尚学堂大数据学习笔记(二) CentOS6.5 + JDK8 + hadoop2.6.5 搭建Hadoop集群
文章目录
- 尚学堂大数据学习笔记(二) CentOS6.5 + JDK8 + hadoop2.6.5 安装配置HDFS
- 1. 安装CentOS6.5系统
- 1.1创建CentOS6.5系统虚拟机
- 1.1虚拟机创建
- 1.2 开启ssh服务
- 1.3 更改hostname
- 2 配置Host
- 3. 安装配置JDK8
- 3.1 上传jdk
- 3.2 解压
- 3.3 将解压后的jdk包拷贝到`/usr/java`目录
- 3.4 在所有节点上配置Java 环境
- 3.5 将node1发送到其他节点node2、node3、node4
- 4.关闭防火墙
- 5.配置免密SSH
- 6. 设置集群之间时间同步
- 7. 配置HDFS
- 7.0 在Windowd上配置单机Hadoop
- 7.1 配置伪分布式HDFS
- 1. 上传Hadoop文件
- 2. 解压文件
- 3. 修改配置文件
- 1. 修改profile文件
- 2.修改`hadoop-env.sh `
- 3. 修改`core-site.xml`
- 4. 修改`hdfs-site.xml`
- 5. 修改`slaves`
- 6. 格式化`NameNode`
- 7. 启动
- 8. 浏览器访问测试
- 7.2 配置完全分布式HDFS
- 1. 修改master上的 core-site.xml
- 2. 修改master上的hdfs-site.xml
- 3. 修改master上的slaves
- 4. 使用scp命令将整个hadoop项目拷贝分发给所有子节点(node2,node3,node4)的相同目录下
- 5.启动
- 7.3 搭建高可用HA
- 1. 配置Zookeeper
- 1. 上传并解压Zookeeper
- 2.配置zookeeper环境(三个节点都需要)
- 3. 修改zookeeper配置文件
- 4. 创建先前定义的zookeeper文件目录以及myid文件
- 5. 拷贝node2当前配置好的zookeeper项目到其他节点node3,node4
- 6. 在每个节点上各自执行4步骤
- 7.启动zookeeper
- 2.配置HDFS
- 1. master配置hdfs-site.xml,按照自身配置修改节点名称,公钥名称
- 2. master修改core-site.xml
- 3. master分发配置文件到所有子节点
- 4. 手动启动journalnode(master,node2,node3)
- 5.格式化
- 1. 在master上格式化namenode
- 2. 启动namenode
- 3. 启动完之后使用jps查看是否启动成功
- 4. 对node2,node3进行同步
- 6. 使用ZKFC
- 1. 在node4节点上启动zookeeper客户端
- 2. 选择任意一个节点格式化zkfc
- 3. 在node4上使用ls /可以看到创建了一个hadoop目录
- 6. master启动HDFS
- 8. 搭建Yarn
- 1. 修改master的mapred-site.xml
- 2.修改master的yarn-site.xml
- 3. 将master配置好的文件分发给其他节点
- 4. 启动Yarn
- 5. 测试
尚学堂大数据学习笔记(二) CentOS6.5 + JDK8 + hadoop2.6.5 安装配置HDFS
1. 安装CentOS6.5系统
工具vmware + CentOS-6.5-x86_64-bin-DVD1.iso镜像
1.1创建CentOS6.5系统虚拟机
1.1虚拟机创建
略过,可查找其他文章
使用的虚拟机镜像:![]()
1.2 开启ssh服务
service sshd start
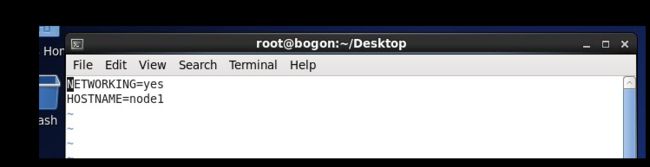
1.3 更改hostname
node1、node2、node3、node4改成相应名称
vi /etc/sysconfig/network
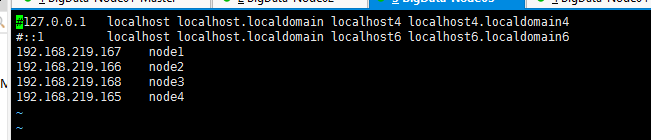
2 配置Host
修改hosts文件(node1、node2、node3、node4)
vi /etc/hosts
3. 安装配置JDK8
(所有节点:node1、node2、node3、node4)
3.1 上传jdk
[外链图片转存失败(img-dNNlPafG-1568773014968)(assets/1568687103215.png)]
3.2 解压
使用下面命令解压jdk包
tar -zxvf xxxxxx.tar.gz
解压完之后:
[外链图片转存失败(img-Gt60pHsq-1568773014969)(assets/1568687296529.png)]
3.3 将解压后的jdk包拷贝到/usr/java目录
[root@node1 ~]# mkdir /usr/java
[root@node1 ~]# mv jdk1.8.0_211/ /usr/java/
结果:
[root@node1 ~]# cd /usr/java/
[root@node1 java]# ll
total 4
drwxr-xr-x. 7 uucp 143 4096 Apr 1 20:51 jdk1.8.0_211
[root@node1 java]#
[root@node1 java]# cd jdk1.8.0_211/
