强化学习系列2:Open AI的gym框架、baselines和Spinning Up
1. gym安装
Openai gym 是openAI用于开发和比较强化学习算法的工具包。github地址点击这里。gym安装十分简单:
pip install gym
也可以下载后安装:
git clone https://github.com/openai/gym.git
cd gym
pip install -e .
运行下面的python代码看是否安装成功:
import gym
env = gym.make('SpaceInvaders-v0')
env.reset()
env.render()
2. gym使用
首先看一个游戏例子,游戏AI采用随机策略,前进1000步,如果中间游戏结束则重新开始:
import gym
env = gym.make('SpaceInvaders-v0')
env.reset()
for i in range(1000):
env.render()
o,r,d,i = env.step(env.action_space.sample())
if d:
env.reset()
会出现如下的动画:

gym 的核心接口是 env,作为统一的环境接口。env.reset()的作用是重置环境到初始状态;env.step(action)的作用是推进一个时间步长,返回 observation,reward,done,info。其中done用于判断一轮迭代是否结束;env.render()函数进行图形渲染。
函数推进的过程如下图。其中step函数相当于仿真器的物理引擎,输入行动a,输出observation、reward、done、info。
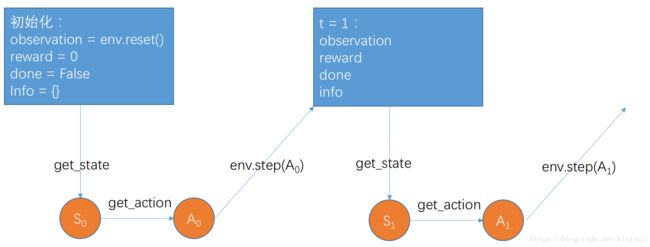
3. 综合示例
接下来看gym自带的小车模型,使用Q-learning方法进行学习。
模型的Observation有4个维度:
| 编号 | 名称 | 最小值 | 最大值 |
|---|---|---|---|
| 0 | 小车的位置 | -2.4 | 2.4 |
| 1 | 小车的速度 | -inf | inf |
| 2 | 木棒的角度 | -41.8° | 41.8° |
| 3 | 木棒的速度 | -inf | inf |
Action有2种情形:0:小车往左移动;1:小车往右移动
Reward:木棒每保持平衡1个时间步,就得到1分。
Done:每一场游戏的结束条件为木棒倾斜角度大于41.8°或者已经达到200分
最终目标:最近100场游戏的平均得分高于195。
代码如下:
import gym
import numpy as np
env = gym.make('CartPole-v0')
max_number_of_steps = 200 # 每一场游戏的最高得分
#---------获胜的条件是最近100场平均得分高于195-------------
goal_average_steps = 195
num_consecutive_iterations = 100
#----------------------------------------------------------
num_episodes = 5000 # 共进行5000场游戏
last_time_steps = np.zeros(num_consecutive_iterations) # 只存储最近100场的得分(可以理解为是一个容量为100的栈)
# q_table是一个256*2的二维数组
# 离散化后的状态共有4^4=256种可能的取值,每种状态会对应一个行动
# q_table[s][a]就是当状态为s时作出行动a的有利程度评价值
# 我们的AI模型要训练学习的就是这个映射关系表
q_table = np.random.uniform(low=-1, high=1, size=(4 ** 4, env.action_space.n))
# 分箱处理函数,把[clip_min,clip_max]区间平均分为num段,位于i段区间的特征值x会被离散化为i
def bins(clip_min, clip_max, num):
return np.linspace(clip_min, clip_max, num + 1)[1:-1]
# 离散化处理,将由4个连续特征值组成的状态矢量转换为一个0~~255的整数离散值
def get_state(observation):
# 将矢量打散回4个连续特征值
cart_pos, cart_v, pole_angle, pole_v = observation
# 分别对各个连续特征值进行离散化(分箱处理)
digitized = [np.digitize(cart_pos, bins=bins(-2.4, 2.4, 4)),
np.digitize(cart_v, bins=bins(-3.0, 3.0, 4)),
np.digitize(pole_angle, bins=bins(-0.5, 0.5, 4)),
np.digitize(pole_v, bins=bins(-2.0, 2.0, 4))]
# 将4个离散值再组合为一个离散值,作为最终结果
return sum([x * (4 ** i) for i, x in enumerate(digitized)])
# 根据本次的行动及其反馈(下一个时间步的状态),返回下一次的最佳行动
def get_action(state, action, observation, reward,episode):
next_state = get_state(observation)
epsilon = 0.5 * (0.99 ** episode)
if epsilon <= np.random.uniform(0, 1):
next_action = np.argmax(q_table[next_state])
else:
next_action = np.random.choice([0, 1])
#-------------------------------------训练学习,更新q_table----------------------------------
alpha = 0.2 # 学习系数α
gamma = 0.99 # 报酬衰减系数γ
q_table[state, action] = (1 - alpha) * q_table[state, action] + alpha * (reward + gamma * q_table[next_state, next_action])
# -------------------------------------------------------------------------------------------
return next_action, next_state
# 重复进行一场场的游戏
for episode in range(num_episodes):
observation = env.reset() # 初始化本场游戏的环境
state = get_state(observation) # 获取初始状态值
action = np.argmax(q_table[state]) # 根据状态值作出行动决策
episode_reward = 0
# 一场游戏分为一个个时间步
for t in range(max_number_of_steps):
observation, reward, done, info = env.step(action)
# 对致命错误行动进行极大力度的惩罚,让模型恨恨地吸取教训
if done:
reward = -200
action, state = get_action(state, action, observation, reward, episode)
if done:
print('%d Episode finished after %f time steps / mean %f' % (episode, t + 1,
last_time_steps.mean()))
last_time_steps = np.hstack((last_time_steps[1:], [t + 1]))
break
# 如果最近100场平均得分高于195
if (last_time_steps.mean() >= goal_average_steps):
print('Episode %d train agent successfuly!' % episode)
break
print('Failed!')
