hive案例-用户行为日志分析
目录
背景
建立相关表
weblog表
member用户表
orders订单表
hive用户日志分析
简单查询、关联查询
日期函数、正则表达式、窗口函数
用户画像标签库的建立和使用【灵活使用行转列、列转行操作】
背景
用户行为日志格式如下:
{"address":{"country":"中国","province":"山东","city":"济南"},"device_id":"879367ed5ea2473d9121779bc48f4765","user_id":"4921528165744221","active_name":"pageview","ip":"111.37.0.130","session_id":"0000f7714f3c48f4838513a65ad7383b","action_path":["http://www.bigdataclass.com/category"],"time_tag":1527604188966,"req_url":"http://www.bigdataclass.com/category"}
{"address":{"country":"中国","province":"山东","city":"济南"},"device_id":"879367ed5ea2473d9121779bc48f4765","user_id":"4921528165744221","active_name":"pageview","ip":"111.37.0.130","session_id":"0000f7714f3c48f4838513a65ad7383b","action_path":["http://www.bigdataclass.com/category","http://www.bigdataclass.com"],"time_tag":1527604410990,"req_url":"http://www.bigdataclass.com"}
建立相关表
weblog表
日志存放在HDFS中,以天最为分区,存放在不同目录。
使用hive创建bigdata数据库,建立日志行为外部表,并添加分区。
-- 创建bigdata库
create database if not exists bigdata;
use bigdata;
-- 创建weblog表,即用户行为表
create external table if not exists weblog (
time_tag bigint comment '时间戳' ,
active_name string comment '事件名称' ,
device_id string comment '设备id' ,
session_id string comment '会话id' ,
user_id string comment '用户id' ,
ip string comment 'ip地址' ,
address map comment '地址' ,
req_url string comment 'http请求地址' ,
action_path array comment '访问路径' ,
product_id string comment '商品id' ,
order_id string comment '订单id'
)
partitioned by ( day string comment '日期')
row format serde 'org.openx.data.jsonserde.JsonSerDe'
stored as textfile;
-- 为weblog添加分区
alter table weblog add partition (day='2018-05-29') location '/user/hadoop/weblog/day=2018-05-29';
alter table weblog add partition (day='2018-05-30') location '/user/hadoop/weblog/day=2018-05-30';
ALTER TABLE bigdata.weblog ADD PARTITION (day='2018-05-31') location '/user/hadoop/weblog/day=2018-05-31';
-- 显示分区
show partitions weblog;
-- 删除分区
alter table weblog drop if exists partition (day='2018-05-31'); 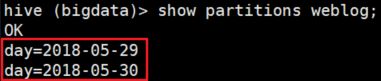 分区信息
分区信息
member用户表
-- 创建用户表
CREATE EXTERNAL TABLE IF NOT EXISTS `bigdata.member`(
`user_id` string COMMENT '用户id',
`nick_name` string COMMENT '昵称',
`name` string COMMENT '姓名',
`gender` string COMMENT '性别',
`register_time` bigint COMMENT '注册时间',
`birthday` bigint COMMENT '生日',
`device_type` string COMMENT '设备类型')
row format serde 'org.openx.data.jsonserde.JsonSerDe'
stored as textfile
location '/user/hadoop/hive/member'; 用户表数据
用户表数据
orders订单表
-- 创建订单表
create EXTERNAL table `bigdata.orders` (
`order_id` string comment '订单id',
`user_id` string comment '用户id',
`product_id` string comment '产品id',
`order_time` bigint comment '下单时间' ,
`pay_amount` double comment '付款金额')
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
stored as textfile
location '/user/hadoop/hive/orders';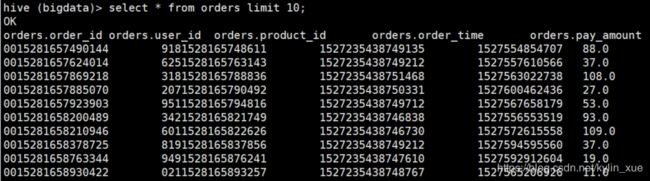 订单数据实例
订单数据实例
hive用户日志分析
简单查询、关联查询
需求1:查询下单用户的id、性别、注册时间。
需求2:查询访问每个产品页面的访问次数。
需求3:统计一下男生、女生花钱总数谁更多,平均每个男生和每个女生谁花钱更多?