[root@node1 jdk1.8.0_211]# pwd
/usr/java/jdk1.8.0_211
3.4 在所有节点上配置Java 环境
node1、node2、node3、node4
[root@node1 jdk1.8.0_211]# vi /etc/profile
[root@node1 jdk1.8.0_211]#
# 在末尾处新增
export JAVA_HOME=/usr/java/jdk1.8.0_211
export PATH=$PATH:$JAVA_HOME/bin
# 重启
. /etc/profile
3.5 将node1发送到其他节点node2、node3、node4
先
cd /usr/java/jdk1.8.0_211
在node2、node3、node4的/usr目录下创建java
mkdir /usr/java
拷贝jdk
[root@node1 jdk1.8.0_211]# scp -r /usr/java/jdk1.8.0_211/ node2:`pwd`
[root@node1 jdk1.8.0_211]# scp -r /usr/java/jdk1.8.0_211/ node3:`pwd`
[root@node1 jdk1.8.0_211]# scp -r /usr/java/jdk1.8.0_211/ node4:`pwd`
4.关闭防火墙
# 永久关闭防火墙
chkconfig iptables off
# 展示关闭防火墙
service iptables stop
5.配置免密SSH
# 在node1、node2、node3、node4生成密钥
[root@node1 jdk1.8.0_211]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
62:12:00:8f:dd:36:56:1e:e8:b8:24:07:c5:d8:cc:62 root@node1
The key's randomart image is:
+--[ RSA 2048]----+
|.Oo .o |
|+E=o.o . |
|oooo* . |
|. +o.o |
| + .. o S |
| . o . |
| |
| |
| |
+-----------------+
[root@node1 jdk1.8.0_211]#
# 处理密钥
[root@node1 jdk1.8.0_211]# cd ~
[root@node1 ~]# cd .ssh/
[root@node1 .ssh]# ll
total 12
-rw-------. 1 root root 1675 Sep 16 19:39 id_rsa
-rw-r--r--. 1 root root 392 Sep 16 19:39 id_rsa.pub
-rw-r--r--. 1 root root 397 Sep 16 12:49 known_hosts
[root@node1 .ssh]# cat id_rsa.pub >> authorized_keys
[root@node1 .ssh]# ll
total 16
-rw-r--r--. 1 root root 392 Sep 16 19:42 authorized_keys
-rw-------. 1 root root 1675 Sep 16 19:39 id_rsa
-rw-r--r--. 1 root root 392 Sep 16 19:39 id_rsa.pub
-rw-r--r--. 1 root root 397 Sep 16 12:49 known_hosts
[root@node1 .ssh]# cat authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAy6IWsRhhBySt64m29Ezk0qJXpa5knI/xvw2R6rXwcfxA3sXHQYDZ4bUFCEgofQe99Kw5iCN0aztvUm6v/wSbn/5eR6Fu/gjVcC4siYOhGrKkhNLLzIkrVfba1qYjEzGmpZdA9mRMsNxqpZ7/8D3y5qXuIhqgOooggUiB7EcVjIfIUUL2k8XDHPI8CJwyNskjm+vtjxqP3f73hZBFuS4ozPAQLEM9gXQHW6kAXJn8AB2ukxxnvs1spEdHgtsFURl0U45BjjIm5Di7eUhxLJ6+E06k62XGWQcfbvIpiEYeol0FGPaE0H/3KhUwvoDM+wU6gvRu1J0T5PkWgJasBPAy8w== root@node1
[root@node1 .ssh]#
# 配置免密
[root@node1 .ssh]# scp ./id_rsa.pub root@node2:`pwd`/node1.pub
[root@node1 .ssh]# scp ./id_rsa.pub root@node3:`pwd`/node1.pub
[root@node1 .ssh]# scp ./id_rsa.pub root@node4:`pwd`/node1.pub
[root@node2 .ssh]# cat node1.pub >> authorized_keys
[root@node3 .ssh]# cat node1.pub >> authorized_keys
[root@node4 .ssh]# cat node1.pub >> authorized_keys