程序输出如下,模型在经过大约835场的游戏后,平均分数能达到了195。
0 Episode finished after 72.000000 time steps / mean 0.000000
1 Episode finished after 8.000000 time steps / mean 0.720000
2 Episode finished after 12.000000 time steps / mean 0.800000
3 Episode finished after 38.000000 time steps / mean 0.920000
4 Episode finished after 15.000000 time steps / mean 1.300000
......
833 Episode finished after 200.000000 time steps / mean 193.770000
834 Episode finished after 200.000000 time steps / mean 194.210000
835 Episode finished after 200.000000 time steps / mean 194.210000
Episode 836 train agent successfuly!
Episode 837 train agent successfuly!
......
这个例子中用到的一些trick包括:
- 使用lookuptable(q_table)存储每个状态s对应的行动a;
- 采取了探索策略,以一定的概率epsilon随机选取行动;
- 随机概率随着时间推进会衰减;
- 错误行动会加上惩罚;
- 将状态和行动转化为数字索引,以提高查询的速度。
4. Baselines简介
Baselines是一个传统强化学习的资源库,github地址为:https://github.com/openai/baselines
Baselines需要python3的环境,建议使用3.6版本。安装openmpi和相关库(tensorflow、gym),mac可以使用brew安装,ubuntu可以使用apt-get,centos可以使用pip安装。
git clone https://github.com/openai/baselines.git
cd baselines
pip install -e .
用下面的语句检查是否安装成功。如果提示缺少某个库,安装即可
pip install pytest
pytest
安装完可进行可视化:
python -m baselines.run --alg=ppo2 --env=PongNoFrameskip-v4 --num_timesteps=2e7 --save_path=~/models/pong_20M_ppo2
python -m baselines.run --alg=ppo2 --env=PongNoFrameskip-v4 --num_timesteps=0 --load_path=~/models/pong_20M_ppo2 --play
根据官方文档,baselines实现的算法包括:
- A2C
- ACER
- ACKTR
- DDPG
- DQN
- GAIL
- HER
- PPO1
- PPO2
- TRPO
5. Spinning Up简介
spinning up是一个深度强化学习的很好的资源,其网址是:https://spinningup.openai.com/en/latest/
首先需要python3.6环境,建议下载anaconda3~这里要注意安装版本问题,目前使用python3.5和python3.7都存在问题。然后安装openmpi和相关库(tensorflow、gym),mac可以使用brew安装,ubuntu可以使用apt-get,centos可以使用pip安装。接下来执行下面的步骤:
git clone https://github.com/openai/spinningup.git
cd spinningup
pip install -e .
用下面的语句检查是否安装成功。如果提示缺少某个库,安装即可
python -m spinup.run ppo --hid "[32,32]" --env LunarLander-v2 --exp_name installtest --gamma 0.999
安装完可进行可视化:
python -m spinup.run test_policy data/installtest/installtest_s0
python -m spinup.run plot data/installtest/installtest_s0
根据官方文档,spinning up实现的算法包括:
- Vanilla Policy Gradient (VPG)
- Trust Region Policy Optimization (TRPO)
- Proximal Policy Optimization (PPO)
- Deep Deterministic Policy Gradient (DDPG)
- Twin Delayed DDPG (TD3)
- Soft Actor-Critic (SAC)