需求1:user_id、gender和register_time三个属性都是来自表member,但是仅仅需要查询下单用户的,所以通过weblog表查询下单用户的user_id,然后和member进行关联操作。
-- 下订单的用户只能在weblog中查询到
select t1.user_id, t2.gender, t2.register_time
from
(select user_id from weblog where active_name='order') t1
join
(select user_id, gender, register_time from member) t2
on t1.user_id=t2.user_id;需求2:注意这里是产品页面,通过req_url中带 "/product/"的即可找到产品页面,active_name为pageview的行为是访问页面
-- 查询访问每个产品页面的访问次数
select req_url, count(1) visit_num
from weblog
where active_name='pageview' and req_url like '%/product/%'
group by req_url;
需求3:member表和gender表进行关联,然后根据gender分为2个组,进行聚合操作即可。
select
gender,
count(1) num_gender,
sum(t2.pay_amount) sum_amount,
avg(t2.pay_amount) vg_amount
from
(select user_id, gender from member) t1
join
(select user_id, pay_amount from orders) t2
on t1.user_id=t2.user_id
group by gender;拓展:查询出男生高于男生平均花费的人数,女生高于女生平均花费的人数。
思路:首先需要计算出男生平均花费和女生平均花费【t4做的事情】,然后按照gender进行join【t3 join t4】,这时每一行都会有pay_amount和avg_amount,并且此时的avg_amount是随性别不同的,只要筛选出pay_amount>avg_amount即可。
select gender, count(1) num
from
(
select t1.user_id, gender, pay_amount
from
(select user_id, gender from member) t1
join
(select user_id, pay_amount from orders) t2
on t1.user_id=t2.user_id
) t3
join
(
select gender, avg(t2.pay_amount) avg_amount
from
(select user_id, gender from member) t1
join
(select user_id, pay_amount from orders) t2
on t1.user_id=t2.user_id
group by gender
) t4
on t3.gender=t4.gender
where t3.pay_amount>t4.avg_amount
group by t3.gender;日期函数、正则表达式、窗口函数
需求4:查询用户下单的具体日期
使用日期函数from_unixtime(bigint, 'yyyy-MM-dd HH:mm:ss')将unix_time ==> yyyy-MM-dd HH:mm:ss.SSS
select
order_id, user_id, pay_amount,
// orders表中的时间单位是ms,所以要转换为s
from_unixtime(cast(order_time/1000 as bigint), 'yyyy-MM-dd HH-mm-ss.SSS') time
from orders
limit 10;关于日期函数的总结:
unix_timestamp('2018-10-25 08:23:33'):bigint timestamp 指的是年月日时分秒,所以格式要对
to_date('2018-10-25 08:23:33'):string 返回日期字符串
second('2018-10-25 08:23:33'):int 返回时间戳中的秒
返回某一日期是星期几? 【已知2012-01-01正好是星期日】
pmod(datediff('2019-02-22', '2012-01-01'), 7)
select date_add('1989-10-25', -1):string 返回1989-10-25日前一天的日期
需求5:查询出每个商品的用户访问量【product_id需要通过req_url来获取】
需求6:查询出下单用户的着陆页、下单前的最后一页、下单前浏览了多少页面
select user_id, landing_page, last_page, count_visit
from
(
select
user_id,
session_id,
active_name,
-- 用户第一次访问的页面
first_value(req_url) over (partition by user_id order by time_tag asc) landing_page,
-- 用户本次之前访问的页面
lag(req_url, 1) over (partition by user_id order by time_tag asc) last_page,
-- 用户浏览的总网页数量
count(IF(active_name='page_view', req_url, null)) over (partition by user_id order by time_tag asc) count_visit
from weblog
) t
where active_name='order'; -- 过滤掉非下单页窗口函数小结:
戳口范围
-- 默认为从起点到当前行
min(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1
-- 当前行+往前3行+往后1行
min(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5
-- 当前行+往后所有行
min(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6窗口函数原理:
一个窗口函数所作用的行集 是 通过FROM子句产生,再经过WHERE、GROUP BY、HAVING过滤得到的"虚拟表"。例如,一个由于不满足WHERE条件被删除的行是不会被任何窗口函数所见的。
用户画像标签库的建立和使用【灵活使用行转列、列转行操作】
用户画像标签库属性:性别、年龄、设备类型、注册时间、首次下单时间、最近一次下单时间、下单次数、下单金额、最近一次下单地理位置。