[root@node2 .ssh]# scp ./id_rsa.pub root@node1:`pwd`/node2.pub
[root@node2 .ssh]# scp ./id_rsa.pub root@node3:`pwd`/node2.pub
[root@node2 .ssh]# scp ./id_rsa.pub root@node4:`pwd`/node2.pub
[root@node1 .ssh]# cat node2.pub >> authorized_keys
[root@node3 .ssh]# cat node2.pub >> authorized_keys
[root@node4 .ssh]# cat node2.pub >> authorized_keys
[root@node3 .ssh]# scp ./id_rsa.pub root@node1:`pwd`/node3.pub
[root@node3 .ssh]# scp ./id_rsa.pub root@node2:`pwd`/node3.pub
[root@node3 .ssh]# scp ./id_rsa.pub root@node4:`pwd`/node3.pub
[root@node1 .ssh]# cat node3.pub >> authorized_keys
[root@node2 .ssh]# cat node3.pub >> authorized_keys
[root@node4 .ssh]# cat node3.pub >> authorized_key
[root@node4 .ssh]# scp ./id_rsa.pub root@node1:`pwd`/node4.pub
[root@node4 .ssh]# scp ./id_rsa.pub root@node2:`pwd`/node4.pub
[root@node4 .ssh]# scp ./id_rsa.pub root@node3:`pwd`/node4.pub
[root@node1 .ssh]# cat node4.pub >> authorized_keys
[root@node2 .ssh]# cat node4.pub >> authorized_keys
[root@node3 .ssh]# cat node4.pub >> authorized_key
6. 设置集群之间时间同步
该部分转自https://blog.csdn.net/know9163/article/details/81141203
集群时间同步:在集群中找一台机器(node1,这里的node1就是任意一台机器,也可以写对应的IP地址),然后集群中的其他机器与node1 每十分钟同步一次。
步骤:
- rpm -qa | grep ntp 查看ntp 和ntpdate 是否安装
[root@node1 share]# rpm -qa | grep ntp
fontpackages-filesystem-1.41-1.1.el6.noarch
ntpdate-4.2.4p8-3.el6.centos.x86_64
ntp-4.2.4p8-3.el6.centos.x86_64
- vi /etc/ntp.conf 需要修改三处
a 打开一个注释 ,192.168.1.0 是node1机器上的网关。
# Hosts on local network are less restricted.
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
改成自己的网段192.168.x.0
b 将server0 ,server1 ,server2 ,server3 注释掉
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
#server 0.centos.pool.ntp.org
#server 1.centos.pool.ntp.org
#server 2.centos.pool.ntp.org
#server 3.centos.pool.ntp.org
c 打开两个注释,server 和 fudge
# Undisciplined Local Clock. This is a fake driver intended for backup
# and when no outside source of synchronized time is available.
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
- vi /etc/sysconfig/ntpd 加上
SYNC_HWCLOCK=yes
# Drop root to id 'ntp:ntp' by default.
SYNC_HWCLOCK=yes
OPTIONS="-u ntp:ntp -p /var/run/ntpd.pid -g"
-
chkconfig ntpd on 将ntp 永久开启
-
service ntpd start 后,可以查看状态 service ntpd status
-
crontab -e 编写定时器同步时间, 意义:每十分钟与node1 同步一次时间。需要在集群中其他的机器中都编写 crontab -e
## sync cluster time
## 分 时 日 月 周 这里是每十分钟同步
0-59/10 * * * * /usr/sbin/ntpdate node1
- ntpdate node1 然后就可以手动先同步一下时间.
