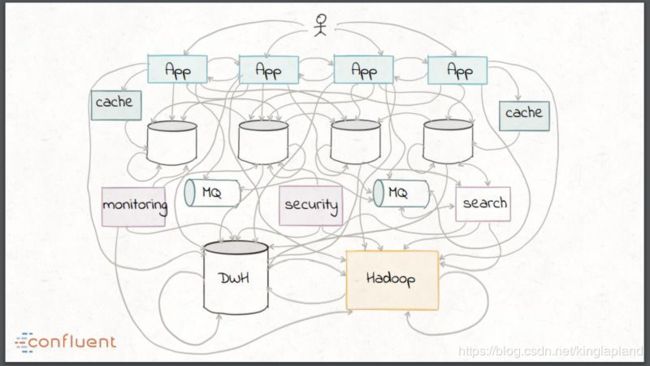
单服务器的数据库正在被分布式数据平台所取代;除了事务性数据,现在有了类型更多的数据源,比如日志、传感器、指标数据等;流数据得到了普遍性增长,在速度方面比每日的批处理有了更快的业务需求。
这些趋势所造成的后果就是传统的数据集成方式最终看起来像一团乱麻,比如组合自定义的转换脚本、使用企业级中间件如企业服务总线(ESB)和消息队列(MQ)以及像 Hadoop 这样的批处理技术。
http://www.dataguru.cn/article-13066-1.html 批处理ETL已死,Kafka才是数据处理的未来?
https://blog.csdn.net/keizhige/article/details/80999780 微服务、SOA、ESB比较
三、数据集成的未来
在上世纪 90 年代的零售行业中,需要对购买者行为趋势进行分析。
存储在 OLTP 数据库中的操作性数据必须要进行抽取、转换为目标仓库模式,然后加载到中心数据仓库中。这项技术在过去二十年间不断成熟,但是数据仓库中的数据覆盖度依然相对非常低,这主要归因于 ETL 的如下缺点:
数据的清洗和管理需要手工操作并且易于出错;
ETL 的操作成本很高:它通常很慢,并且是时间和资源密集型的;
ETL 所构建的范围非常有限,只关注于以批处理的方式连接数据库和数据仓库。
在实时 ETL 方面,早期采用的方式是企业应用集成(Enterprise application integration,EAI),并使用 ESB 和 MQ 实现数据集成。尽管这可以说是有效的实时处理,但这些技术通常很难广泛扩展。这给传统的数据集成带来了两难的选择:实时但不可扩展,或者可扩展但采用的是批处理方案。
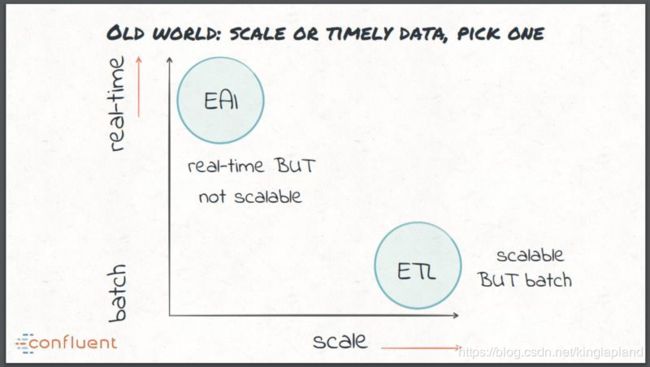
这些需求推动一个统一数据集成平台的出现,而不是一系列专门定制的工具。
这个平台必须拥抱现代架构和基础设施的基本理念、能够容错、能够并行、支持多种投递语义、提供有效的运维和监控并且允许进行模式管理。Apache Kafka 是七年前由 LinkedIn 开发的,它就是这样的一个开源流平台,能够作为组织中数据的中枢神经系统来运行。
1.2 Kafka的使用场景:
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
原文链接:https://blog.csdn.net/zhongwumao/article/details/81171143 kafka集群搭建及简单使用