最简单的方法可以通过多表关联,但是这样不好维护,如果新增新的标签,需要原标签库和新标签再次进行关联。
所以,我介绍一种按照标签语义分区,灵活运用行转列、列转行的方法。
// undo 原理介绍
第1步:建立中间表和大宽表。
中间表user_tag_value只有3个字段:user_id, tag 和 value【1个user的所有标签和值对应了多行】。
大宽表user_profile只有2个字段:user_id, profile【profile是一个json串,存放了用户的所有可能标签】。
-- tag_value中间表
create external table user_tag_value (
user_id string comment 'user id',
tag string comment '标签',
value string comment '标签值'
)partitioned by (module string comment '标签模块')
row format serde 'org.openx.data.jsonserde.JsonSerDe'
stored as textfile
location '/user/4800613/hive/user_profile/tag_value';
-- user_profile大宽表
create external table user_profile (
user_id string comment 'user id',
profile string comment '用户标签'
)
row format serde 'org.openx.data.jsonserde.JsonSerDe'
stored as textfile
location '/user/4800613/hive/user_profile/user_profile';第2步:将不同标签写到相应分区。
-- 性别、年龄、设备类型、注册日期 写入 basic_info 分区
insert overwrite table user_tag_value partition(module='basic_info')
select user_id, mp['key'], mp['value']
from
(select user_id,
array(map('key', 'gender', 'value', gender),
map('key', 'age', 'value', cast(2018-from_unixtime(cast(birthday/1000 as bigint), 'yyyy') as string)),
map('key', 'device_type', 'value', device_type),
map('key', 'register_day', 'value', from_unixtime(cast(register_time/1000 as bigint), 'yyyy-MM-dd'))
) arr
from member
) s lateral view explode(arr) arrtable as mp;-- 首次下单时间、最近下单时间、下单次数、下单金额写入中间表的 consume_info 分区
insert overwrite table user_tag_value partition(module='consume_info')
select user_id, mp['key'], mp['value']
from
(
select
user_id,
array(
map('key', 'first_order_time', 'value', min(order_time)),
map('key', 'last_order_time', 'value', max(order_time)),
map('key', 'order_count', 'value', count(1)),
map('key', 'order_sum', 'value', sum(pay_amount))
) arr
from orders
group by user_id
) s lateral view explode(arr) arrtable as mp;-- 从 weblog表 得到 地理位置信息
insert overwrite table user_tag_value partition(module='geography_info')
select user_id, 'province' as tag, t1.province
from
(
select
user_id,
address['province'] as province,
-- 同一个user_id对应多个记录,选择最近下单的那个地址
row_number() over (partition by user_id order by time_tag desc) order_rank
from weblog
where active_name='pay'
) t1
where t1.order_rank=1;第3步:user_tag_value中间表行转列为大宽表
insert overwrite table user_profile
select
user_id,
concat('{', concat_ws(',', collect_set(concat('"', tag, '"', ':', '"', value, '"'))), '}') as json_string
from user_tag_value
group by user_id;查询 user_profile 前3条记录如下:
0001528165978481 {"gender":"女","age":"43.0","device_type":"Android","register_day":"2018-05-29"}
0001528166031761 {"gender":"女","age":"44.0","device_type":"WEB","register_day":"2018-04-25","first_order_time":"1527578321393","last_order_time":"1527578321393","order_count":"1","order_sum":"40.0","province":"山西"}
0001528166058390 {"gender":"女","age":"26.0","device_type":"WEB","register_day":"2018-04-09"}
使用user_profile查询用户标签举例:
-- 查询用户的性别、年龄、所在省
select
user_id,
get_json_object(profile, '$.gender') gender,
get_json_object(profile, '$.age') age,
get_json_object(profile, '$.province') province
from user_profile;