7. 配置HDFS
7.0 在Windowd上配置单机Hadoop
//… 省略
7.1 配置伪分布式HDFS
在单节点上配置
1. 上传Hadoop文件
2. 解压文件
cd到上传文件目录 cd /opt/sxt
使用 tar -zxvf hadoop-2.6.5.tar.gz 解压
tar -zxvf xxxx.tar.gz 解压
[root@node1 ~]# ll
total 369816
-rw-------. 1 root root 3320 Sep 16 07:26 anaconda-ks.cfg
drwxr-xr-x. 2 root root 4096 Sep 16 07:32 Desktop
drwxr-xr-x. 2 root root 4096 Sep 16 07:32 Documents
drwxr-xr-x. 2 root root 4096 Sep 16 07:32 Downloads
drwxr-xr-x. 9 root root 4096 May 24 2017 hadoop-2.6.5
-rw-r--r--. 1 root root 183594876 Sep 16 19:45 hadoop-2.6.5.tar.gz
-rw-r--r--. 1 root root 41364 Sep 16 07:25 install.log
-rw-r--r--. 1 root root 9154 Sep 16 07:23 install.log.syslog
-rw-r--r--. 1 root root 194990602 Sep 16 19:23 jdk-8u211-linux-x64.tar.gz
drwxr-xr-x. 2 root root 4096 Sep 16 07:32 Music
drwxr-xr-x. 2 root root 4096 Sep 16 07:32 Pictures
drwxr-xr-x. 2 root root 4096 Sep 16 07:32 Public
drwxr-xr-x. 2 root root 4096 Sep 16 07:32 Templates
drwxr-xr-x. 2 root root 4096 Sep 16 07:32 Videos
[root@node1 ~]#
[root@node1 ~]# mv hadoop-2.6.5 /opt/sxt/
[root@node1 ~]# cd /opt/sxt/
[root@node1 sxt]# ll
total 4
drwxr-xr-x. 9 root root 4096 May 24 2017 hadoop-2.6.5
[root@node1 sxt]#
3. 修改配置文件
1. 修改profile文件
vi /etc/profile
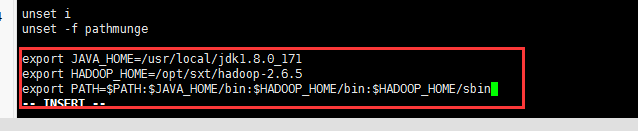
重新加载配置文件
source /etc/profile
vi /etc/profile
# 添加hadoop配置
export JAVA_HOME=/usr/java/jdk1.8.0_211
export HADOOP_HOME=/opt/sxt/hadoop-2.6.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 重新加载profile文件
[root@node1 hadoop-2.6.5]# . /etc/profile
[root@node1 hadoop-2.6.5]# hd
hdfs hdfs.cmd hdfs-config.cmd hdfs-config.sh hdparm
2.修改hadoop-env.sh
先cd到解压后的hadoop目录里面
vi etc/hadoop/hadoop-env.sh
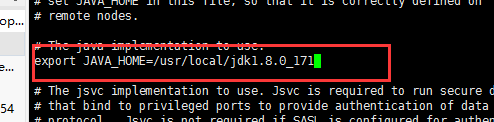
修改JAVA_HOME为自己配置的JAVA_HOME
[root@node1 hadoop-2.6.5]# vi etc/hadoop/hadoop-env.sh
# 修改里面JAVA_HOME配置
# The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.8.0_211
3. 修改core-site.xml
vi etc/hadoop/core-site.xml
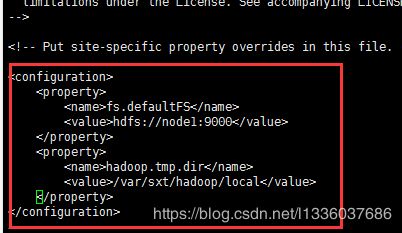
vi etc/hadoop/core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/sxt/hadoop/local</value>
</property>
4. 修改hdfs-site.xml
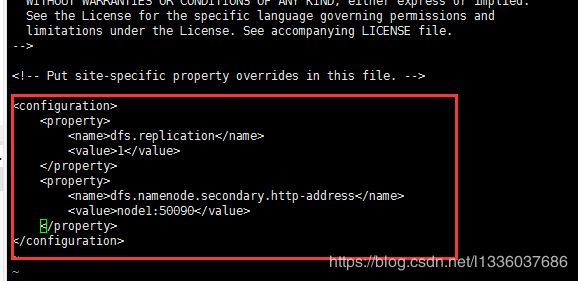
[root@node1 hadoop-2.6.5]# vi etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
</property>
replication表示副本数, 伪分布式要设置为1
5. 修改slaves
vi etc/hadoop/slaves

[root@node1 hadoop-2.6.5]# vi etc/hadoop/slaves
node1
6. 格式化NameNode
hdfs namenode -format

看到这句证明成功
[root@node1 hadoop-2.6.5]# hdfs namenode -format
7. 启动
start-dfs.sh

输入jps能看到以下效果代表启动成功
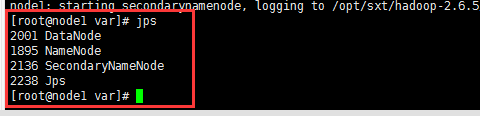
[root@node1 current]# start-dfs.sh
Starting namenodes on [node1]
The authenticity of host 'node1 (192.168.219.167)' can't be established.
RSA key fingerprint is 6c:5a:b4:9a:9e:e1:27:99:9c:34:66:5c:d5:93:d0:72.
Are you sure you want to continue connecting (yes/no)? yes
node1: Warning: Permanently added 'node1,192.168.219.167' (RSA) to the list of known hosts.
node1: starting namenode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-namenode-node1.out
node1: starting datanode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-datanode-node1.out
Starting secondary namenodes [node1]
node1: starting secondarynamenode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-secondarynamenode-node1.out
[root@node1 current]# jps
3490 Jps
3220 DataNode
3143 NameNode
3327 SecondaryNameNode
[root@node1 current]#
8. 浏览器访问测试
在本机上使用浏览器访问 http://IP:50070可以看到:
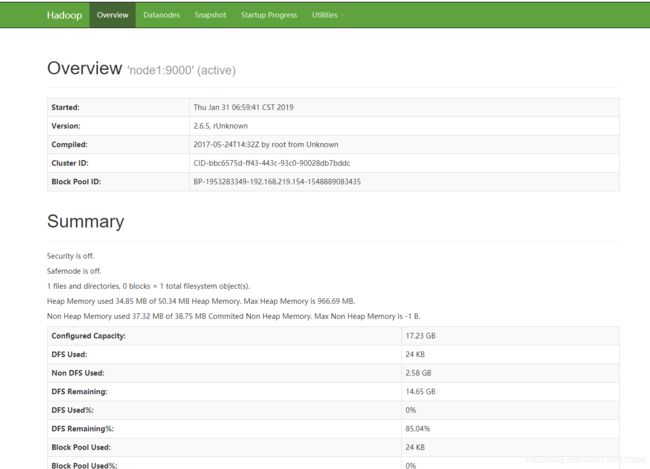
7.2 配置完全分布式HDFS
1、 配置node2、node3、node4的/etc/profile
# 添加配置
export JAVA_HOME=/usr/java/jdk1.8.0_211
export HADOOP_HOME=/opt/sxt/hadoop-2.6.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

1. 修改master上的 core-site.xml
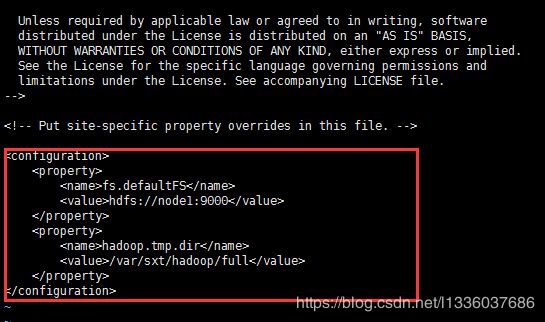
[root@node1 hadoop-2.6.5]# vi etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/sxt/hadoop/full</value>
</property>
</configuration>
2. 修改master上的hdfs-site.xml
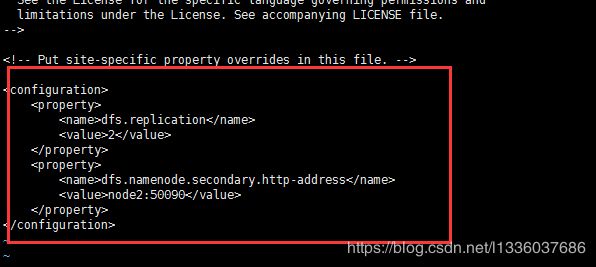
[root@node1 hadoop-2.6.5]# vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:50090</value>
</property>
</configuration>
3. 修改master上的slaves
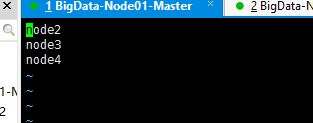
[root@node1 hadoop-2.6.5]# vi etc/hadoop/slaves
node2
node3
node4
4. 使用scp命令将整个hadoop项目拷贝分发给所有子节点(node2,node3,node4)的相同目录下
先cd到master的opt目录下
scp -r ./sxt/ root@node2:/opt/
scp -r ./sxt/ root@node3:/opt/
scp -r ./sxt/ root@node4:/opt/
5.启动
hdfs namenode -formatstart-dfs.shjps使用jps查看相应模块是否启动- 使用浏览器访问测试,
masterip:50070
7.3 搭建高可用HA

1. 配置Zookeeper
node2、node3、node4
1. 上传并解压Zookeeper
解压到/opt/sxt/下
tar -zxvf zookeeper-3.4.6.tar.gz -C /opt/sxt/
2.配置zookeeper环境(三个节点都需要)
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_211
export HADOOP_HOME=/opt/sxt/hadoop-2.6.5
export ZOOKEEPER_HOME=/opt/sxt/zookeeper-3.4.6
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
source /etc/profile
3. 修改zookeeper配置文件
先cd到conf目录下,拷贝一份配置文件,重命名为zoo.cfg:cp zoo_sample.cfg zoo.cfg
修改配置文件zoo.cfg
1.修改数据地址
# example sakes.
dataDir=/var/sxt/zk
2.在末尾追加
#autopurge.purgeInterval=1
server.1=192.168.219.155:2888:3888
server.2=192.168.219.156:2888:3888
server.3=192.168.219.157:2888:3888
4. 创建先前定义的zookeeper文件目录以及myid文件
# 1. 创建目录
mkdir -p /var/sxt/zk
# 创建myid文件,写入先前配置在末为追加的server.id ,当前服务器对应的是server.1所以写入1
echo 1 > /var/sxt/zk/myid
5. 拷贝node2当前配置好的zookeeper项目到其他节点node3,node4
先cd到/opt/sxt/目录下
scp -r ./zookeeper-3.4.6/ node3:`pwd`
scp -r ./zookeeper-3.4.6/ node4:`pwd`
6. 在每个节点上各自执行4步骤
# 1. 创建目录
mkdir -p /var/sxt/zk
# 创建myid文件,写入先前配置在末为追加的server.id ,当前服务器对应的是server.1所以写入1
echo 1 > /var/sxt/zk/myid
7.启动zookeeper
启动顺序 node2,node3,node4
启动zookeeper
zkServer.sh start
查看zookeeper状态
zkServer.sh status
2.配置HDFS
1. master配置hdfs-site.xml,按照自身配置修改节点名称,公钥名称
<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.nameservicesname>
<value>myclustervalue>
property>
<property>
<name>dfs.ha.namenodes.myclustername>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1name>
<value>node1:8020value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2name>
<value>node2:8020value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1name>
<value>node1:50070value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2name>
<value>node2:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://node1:8485;node2:8485;node3:8485/myclustervalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/var/sxt/hadoop/ha/jnvalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.myclustername>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/root/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
configuration>
2. master修改core-site.xml
hadoop.tmp.dir必须是一个空目录
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://myclustervalue>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/var/sxt/hadoop/havalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>node2:2181,node3:2181,node4:2181value>
property>
configuration>
3. master分发配置文件到所有子节点
scp hdfs-site.xml core-site.xml node2:`pwd`
scp hdfs-site.xml core-site.xml node3:`pwd`
scp hdfs-site.xml core-site.xml node4:`pwd`
4. 手动启动journalnode(master,node2,node3)
hadoop-daemon.sh start journalnode
使用jps查看journalnode是否启动成功
5.格式化
1. 在master上格式化namenode
hdfs namenode -format
2. 启动namenode
hadoop-daemon.sh start namenode
3. 启动完之后使用jps查看是否启动成功
[root@node1 hadoop]# jps
4721 Jps
4521 JournalNode
4651 NameNode
4. 对node2,node3进行同步
分别在node2,node3节点执行同步命令
hdfs namenode -bootstrapStandby
可以看到下面信息,则代表成功:
······
19/01/31 15:33:32 INFO namenode.NameNode: createNameNode [-bootstrapStandby]
=====================================================
About to bootstrap Standby ID nn2 from:
Nameservice ID: mycluster
Other Namenode ID: nn1
Other NN's HTTP address: http://node1:50070
Other NN's IPC address: node1/192.168.219.154:8020
Namespace ID: 1181164627
Block pool ID: BP-2019459657-192.168.219.154-1548919768243
Cluster ID: CID-ab317192-2eb3-42a4-81bf-b2f6e15454bc
Layout version: -60
isUpgradeFinalized: true
=====================================================
19/01/31 15:33:33 INFO common.Storage: Storage directory /var/sxt/hadoop/ha/dfs/name has been successfully formatted.
······
6. 使用ZKFC
1. 在node4节点上启动zookeeper客户端
zkCli.sh
2. 选择任意一个节点格式化zkfc
hdfs zkfc -formatZK
可以看到:
······
19/01/31 15:39:43 INFO ha.ActiveStandbyElector: Session connected.
19/01/31 15:39:43 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK.
19/01/31 15:39:43 INFO zookeeper.ClientCnxn: EventThread shut down
19/01/31 15:39:43 INFO zookeeper.ZooKeeper: Session: 0x368a2b711ff0001 closed
3. 在node4上使用ls /可以看到创建了一个hadoop目录
[zk: localhost:2181(CONNECTED) 8] ls /
[zookeeper, hadoop-ha]
6. master启动HDFS
start-dfs.sh
可以看到:
[root@node1 hadoop]# start-dfs.sh
Starting namenodes on [node1 node2]
node1: starting namenode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-namenode-node1.out
node2: starting namenode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-namenode-node2.out
node2: starting datanode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-datanode-node2.out
node3: starting datanode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-datanode-node3.out
node4: starting datanode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-datanode-node4.out
Starting journal nodes [node1 node2 node3]
node2: starting journalnode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-journalnode-node2.out
node3: starting journalnode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-journalnode-node3.out
node1: starting journalnode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-journalnode-node1.out
Starting ZK Failover Controllers on NN hosts [node1 node2]
node1: starting zkfc, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-zkfc-node1.out
node2: starting zkfc, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-zkfc-node2.out
8. 搭建Yarn
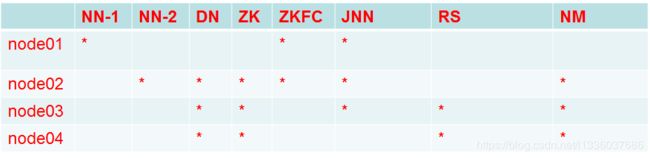
1. 修改master的mapred-site.xml
先拷贝一份,重命名为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
修改mapred-site.xml配置
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
2.修改master的yarn-site.xml
vi yarn-site.xml
添加如下配置,依照自己情况修改:
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>cluster1value>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>node3value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>node4value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>node2:2181,node3:2181,node4:2181value>
property>
configuration>
3. 将master配置好的文件分发给其他节点
scp mapred-site.xml yarn-site.xml node2:`pwd`
scp mapred-site.xml yarn-site.xml node3:`pwd`
scp mapred-site.xml yarn-site.xml node4:`pwd`
4. 启动Yarn
start-yarn.sh
可以看到:
starting yarn daemons
starting resourcemanager, logging to /opt/sxt/hadoop-2.6.5/logs/yarn-root-resourcemanager-node1.out
node4: starting nodemanager, logging to /opt/sxt/hadoop-2.6.5/logs/yarn-root-nodemanager-node4.out
node3: starting nodemanager, logging to /opt/sxt/hadoop-2.6.5/logs/yarn-root-nodemanager-node3.out
node2: starting nodemanager, logging to /opt/sxt/hadoop-2.6.5/logs/yarn-root-nodemanager-node2.out
当前命令只能启动nodemanager的节点,若是要启动node3,node4则需要在相应节点上手动启动。
分别在node3,node4执行以下命令
yarn-daemon.sh start resourcemanager
使用jps查看ResourceManager,NodeManager是否启动成功
[root@node3 ~]# jps
4434 NodeManager
3714 JournalNode
3635 DataNode
4793 Jps
4570 ResourceManager
3231 QuorumPeerMain
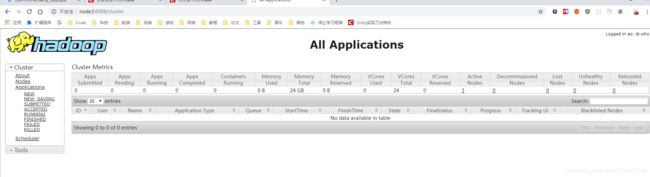
5. 测试
使用本机浏览器访问node3:8088 或 node4:8088
可以看到:
在这里插入图片描述